
 起点课堂会员权益
起点课堂会员权益谷歌之后,OpenAI也要给新闻网站付费了?
大模型的发展离不开语料,但语料可不是凭空产生。在吞完免费内容后,付费的优质内容,必然成为大模型的选择对象,这样以来,就涉及到成本问题了。

近两年,大模型喷涌,它们在文字、图片、音视频等内容形态的生成上大放异彩。内容创作一直认为是人“独属”的技能,自OpenAI于2022年发布ChatGPT之后,众多大模型开始挑战一直被人类把持的这一独特技能。从初期惊艳心态“祛魅”后,大众逐步了解了这个新生事物的“创作原理”。
它需要先“吞食”海量的文字内容、图片内容、音视频内容,这些大数据先被高速分析和处理,在深度学习技术的推动下,大模型愈发像人一样可以创作文字、图片、音视频等多模态内容。包含社交娱乐到工作学习等场景的内容生成,能力越来越强的大模型,将深刻改变未来世界。
快速发展背后,大模型侵权问题频繁爆发。
01
今年4月末,包括《纽约每日新闻》和《芝加哥论坛报》在内的多家新闻机构在纽约的联邦法庭对OpenAI及Microsoft提起了法律诉讼,控告二者在未获授权下,利用其新闻稿件来教导生成型人工智能(AI)技术。随后,美国调查新闻中心(CIR)指控OpenAI和Microsoft使用版权材料来训练其人工智能模型。一份在纽约联邦法院提交的投诉声称,OpenAI未经许可或付款就利用了CIR的内容。
这让人不得不联想到十年前,美国众多新闻机构对谷歌搜索引擎的法律诉讼。其实,大模型自诞生就被看做搜索引擎之后,网民的全新信息获取工具,相比于后者,大模型除了提供精准信息,还可以直接“原创”文字、图片、音视频内容供用户使用。
如今,谷歌已经对非常多新闻机构“付费”,大模型或许也难逃这个结局,虽然OpenAI对此强调使用公开材料训练AI模型属于合理使用。
新闻机构和互联网巨头的较量,最早可追溯到2009年。
2009年,美国新闻集团旗下的《华尔街日报》新闻网站采取收费制,网友打开该网站部分新闻可浏览第一段,若想阅读全文就须付费。彼时这类收费新闻若由谷歌搜寻链接,却可阅览全文。
在“2009年有线电视展会”上默多克谴责谷歌,称搜索巨人正在窃取不属于自己的内容,因此呼吁内容所有者进行反击。默多克控诉:“我们还要让谷歌继续窃取我们的版权内容吗?不能再这样下去了。”
即使到了今天,新闻网站的优质内容,仍是谷歌等搜索引擎向用户提供优质服务的必要组成部分。搜索引擎在赚取大量财富的同时,新闻网站却成了谷歌们的“陪嫁品”。围绕搜索引擎是否应该向新闻网站付费的讨论,从美国蔓延到全球,从十几年前争议持续到今天。
漫长时间的较量下,现在谷歌向新闻机构付费已是一种常态化现象。
早在2020年,谷歌公司就对外宣布,当时已与全球约200家报道机构建立了合作关系,将开始一项推送新闻的新服务,未来3年,谷歌将支付10亿美元的新闻稿件等的使用费。
02
相比于,搜索引擎的索引“侵权”和广告垄断等拷问。大模型与新闻机构的较量更为全面,双方的矛盾也更为激烈。
要知道,全球新闻网站依靠谷歌带去的源源不断流量,尚能够通过广告服务、付费阅读等业务盈利。而大模型的服务机制中,超链跳转所占比例并不高,也就说服务大多在大模型产品内就结束,新闻网站从中更难获取利益。
这一次,率先对大模型开战的为《纽约时报》,2023年底该报对OpenAI以及Microsoft提起诉讼,指控后者未经授权使用该报版权内容训练AI模型,并在ChatGPT产品中呈现给用户。截至今年6月底,已至少有13家新闻媒体机构对OpenAI和Microsoft提起了侵权诉讼。
据新闻集团首席执行官罗伯特汤姆森所说“媒体的集体知识产权正受到威胁,我们应该大声要求赔偿。”新闻行业律师Steven Lieberman更是直言,OpenAI的巨大成功也要归功于其他人的工作,它在未经许可或付款的情况下获取了大量优质内容。
这类起诉并非只是存在新闻行业,大模型多模态发展,也引起其他行业企业和机构展开反击。
美时间6月24日,全球三大唱片公司索尼音乐集团、环球音乐集团和华纳音乐联合多家唱片公司,向AI音乐生成公司Suno和Udio开发商Uncharted Labs发起诉讼,指控后者非法使用版权音乐来训练模型并提供服务。
唱片公司指控Suno抄袭了662首歌曲,Udio抄袭了1670首歌曲,正在尝试索取每件音乐作品最高15万美元的赔偿费用。
国内也发生了类似事件,今年6月6日360 AI发布会上,360集团创始人、董事长周鸿祎在演示360AI浏览器的创新功能“局部重绘”时,选用了一张女性古装写真图片进行演示。两天后,ID为DynamicWangs的创作者在社交平台上发难,认为该图片是他利用AI绘图模型精心创作,并指责360公司未得到自己的授权。
内容创作行业,追“新”是一个特点,最新的思想、最新的事件、最新的言论、最新的图画风格或最新的视频模式。对大模型而言,如果缺了最及时信息的提供,必然会被用户吐槽提供的内容过时、传统,而想要追“新”,就难免和各种内容行业机构产生在“版权”方面的纠纷。
在去年《纽约时报》起诉书中就有这样一段内容,ChatGPT几乎逐字复制了其新闻报道。该报举例称,2019年,《纽约时报》发表了一篇荣获普利策奖的关于纽约市出租车行业掠夺性贷款的系列文章。该报称,只要稍加提示,ChatGPT就会一字不差地背诵其中的大部分内容。

来源:《纽约时报》起诉书
显然,一部分ChatGPT用户已把大模型当做了搜索引擎来使用。这种形式究竟算不算侵权呢?法律定义上尚有讨论空间,可随着大模型的大踏步商业化,类似拷问会层出不穷。就算当下版权法体系下算不得“大事”,可随着版权方的积极维权,也难免会有新的立法来杜绝这种现象。毕竟,新闻网站主要是靠流量和伴生的广告盈利,ChatGPT这种直接杜绝用户和新闻网站“链接”的方式,侵犯了后者的利益。
其实,现在包括美国和中国两个AI大国,版权法方面和AI相关的法律内容尚在探索中,但考虑到大量内容创作者依靠版权吃饭的现实中,大模型和内容版权的较量将是个长期问题,从新闻网站与搜索引擎的十几年较量历史中总结,大模型公司向内容方付“版权费”或是一个必然的结果。
03
内容版权方未来向大模型“发难”主要在两个层面,第一是训练AI模型时有没有用到我的版权内容;第二是输出的文字、图片、音视频内容有没有涉及侵权的地方。
大模型商业化必然要面临“版权”问题,以OpenAI最新发布的GPT-4o为例,该大模型能够处理50种不同的语言,相比过去版本提升了速度和质量,并拥有了可读取人情绪的能力。它接受文本、音频和图像三者组合作为输入,并能生成文本、音频和图像的任意组合输出,“与现有模型相比,GPT-4o在图像和音频理解方面尤其出色。”
它的应用场景非常丰富,包括实时翻译、会议报告生成、法律咨询、创意写作、虚拟客服等场景,包括实时语音和视频分析功能。且用户还可以和它聊天,通过提问获取最新知识,甚至一些人开发了和大模型恋爱的“赛道”。
除了生活场景,大模型会在越来越多商业场景中应用。这就意味着,虽然OpenAI宣布GPT-4o目前可免费使用(限次数),但用户只有付费才可无限使用。况且,商业化权限一直在OpenAI手中。
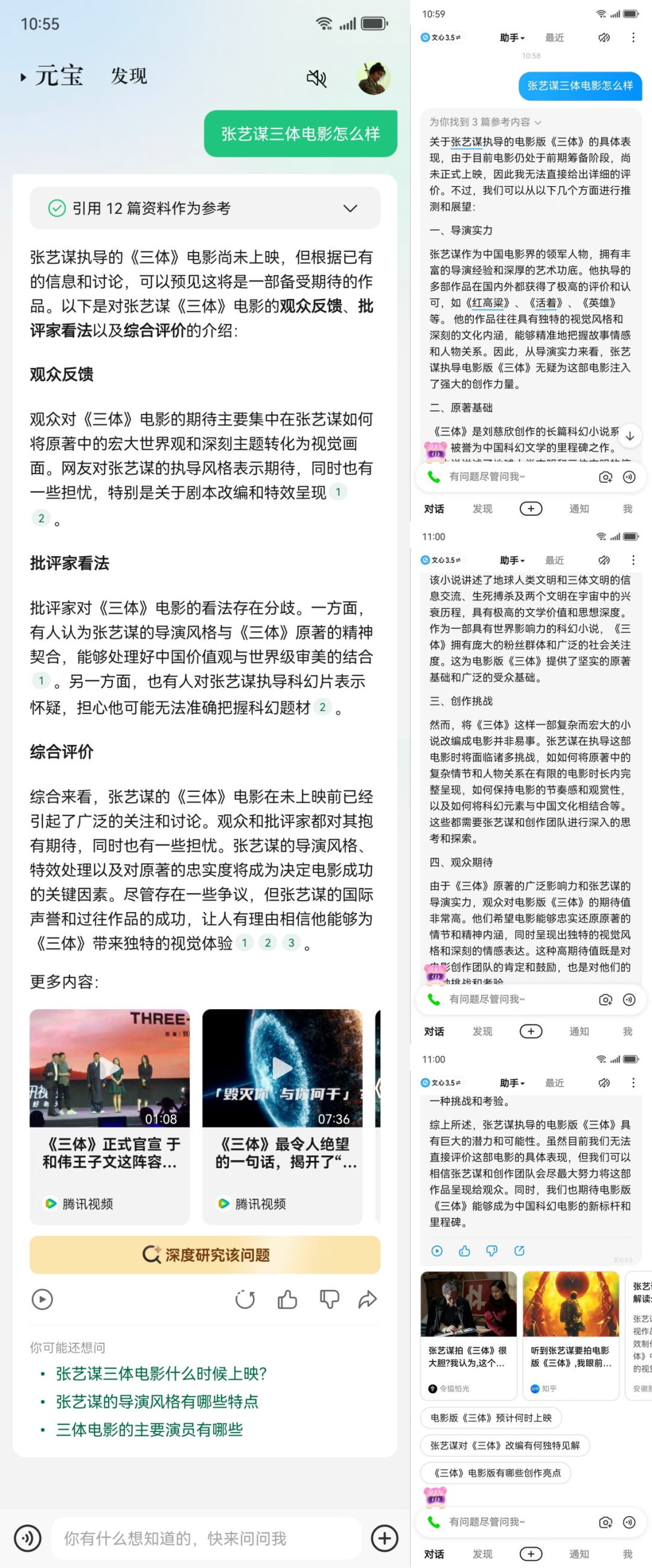
图片介绍:左腾讯元宝、右文心一言
由于国内无法使用GPT-4o,小编就用腾讯元宝大模型、文心一言大模型提问“张艺谋三体电影怎么样”这个热点。从腾讯元宝的答案中,每一个答案段落都有其引用超链出处。文心一言上的答案虽然未提供超链,但下方也有相关话题的超链接。
其实,大模型只是工具,输入某方面的内容,才具备输出相关方面“答案”的能力。要知道,内容创作的进化非常快,在大模型生活场景、商用场景中,想要能够随时提供最佳体验予以用户,必须要“喂食”最新的数据。而且,在用户需求下,输出的答案难免会“复制”新闻网站或其他版权方的内容。在大模型目前刚起步时期,这类矛盾还只是限于部分大的新闻机构和大模型公司之间,一旦大模型在日常生活中应用普遍化,这种矛盾将会进一步激化。
未来,这种围绕版权的纠纷会以什么样的方式解决?现在,已经很多案例发生,未来类似问题解决方式跳不出这些圈子。
围绕人工智能的法案正在出台,2023年12月8日,欧盟委员会、欧洲议会和欧盟成员国代表达成的《人工智能法案》(AIAct)。该法案明确提出,对于类似ChatGPT的通用AI系统(GPAI)以及相关的GPAI模型,提供方需要制作技术文件、遵守欧盟版权法、披露训练系统时使用的数据内容汇总。如果各企业和机构违反欧盟的AI法将面临罚款。
今年8月15日,由国家互联网信息办公室等七部门联合发布的《生成式人工智能服务管理暂行办法》正式施行,这是我国首个针对生成式人工智能产业的规范性政策,也是全球第一部人工智能生成内容管理办法。
监管机构将对违规行为进行相应处罚,今年3月,法国市场监管机构宣布,已向美国谷歌公司开出一张2.5亿欧元(约合人民币19.7亿元)的罚单,原因是谷歌未经同意使用法国出版商和新闻机构的内容训练旗下的聊天机器人“巴德”(其升级版名为“双子座”),违反了欧盟知识产权的相关法规。
谷歌因此成为第一个因为训练数据“侵权”被罚款的公司。有了这个前车之鉴,未来或有更多大模型企业会因为训练数据问题,遭受相关的管制。
对于大模型公司而言,如何和拥有版权的内容公司获得合作,将是未来重要的战略。今年6月份,《时代》杂志与OpenAI宣布,两家公司达成了一项多年内容授权协议和战略合作伙伴关系。该协议允许OpenAI将这家出版商的内容引入ChatGPT,并帮助训练其最先进的AI模型。
据悉,双方合作内容非常深入,OpenAI甚至能够访问《时代》过去100多年的档案和文章,以训练其AI模型,并在其面向消费者的产品(如ChatGPT)中用于回复用户的询问。
作为回报的是,OpenAI使用《时代》杂志的内容时会注明引用并链接原始来源。《时代》杂志将可以使用OpenAI的技术,以便为其受众“开发新产品”。
无论怎么说,原创内容是互联网高速发展重要的支柱之一。过去,新闻网站、音乐公司、版权商和谷歌搜索引擎展开的十几年“版权战争”,将会在大模型领域重现,且斗争程度要远超过前者。
任何一种技术的繁荣,都不应该建立在“巧取豪夺”之上。大模型企业或可以用提高与新闻网站等内容机构的合作门槛,增加自身的竞争护城河。
目前来看,大模型没有办法由0变100。作为大模型“养料”供给方,内容原创者或机构,也完全有理由,从大模型蓬勃发展中获取合理的利益。
引用文章:
财联社《巨大压力之下谷歌放弃“吃独食” 承诺未来三年向出版商支付10亿美元》
每日经济新闻《13家媒体怒告OpenAl等AI巨头背后:内容创作为何成了大模型的“免费午餐”?》
观察者网《欧盟内部市场专员:欧盟达成“历史性AI立法”,成首个制定AI明确使用规则的大陆》
四川观察《谷歌被罚2.5亿欧元,AI训练数据版权问题再引争议》
财联社《OpenAI与《时代》杂志达成合作协议,将用其内容训练ChatGPT》
专栏作家
师天浩,微信公众号:shitianhao01,人人都是产品经理专栏作家。科技自媒体人,曾就职于博客中国、互联网实验室、百度等公司,曾在《南方都市报》《计算机应用文摘》等报纸杂志刊文。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


