
 起点课堂会员权益
起点课堂会员权益Google 发布「AI 全家桶」反击 GPT-4o !搜索引擎罕见大更新, 121 句「AI 」道尽焦虑
本文聚焦于Google I/O大会发布的AI全家桶,涵盖搜索引擎的革新与多模态AI项目的进展,深入探讨了AI技术的最新应用,引导读者洞悉AI领域的未来趋势,希望对你有所帮助。

紧跟步伐绝不落后昨晚 OpenAI 发布了 ChatGPT-4o 后,压力就给到了 Google I/O ,仿佛 Google 无论如何也摆脱不了「AI 界的汪峰」这一称号。而 Google 则通过近 2 个小时的发布会,提了 121 次 AI ,推出了十余种新品及升级,可谓「量大管饱」,火力全面覆盖,但给人的惊喜却并不多。

我们先给大家一次性总结这场发布会的亮点,更多功能解析请接着往下看。发布会要点:Google Search AI:发布了 AI Overviews,加强版 AI 搜索概要功能,多步推理能力上架。Gemini 大模型:Gemini 1.5 Flash(100 万上下文);Gemini Pro(200 万上下文)。Gemma 大模型:发布开源多模态大模型 Pali Gemma 和 Gemma2。AI in Google Workspace:用 Gemini 的能力和 Side Panel 的形式,将 Google 系列产品串在一起。
Gemini App:手机版的 Gemini 应用程序,即将支持和 AI 视频对话,近几周发布。Project Astra:最新的多模态 AI 项目,包含 Imagen3、 Music AI Sandbox 和 Veo 等针对图像、音乐、视频的生成式 AI。做搜索起家,用搜索王炸Google Search 是 Google 最大的投资和创新领域之一,更是它们的创始产品。
25 年前,Google 开启了搜索功能,今晚 Google 再次拓展了搜索的边界。简单来说,有了 AIGC 的 Google Search,可以做到更多事情:无论你在想什么,无论你需要完成什么,只要问问(它),Google Search 就能找到。而 Google Search 的一切进化,都是建立在专为其定制的 Gemini 模型上。Google 在发布会上介绍,「与众不同」的 Google Search,主要有三个独特的优势:Google 的实时信息包括超过一万亿个关于人、地点和事物的事实名列前茅的产品,和最好的网络服务之一Gemini 的力量
把将这三件事结合在一起,就解锁了 Google 在搜索领域的全新能力。第一个新功能是 AI Review,用户可以通过在搜索结果的顶部,获取由 AI 大模型生成的摘要,以此简化整个搜索过程,让复杂问题的检索过程,变得简单。
Google 称,到今年年底,将有超过十亿人使用 Google Search 中的 AI Review 功能,而且 Google 宣称,这也将会是其搜索引擎 25 年以来最大的更新之一。Multi-step reasoning 是 Google Search 中的另一个重磅功能。
通过全新的多步推理,以后我们做一些生活、工作和出行的计划,会变得非常简单。比如你可以通过搜索栏来找到「附近最好的瑜伽馆」,随后附近所有关于瑜伽馆的评价评分、课程推荐、距离等重要信息,都会被分类成块,十分清楚地在搜索结果中显示。
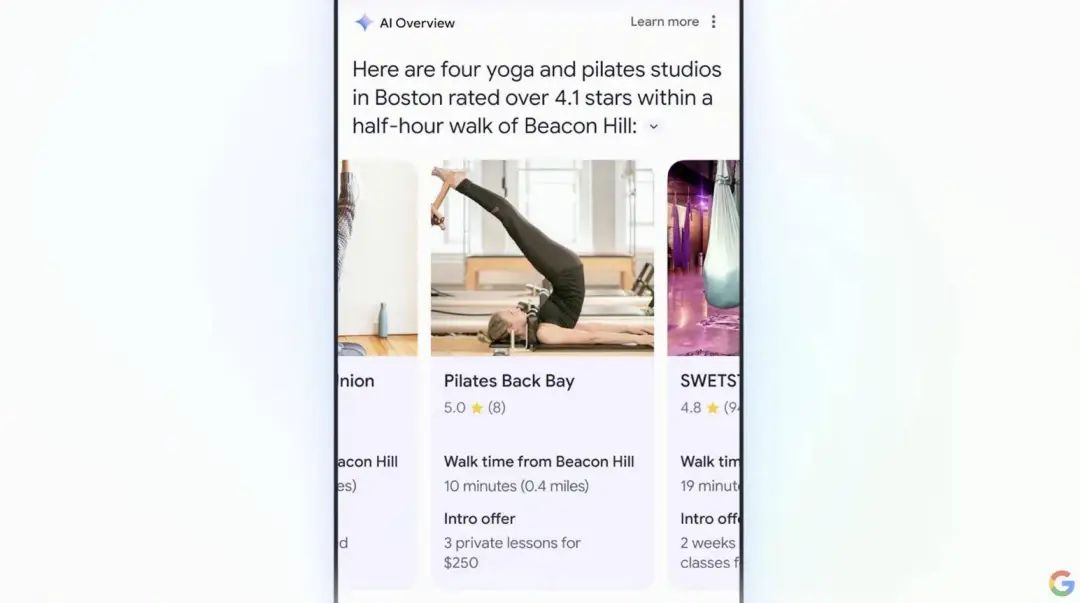
依靠 Google 自有的庞大数据库,AI 在搜索过程当中可以调用最新、最全的高质量信息,所以搜索结果的准确性和可信性也就有了更多的保障。目前,Google 在全球包含了超过 2.5 亿个地点,并实时更新,当中还包括评分、评论、营业时间等重要信息。Planning in Search 是另一个帮你减少负担的更新。
比如你现在正在重新调整膳食结构、从头安排饮食计划,不想在早餐、午餐和晚餐时吃通心粉和奶酪。直接把需求抛给搜索框,Google Search 就能还给你一份按照要求,且合理安排的全新一周食谱。
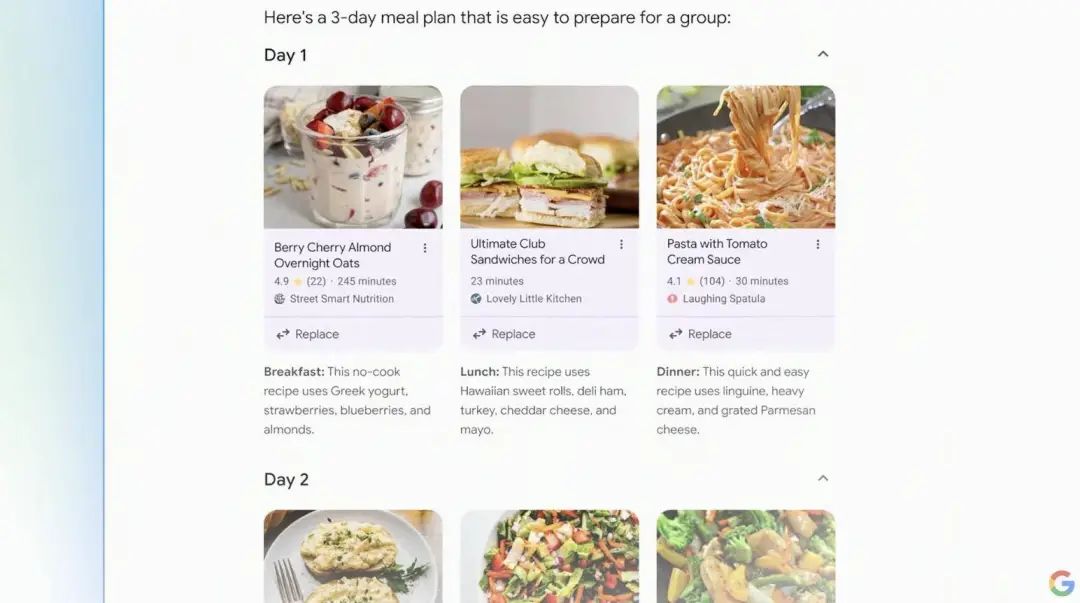
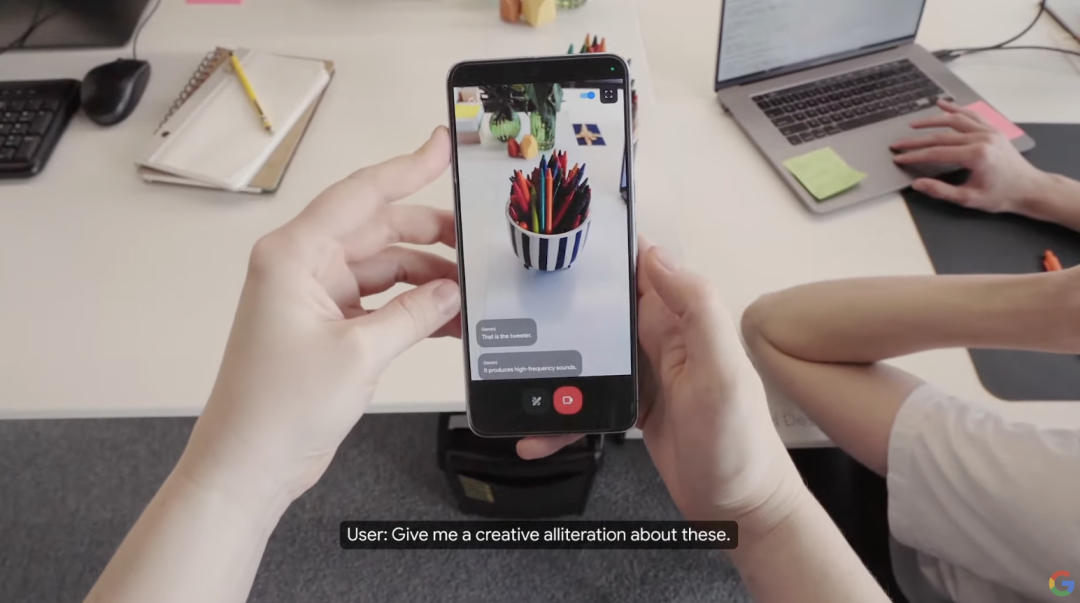
而且,你还可以随时改变条件和细节,搜索的结果也会根据最新的提示实时更新。如果说上述的功能,我们已经在其他公司的产品中见过,甚至用过,那 Ask with Video ,一定会给你一些惊喜。生活当中有很多物件,都有着各自的专属名称,有些器械出现一些小问题时,也都有着对应的修理方式。但很多时候只有专业人士才能叫得出,也只有他们能「对症下药」。现在通过 Google Search 的 Ask with Video,每个人都能成为专家,它相当于一本装在手机里的百科全书。

唱片的零部件不起作用了不知道从何下手,相机的快门突然失灵……以前可能要大费周折地寄回厂家售后。但现在用 Google 设备的镜头拍下问题所在,Google Search 就能根据你所遇到的问题初步诊断,一些小故障还能当场给出解决方案。在发布会的实时演示里,AI 还把整个的修理步骤一一列出,按照屏幕上的指示,演示者很快就能解决小麻烦。
这个功能,是通过 AI 逐帧分解视频,把每一帧的关键信息导入 Gemini 的长触点窗口挨个分析,并梳理网络中相关的文章、论坛、视频等,从中找到见解,以此实现了 Ask with Video 的智能建议。比起传统的文字输入,视频最大的好处在于,我们和 AI 的交互过程变得更加直观,用「这里」「这个」等模糊的词语,也能使大模型知道我们指代到底是什么。
Google 称,这些最新的 AI 功能,将会在未来几周内在实验室功能推出,这也意味着更强大的 Google Search 离落地已经不远了。后续版本中,它甚至还将能基于页面中视频的自动字幕来寻找答案,不知道会不会抢了那些「1 分钟看完 XX 电影」博主的饭碗。图 · 歌 · 片,瞄着 OpenAI 打如果说前两天的 GPT-4o 是 AI 再一次给世界带来了一点震撼,那今晚 Google 官宣的 Project Astra 则是震撼的延续。Project Astra 是 GoogleMind 的原型——一个通用人工智能助手。

和 GPT-4o 的使用效果类似,用户可以通过它和 AI 实时对话,以及视频聊天。发布会的演示可以很好地表现这个新功能,工作人员在演示视频中将手机镜头对准身边的物品,并向 Project Astra 提出一些疑问,它几乎能做到零延时地准确回答。例如 Project Astra 能说出音响上半部分的是高音喇叭,对电脑屏幕上显示的代码也能轻松识别其具体作用。
Google 称:我们的新项目专注于构建一个未来的人工智能助手,它可以在日常生活中真正提供帮助。基于更强大的 AI 性能,Google 在 I/O 上还宣布了另外三个实用功能,它们分别在「图像」「音乐」「视频」领域,体现着先进技术的「未来感」。Imagen 3 是 Google 发布的最新的图像生成模型。

它可以更加理解我们的提示词,并以此创建更加逼真的图像。发布会上展示的「狼」的生成图片,就是 Imagen 3 在一段叙述中,准确提取了 8 个细节信息,并且在图片中都有体现。

不难发现,生成图片不仅细节准确,而且十分逼真。Imagen 3 还能应对一些更加抽象的图片创作,例如根据「彩虹色」「羽毛组成的 light」「黑色背景」的提示,生成的创意图片。

就像是它很清楚你想要什么。发言人甚至在发布会上开玩笑式地炫耀「你可以用它来数别人脸上的胡须」。在音乐生成方面,Google 也有了新的突破。Music AI Sandbox 是最新推出的音乐生成模型,Google 这次在 I/O 现场还请来了 Marc Rebillet 坐镇分享。

根据艺人创作的一小段音乐 demo,Music AI Sandbox 能在此基础上拓展延长,还可以进一步按照用户输入的提示词,如音乐风格和种类等,进行乐曲的二度创作。Google 称,它们和 YouTube 一起构建了 Music AI Sandbox:这是一套专业的 AI 音乐工具,可以从头开始创建新的乐器部分,在轨道之间转换风格等,以帮助我们设计和测试它们。另一个实用模型名为 Veo,专注于生成视频。

用户只需输入相关的文本、图像或视频提示,Veo 就能创建高质量的 1080p 规格的视频,时长也达到了 60 秒之久。它能以不同的视觉和电影风格捕捉指令中的详细信息。

例如,我们可以在提示中输入事物、横向或延时的航拍照片,并使用其他提示进一步编辑视频。一直以来,视频生成 AI 「只在理论上成立」其实有诸多阻碍,其中走向「能用」的最大门槛是:视频生成时间只有短短几秒,一般只能在一两个动作里反复横跳。

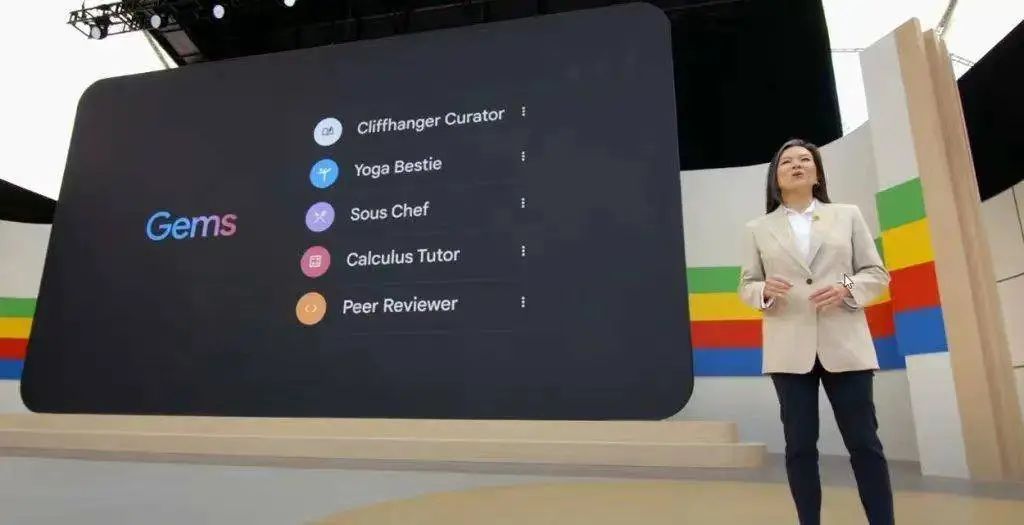
所以 Sora 发布之初才会引起非常大的讨论,而今晚开始,Google 的 Veo 也成了大家重点关注的对象,从照片写实主义到超现实主义和动画,大部分的影视风格,它都能处理。除了 Project Astra 以外,Google 还为我们提供了一个可私人定制的 Gemini ——Gems。Google 表示,它能在保留指定特征的情况下完成任务,成为千人千面的私人助手,用户可以通过调整定位,使其成为瑜伽好友、虚拟的流行人物、健身伙伴、创意写作指导甚至是微积分导师等,都不在话下。
Gemini 狂卷长文本,Gemini 家族再添新成员Gemini 项目自曝光以来,一直备受关注。起初也曾存在一定争议,但后来也凭借自身实力挽回了口碑,而今也越来越成熟。据皮查伊介绍,目前有超过 150 万开发人员使用 Gemini 模型,用户数量已经达到 20 亿,如今皮查伊再提「Gemini 时代」,目标是将其集成到所有产品中,为用户带来全新体验,也为创造者、开发者、创业公司创造新的机会。

目前最新的 Gemini 1.5 Pro 支持 100 万 token 文本量,今年晚些时候据称这个数字将会达到 200 万,能够同时处理 2 小时的视频、22 小时的音频、超过 60,000 行代码或超过 140 万个单词。此外,大会还宣布了基于 Gemini 1.5 Pro 的 Gemini Advanced,据称它可以处理「多个大型文档,总计最多 1500 页,或汇总 100 封电子邮件」,还支持 35 种语言和 150 多个国家 / 地区。
不得不说,在文本量方面,Gemini 确实很卷,「朝着将任何输入转为任何输出的目标迈出了一大步」。

安全永远是重中之重自 AI 诞生之初以来,关于如何辨别 AI 生成内容的争论就一直没有停止。Google 的对策是通过 SynthID,为 AI 生成的图像和音频添加不可见的水印,使其更易于区分,未来 Google 将会把这一范围推广到文本及视频中,并在接下来的几个月里,通过更新生成式 AI 工具包开源 SynthID 文本水印,帮助更多开发人员更轻松地负责任地构建 AI。

Gemini 融入其中后,Android 会在通话过程中,检测到可疑活动时发出警告,例如被要求提供您的社会安全号码和银行信息,属于是直接把「反诈中心」装手机上了。还有无障碍功能 TalkBack 也将通过 Gemini Nano 增强,图像描述将更加清晰和丰富,帮助视力不佳的用户通过语音反馈更好地操作手机,体现出 Google 一贯的人文关怀。

而对于 Google 今晚的表现,英伟达 NVIDIA 研究经理 Jim Fan 的评价,十分中肯。Google 新发布的模型似乎是多模态输入,但不是多模态输出的 Imagen3 和 Music AI Sandbox 仍然作为独立组件与 Gemini分离。将所有模态 I/O 原生合并是不可避免的未来。它可以执行任务,如「使用更机器人化的声音」「编辑这幅图像」「生成一致的漫画条带」。而且还不会在模态边界上丢失信息,例如情感和背景声音,全新模型打开了新的上下文能力,用户也能通过少量示例教导模型,并以新颖的方式结合不同的意义。
GPT-4o 并不完美,但它正确地掌握了形式因素,用安德烈的 LLM- 作为操作系统的比喻来说:我们需要模型本地支持尽可能多的文件扩展名。Google 做对了一件事:他们终于在将人工智能整合到搜索框中做出了认真的努力。Gemini 不必是最好的那一个,但却可以成为最广泛使用的一个。
本文由人人都是产品经理作者【爱范儿】,微信公众号:【爱范儿】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


