
 起点课堂会员权益
起点课堂会员权益
都说谷歌被OpenAI狙击了,我怎么觉得它在狙苹果
 产品经理在不同的职业阶段,需要侧重不同的方面,从基础技能、业务深度、专业领域到战略规划和管理能力。
产品经理在不同的职业阶段,需要侧重不同的方面,从基础技能、业务深度、专业领域到战略规划和管理能力。在OpenAI的春季发布会之后,谷歌的 I/O 2024 大会也如期而至,本文分享了看完谷歌的 I/O 大会的一些感受,一起来看。

谷歌的 I/O 2024 大会也如约而至了。。。
发布会是在美国山景城开的,咱差评编辑部也派人去了现场,听身处前线的同事讲,不知道是不是 OpenAI 抢了风头的缘故,今年现场的氛围似乎都没前几年那么热闹了。
在以前,用万国来朝形容 I/O 大会都不为过,而今年很明显人没那么多( 不过以前有卖门票,这次没卖 )。
不过这毕竟还是谷歌,在整整快两个小时的发布会里,蹲在屏幕前看的世超,还是被秀了好几波肌肉。
简单一句话概括,和昨天的 OpenAI “ 小而美 ” 的春季发布会比起来, I/O 大会完全就是 “ 大而全 ” 。
反正就是各种和 AI 能挂上钩的东西,他们都来了一遍,从最基础的大模型,到能生成视频、音乐的 AI ,再到 TPU 芯片等等。
世超也从里面挑了几个比较亮眼的产品,来和大伙说道说道。
首先,世超觉得,昨天 OpenAI 发布会就是对着今天谷歌狙击的。。。
谷歌这次重点推出的多模态 AI 助手Project Astra ,和昨天 OpenAI 的 GPT-4o 几乎没差,都是能和多模态实时交互的 AI 。
把麦克风、摄像头的权限给 Project Astra 之后,它能眼观六路、耳听八方,随便问啥,它都能第一时间给出答复。
比如让它看看办公室里有没有会发出声音的东西,当镜头扫过一个音响时,它立马就能反应过来。
想再了解了解音响的构造啥的,也能直接在屏幕上写写画画,然后提问,整个过程 Project Astra 全都能看懂。
而且因为有最新的 Gemini 在背后撑腰,它的理解能力也是一绝。

随机找到一个程序员的工位,指着屏幕里的代码问是干啥的, Project Astra 没反应几秒就能给出答案,而且还能准确说出用了啥代码。还有搞个 “ 薛定谔的猫 ” 梗图,它也能迅速猜出来。
不过它和 GPT-4o 还是有点区别在的,就是说话的语气语调啥的,没昨天的 GPT-4o 的人味儿那么重, Project Astra 稍微有点高冷的味道。
而且 Project Astra 身上还有一个 GPT-4o 没展示的技能,有记忆,比如在演示里, Project Astra 能准确记住,镜头一扫而过的桌子上,放了一个苹果。

这对实时交互 AI 来说,算是相当关键的一个能力了。不过在前线的同事跟世超说,现在 Project Astra 就只能记一分钟的事儿,但之后上线的版本肯定能记更多。
但有一说一,就算是世超,也不能把过去一分钟看到了东西一五一十的全记下来。。。
要不是昨天 GPT-4o 已经抢先亮相了一波, Project Astra 一定会被各路媒体打上 “ 炸裂 ” 、 “ 史诗 ” 、 “ 颠覆 ” 、 “ 改写历史 ” 的标签。
可惜,仅仅是晚了一天,现在大家对 Project Astra 的形容只有一个标签: “ 跟 GPT-4o 好像 ” 。
真心建议谷歌抓一下内鬼。
除了多模态实时交互的 AI 外,谷歌还一次性放出了各种单独的多模态 AI ,有文生图的 Imagen 3 ,文生视频的 Veo ,文生音乐的 Lyria 。
而这些,世超觉得,就是摆明了对标市面上的那些 Sora 、 Suno 之众。
像是文生视频的 Veo ,从 1080p 的画面效果,还有 60 秒的时长,都要和 OpenAI 的 Sora 看齐。

不过谷歌没学 Sora 用 DiT ( Diffusion Transformer )架构,而是自己揉了好几个老模型,像是 GQN 、 DVD-GAN 、 Imagen-Video 、 Phenaki 、 WALT 等等。
从最后生成视频的效果来看,和 Sora 也确实有的一拼。
谷歌自个儿也说了, Veo 能驾驭各种风格,航拍、延时摄影等等镜头语言都能秒懂。。。
有意思的是,谷歌在每个视频下面都特意标了一行小字:所有视频均由 Veo 生成,未经修改。
在点谁应该就不用世超多说了吧。。。

而除了上面这些,谷歌还推出了对标 GPT-4 Turbo 等轻量性能大模型的 Gemini 1.5 flash 、对标 llama 3 等开源大模型的 Gemma 2 ,还有 Google 自家的新 TPU 等等。。。世超在这儿就不一一介绍了。
反正看起来,谷歌似乎不愿放弃AI 领域里的每个赛道,想把自己打造成一个 AI 界的六边形全能战士。
而更可怕的是,在各个领域里, Google 相比友商虽然都不一定是最好的,但也并不落后多少。
同时,谷歌的上限和野心,肯定不限于此。因为谷歌还拿出来些不少其他大厂单打独斗,绝对拿不出来的东西。而世超觉得,正是这些东西,有机会能让谷歌从AI 领域的追赶者,跻身为领跑者。
因为谷歌,拥有其他AI 巨头所没有的成熟系统与应用生态。

这次 I/O 大会上,谷歌就展示了好几个这样的例子。
比如他们先展示了一波 Gemini 和 Google 相册的结合。记不清自个儿车的车牌号,在 Google 相册里搜索 “ 查找车牌号 ” , Gemini 能直接从图库里准确找到车的照片,并把车牌号告诉你。
还有在谷歌 Gmail 邮箱里,你也能让 AI 帮你查航班信息,在谷歌地图里,能让 AI 帮忙获取酒店附近的餐厅和旅游景点,再给计划相应的日程。
这还没完,谷歌的老本行搜索这次也上 AI 了,而且一上来就搞了波大的,支持语音、图片,还有视频搜索。
比如说唱片机坏了想查查原因,直接镜头对准故障位置问就行了, AI 会立马反应给出答案。

还有压箱底的胶片机不怎么会使,同样拍给它看就行了,不需要自己再绞尽脑汁去形容。

只不过,这次谷歌又在演示上翻车了。。。有媒体扒出,胶片机的那个回答完全就是在胡扯,回答中的一个建议是 “ 把胶卷取出来看看 ” ,而这样只会让整卷胶卷直接报废。。。

不过,这至少说明他们玩儿的就是个 real ,毕竟大模型乱讲话这事儿一直存在,而出错,比造假还是强一些的。
总之,按照谷歌的说法, Gemini 大模型正在全面整合谷歌的那一大家产品中,包括在未来,他们将把AI 直构建到 Android 操作系统的底层之中,准备改写用户和手机之间的交互方式。
他们也举了一些例子,像是用手机看球时,不知道运动员犯没犯规,圈起来就能问,还有做题时圈一圈就能搜题。
而且显示答案的时候,它也不会跳转到别的 AI 软件里面去,属于是把 AI 融到系统最最最底层了。
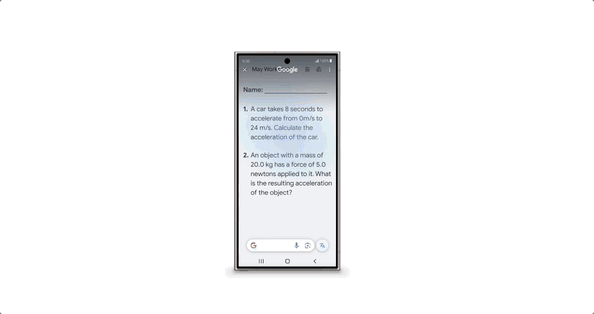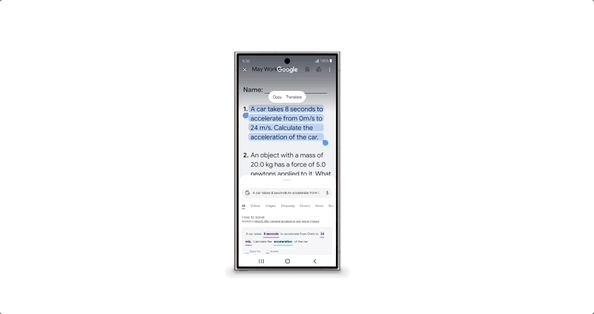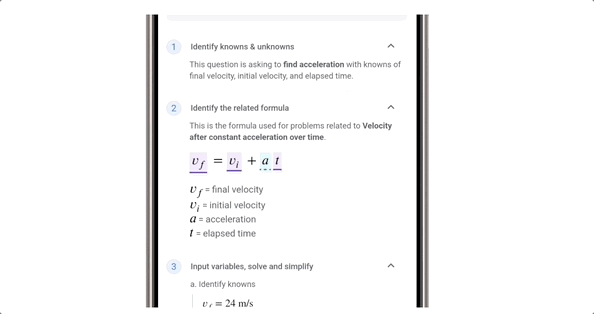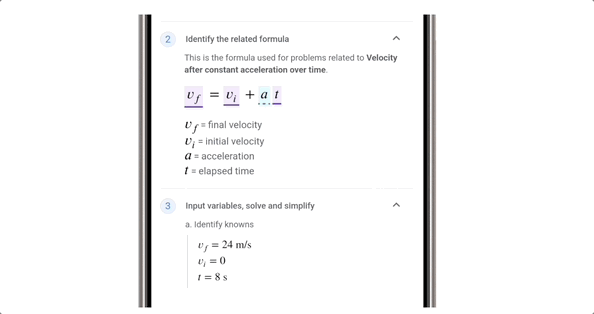
甚至在打电话的时候, AI 还能实时反诈,能从对话中直接判断对方是不是骗子,要是有可疑的字眼,立马会弹窗提示。
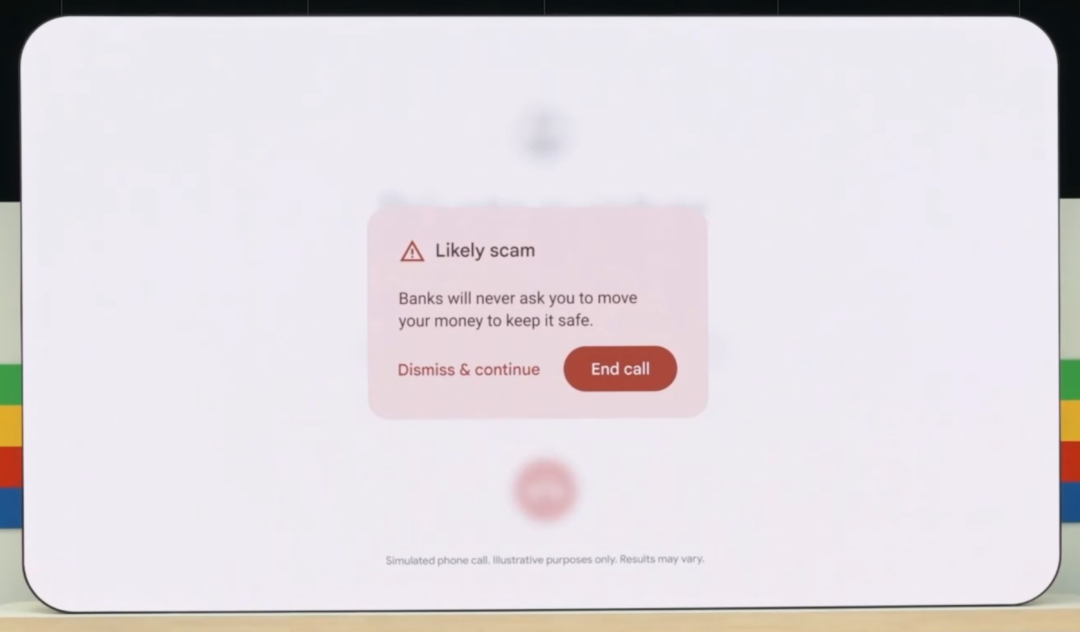
其实看到这的时候,世超已经感受到了谷歌做 AI 的优势,未来 AI 肯定要朝着底层生态去发展。
而作为一家大企业,谷歌手里的资源是相当多,而且还有安卓这个大阵营,它能轻易把 AI 打入安卓内部,但 OpenAI 要和 iOS 深度结合,估计没这么随心所欲了。
总之这次谷歌的 I/O 大会啥产品都有,但要说出类拔萃,还谈不上。不过,在AI 应用集成这一个最直面消费者的维度上看,谷歌还真是目前 AI 领域的集大成者之一。
这一波,去年还被称作是 AI 圈 “ 仲永 ” 的谷歌,算是渐入佳境了。
不过世超看完谷歌的 I/O 大会,倒觉得他们这次不仅仅要 “ 狙击 ” OpenAI ,更要把苹果生态也一起狙了。。。
所以下一回合,到苹果你了。
图片、资料来源:
谷歌,知危
本文由人人都是产品经理作者【差评】,微信公众号:【差评】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







- 目前还没评论,等你发挥!









