
 起点课堂会员权益
起点课堂会员权益大模型真的在吞噬人类的一切数据吗?
随着大模型对数据的大量需求,人们开始担忧数据资源是否会被耗尽。本文将探讨大模型是否真的在吞噬人类的一切数据,以及这一现象对AI未来发展的潜在影响。

在弗兰克·赫伯特的《沙丘》中,沙漠星球厄拉科斯的沙丘下隐藏着一种无价之宝:香料。
这种神秘物质使太空旅行成为可能,能延长寿命,并具有扩展意识的效果,是宇宙中最宝贵的财富。“谁控制了香料,谁就控制了宇宙”。正如香料在《沙丘》宇宙中占据着至关重要的地位一样,在当今的生成式人工智能时代,数据也承载着类似角色。
就像《沙丘》中对香料的争夺,现实世界里各方势力也在为数据资源展开激烈角逐。海量的数据如同埋藏在数字世界沙丘下的“香料”,蕴藏着难以估量的价值。而那些能够高效采集、管理和利用数据的企业,就像小说中控制香料的势力,在这场数据争夺战中占据着优势地位。
如同香料在《沙丘》宇宙中的供应并不是无限的如果开采过度或生态系统受到破坏,香料的产量可能会大幅减少甚至耗尽,数据也可能被耗尽。根据非营利研究机构Epoch AI的最新论文,大语言模型会在2028年耗尽互联网文本数据。
大模型真的在吞噬人类的一切数据吗?我们是否正处在一个看似无尽的数字香料狂潮中,不断地向这些饥渴的大模型提供养分?
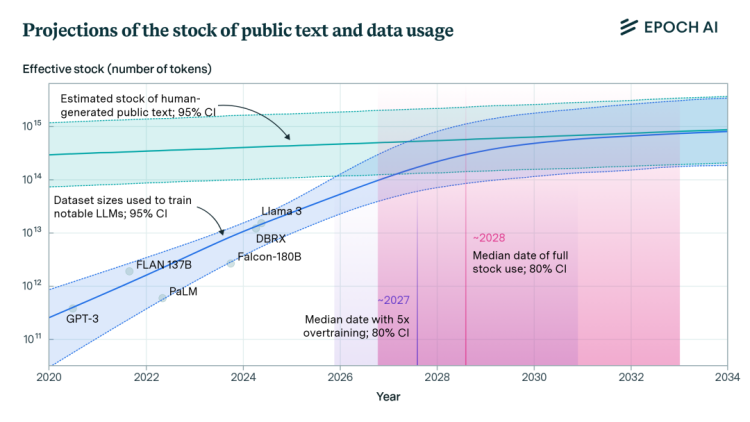 预计在未来几年内可能会耗尽现有的公共文本数据存量
预计在未来几年内可能会耗尽现有的公共文本数据存量
人类生成的数据量有限,一旦这些文本数据被耗尽,可能会成为约束语言模型继续扩展的主要瓶颈。相关论文认为,语言模型将在2026年到2032年之间利用完这些数据,但如果考虑到利润最大化,过度训练数据可能会导致数据在2025年就被用完。
月之暗面创始人杨植麟也在近期表达了类似观点,他认为大模型通向AGI最大的挑战是数据。杨植麟表示,“假设你想最后做一个比人类更好的AI,但可能根本不存在这样的数据,因为现在所有的数据都是人产生的。所以最大的问题是怎么解决这些比较稀缺、甚至一些不存在的数据。”
根据Epoch研究员Pablo Villalobos的观点,OpenAI在训练GPT-4时使用了大约1200万个token,GPT-5需要60到100万亿个token才能跟上预期的增长。关键在于即使用尽互联网上所有可能的高质量数,仍然需要10万到20万亿token,甚至更多。
面对如此庞大的数据需求,合成数据也是一个学术界和产业界都在尝试的重要方向。合成数据基于现有数据进行扩充,这种能力对未来的训练数据规模至关重要。不过,用AI生成的数据进行训练也存在一些局限性,例如可能导致模型崩溃等问题。
目前,大模型厂商主要从网络上抓取科学论文、新闻文章、维基百科等公开信息来训练模型。从长远来看,仅依靠新闻文章和社交媒体等内容可能无法维持人工智能的发展需求。这可能迫使企业开始利用一些敏感的私有数据,如电子邮件、聊天记录等,或不得不依赖于聊天机器人自身生成的质量不高的数据。
一、数据不够用是“杞人忧天”?
没有数据就无法训练大语言模型,但数据真的不够用了吗?对于这一问题,也有人持有不一样的观点。
星环科技孙元浩认为,这是一个“假新闻的判断”。在他看来,除了现有互联网的存量数据,各个企业内部还有大量的数据没有被利用,“现在数据多到远远超过模型可以处理的量”。
“大模型结构和训练方法都不是秘密了,而语料散落在各种地方,需要把现有语料整理起来训练或微调模型,工作量非常巨大,这是目前最大的挑战。”孙元浩告诉硅星人。
其中的一个重要问题,是数据处理范式从结构化数据到非结构化数据的转变。结构化数据,例如数据库中的表格数据,有明确的字段和格式,易于存储和查询。而文本文档、合同协议、教材等非结构化数据,虽然包含丰富的信息和知识,但由于缺乏统一的格式,难以直接存储和检索,企业内部的非结构化数据往往也需要更专业的数据标注处理。
为此,星环试图通过提供包括语料处理、模型训练、知识库建设在内的工具链,提升企业的数据处理能力。“我们意识到不可能一个模型通晓各个领域,企业核心机密是不可能让你知道的,我们定位为提供工具帮你做训练,你自己炼一个模型。”
挖掘企业内部数据重要性的另外一个例证是摩根大通拥有150PB的专有数据集,而GPT-4仅在不到1PB的数据上训练。不过两者的数据在质量、类型和用途上存在显著差异。大模型面临的挑战主要在于获取高质量、多样化且合法可用的训练数据,而非简单的数据量不足。
对于“数据荒”,数据服务商景联文科技创始人刘云涛也表达了类似观点。“我们现在真实数据都来不及处理,数据不够是杞人忧天了。”他向硅星人表示,“我预估洗完之后,中国的高质量数据大概是有150TB,世界上还有很多个国家。”
他认为目前存在的问题主要在于高质量的数据的问题,涉及到数据清洗、数据工程。
刘云涛表示,大模型时代的核心变化首先是数据量变大了,“以前一个题库10 万、20万道已经很大的项目。现在以亿为单位,技术处理能力就变得非常重要了,因为你不可能靠人工。”
第二个变化在标准环节,需要引入专业领域的人工标注,“原来人工标注和自动化标注是一个平行的关系,那现在更像是技术标注放在前一轮,后一轮是专家级的标注。”
专家级标注指的是一种更高级别、更精细的人工标注过程,这种标注工作通常需要专业知识,能够对自动化标注的结果进行校正和优化,以确保数据集的高质量。与此前的用低成本劳动力完成的简单数据标注工作也有所不同。据称,OpenAI内部就有一个几十名博士级别的专业人士组成的团队来做标注。
大模型厂商在处理数据时遵循的流程通常包括几个环节:首先,数据从各渠道获取被获取后,进入数据工程部门。数据工程师会对数据进行清洗和预处理。接着,处理好的数据会被交给算法部门,算法部门会利用多种方法进一步处理,包括调参、通过监督学习对模型进行微调(SFT),以及使用人类反馈来强化学习模型(RLHF),经过这些步骤处理后的数据,最终会被应用到具体的任务或产品中。
在这一过程中,大模型厂商的核心的需求是从分布在各处的数据中提炼出可以用于微调、训练或持续优化模型的高质量数据。
Scale.AI专注于为企业客户提供训练数据的数据标注开发。该平台采用自动化标注、半自动化标注和人工审核等先进技术,提高标注的速度和准确性,并提供数据管理和质量控制工具。
在刘云涛看来,Scale.AI的核心不在于有很多数据,而是拥有快速处理数据的能力。“Scale AI建立了一整套数据清洗的流程,另外还建立了一套数据引擎,能形成真正的数据飞轮,这是个流程性的技术的问题。”
二、开源数据的困境
大语言模型之所以能够展现出惊人的理解和生成能力,是因为从海量的预训练数据中学习了丰富的世界知识。而开源数据,如网页、书籍、新闻、论文等,正是这些预训练语料的重要来源。通过开放共享,开源数据为模型提供了广泛而多样的知识来源,使其能够学习到人类社会的方方面面。可以说,没有开源数据的支撑,大语言模型就难以获得足够的“知识养料”来实现快速发展。
由社区和非营利组织推动的开源数据项目,为语言模型的训练提供了丰富多样的语料,对推动了自然语言处理技术的发展至关重要。智源研究院林咏华告诉硅星人“如果没有Common Crawl,整个大模型的发展都会延后。”
她也指出了一个相关的问题,国外志愿者参与的开源数据集的建设,如BookCorpus、古腾堡工程都积累数年时间,而在国内很少有人做类似的事情,这就造成了中文数据的数据孤岛问题。
人工智能开源开放数据平台OpenDataLab相关负责人告诉硅星人,数据资源持有方普遍存在的一个顾虑是无法明确数据开源行为对自身的价值,单纯的数据开源对于中小型企业很难形成短期的回报。“从投资与回报角度看,企业如果开源模型,其带来的技术的迭代和创新,对企业来讲无疑是一种回报,而开源数据则几乎是纯‘利他’的行为,很难有实际的收益。”
因此,相较于国外由非营利机构推动,国内各类事业单位在推动数据开源的过程中扮演了十分重要的角色。不过,随着用户规模和数据需求的增长,也为各类数据开源社区的资金与存储等带来了现实挑战。
OpenDataLab从公开数据收录、开源平台建设、数据工具研发、高质量原创数据集发布、生态合作等多方面入手,正在着手推动解决研究和开发中数据需求。
OpenDataLab表示,中文大规模数据集在开源程度、规模以及质量方面与英文数据集相比存在差距,这在一定程度上制约了中文自然语言处理技术的发展。目前OpenDataLab已经联合多家机构,发布了一系列原创高质量的大规模AI数据集,他们也希望能与更多机构一道,通过合作来邀请更多人参与到数据开源事业中来。
在公共数据开放和社会力量方面,中国与美国存在一些差异,美国政府在公共数据开放中扮演着重要角色,致力于“应开尽开”。政府建立专门的AI训练数据开放平台,对数据进行标识、清洗、标注等处理,并提供便捷的检索和接口服务。社会力量则整合政府开放数据与网络公开数据,以开源为主形成高质量训练语料,并在行业大模型中贡献专业性。
中国的公共数据共享和利用程度上仍有不足。部分领域如天气、司法的数据开放不如美国充分,在开发利用中也缺乏API支持。社会力量主要结合海外开源数据和国内网络公开数据形成训练集在行业大模型中,社会力量虽有贡献,但受限于专业门槛高、企业共享意愿低、公共数据开放不足等困难。
三、数据采集中的“灰度”
生成式人工智能的发展主要依赖大模型以及对大模型的数据训练,数据训练又离不开大规模的数据爬取。数据采集是产业链的起点,涉及从互联网、社交媒体、公共数据库等多个渠道收集原始数据。这一环节需要遵守数据隐私和版权法规,确保数据来源的合法性。随着技术的发展,自动化工具如网络爬虫被广泛使用,但同时也带来了数据隐私和安全等问题。
五号雷达相关负责人童君告诉硅星人,数据爬取方面,Robots协议在网络数据获取是一种行业内的约定俗成。不过Robots协议遵循基于爬虫的自觉性,并不能从根本上阻止数据的获取。“这个行业水下的产业占80%,比如场外项目制的数据购买,数据进行二次加工之后,源头的数据是来自于哪里?这个东西没办法追溯。”
景联文创始人刘云涛则建议从“灰度”的角度来看待这个问题,“一个全新的行业,无论从国家到企业、个人都在探索,一定是有灰度的”。他认为,在大数据和人工智能的新兴行业中,存在着一些灰色地带,主张应该用技术手段将灰色地带变成白色,合法合规。
景联文用技术手段如SFT或人工标注,将获取的数据转化为可交付使用的数据,建立高质量大模型训练数据集。他打了个比方,就像“别人在野地里采摘的白菜,经过他们的加工,变成了预制菜。”
随着数据被定义为新的生产要素,全国各地纷纷成立了大量的数据交易所和交易中心。成为解决行业内的灰色地带问题,提高市场参与者的安全感的一种新的机制。
截至目前,国内已成立了超过40家数据交易所,包括上海数交所、贵阳大数据交易所和北京国际大数据交易所等。这些交易所通过搭建数据要素流通平台,提供数据供需对接撮合机制,以释放数据要素的价值。
刘云涛认为,数据交易所是一个显著中国特色的新兴市场,但建立一个有效的数据交易体系还需要大量的工作来完善。“能不能真正解决数商和购买方之间的问题?如果交易所只是让我们付出,不能给我们带来收益,那就没有意义,这个事是需要时间的。”
五号雷达童君也表示,“大模型厂商基本上不会去交易所买数据。不是说今天我来做大模型,然后买一堆数据回来。”
据介绍,数据交易市场目前存在多种模式。有的大公司建立了平台,提供数据产品和数据集,主要以API形式供企业购买服务。此外,还存在针对特定项目的定制化数据购买模式。在这种情况下,买方了解数据的来源(如气象局)。并直接与拥有数据的机构或企业进行交易。
四、“是时候把数据Scale Down了”
LLaMA3通过将训练数据从2T增加到15T,即使模型架构保持不变,模型性能得到了显著提升,然而,这种“暴力扩展”的方法虽然有效,但也面临着边际效应递减和资源消耗增加的问题。
语料规模并非越大越好,而是高信息密度的语料规模越大越好:Common Crawl是400TB的数据集,包含了互联网上数十亿网页,内容非常广泛但未经清洗。而C4则是对CC进行了过滤噪声、重复内容等清洗后的305GB数据集。经评估发现基于C4训练的模型性能优于CC,这既说明了数据清洗的重要性,也说明了语料规模不能一味追求大。
近期,DCLM项目组,从Common Crawl中成功提取并清洗出240T的数据,也为数据规模增加的可行性提供了新的证据。这一进展为数据的“Scale Up”策略提供了支持,但同时也提醒人们注意到数据处理和清洗背后的计算成本。

清华博士秦禹嘉表示,前scaling law时代我们强调的是scale up,即努力追求数据压缩后的模型智能上限,后scaling law时代大家比拼的是scale down,即谁能训练出“性价比”更高的模型。
例如,PbP团队利用较小模型的性能评价来过滤数据,从而提升大型模型的训练效果和收敛速度。类似地,DeepSeek通过使用fastText来清洗高质量数据,为特定场景下的模型训练提供了优质数据。
这些研究成果暗示,通过彻底优化数据的质量,小型模型的训练效果可以接近或等同于使用大规模“脏数据”训练的大型模型。这不仅示范了数据清洗在提升模型效率中的重要性,也说明在某些情况下,模型的参数规模并非越大越好,关键在于如何有效地利用每一份数据。
随着AI领域的不断发展,这种对“效率”和“质量”的追求正在成为研究和实践中的新趋势。未来,数据处理的方法,包括数据去噪、改写预训练数据等策略,将成为推动大模型发展的关键因素。同时,这也意味着数据质量可能成为衡量AI模型性能的新标准,而不仅仅是数据规模。
在当今快速发展的人工智能领域,数据成为了推动技术前进的基石,它的角色越来越像《沙丘》中珍贵的香料——无处不在,价值巨大。随着对数据需求的增长,如何有效地收集、处理和利用这些“数字香料”成为了关键问题。从提高数据质量到拓宽数据获取渠道,未来的AI发展不仅取决于我们如何应对这些挑战,更在于我们如何在数据的海洋中探寻新的可能。正如《沙丘》展示的那样,真正的力量来自于对这些资源的理解和利用——谁解决好了数据问题,谁就拥有了未来的钥匙。
《沙丘》中的领航员通过食用香料获得了预测未来的能力,人工智能算法通过处理大量数据集,发现模式和趋势。在《沙丘》宇宙中,人类在香料混合物的影响下进化,获得新的能力并经历意识的重大飞跃。同样,人工智能乃至AGI的发展也可能会为人类带来类似的深远影响。
只不过如果知道十年前在社交媒体上发布的内容,有朝一日会成为推动技术进步的“香料”,或许我们会更加慎重地对待自己的数字足迹。
作者|周一笑 邮箱|zhouyixiao@pingwest.com
本文由人人都是产品经理作者【硅星人】,微信公众号:【硅星人Pro】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


