
 起点课堂会员权益
起点课堂会员权益
基于XGBoost特征选择方法在业务中的应用
 产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。
产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。本文介绍了一种使用XGBoost机器学习方法来筛选具有高转化潜力的客户群体的策略。通过实例分析,我们展示了如何利用XGBoost模型进行特征选择,以及如何根据这些特征设计精准的营销活动,显著提高营销效果和业务收益。

一、应用场景
在营销活动名单下发以及空网付费券包的人群筛选等推广环节中,很重要的一个环节是如何准确挑选出最有潜力的客户进行线上线下的营销接触,以求增加下单转化,从而提升业务效益。
因此,在各类营销活动中,我们需面临如何准确识别有效用户的挑战。
本文将提出并应用一种机器学习方法—XGBoost特征选择进行更为精细的营销人群识别,从而协助我们更准确筛选出潜在的营销目标群体。
二、解决方案
通常营销目标群体含括了许多不同的特征属性,如年龄、性别、寄件频率、兴趣区域、居住地、手机型号、常用寄件/收件类型等等。

我们可以运用机器学习的方法来确定具有高潜力营销价值的目标群体特征,并据此制定针对性的营销策略。
1. XGBoost概念
XGBoost是一种机器学习系统,全称是eXtreme Gradient Boosting,简称XGB,是GBDT算法的一个变种。
它是一种监督算法,是boost算法的一种,也属于集成学习,是一种伸缩性强、便捷的可并行构建模型的Gradient Boosting算法。它高效地实现了GBDT算法并进行了算法和工程上的许多改进,可用于分类、回归,排序问题。
由陈天奇等人于2014年开发,以优化的方式增强其性能和速度。逐渐被越来越多的数据科学家采用,并在许多机器学习比赛中脱颖而出。
2. XGBoost基本原理
XGBoost算法的基本原理如下:
1)初始化一个弱学习器(通常是决策树),并计算该学习器的预测值和损失函数;
2)算法计算损失函数对于当前预测值的梯度。梯度可以被理解为损失函数在当前预测值处的斜率,它给出了优化损失函数的方向;
3)算法使用新的学习器去预测梯度,而非真实的标签。新的预测值等于原始预测值加上学习率乘以梯度的预测值;
算法反复执行步骤2和步骤3,直到损失函数达到最小值或者达到预设的迭代次数。最后,所有学习器的预测值被加权求和,得到最终的预测结果。
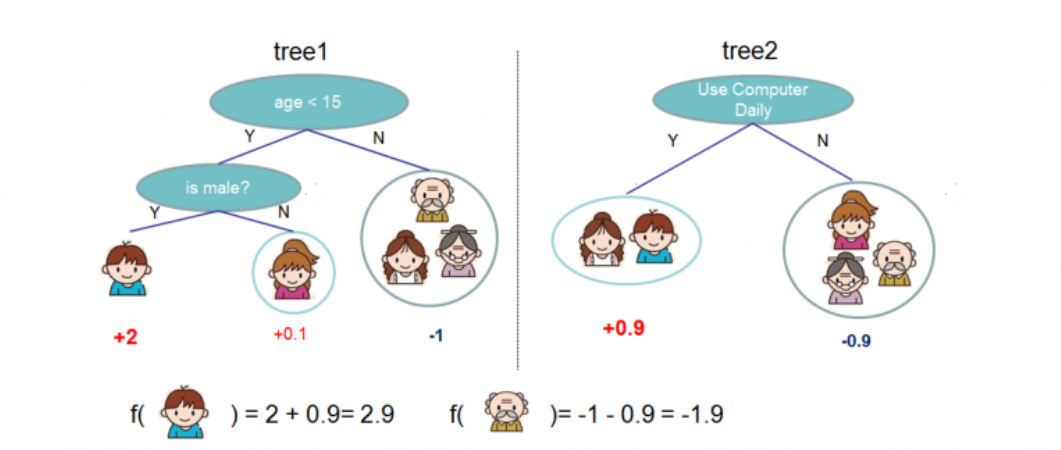
3. 数据模型应用流程
在探索中,我们总结了一套适用于线增业务中的数据建模流程,具体如下:
三、应用案例
以某头部App电商退货目标客户筛选为案例,通过xgboost特征选择方法实现目标人群的圈定,通过如下小程序弹窗形式进行营销。
我们基于前6个月的历史数据提取样本:
1)目标变量: 退货率;
2)自变量:会员等级、手机品牌、性别、年龄、城市等等(由于类别存在中文分类,故采取独热编码进行转化)。
在完成样本预处理后,我们构建XGBoost特征重要度模型(采用网格搜索寻找模型最佳参数),核心代码如下:
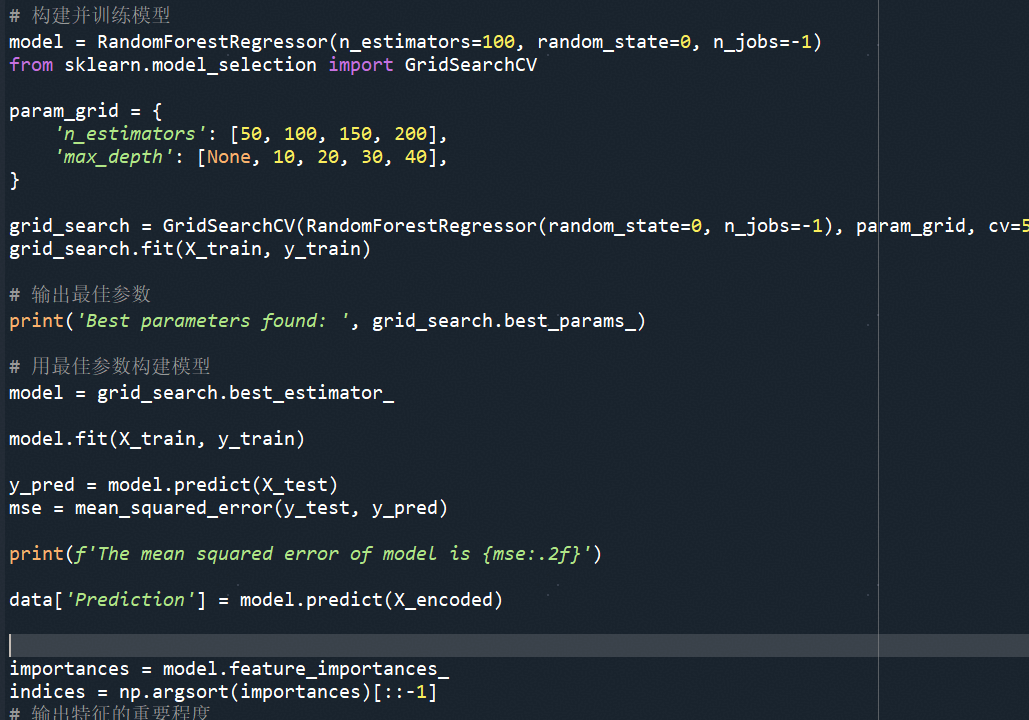
通过模型,我们完成特征重要度输出:
根据模型结果输出策略,电商退货率高的客群特征标签(也可以进行特征交叉组合),进而与电商收件高且无退货的客群做特征交集,从而筛选出一个目标客群来做精准营销。
活动策略通过AB测试评估,实验组(通过本文提到XGBoost筛选特征人群)整体下单转化相较对照组提升30+%,投放期间带来直接增收数十万元。
【备注:对照组1:为业务人员根据经验圈选人群规则;对照组2:根据传统决策树方法圈选的人群规则】
本文由 @佑佑和博博~ 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!








