
 起点课堂会员权益
起点课堂会员权益推荐策略产品经理必知必会③:粗排、精排、重排模型
前两篇文章,我们分享了数据处理和数据召回的策略。数据召回后的下一个环节就是粗排,分为基于规则、基于模型两种。这篇文章,我们来详细说明一下。

一、粗排策略
召回的下一个环节就是粗排。粗排主要包括两类:基于规则、基于模型。
主要分以下三个步骤:
- 对召回的结果进行汇总去重
- 将去重后的结果输入粗排模型中
- 遴选出排名前几位的物料
1. 基于规则的粗排策略
如若召回策略都是基于规则或协同过滤的召回,那么每一路在返回时会有一个对应的归一化分数,先对所有召回路结果进行汇总去重,如果一个物料出现在多个召回路里,则将物料分数相加(加权汇总时可以为每路召回设置权重),最终按照总分倒排。
2. 基于模型的粗排策略
基于规则的粗排策略虽然简单,但是不够智能化。目前行业先进的解决方案是搭建专门的粗排模型,针对返回的物料进行初步的CTR预估,公式为:CTR粗排 = 曝光点击数/召回物料数。
3. 粗排策略效果评估
粗排策略效果评估有线上和离线两种方式。在进行线上评估时,可直接实施AB Test小流量实验,比较新粗排策略与旧粗排策略,关注推荐系统几个核心效果指标的变化。
在离线评估时,对于基于模型的粗排策略重点关注离线AUC指标(基于规则的也是),也可以对比粗排模型与精排模型返回物料与曝光点击物料的重合度,重合度越高,代表粗排效果越好。
二、精排策略
物料经过召回、粗排、过滤环节后才会进入精排模型,过滤环节多采用硬规则,入电商领域的无货过滤、未上架过滤、黑名单过滤等。
精排模型是整个推荐系统中最复杂的模型,也是耗时最多的模型,做策略产品经理工作的同学需要重点关注哦!
1. 学习目标
首先需要针对精排模型设定学习目标,在不同业务场景下,精排模型的学习目标不一样。
电商推荐场景:
大部分情况下,精排模型的核心目标都是CTR(曝光点击率),极少数情况为CVR(曝光转化率),主要看业务诉求。以京东和淘宝为代表的综合性电商平台,目前以预估CTR为主,精排模型正样本为埋点记录中被用户点击的商品,负样本为埋点记录表中曝光却未被点击的商品。
内容推荐场景:
以抖音、快手为例,精排模型全部采用多目标排序的方法,核心业务指标为DAU、用户使用时长。为了留住用户,需要为其推荐感兴趣的视频,也要让用户互动起来。关键在于增加用户使用时长,增加正向反馈,减少用户负向反馈。
正反馈指标:(显性)点/转/评/收藏;(隐性)观看时长、完播率、有效播放率等。
负反馈指标:(显性)负反馈点击、举报、负面评论;(隐性)短播放、停止浏览等
精排模型需要汇总指标,综合排序,排序公式为:
$$RankScore=a*P_播+b*P_赞+···+h*f(P_t)$$
应用分数计算公式时,应先针对每一个指标设置一个超参数,然后计算所有指标的加权结果,基于最终结果进行统一排序。
2. 算法选择
确定训练目标与训练样本后,接下来需要确定使用哪一种算法来进行学习。目前行业里的精排模型大多使用深度神经网络(deep neural network)算法,即DNN算法。
在预测CTR时也可以选择使用经典的LR算法,或者LR+GBDT算法。具体可以结合公司实际的系统架构和业务情况进行选择。DNN效果好,解释性差,对系统性能要求很高,线上部署会导致系统整体的时延很高,用户体验差。
如果使用LR算法预估CTR,主要工作是构建模型特征。如果使用DNN算法,一部分工作是构建模型特征,另一部分工作是设计神经网络结构,策略产品经理主要参与构建模型特征。
3. 特征构造
如果说召回的关键是样本的选择,那么精排的关键就是特征的构造。为了更好理解用户行为,会采用用户特征、物料特征、交叉特征等,接下来将以电商APP首页推荐场景为例介绍一些特征。
1)静态特征
- 用户特征:用户ID、性别、注册时间、是否会员、注册手机号、所在城市、职业、收入水平、婚姻水平等。
- 物料特征:SKU ID、一级类目、二级类目、三级类目、品牌名。
静态特征基本不会变化,能帮助模型理解用户和商品的一些基础信息。
2)请求特征
请求特征:请求ID(Request ID)、请求时刻(时刻、早中晚、日期)。
请求时间特征主要为了区分用户在不同季节、一天之中的不同时间的消费行为偏好。
3)用户基本画像特征
通过用户画像特征表了解用户消费能力、消费频次、类目偏好等,同时统计不同时窗下(如7、15、30天)用户的特征信息。也设置有比例衍生类特征,用于计算各个子类占父类的比例,最终通过该特征理解用户对各个子类的偏好度。
例:比例类衍生特征:上述各个一级类目的子项占该用户总订单、下单总金额的比例。
4)用户商品画像特征
用户商品画像特征表是对用户基本画像特征的进一步补充,有助于深层次理解用户对特定商品、品牌、类目等的偏好,仍需统计不同时窗下(如7、15、30天)用户的特征信息。
5)行为序列特征
上述特征基本属于用户的属性特征,而行为序列特征则指用户的动作行为特征,模型基于用户的历史行为序列来预测下一次行为。在现实生活中,人们在线上APP的行为具有强关联性,在模型加入行为序列特征后能使模型捕获用户的动态偏好。常见行为序列:用户点击序列、加购序列、下单序列、观看序列等。
例如,在构建一个点击行为序列时,首先需要定义一个序列长度,如4,则将用户浏览该物料前的最近4个物料批结在一起,形成一个点击行为序列。

6)交叉特征
在实际应用中,我们会将很多单个特征组合在一起形成交叉特征,通过特征组合更加全面地挖掘用户的兴趣偏好。User ID和SKU ID的组合特征是精排模型里面最重要的一个特征。
4.特征选择
完成特征构造后,就可以开始特征选择了。特征选择是指从众多特征中选择一个子集的过程。在实际应用模型时要考虑模型整体性能,选择最高效的特征集,主要选择方法有以下四种
1)业务经验法
策划产品经理和算法工程师基于对实际业务场景的理解进行特征构建和特征选择。此方法不需要借助模型离线效果评估,完全凭借人工经验和业务知识。
流程:特征选择(特征候选集——>特征子集)——>算法选择、模型训练——>模型效果评估
- 电商推荐场景:用户品类偏好、品牌偏好、消费力匹配等特征
- 内容推荐场景;用户视频类型偏好、视频题材偏好、视频时长偏好等特征
- 金融风控场景:银行征信报告的了结,需要咨询业务专家
优点:快速高效——可以快速构建一批价值比较高的特征,实现模型快速上线。
缺点:高度依赖人工,无法大规模复制——尤其对于金融风控等复杂度高的场景
2)过滤法
从特征本身以及特征和样本标签的相关性出发进行选择,也不依靠模型离线效果评估。关键在于:如何科学评估特征的价值,通常有如下两种方法:1.评估特征本身的相关指标。 2.评估特征和标签之间的相关性。
- 评估特征本身的相关指标
(1)覆盖率指标:特征能够覆盖样本中超过50%的数据时有价值
(2)方差指标:不同样本在同一个特征上的分布差异越小,代表该特征对样本的区分度越小。(注意统一量纲)
- 评估特征和标签之间的相关性
如果特征X和标签变量Y的数据类型不同,则采用的方法不一样。
若特征X为数值变量,标签Y也为数值变量,则用皮尔逊相关系数公式。
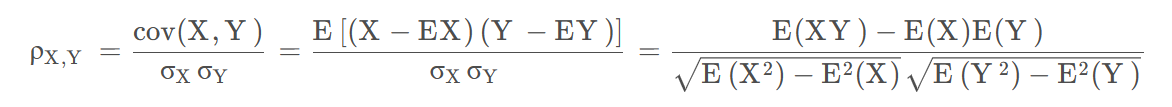
若特征X为数值变量,标签Y为类别变量,则用费雪分数。

若特征X为类别变量,标签Y也为类别变量,皮尔逊卡方检验。

3)封装法
以特征应用到模型里产生的实际效果为出发点进行特征选择的办法,不断挑选实验、循环反复。挑选特征组合的方法有两种:完全搜索;启发式搜索。
- 完全搜索:遍历所有特征,暴力计算,实用性不高
- 启发式搜索:
(1)序列前向选择:从空集开始添加,效果最优的留下,不断重复直至效果无法提升
(2)序列后向选择:从全量开始去除,效果最优的留下,不断重复直至效果无法提升
封装法的优点:最佳应用效果
封装法的缺点:时间成本高、选择流程长、计算量大
4)嵌入法
多种方法结合使用,伴随建模全过程不断基于模型效果实验特征组合。首先,分析单个特征对模型效果的重要性,分别基于单个特征建模,观察离线效果,基于特征重要性进行初步的特征选择和判断。
5. 特征编码
在实际建模时无法直接使用这些特征,需要进行特征编码。常用方法有三种:one-hot编码;分插编码;向量映射编码,主要构建元组、向量组进行编码。
6. 模型训练
主要分为三步:构建训练样本、基于训练样本进行模型训练、输出收敛的模型。
- 构建训练样本:小心数据穿越的问题。
- 基于训练样本进行模型训练:本质是通过数学计算的方式学习训练样本数据,最终得到一组收敛的模型参数w,主要使用梯度下降法,训练过程中可以加入正则项系数如L1、L2用于提升模型的泛化能力、防止模型过拟合。
- 输出收敛的模型:设定阈值,若P>阈值,则成立。
7. 效果评估与迭代应用
离线效果评估,一般构造多版模型,挑选离线效果最优的模型线上部署,主要验证模型在测试样本上的效果。对于分类任务来说,看AUC指标。
迭代应用也称模型的自学习,不会对算法和特征工程做较大调整,但会对新线上数据进行重新训练,替换旧模型。若要调整,则AB Test小实验等德国
以上就是构建精排模型的全部步骤,策略产品经理可以参与精排模型的主要工作是模型训练样本的挑选和特征工程的构建。
三、重排策略
重排策略一般要完成以下3项工作:
1.全局最优的排序调整:以淘宝为例,用户浏览是一个连续的过程,一屏内有4个商品,而精排模型返回的主要是最优单品,而不是最优组合,所以需要重新排列。
2.基于用户体验的策略调整:调整用户在APP前端实际看到的物料顺序,保证前端展示物料的新颖性、多样性。
3.适当的流量监控:和业务强相关的流量调控策略会部署在重排层,比如对某些物料的加权,常见的有对直播内容的加权、情人节对花卉等商品的加权等,这些策略只有部署在最后一层才可以实现直接调控。
1. 全局最优的排序调整
排序模型有三种优化目标:单点优化(point wise)、成对优化(pair wise)、序列优化(list wise)。精排模型的CTR预估实际上就是单点优化,不考虑上下文信息。成对优化和序列优化都考虑上下文信息,但是成对优化只考虑两个物料的顺序关系,重排模型的优化目标通常是序列优化(list wise)。
序列优化本身不是一个具体的算法或者模型,只是一个模型的优化目标或者损失函数的定义方式。序列优化关注整个列表中物料之间的顺序关系,主要分以下两个步骤:
第一步:序列生成
序列生成模型基于精排模型返回的商品数量进行排列组合,一般情况下从排序靠前的候选集中进行挑选。
第二步:对生成的序列候选集进行效果评估。
首先需要构建一个序列评估模型,目前序列评估模型中常用的算法是RNN(recurrent neural network,循环神经网络)。RNN模型的一大特点是以序列数据为输入,通过神经网络内部的结构设计有效捕捉序列之间的关系特征,非常适合作为序列评估模型来实现序列优化。
模型针对序列中的每个商品重新给出P(CTR),一般情况下只会对精排模型的CTR进行微调,不会大幅调整精排模型预估的CTR,最终选择综合CTR最高的序列返回App前端。
2. 基于用户体验的策略调整
主要包括两种:打散策略、多样性策略
1)打散策略
在电商推荐场景,需要针对同三级类目、同品牌、同封面图的商品进行大赛;在内容推荐场景下,需要针对同类型、同封面图、同作者的内容进行大三。目前主流的打散策略主要基于硬规则的打散,也有基于用户个性化兴趣的打散方式(容易出现UE问题)。
电商同三级类目商品打散,针对此类打散一般使用滑动窗口法打散,构建两个窗口,若符合硬规则则移动窗口,若不符合则按顺序替换,容易出现末尾扎堆的问题(末尾物料顺序无法调整)
2)多样化策略
向单个用户推荐多少种不同类目的商品,怎么样推荐才算符合多样性,这是由各平台自己决定的,一般由策略产品经理和相关业务方一起制定规则。实际应用时通常采用多种策略,观察实际线上效果,然后基于AB Test小流量实验效果进行讨论,最终在平衡业务诉求和实际线上效果的基础上确定一版最终策略。
多样性策略和打散策略最终融合在一起,变成一个多目标约束优化问题。为了方便省心,我们通常直接使用硬规则策略解决。
3. 适当的流量监控
流量调控策略只有一种,直接在重排层针对这部分物料进行相应权重的调整。但在实际落地中不仅要考虑CTR这一指标,在电商领域还要考虑转化率、曝光率、GMV、质量分等。对于内容场景,我们需要考虑视频的预估完播率、预估播放时长、互动率以及发布者账号的等级等。在最终排序时一般设置一个综合性的排序分数,具体排序公式可以自行拟定。
本文由 @策略产品经理规划 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pixabay,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


