
 起点课堂会员权益
起点课堂会员权益如何去评测一个大模型
做AI应用时,我们都会对个大模型进行分析评测,挑选出合适的。但大模型不是APP类产品,评测的方法肯定不同,这篇文章,我们就来看看作者建议如何评测。

一、权威机构评测
这是目前由国内C-Eval机构给出的国内大模型的评测排名。
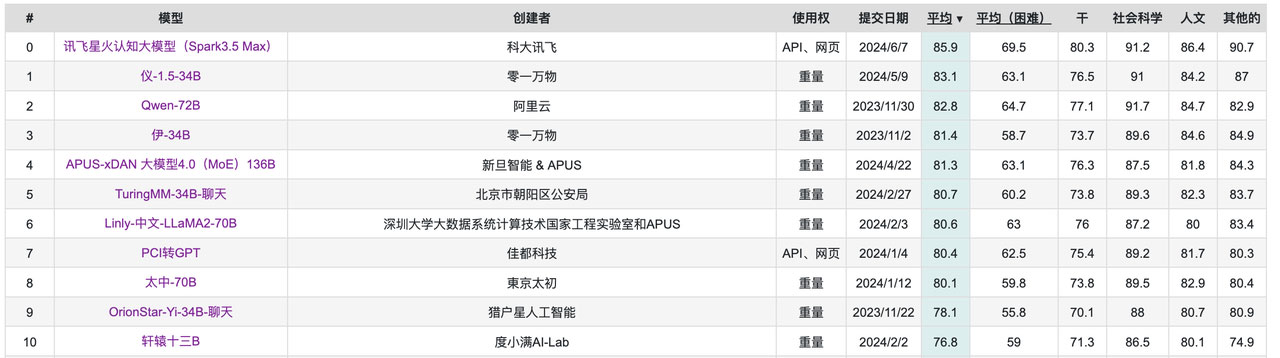
C-Eval 是一个全面的中文基础模型评估套件。由上海交通大学、清华大学和爱丁堡大学研究人员在2023年5月份联合推出,它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别,用以评测大模型中文理解能力。
那么像这样的机构或者是说大模型的公司,是怎样通过这么多的题目和学科去评测一个模型的好坏和使用好感度的呢。下面让我们来研究一下。
二、如何去评测一个模型
1、我们去评测模型到底是在评测什么呢?
我们说对大规模数据训练的大模型的评估,主要是评估模型的理解能力、推理能力和表达能力,以确保它能够在新的未见过的数据上有能够进行有效的工作和泛化能力。
2、如何评测呢?
我们去评测任何一个模型或是说任何一个模型的某一项能力的时候,并不是盲目去问问题看回答的。而是要先确定好一个评测标准,有了这些规则,我们才能根据这些规则标准去评测一些的模型的好坏,或者说模型的有效的工作能力才有了依据的标准。
那么,我们要去定义的规则标准是什么呢?
假如:我们评测模型的标准定义为:回答是否偏题、内容丰富度是否够丰富、逻辑是否正确、语意是否通顺、如果是书信问题格式是否正确、表达是否有冗余或者重复、是否遵循多轮的逻辑、回答的知识点是否有遗漏等等。
那有了这些基础的标准我们就可以根据这些标准来制定一些方案来评测模型了
1)给模型打分
我们可以把模型的回答定为4个分数
- 4分:完全符合规则。
- 3分:不完全满足,有点可以接受的小问题,比如标点符号之类的。
- 2分:不完全满足,有大瑕疵,但大意解释清楚了
- 1分:完全不满足,完全没有回答问题。
2)模型之间相比较
模型之间相比较的方式为 “GSB(good same bad)”:意思是人们从整体感知,评判为两个模型之间的优劣。
通俗来讲:G:就是good 也就是好的模型、B:就是bad 也就是坏的模型、S:就是same 一样好或是一样坏的模型。
这个方法适用于多个模型之间的对比
评测方法为:
模型A VS 模型B
A:如果A好,打A
B:如果B好,打B
S:如果一样好(或者一样不好),打S。
统计结果:
模型A :模型B = A好的数量 :S的数量 : B好的数量
比如,A : B = 25:30:55,B胜出
这两种方法是AI训练师在做模型训练时比较常用的方法。
3)需要注意的事情
在测评的时候一定要应客观公正,不能根据个人知识水平、立场偏好、回复长短等评测,这样会对回答失去公平性。
三、评测的数据集从哪里来
测数据集,可以客观地评估模型在实际应用中的表现。只有在评测数据集上表现良好的模型,才能认为其具有实际应用价值。然而获取数据集的渠道可以从以下几个方面来获得以及清洗数据:
公开数据集平台:
- C-Eval:C-Eval数据集主要用于评测大模型的知识和逻辑推理能力,即大模型是否能够认识和理解广泛的世界知识,并类似人类一样对事物进行推理规划
- GitHub:许多研究人员和开发者会在GitHub上共享数据集。
行业数据平台:
- 阿里云天池:阿里云提供的一个数据竞赛平台,提供丰富的数据集和竞赛机会。
- 京东AI研究院:提供一些公开的机器学习数据集。
学术研究:
- 研究论文:许多研究论文会附带数据集链接,可以通过阅读相关领域的研究论文获取数据集。
- 学术会议和期刊:顶级的机器学习和数据科学会议(如NeurIPS、ICML、CVPR等)和期刊(如JMLR、TPAMI等)通常会发布与研究相关的数据集。
API和开放数据接口:
- 一些开放数据平台提供API接口,可以通过API获取最新的数据。例如,Twitter API、Weather API、Google Maps API等。
最后,我们在选择数据集时需要考虑数据集的质量、规模、标签的准确性以及是否与评测任务相关。确保数据集足够多样化,能够涵盖模型可能遇到的各种情况,从而全面评测模型的性能。
本文由 @贝琳_belin 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


