
 起点课堂会员权益
起点课堂会员权益OpenAI发布新模型GPT-4o:对所有人免费、更易用、更强
今天凌晨,OpenAI发布会召开,其中最重磅、最核心的是GPT-4o 这个新模型。具体能力如何?一起来看看吧。

今天凌晨 1 点( 太平洋时间 5 月 13 日上午 10 点 ),OpenAI 的 CTO Mira Murati 在三十分钟不到的时间里,用一场短的春季发布会,给了大伙们秀了一波 OpenAI 的新肌肉。
说实话,看得还有点让人意犹未尽,因为这 AI ,好像成精了。
这场发布会主要有四个部分,分别是桌面端 App 的更新、 WebUI 的更新、GPT-4o 模型的发布、实时 AI 助手的功能演示。
而其中最重磅、最核心的,无疑就是 GPT-4o 这个新模型。

根据 Mira Murati 的说法,OpenAI 的愿景是 AI 的便利能福泽所有人类,所以新的 GPT-4o 模型会向大伙们免费开放使用,付费用户呢,则在使用次数上比免费用户多 5 倍。( 官方指出,当使用次数达到上限时,免费用户会被强制退回到 GPT-3.5 版本。这应该是出于成本考量。 )
而相比于上一代的 GPT-4 Turbo,GPT-4o API 的速度快了 2 倍、费用便宜了 50%、速率限制上,也比前者高了 5 倍。

当然,如果只是这些性能上的“ 略微提升 ”,那就对不起 OpenAI 在 AI 领域话事人的地位了。
实际上,根据 OpenAI 官网的介绍,GPT-4o 中的 “ o ” ,代表的是 “ omni ”,也就是 “ 全能 ” 的意思。它成功地把文本、视觉、音频全部打通了,这意味着 GPT-4o 可以接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合输出。
这对多模态大模型来说,是一个重大改变。
拿此前 ChatGPT 的语音模式为例,它要用到三个独立模型组成的管道,一个模型负责将音频转录为文本,第二个模型是 GPT-4 ,它负责接收文本并输出文本,第三个模型则将该文本转换回音频。
这个过程意味最中间的主角 GPT-4 收到的信息其实是二手的 —— 它无法直接观察音调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感等等。
而在最新的 GPT-4o 模型中,所有输入和输出,都由同一神经网络处理,也就是说,新的 GPT-4o 是一个原生的多模态模型,而非之前的组合模型,它解决了上述的所有缺点。
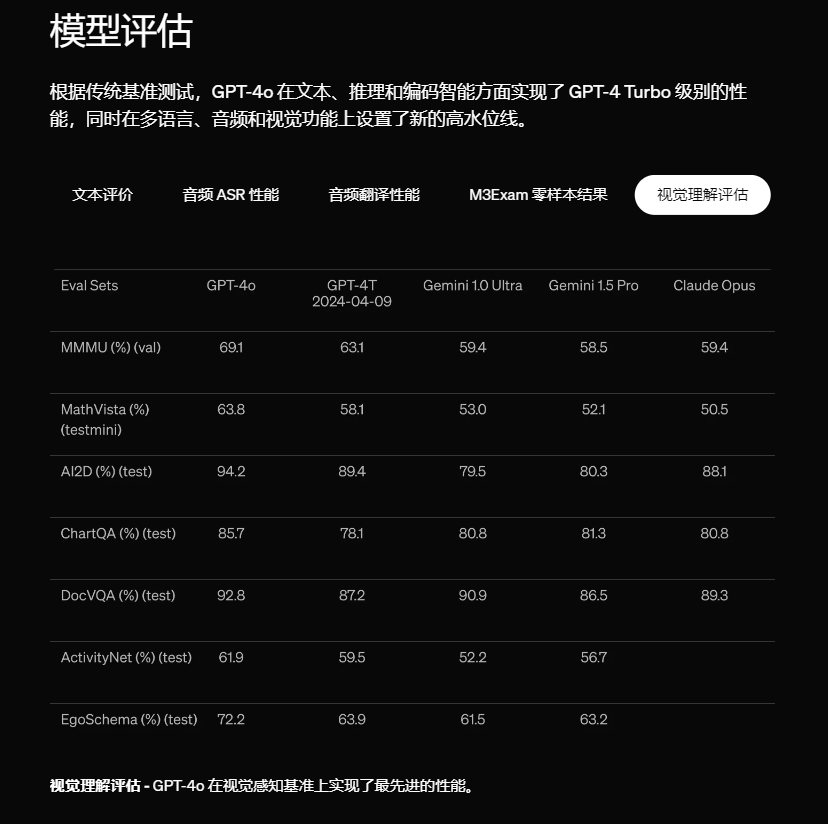
总之,在各型数据,特别是视觉和音频理解上,GPT-4o 相比于市面上的其他大模型,又来了一波遥遥领先。
在发布会上,他们也简单演示了一下基于 GPT-4o 的最新 AI 助手,只能说是相当震撼。
一个是 AI 助手建议 OpenAI 的工作人员别紧张,演讲前可以做个深呼吸。OpenAI 的员工则故意呼吸得很大声,让 AI 助手对其深呼吸做出评价,AI 助手直接损了他一句 “ 你不是吸尘器 ”。。。
很明显,新模型能听出发言人呼吸声的轻重,并且会富有情感的适时开玩笑。

另外,工作人员一边要求 AI 助手讲个故事,一边不断要求 AI 变化音色、语调、情感等等。AI 则像《 喜剧之王 》中的周星驰一样,完美应对 “ 导演 ” 的每个需求。
同样,AI 助手的视觉能力,也在演示现场惊艳了不少人。无论在是现场通过视频,一步步指导工作人员解方程,还是通过摄像头,观察人的表情猜其心情,AI 助手几乎都完美胜任。
在发布会中,他们还展示了 AI 助手的实时翻译功能,在演示中 AI 意大利语和英文完美切换,基本感受不到任何时延。
知危编辑部上传了发布会的完整视频,搭配了机翻字幕,各位可以看看视频演示效果,在惊艳的效果面前,我们的文字形容是十分苍白的,请从视频第 9:15 分开始观看演示。( 时间仓促,机翻字幕没有进行精校,导致英文字母有部分位置重叠、有一段意大利语机器识别为乱码,但基本不影响对视频的理解,给您带来的体验不够完美,抱歉 )
知危编辑部认为本次发布会的另外一大亮点,则是基于 GPT-4o 的桌面端 App,在发布会的现场演示中,用户使用 ChatGPT 时,不再需要面对这文本对话框做输入。
你可以给 OpenAI 的桌面 App 分享屏幕,让 AI 直接线上帮你解释代码、分析图表,并且能通过语音与你实时沟通。只能说老罗的 TNT 生不逢时,在当时确实缺少了大模型的赋能。
不过,知危编辑部觉得最可怕的是,按照 OpenAI 官网的说法:他们只是浅尝辄止地探索了一番,做了些演示,连他们自己也没完全搞清楚这个模型具体能做什么样的事儿、上限在哪里。

例如简单生成图片,还有图片的风格化,GPT-4o 似乎完全不在话下。
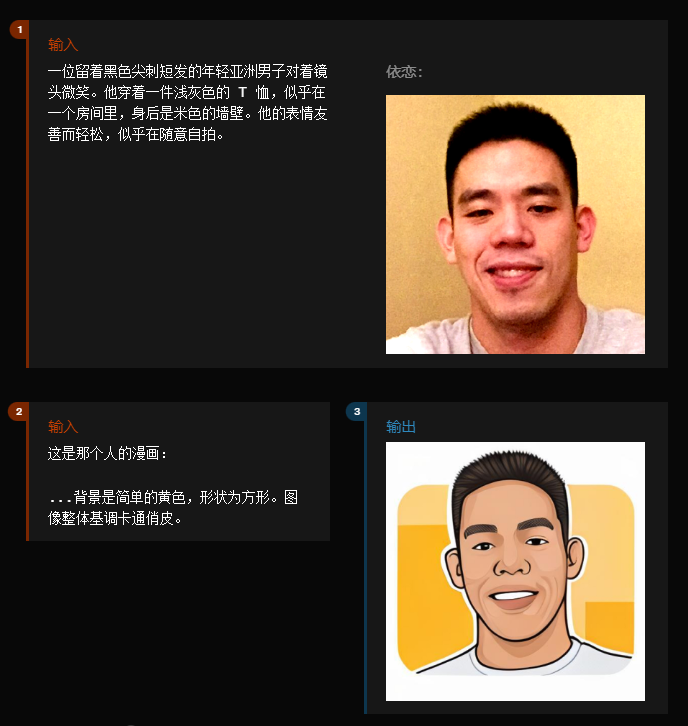
你也可以通过详细的描述,让 AI 做出相应的设计图片。

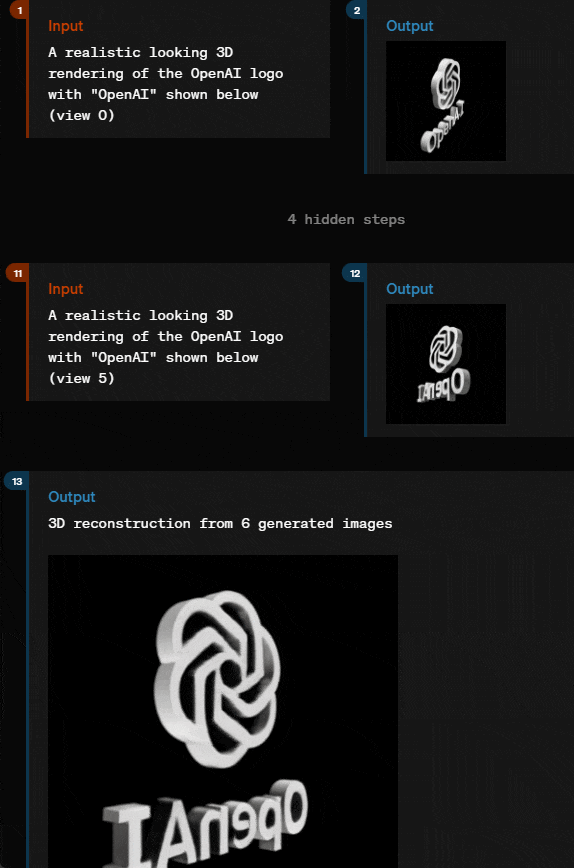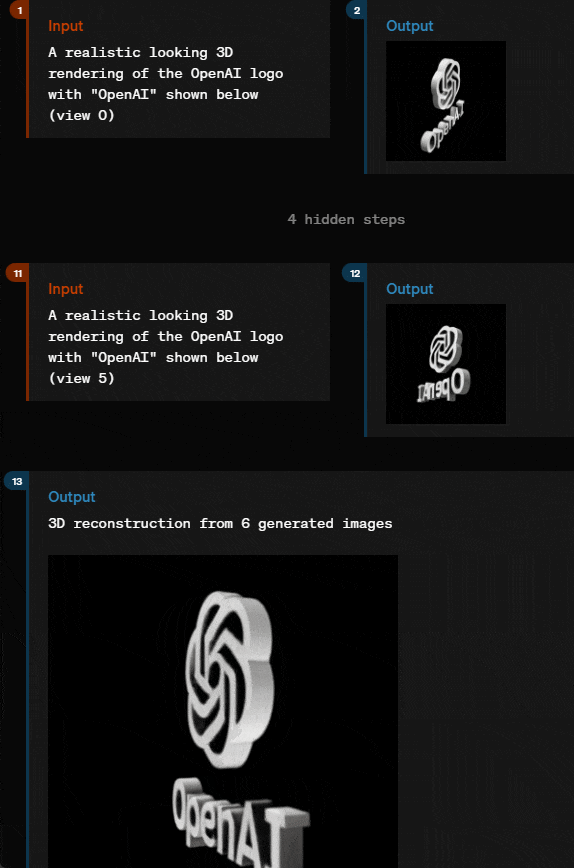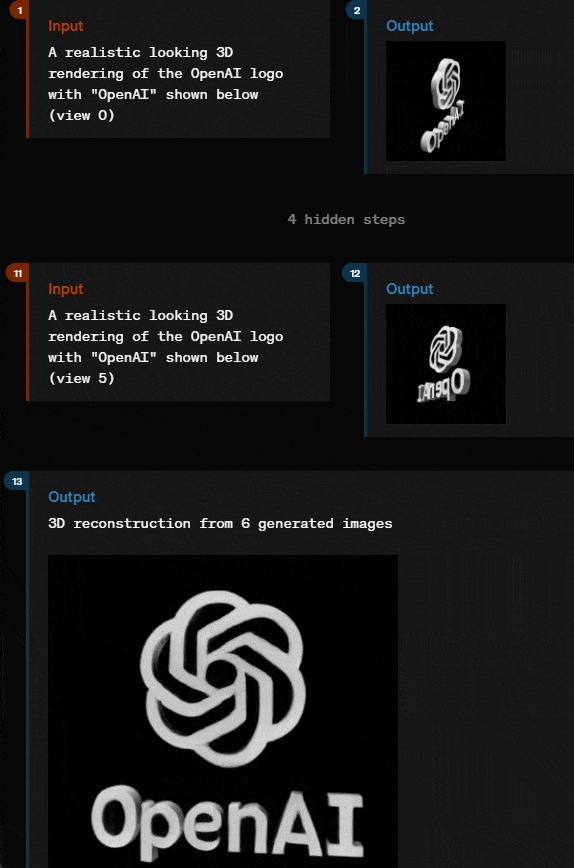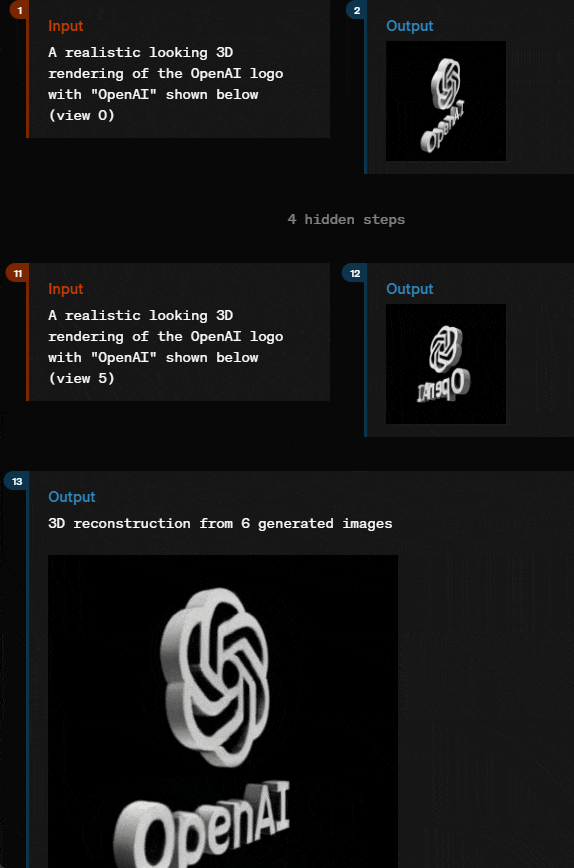
通过几个简单描述和输入,就输出 3D 图形,GPT-4o 似乎也能胜任。
甚至,它还能直接按照要求,输出相应的声音。

以下是生成的声音,可以点击播放↓按照 OpenAI 的说法,GPT-4o 的文本和图像功能,今天开始就会在 ChatGPT 中推出,并给出了入口链接。而音频功能,则需要经过几周乃至几个月的安全评估,才会正式开放。
不过,截至发稿前,知危编辑部所有拥有的 ChatGPT 账号中,通过官方入口进入后依旧只有 GPT-3.5 和 GPT-4 两个选项,不知是否是后台还没将功能上线完毕,所以我们暂未能给您带来实测体验。
各位可以稍安勿躁,或许过几个小时,GPT-4o 就会上线完毕,我们就可以进一步体验了。到这里,我们对 GPT-4o 的快速介绍已经完毕,相对于 “ 免费 ” 和 “ 更强 ”,我们认为这次更新最重要的是 “ 易用 ” 性。
我们认为,最好用的工具,应该让你并不会感觉到它的存在。过去,手机和电脑固然大大的提高了我们工作生活的效率,但它们依然有一定的门槛,依然需要你想办法去 “ 高效的输入 ”。而这次,GPT-4o 真正的让人与机器的交流变得丝滑,用语音和视频这种最原始、简单的方式,使你你能获得你想要的信息、做成你想要完成的事。
或许,我们可以把这称之为 “ 大模型的 OS 化 ”,忘掉 Windows、MacOS、iOS 或是 Android 吧,在未来,我们可能将不会接触操作系统,我们唯一需要的,就是对一台机器说话。
最后,我们放一个 GPT-4o 通过视频给两个玩石头剪子布的工作人员当裁判的视频,看了之后,你就明白什么是 “ Only OpenAI Can Do ” 了
本文由人人都是产品经理作者【汪仔2083】,微信公众号:【知危】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


