
 起点课堂会员权益
起点课堂会员权益
为什么用户调研需要50位定性和500份定量呢
 产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。
产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。为什么我们做用户调研时,样本量不是50就是500这样的数字?为什么不是300,或者是20这样?作者通过自己公众号为例,对这个问题进行了详细的分析,并解释了背后的理论依据,分享给大家。

教员经常讲,你对于某个问题没有调查,就停止你对于某个问题的发言权。
要注重调查、反对瞎说。
今天某个朋友在问我定性和定量调研的关系,问定性调研为啥是50位,不是30不是100呢?
有没有理论支撑?
我当时被问住了,尴尬了回了句 哈哈哈,好问题。
午饭后,重新思考了这个问题,做一个简单的梳理。
定性调研:
已购用户定性调研,有几个关键性的指标要明确。
1、用户是谁
2、用户在哪
3、用户使用产品属于什么阶段
举个例子,
我在写公众号,我的产品就是输出关于机器人赛道相关的东东。
那我做定性调研怎么做呢?
一、用户是谁
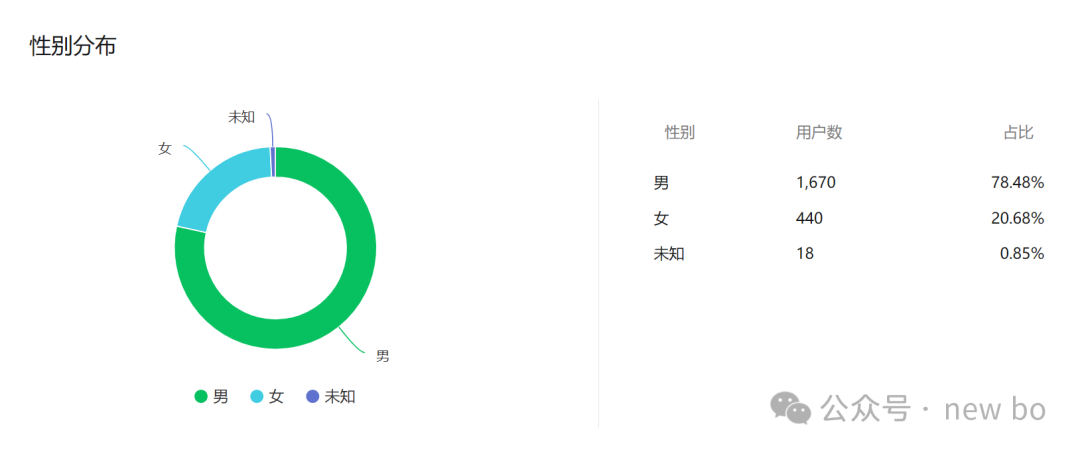
通过后台数据会发现,我的公众号粉丝男女比例,差不多4:1
那我做调研男女比例也要遵循这个逻辑。
用户是谁还要包含年龄、职业、收入、等等维度,那个群体多那个群体相对比例也要增加。
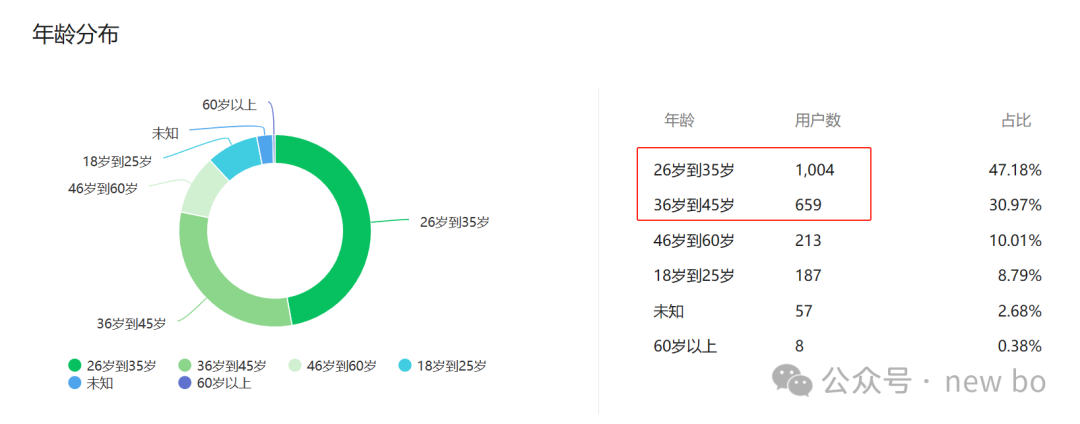
那我在访谈时就要侧重在26-45的年龄区间。
二、用户在哪呢?
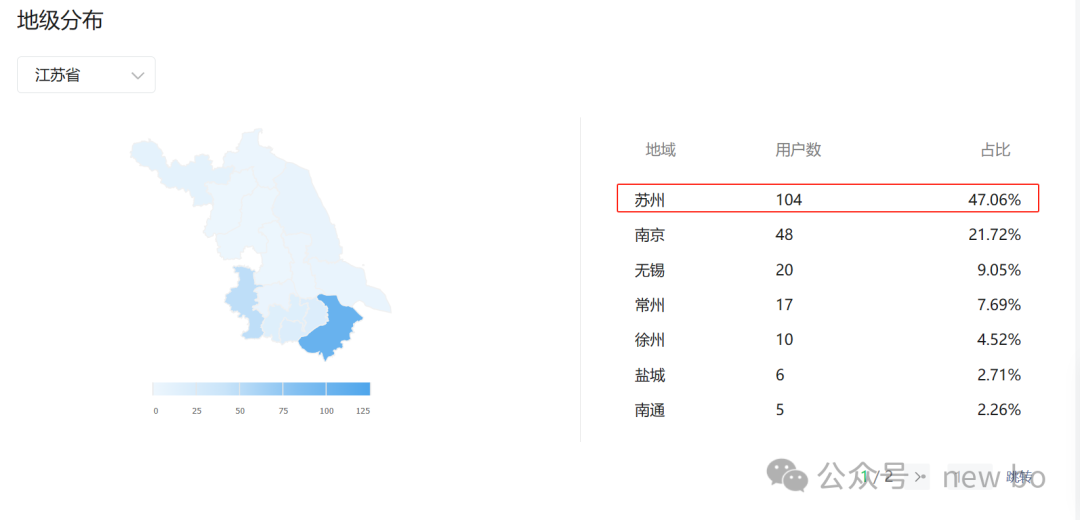
还是以我公众号为例,那我的访谈重点区域就在这几个地方。
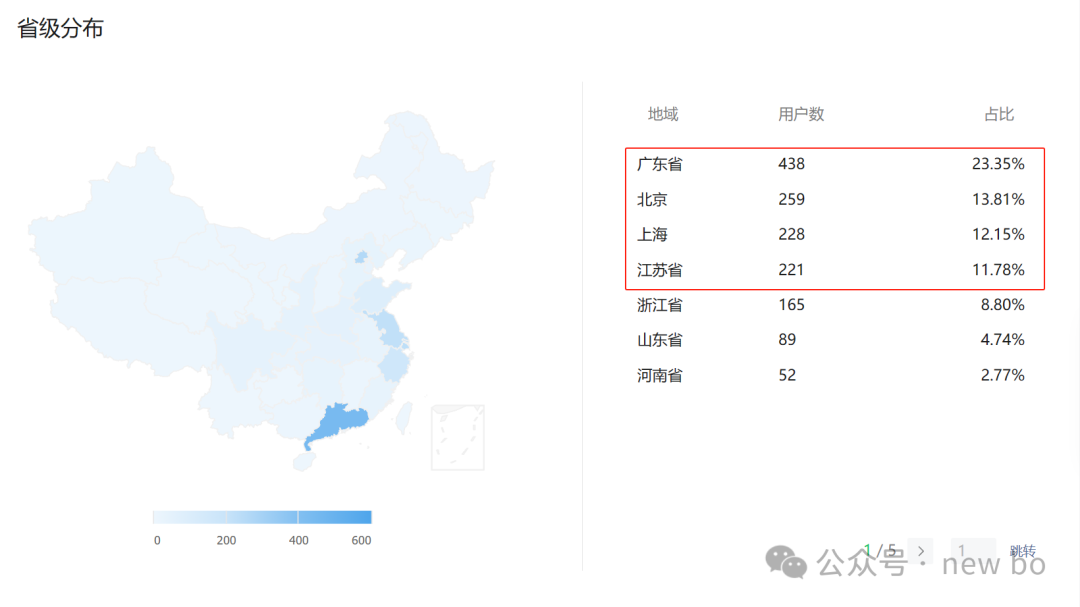
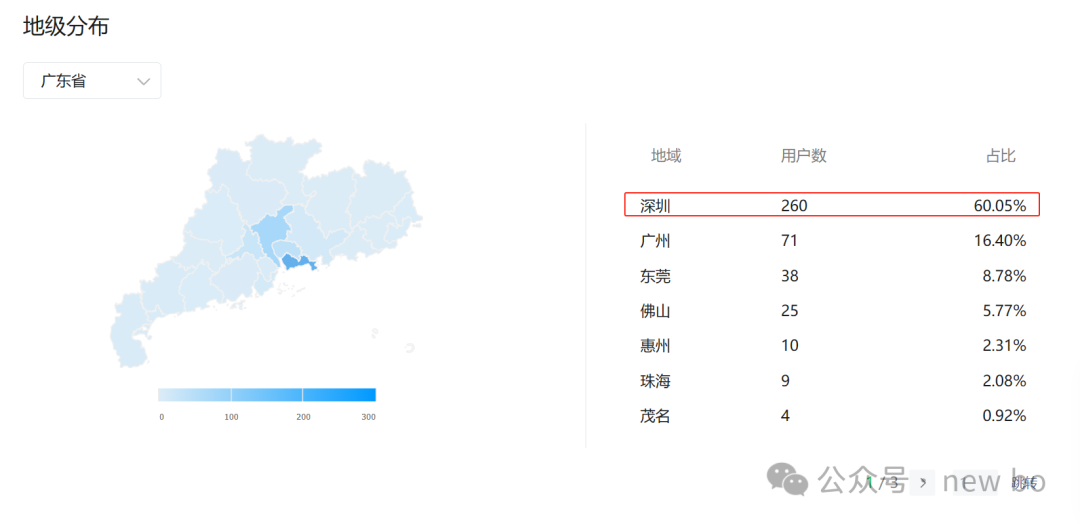
继续拆解,广东访谈重点在深圳,江苏访谈重点在苏州。
三、用户使用产品属于什么阶段
1、未使用人群
2、已使用人群
3、重度体验人群
按照阶段再结合地区和用户分解
3(阶段)x2(性别)xN(地区选择)xS(年龄选择)
按照我的来看
3x2x4x2=48人
这还没按照粉丝比例去做调整,那50位是不是算合理呢。

新产品的调研也可以做参考,也是适用的。
定量调研:
500份的调研样本不代表回收的有效数据,那为啥是500呢?
我们在读书阶段可能都接触过一部分统计学,在统计学里有个概率问题。
我不做科普,样本量其实也有几个关键性指标。
1、置信区间
2、置信水平
3、人口规模
4、标准差
感兴趣的自行百度
那统计学中有一个概念叫做Z分数。
Z 分数是统计学中的一个概念,它表示你的分数距离平均值有多少个标准差。在计算样本大小时,Z 分数代表了你想要的置信水平。
常见的置信水平有 90%,95%,和 99%,它们对应的 Z 分数分别大约是 1.645, 1.96, 和 2.576。
正太分布Z值表是现成,可以看下图
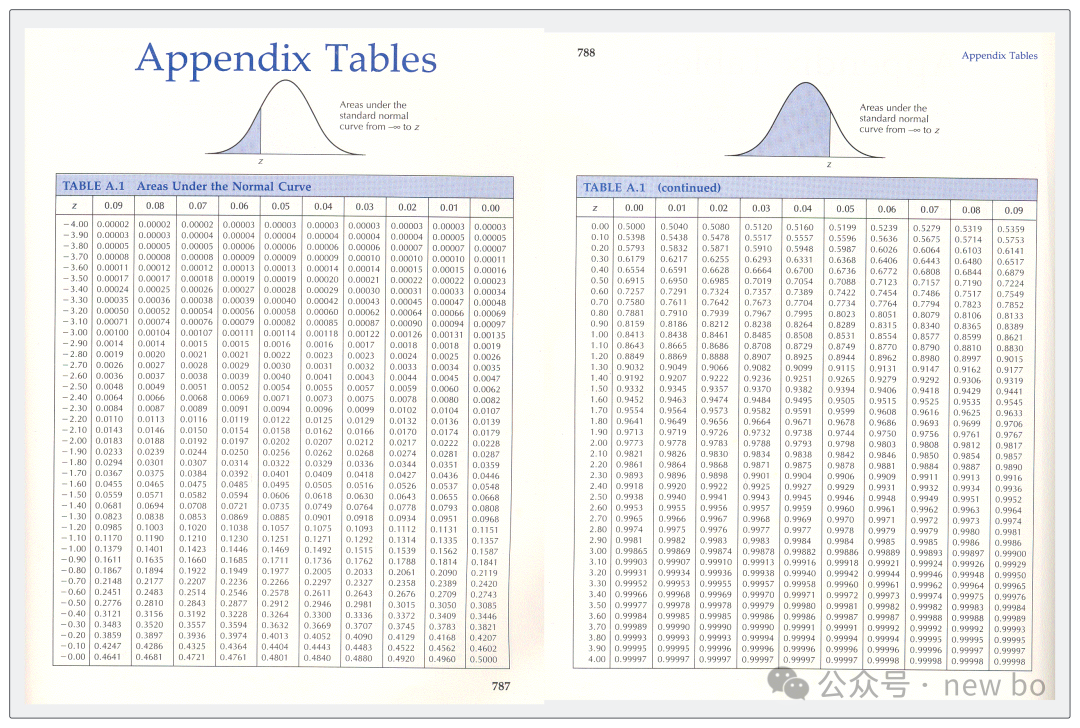
正态分布Z值表怎么看呢?
比如,我们想要找到置信水平为 90% 的时候,Z 分数是多少?
90% 的置信水平意味着中间覆盖了总体的 90%,留下两端各占 5%(100% – 90% = 10%,两端各占一半,所以是 5%)。
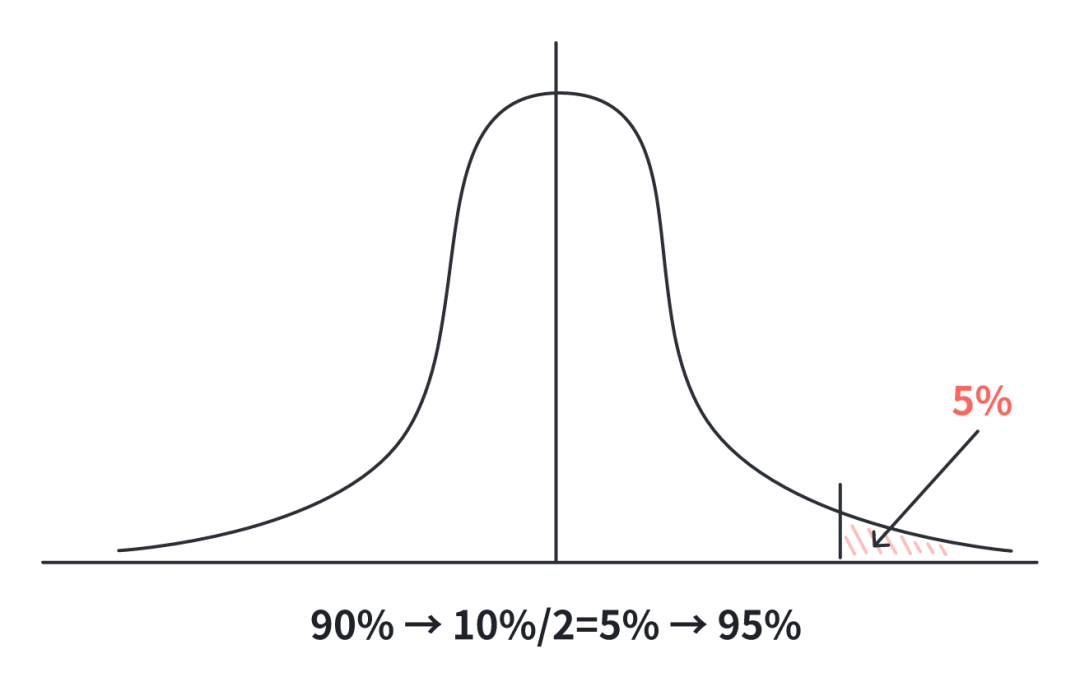
在标准正态分布中,这意味着你需要找到累积概率为 95%(50% + 45%)的 Z 分数。因为从最左端到中间覆盖了 50%,再加上从中间到你的 Z 点的 45%。
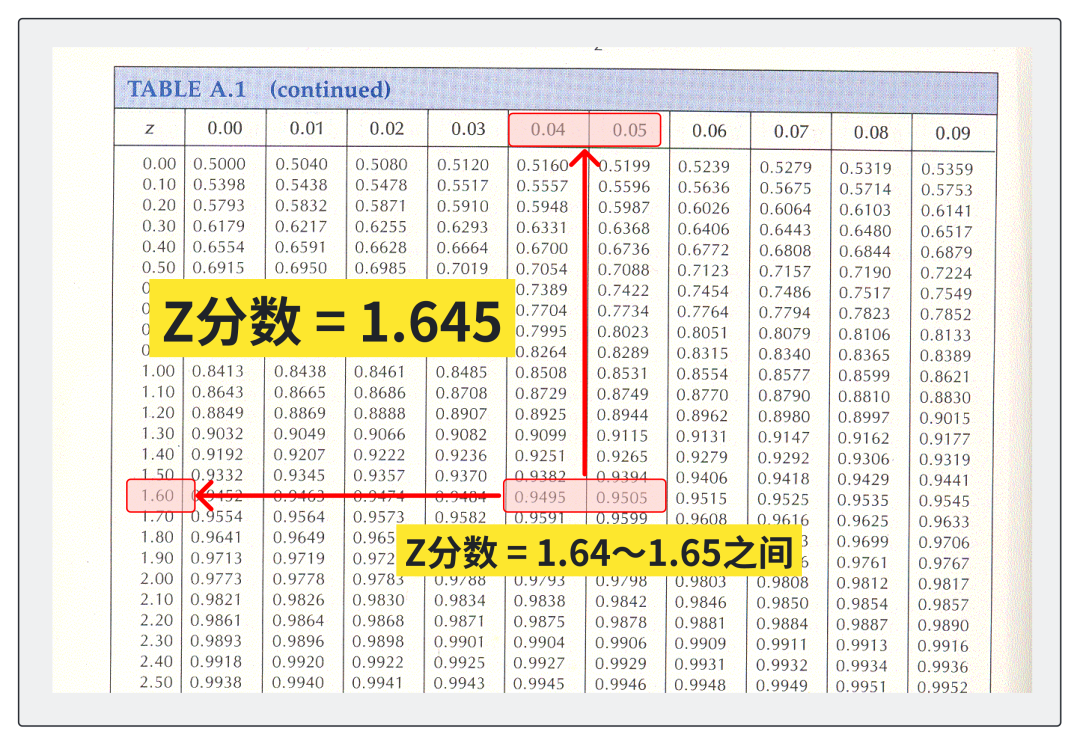
使用正态分布Z值表
找到对应的行和列,然后沿着这行和列确定交点,你就可以找到对应的 Z 分数。如果表是从最左侧到 Z 点的累积概率,你会找到累积概率为 0.9500 左右的 Z 分数。
好像还是没聊到样本量,别着急。
当你了解了这些信息,自然就会了解到一个公式

1)置信水平(Z 分数):你需要多大的置信度?这决定了你的 Z 分数。
2)预期的效应大小(P):这通常是你希望能够检测到的最小变化或差异。
通常使用 P = 0.5 作为保守估计,因为这会给出最大的样本大小。
3)标准差(e):预期答案的变化范围。
如果你不确定,可接受的误差范围 e 可以用 0.05(即 5%)作为一个保守估计。
假设我们要计算的情景如下:
置信水平是 95%,所以 Z = 1.96
预计效应大小(比例)P = 0.5
可接受的误差范围 e = 0.05(即 5%)
我们将这些值代入公式中:
N = (1.96² × 0.5 × (1 – 0.5)) / 0.05² = 384.16
根据计算,当置信水平为 95%,预期效应大小为 0.5,且可接受的误差范围为 5% 时,所需的样本大小大约为 384.16。
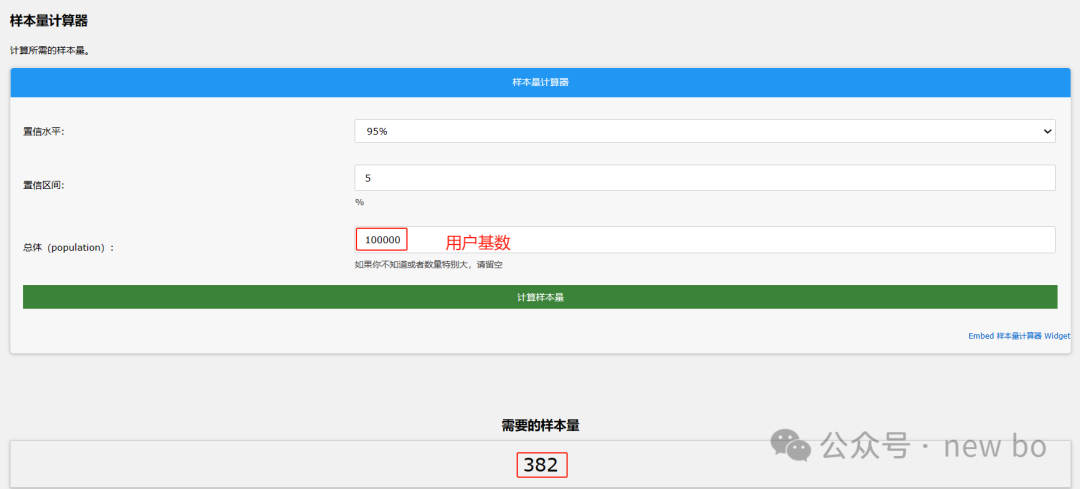
用样本计算器计算,用户基数十万人,有效样本量382就可以覆盖。
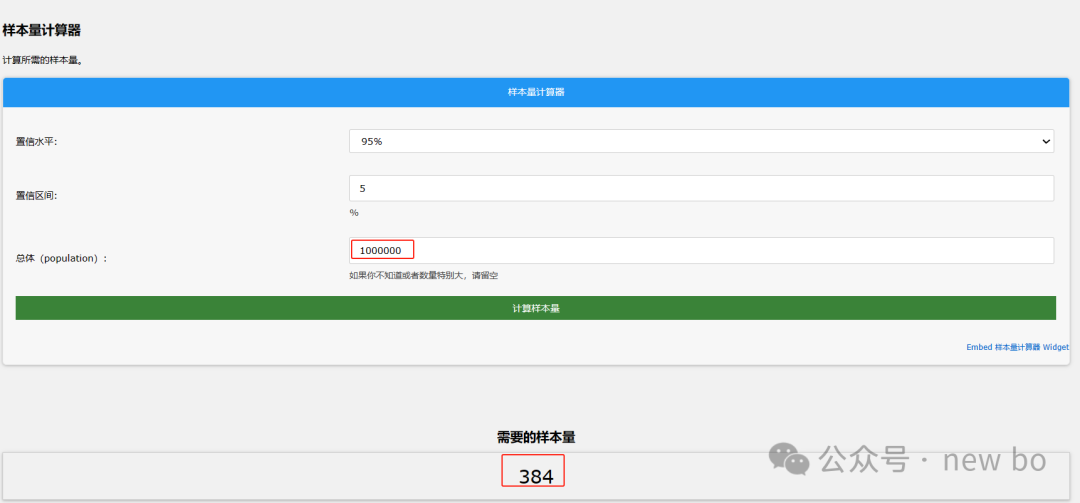
用户基数100万,有效样本量384。
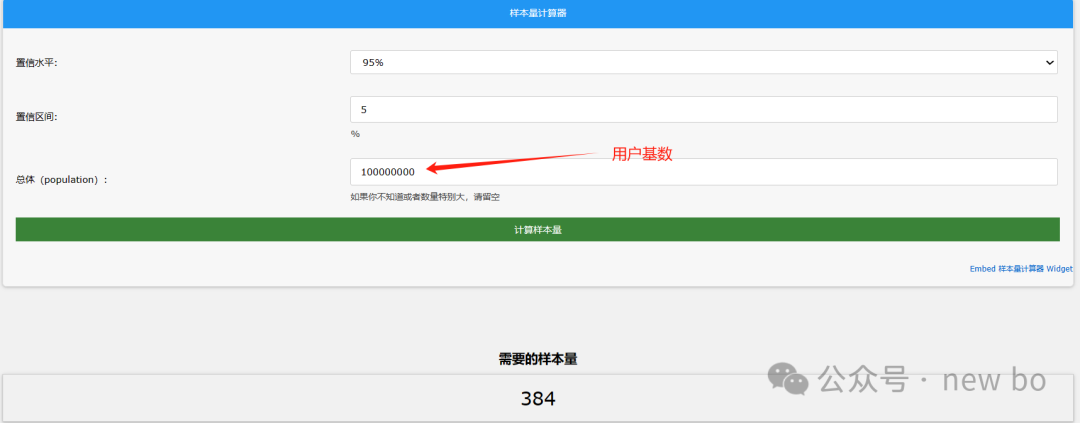
用户基数一个亿,你会发现还是384。
神奇不?
没有调查,我怎么可能瞎说。
以上
本文由人人都是产品经理作者【new bo】,微信公众号:【new bo】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







- 目前还没评论,等你发挥!









