
 起点课堂会员权益
起点课堂会员权益数据分析工具:Pandas架构分析
在工作中,我们一般用excel或者SQL来处理和分析数据,本文分享了Pandas框架,给出该工具的使用方法,供大家参考。

以往数据分析常使用的工具是excel和sql,用这两个工具做过大数据分析的网友都能感受到那种痛苦,本文对Python的Pandas大数据分析工具做架构分析,以方便掌握该强大的工具。
本文的架构分析是通过阅读pandas中文出版物教程、互联网搜索、代码验证的基础上得到的结构猜想,并没有深入源代码分析,实际架构与本分析可能略有出入,请知悉。
1. 结构概览
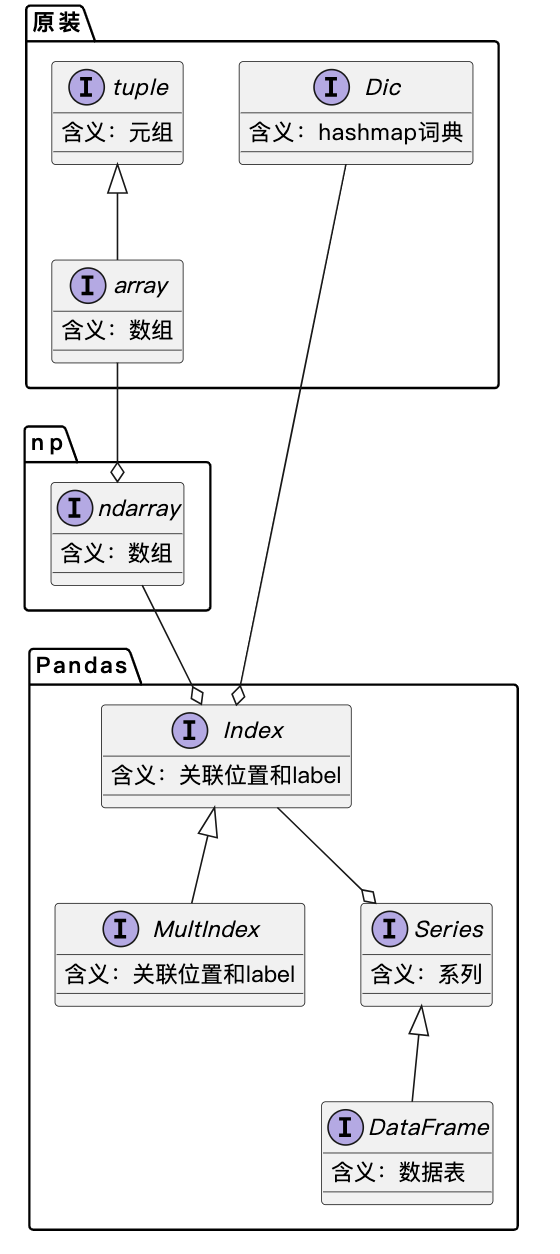
Pandas就是数据容器,容器好不好用,不仅取决于容器能装多少东西,更取决于,取出来是否方便。Pandas的Series和DataFrame作为数据容器就像一本书。
- 数组容器:就是这本书只有页码。如果书本不超过几百页,或者使用的很少,使用起来并没有问题,如果书本有十万页,频繁找东西时肯定就麻烦了。数据分析就像在几十万、几百万页的书本里,找数据,只有页码是不够用的。
- Index容器:Index是对数组容器页码的拓展,在原页码的基础上增加了文本描述,读者对频繁使用的章节可以夹个标签。Index容器有很多子类型,可以简化索引的使用,如:DatetimeIndex、PeriodIndex、IntervalIndex等
- MultiIndex容器:是对Index容器的组合,不仅支持一层便签,可以支持任意层便签,通过该容器可以实现目录管理。
Series是一列数据值,DataFrame是N列数据是,是N个Series的组合。Series和DataFrame从容器的角度,主要拓展的是索引部分,两者的分为index和values两部分,其中index是索引,有复杂的各种实现类。values仍是ndarray类型。
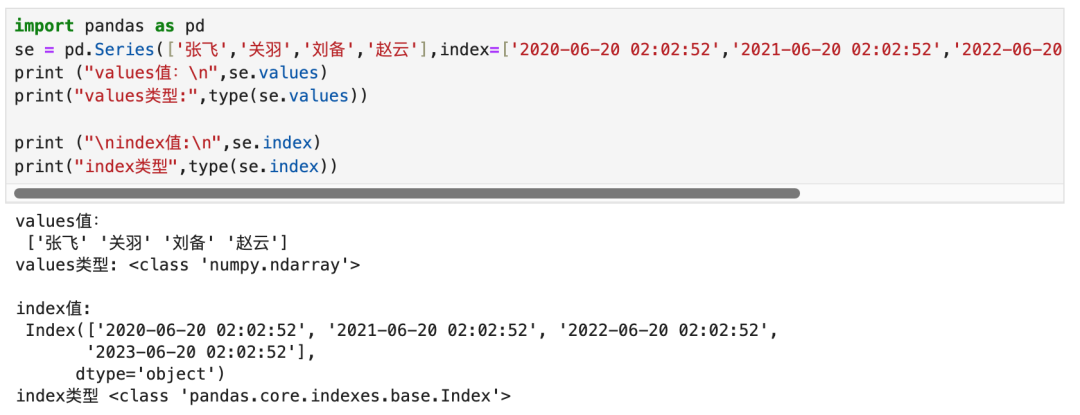
2. Series
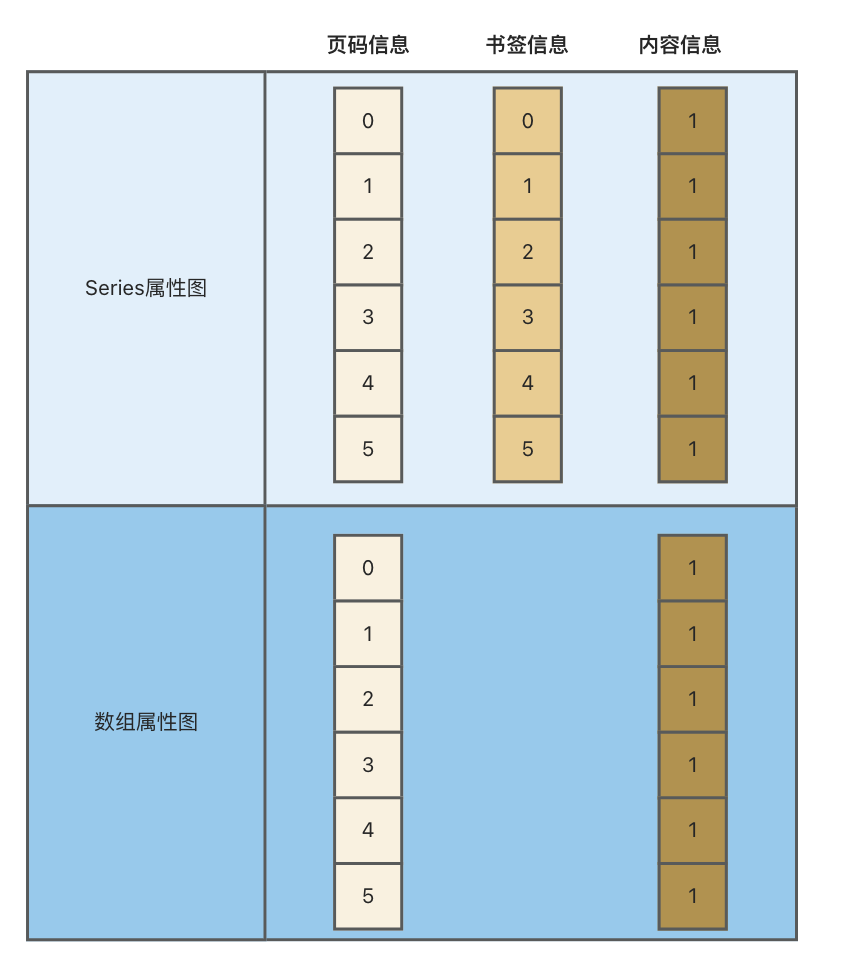
Series是对数组的封装,比普通数组新增index的属性。不考虑MultIndex的场景该图是准确的,考虑MultiIndex,书签信息可以有无数列数据。
2.1 数据初始化
Series的两列位置信息,页码信息是系统自动编码,无法人工介入。书签信息是手动编码,可以指定也可以不指定。
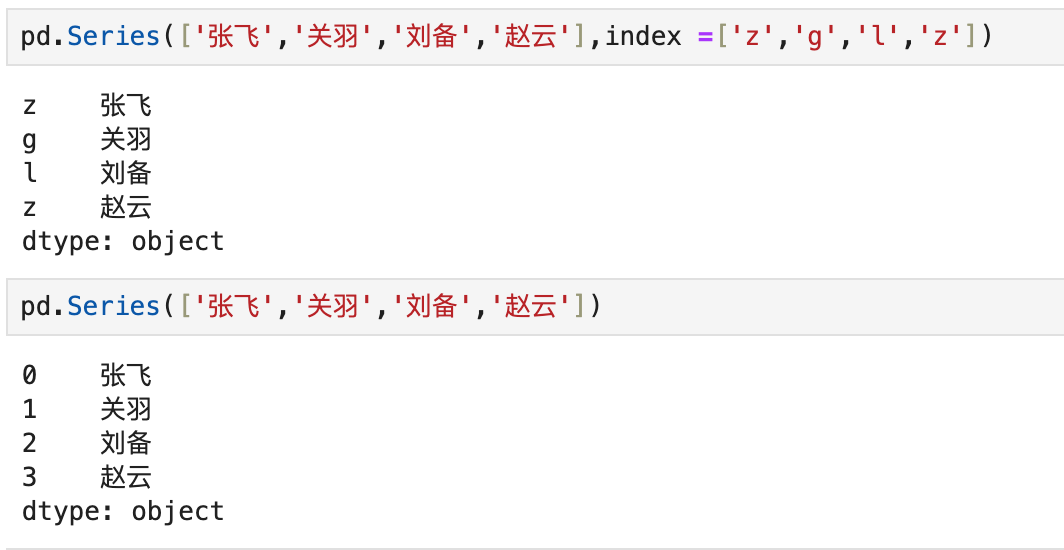
索引列和对象可以单独起名字。value没有名字

2.2 通过Index定位值
数组支持按位置访问,比如s[1]
Series支持按位置和按index访问两种方式。
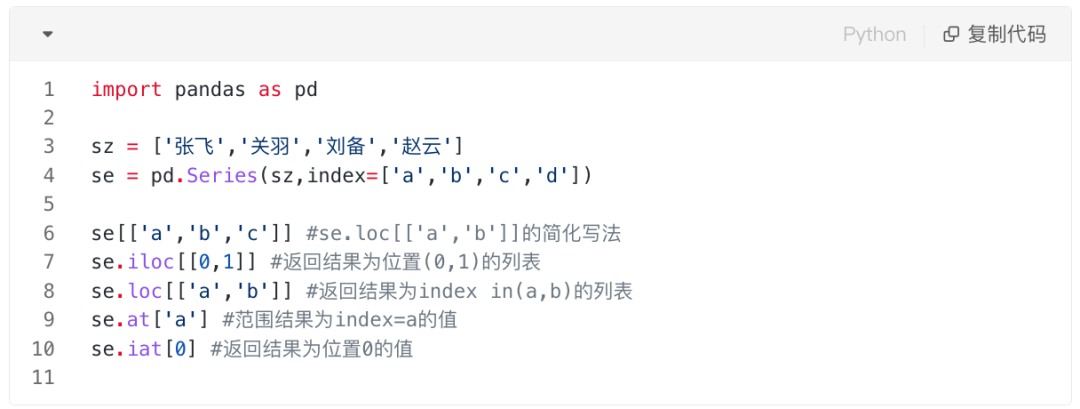
- Series传入的标签参数可以换算为位置信息。
- loc和iloc返回值是向量
- at和iat返回值为标量
位置信息的使用,用SQL表达就是:from 原表 where index.loc in() or index.lable in()
2.3 通过值定位Index



- 函数返回值为bool类型的Series
- 要得到index值或者数据向量,需要再调用一次se.loc[]
此处函数的使用,用SQL表达就是:from 原表 y left join BoolSeries yi where y.index = yi.index and yi.value =True
2.4 MultiIndex构建
Index和MultiIndex都是数组,数组的个数=数据的行数。Index数组的元素是标量数值。MultiIndex的数组元素是元组,可以是二元组、三元组、四元组等。
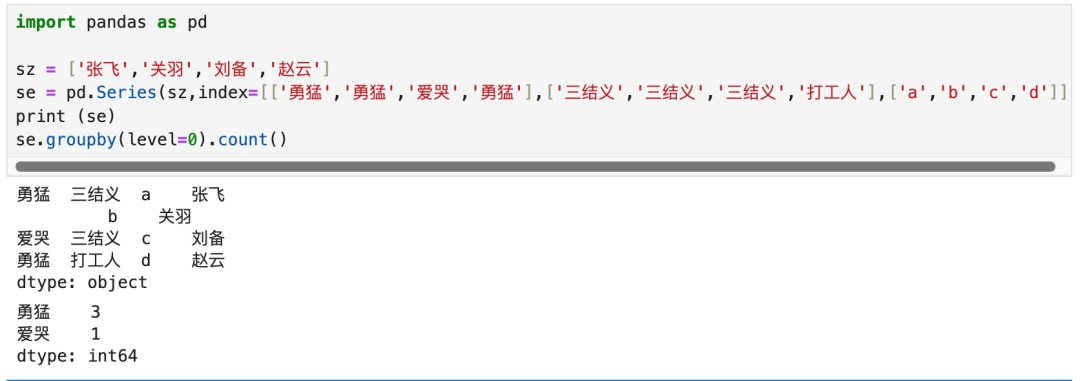
这里的目录操作,也是人工智能算法打标签的地方,打好标签就可以分群,就可以推荐了。
对于Series由于只有一列数据,所有列的层级就没有建目录的功能,DataFrame有此功能。
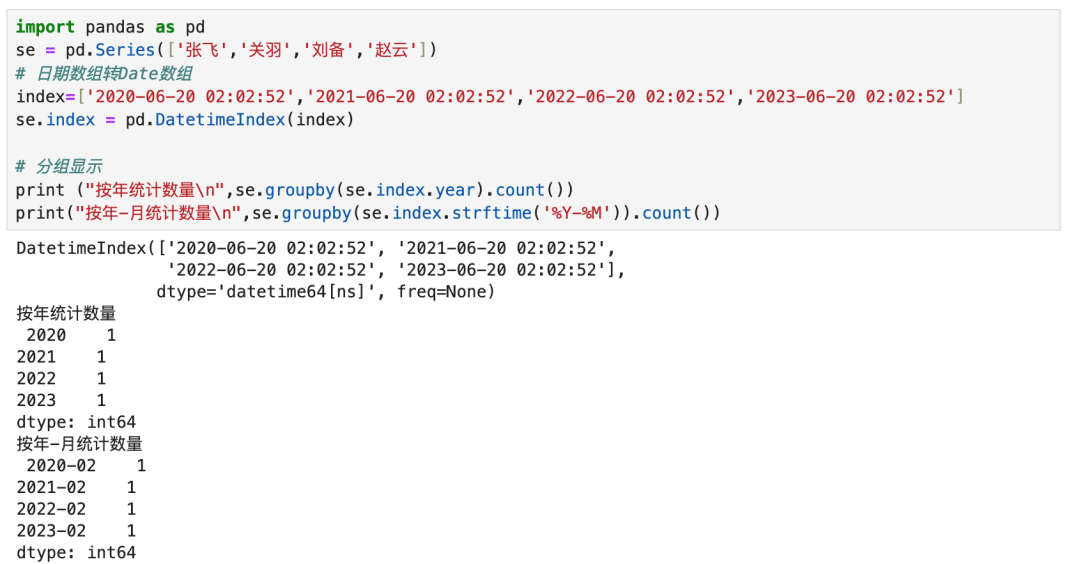
2.5 时间构建目录
时间可以按年、月、日、时、分这五个维度构成一个目录层级结构,可以用目录实现。直接使用DatetimeIndex对象构建:
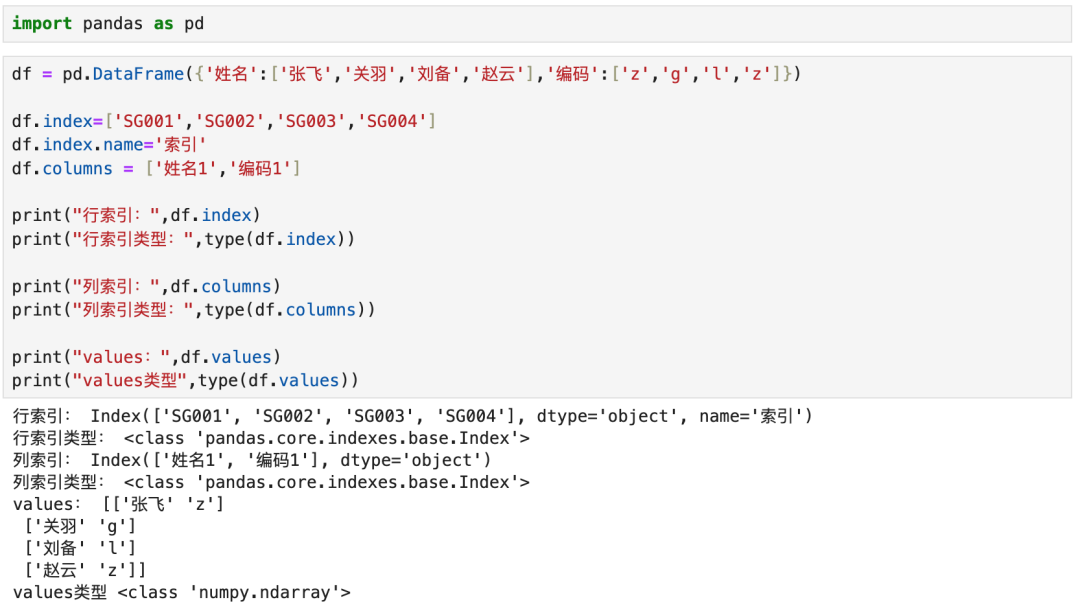
3. DataFrame
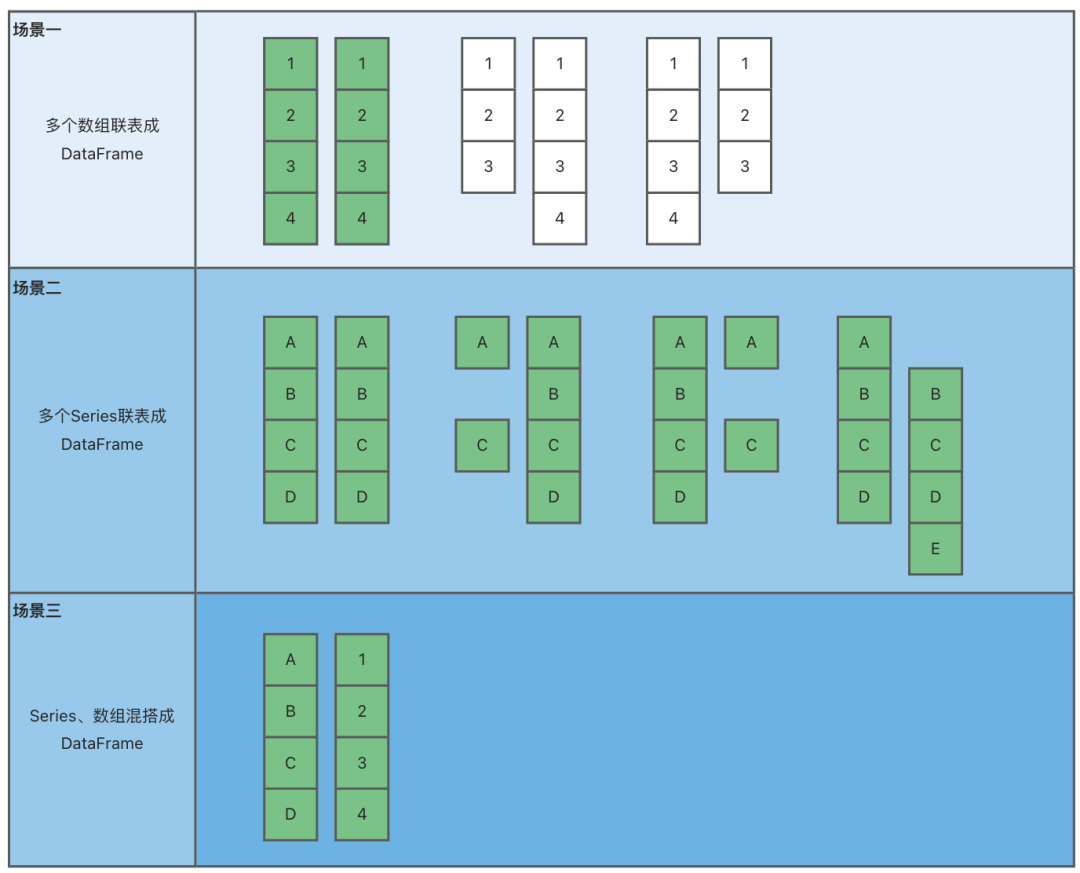
DataFrame是有多个Series或数组联表而成的组装表。
Series和数组的组装方式分为三种场景,每种场景有几种存在的组合,如图,绿色的组合场景是合法的,白色的组合场景是非法的。
3.1 多个数组合并
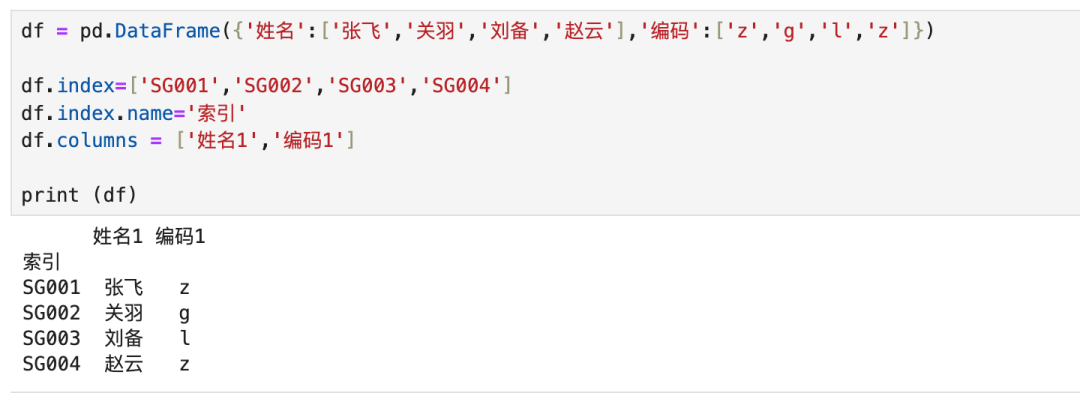
数组和DataFrame的维度信息对照:
- 数组是有序的,所以有位置信息,位置信息是隐含的。隐式对应于DataFrame的index属性。
- 数组是有值的,所以有数值信息,数值信息是显式的。显式对应DataFrame的value属性。
数组和DataFrame的存储值对照:
- 数组的值存储的是地址,所以数组可容纳数值、字符串、对象等任意类型。
- DataFrame每列存储的类型是固定的,所以DataFrame组装时,会自动转换数据类型。
组装关系用SQL表示为:

原则猜测:
之所以数组组装要求严格,是因为数组本身很灵活,数据清洗程度低,数据脏乱差的概率更大,所以此处严格校验,可以降低数据错误的风险。
3.2 多个Series合并
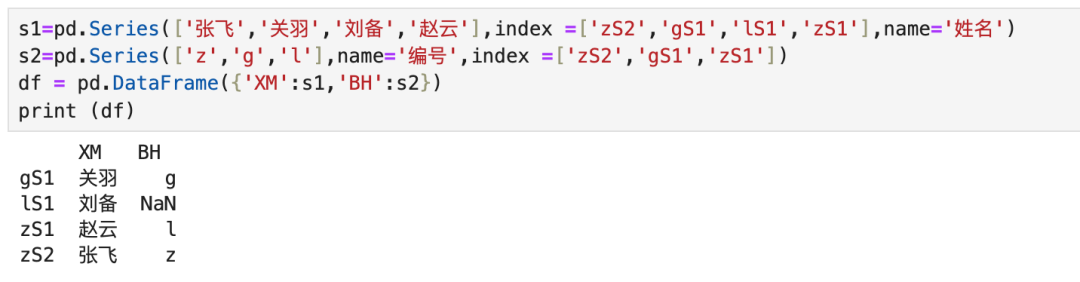
多个series组成DataFrame实际执行的是连表操作,效果等同于Sql语句的全连接。
3.3 Series和数组合并
只要有数组存在,就必须完全对齐,索引列使用Series的索引列。系统默认Series和数组的索引列按照所在顺序建立联表关系。
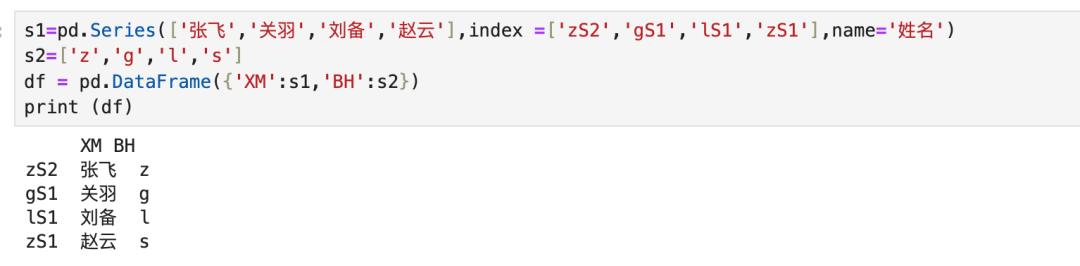
当Series和数组组成DataFrame时,按照从严法则,必须上下对齐。
4. 数据分组
分组是根据索引将数据聚合,两种方法:
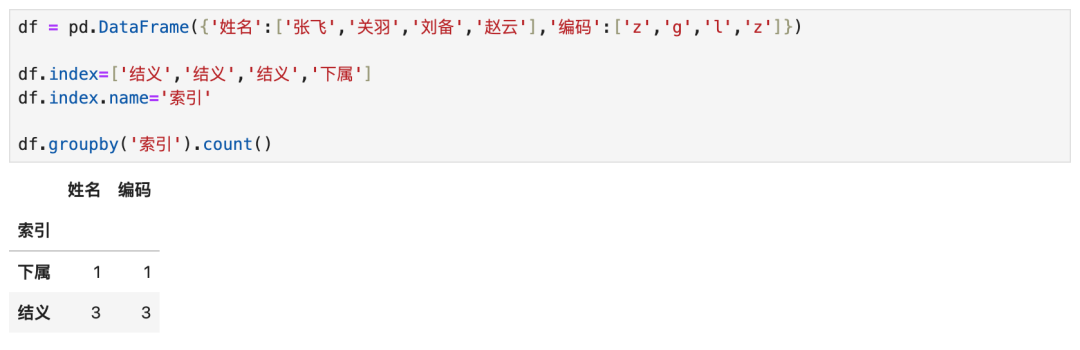
- 显式声明索引,可以直接使用索引分组
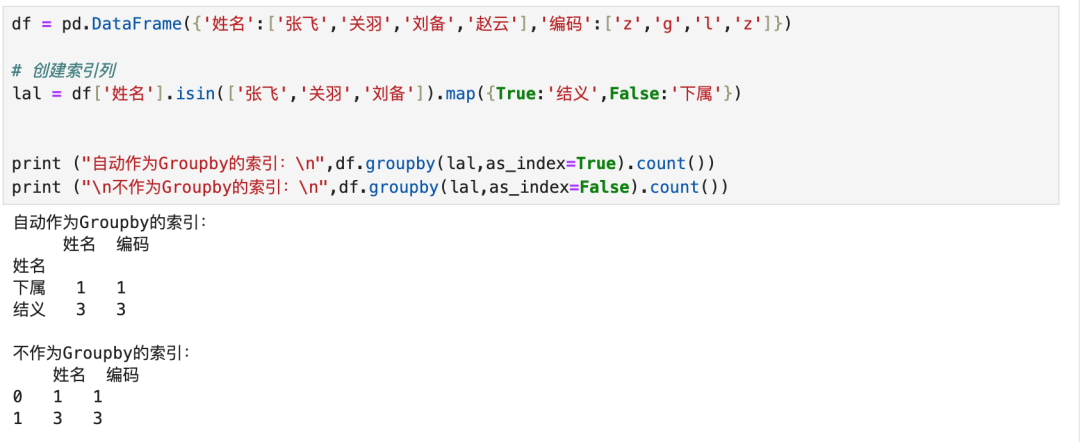
- 不声明索引,调用groupby后自动创建索引
分组有三个维度:
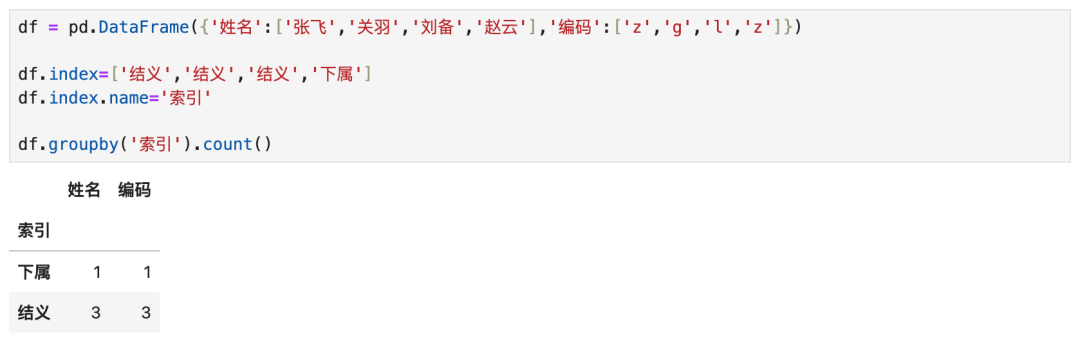
- 行维度分组:groupby
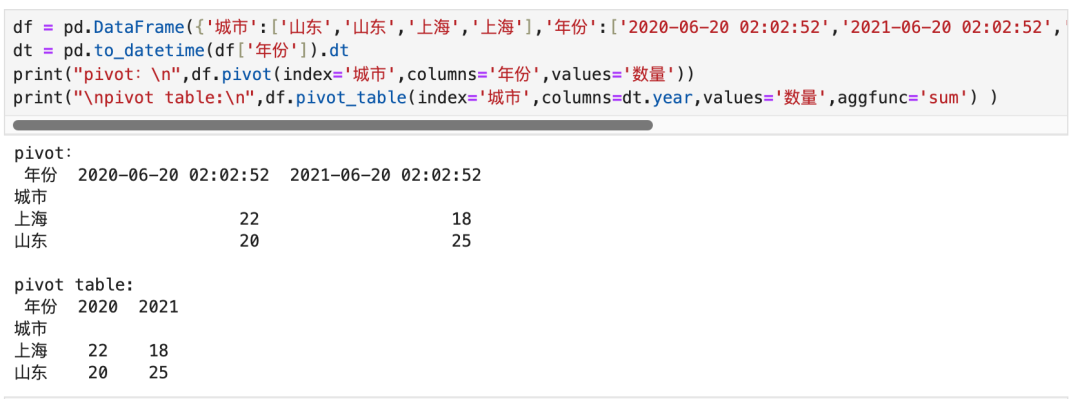
- 行维度分组+列维度分组:数据透视表 pivot
- 按顺序,固定行数组成窗口分组:rolling、expanding
4.1 显式声明索引后分组
4.2 分组后自动创建索引
4.3 行维度分组
4.4 行列两维度分组
4.4.1 单行单列写法
4.4.2 多行单列写法
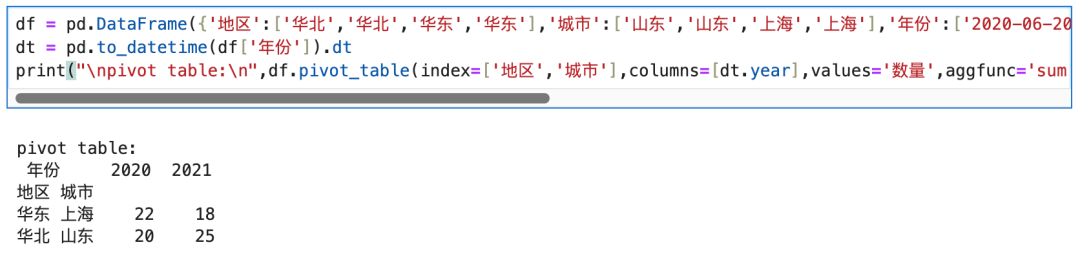
4.4.3 多行多列写法


4.5 窗口滚动分组
滚动分组是按照位置数量分组,实际工作中常说的过去1年,过去一个月,过去一周,以及时间函数都使用滚动计算的理念。
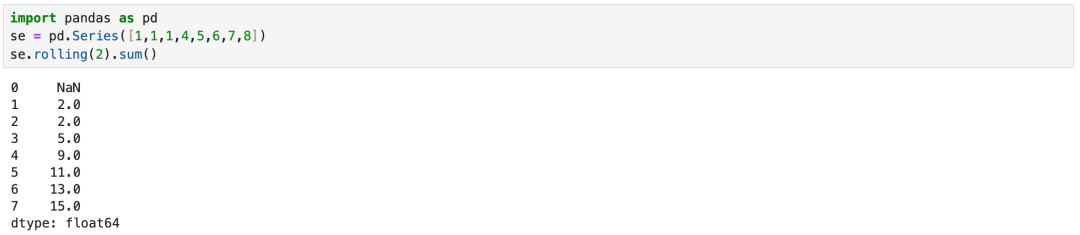
窗口函数与窗口累计函数都可以使用apply函数拿到窗口的值数组,可以使用该值,做任意匹配的运算。
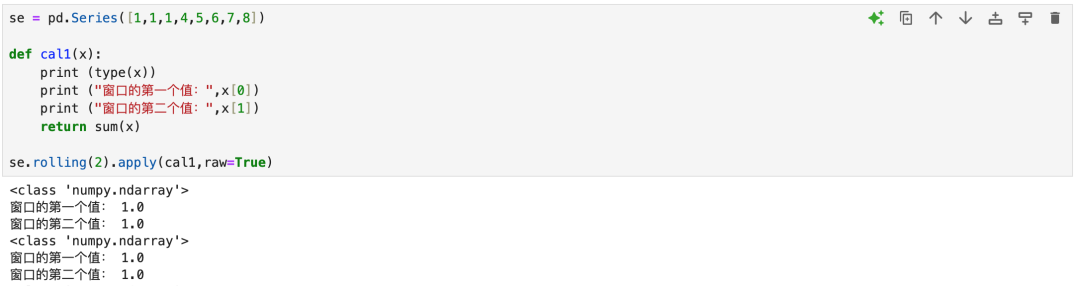
4.6 窗口累计分组

5. 改变数据形状
Pandas中,处理的数据基本都是按表格组织,数据输入有两种方式,按行输入,按列输入。为了输入方便基本会按长轴维度输入数据。
比如8行两列的数据,可以按照行的顺序写,也可以按照列的顺序写。对于该数据,肯定是按列的顺序书写,需要输入的中括号最少。数据输入后再处理即可。

图中可知,数据调用zip分组后,从数据分组的角度看:zip和数据转置的效果是一致的。
6. 数据查询逻辑
Series和DataFrame作为数据容器,数据查询是很重要的逻辑,此处再系统梳理一下流程。
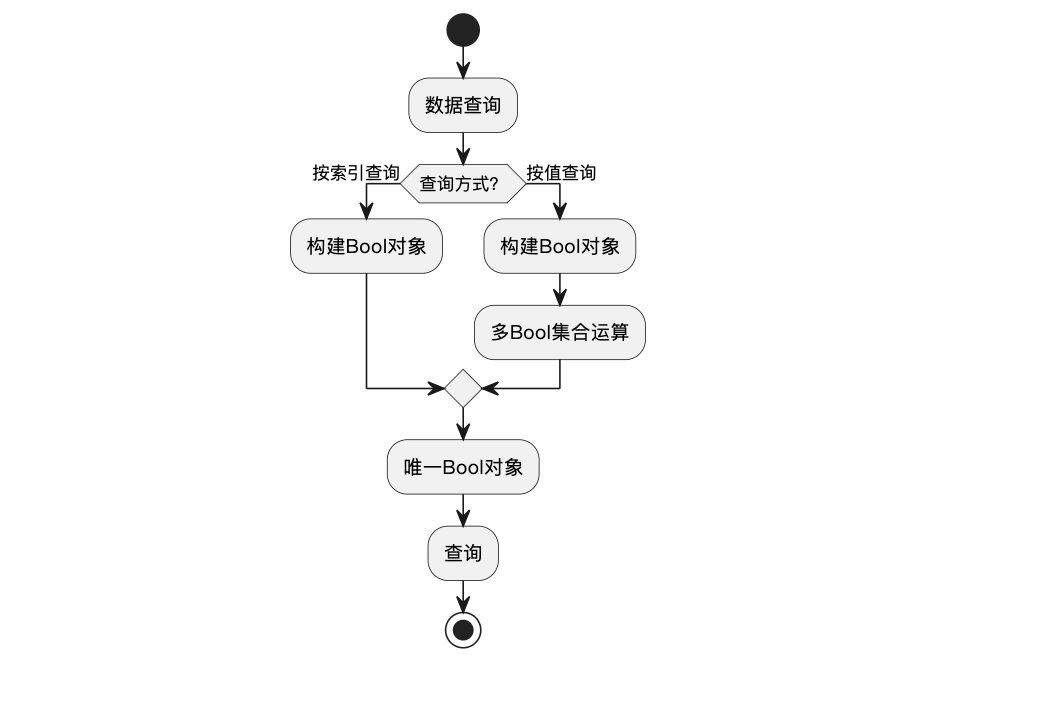
6.1 按索引取值
按索引取值,类比于select的按照主键取值。Pandas接受到入参索引后,会构建一个与被查询数据,相同索引的Series,其中被查询的索引对应值为True,未被查询的索引对应值为False,将该Series作为入参,查询效果与直接输入索引查询效果相同。
代码如下:

6.2 按值取值
按照值取值时,每个运算符对应一个Bool。如果Bool之间是and关系,就执行b1*b2如果Bool之间是or关系,就执行b1+b2
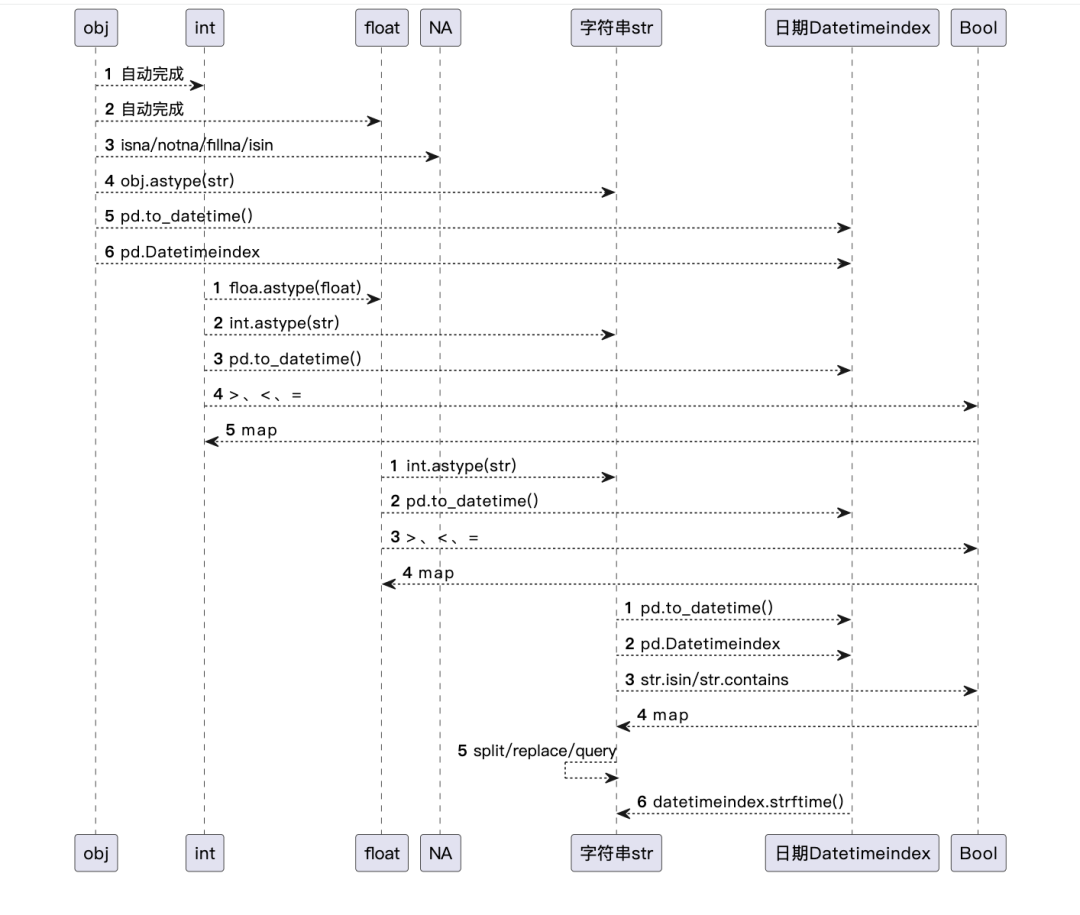
7. 不同数据类型之间的转换逻辑
8. Index展开详解
8.1 概述
index是比数组更大的容器,数组内的元素可以是不同的类型,index统一定义了数组的类型,必须是obj、Datetime、int、Period等其中的一种。index会猜测数组内存储的数据类型,如果是数值,会自动转换为对应的类型,否则统一定义为object类型。
- 定义object类型的好处是:可以存储任意类型的数据。
- 定义object类型的缺点是:大而全,就没有操作数据的方法。小而精,才可以使用对应的操作方法。
- 为了调用int、Datetime类型数据对应的操作方法,需要显式的转换为对应的类型。
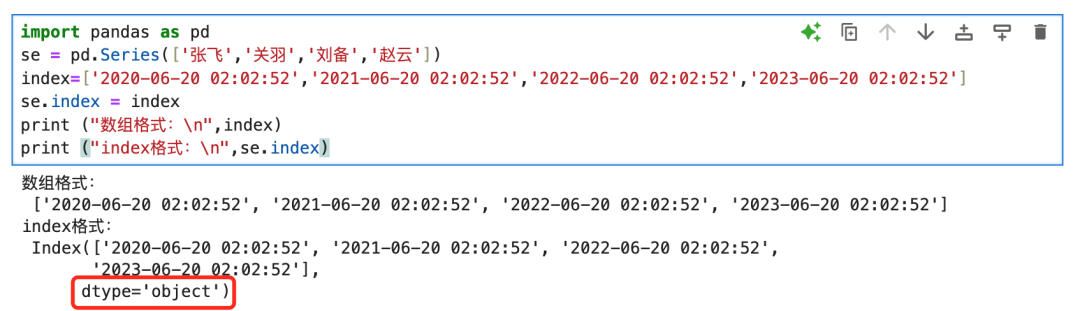
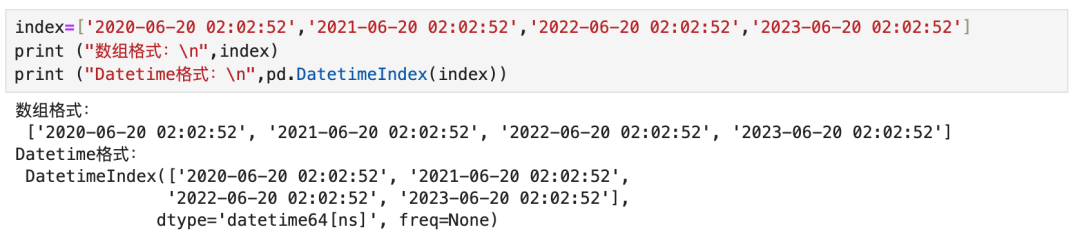
8.2 DatetimeIndex
DatetimeIndex就是Datetime格式的index。日期是一组连续的数字,默认可以按照年、月、日、时、分、秒分组,也可以自定义时间段分组。如果某Series或者DataFrame需要使用年月日时分秒做分组依据,有两个方案:
8.2.1 年月日时分组成5列数组,通过MultiIndex赋值
将字符数组转为
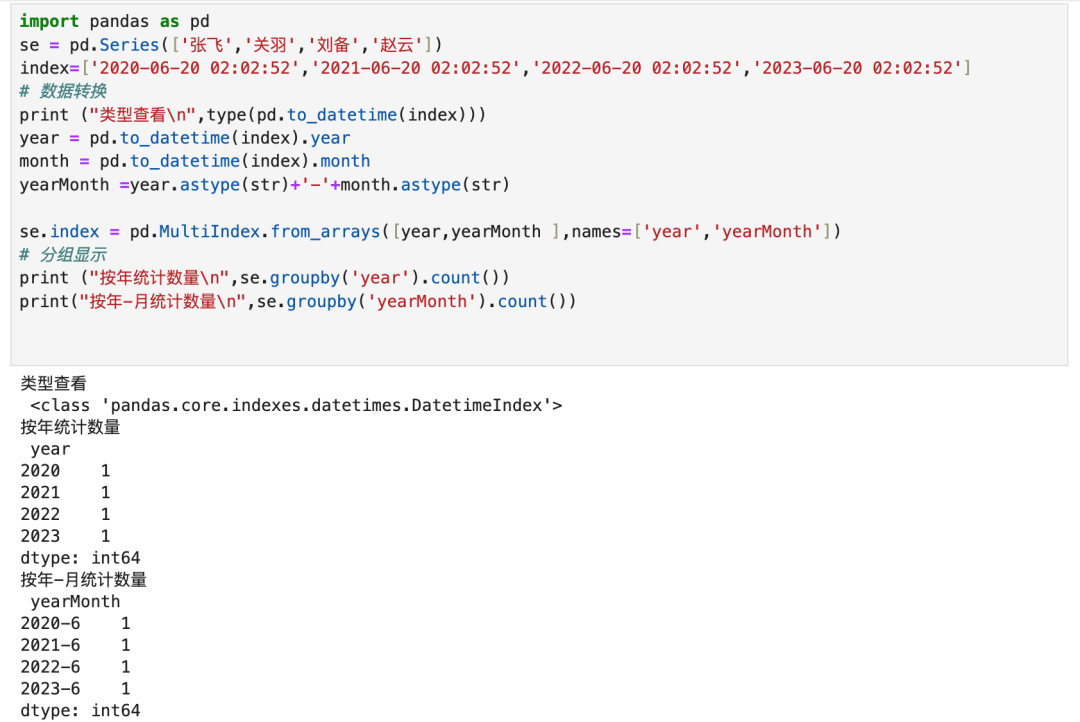
8.2.2 直接将日期转为Datetimeindex赋值,用方法取值
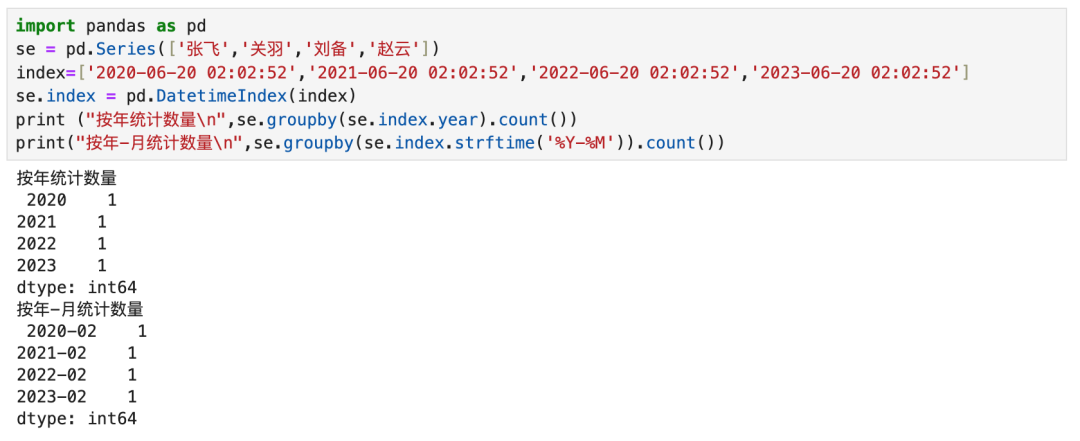
两个对比,显然第二个方案更简单灵活。
9 .常用函数说明
9.1 map与replace的等价写法
map可以将任意值改名其他值,此处主要介绍将Bool转成文本。因为在查询函数返回的值都为bool类型,所以此场景使用map函数的频率更高。
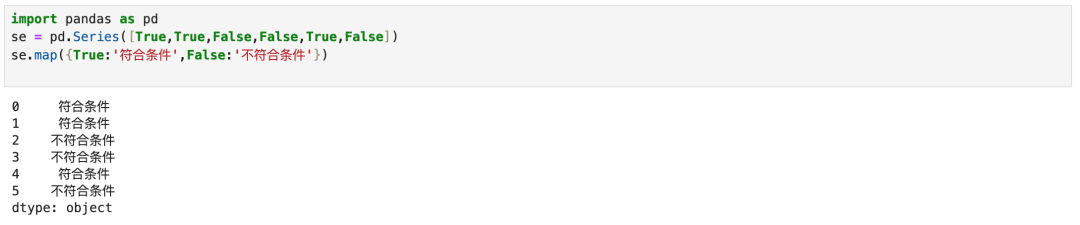
map的传参是集合,是因为这里传值是映射关系。

调用多次replace函数的效果与调用map函数的结果相同。
9.2 isna与isin的等价写法
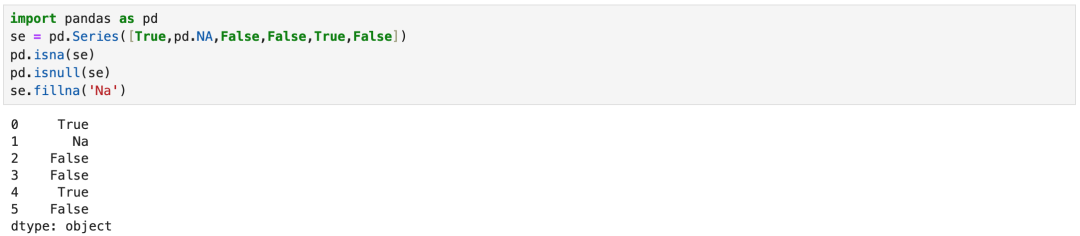
isna与isin(pd.NA)是等价的。fillna与replace(pd.Na)是等价的。
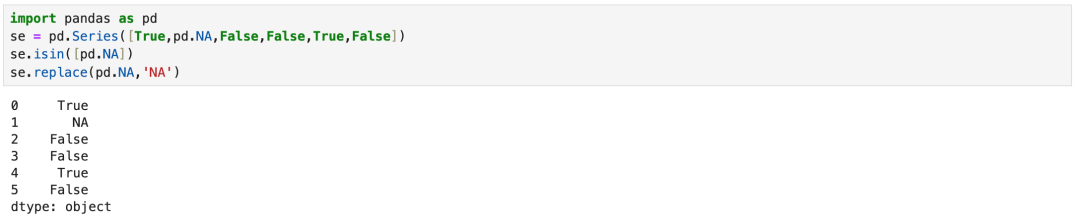
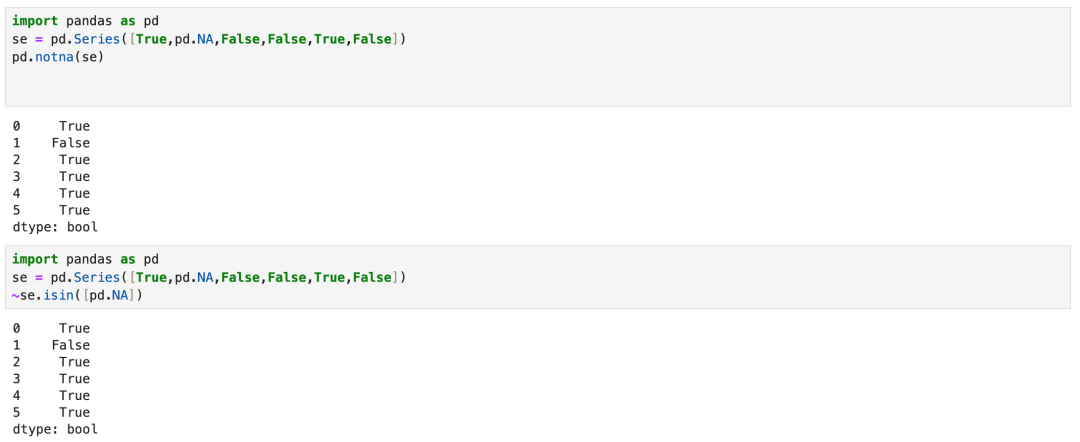
9.3 notna与notin的等价写法
pandas没有not in函数。但是有波浪线表示取反,即True取反后是False,False取反后是True
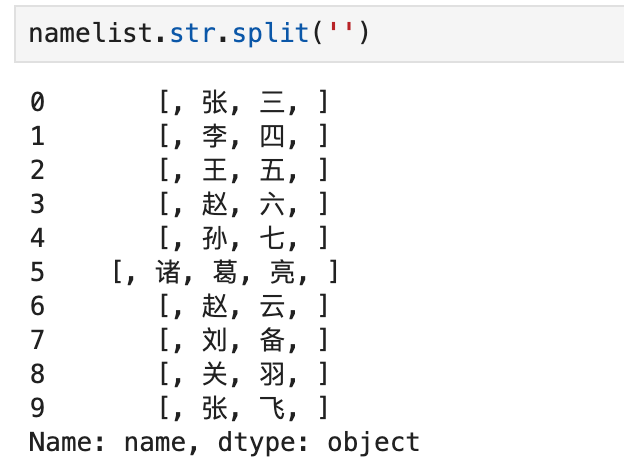
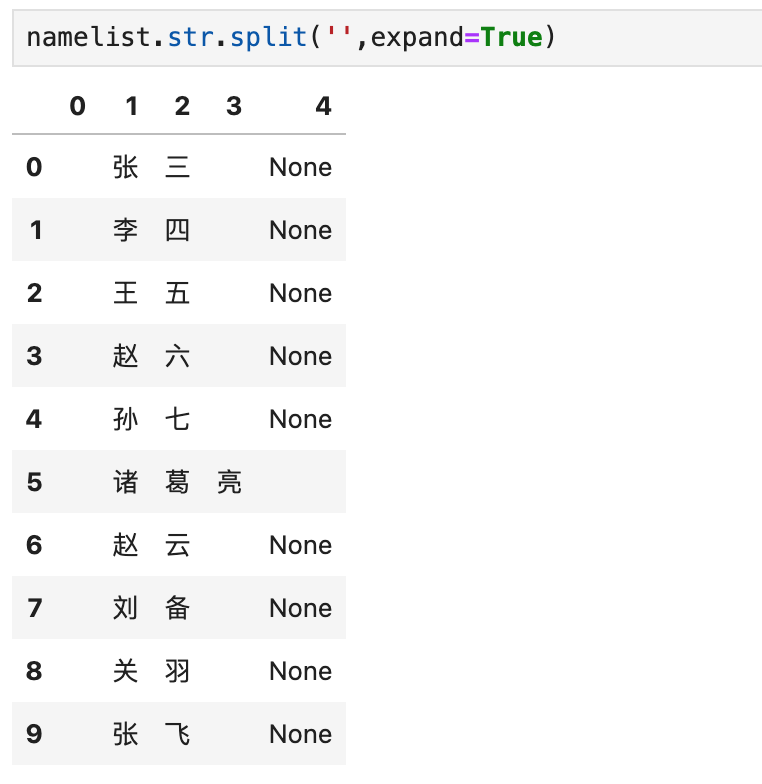
9.4 列拆分函数split
Series分列,默认是将内容分成,数组,不会展开。
9.4.1 默认为Series格式
9.4.2 数据自动变成DataFrame格式
本文由 @我是产品张 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


