
 起点课堂会员权益
起点课堂会员权益Adtributor归因在指标异动分析上的应用探索
如何使用Adtributor算法执行归因分析,帮助广告主精确评估各渠道的广告效果呢?本文将通过实际应用案例展示该算法如何迅速定位销售异常的根本原因。这不仅能提升广告的投入产出比,还能为未来的营销决策提供数据支持。

一、应用场景
在数字营销领域,归因分析被广泛应用于评估不同渠道的广告投放效果。如一个用户通过多个渠道接触到同一品牌的广告,并在最终决定购买时,归因分析可以帮助确定每个渠道对用户购买的贡献程度。这有助于广告主更准确地了解哪些渠道的广告投放更为有效,从而优化未来的广告投放策略。
简而言之,归因分析通过合理地分配用户行为的“贡献”到每一个渠道或因素,帮助业务人员更好地理解用户行为路径,评估广告和营销活动的效果,并据此优化策略,提高转化率和投资回报率。
二、解决方案
Adtributor算法是微软研究院于2014年提出的一种多维时间序列异常根因分析方法,在多维度复杂根因的场景下具有良好的可靠性。
算法完整过程包括数据预处理、异常检测、根因分析和仿真可视化4个步骤,我们主要借鉴了根因分析环节的方法,该环节使用惊奇性和解释力对指标实际值和预测值之间的差异进行解释。
1. 解释力(Explanatory power)
指标的维度的解释力是该维度指标的变化额度在整体指标变化额度的占比,如下面公式描述,其中Aij为某个维度的真实值、Fij为某个维度的指标的预测值、A为某个指标的真实值、F为某个指标的预测值、i是维度{dim1, dim2 …dim n}, j为维度里的元素{e11, e12, e21, e22 …}。
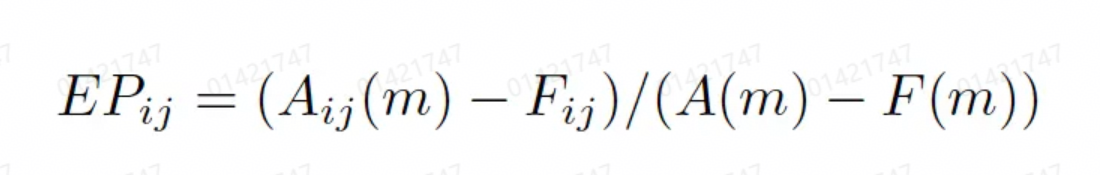
在实际应用中,我们需要人为确定一个解释力的阈值,例如如果某个维度的某个元素的解释力已经超过了40%,我们就觉得这个维度的元素对于整体的变化有很高的解释力度(可能是导致指标变化的主要因素)。而一个维度可能有多个元素会超过这个阈值,我们就需要将多个元素的解释力值进行求和得到这个维度对于整体指标的解释力。
2. 惊奇指标(Surprise)
在进行归因的时候,我们还面临一个问题就是排序问题,哪些维度导致的指标波动的差异最大呢?
这个时候就引用了一个惊奇指标,通过预测值的概率分布和真实值的概率分布的差异【Jensen-Shannon (JS) divergence】,来评估维度导致的指标波动的重要程度,这个数值范围是0~1,越接近0说明预测值和真实值的分布越接近,越接近1说明预测值和真实值的分布差异越大。
计算公式如下:

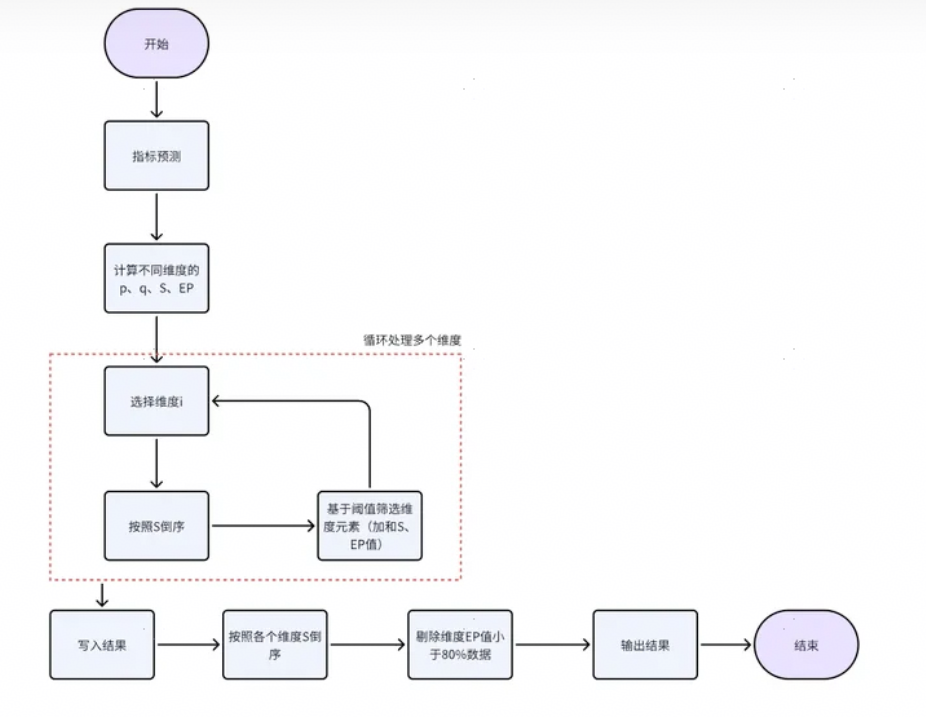
3. 归因流程
step1:先把数据提前处理好,预测指标、计算p、q、S、EP这些指标。
step2:循环迭代不同维度按照单个元素的EP阈值筛选维度元素数据,对于EP值和S值进行加和,并将数据写入结果集合之中。
step3:最后,对于循环之后的结果按照S值排序,并且基于二八原理,剔除维度EP值低于80%的数据,输出结果。
三、应用案例
以某产品购卡行为为例,一级购买分类包括:(a)套餐 (b)扣款类型 (c)业务区 。
其中一级类别可继续细分,如套餐可细分:(1)连续包月 (2)连续包季 (3)连续包年 (4)SVIP月卡 (5)SVIP季卡 (6)SVIP年卡。
当某天卡购买量有异常(通过预测值与真实值误差来判断,超过阈值则认为当天卡购买量有异常(阈值基于历史数据来制定),我们可以利用上文提到的Adtributor归因来实现异常问题的快速定位。
Adtributor归因核心代码如下:
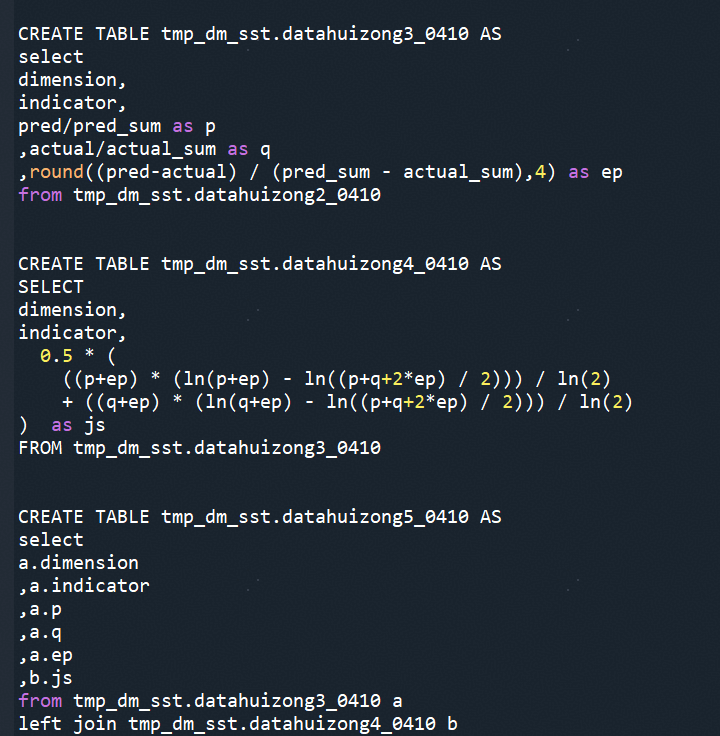
以7月5号购买异常波动为例(在7月5号我们发现卡的购买量t-1真实值与当天的预测值出现显著差异),我们利用Adtributor归因在数秒内完成异常原因的自动定位(通过归因,如下图所示我们可以立即知悉7月5号异动是由扣款渠道的2个因子导致的(扣款周期、扣款方式)。
这样基于归因算法,我们很方便完成异常波动的原因分析(即7月5号购买量大幅下滑是由扣款渠道类别下(a)扣款周期(b)扣款方式两个因子导致),从而可针对这两个因子调整我们的业务策略。
本文由 @佑佑和博博~ 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。








代码里的 js公式 为什么和 ep有关系呢