
 起点课堂会员权益
起点课堂会员权益基于支持向量机的分类模型在业务分类场景中应用探索
在竞争激烈的市场环境中,准确快速地识别高潜力用户成为提升营销效果的关键。本文将介绍如何利用支持向量机(SVM)模型,通过智能数据分析精准定位潜在客户群,特别是在节日促销活动中如何有效提升策略执行力和发掘新的商机。
一、应用场景
在我们的日常工作中,分类问题是我们常会遇见的一个问题。
以端午节到来为例,我们需要识别出高潜用户并将他们的信息提供给跟进团队,以期待获得更良好的活动效果。这就使得识别高潜力用户,变得至关重要。
在本文中,我们将基于支持向量机(SVM)模型,透析如何有效地识别这些高潜力用户。
二、解决方案
支持向量机(Support Vector Machine, 简称SVM)是一种由Cortes和Vapnik在1995年首次提出的机器学习算法。
它在处理小样本、非线性和高维模式识别方面展现出了诸多独特优势。更为值得一提的是,SVM还可以广泛应用于函数拟合等其他机器学习问题中。
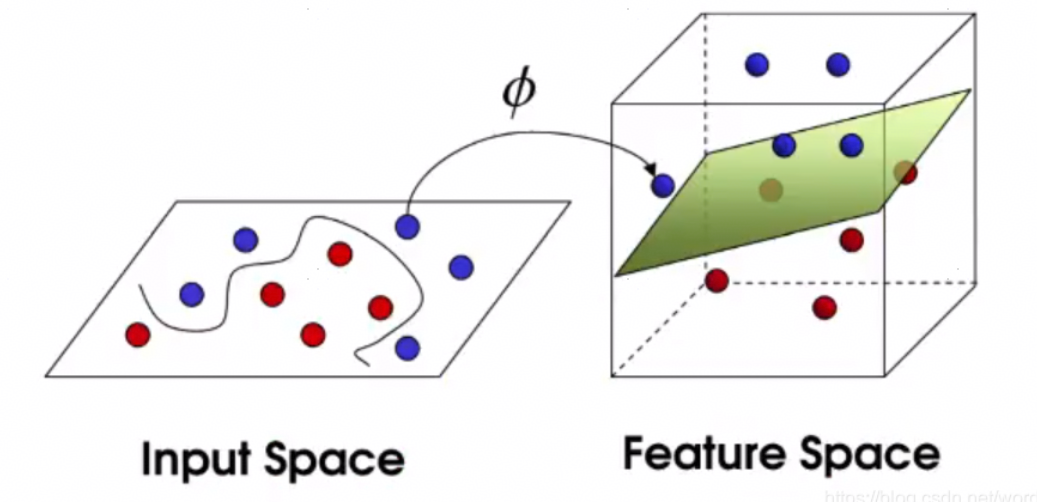
1. SVM基本原理
支持向量机(Support Vector Machine,简称SVM)是一种广泛应用的机器学习算法,其核心原理在于在高维空间中构造一个用于分类或回归的超平面。
详细来说,SVM首先将数据集映射到高维空间,接着在该空间中找寻一个最优的超平面,该超平面能够有效地区分不同类别的数据点。这个“最优”的超平面定义为将离它最近的数据点(即支持向量)到超平面的距离最大化。
其分类过程则涉及将新的数据点投影到高维空间,根据其相对于最优超平面的位置来确定其所属类别:如果新数据点在超平面的正方向,则归为正类,反之则为负类。虽然在高维空间中可以有无数个超平面(如感知器),但最大化几何间隔的分离超平面却是唯一的。
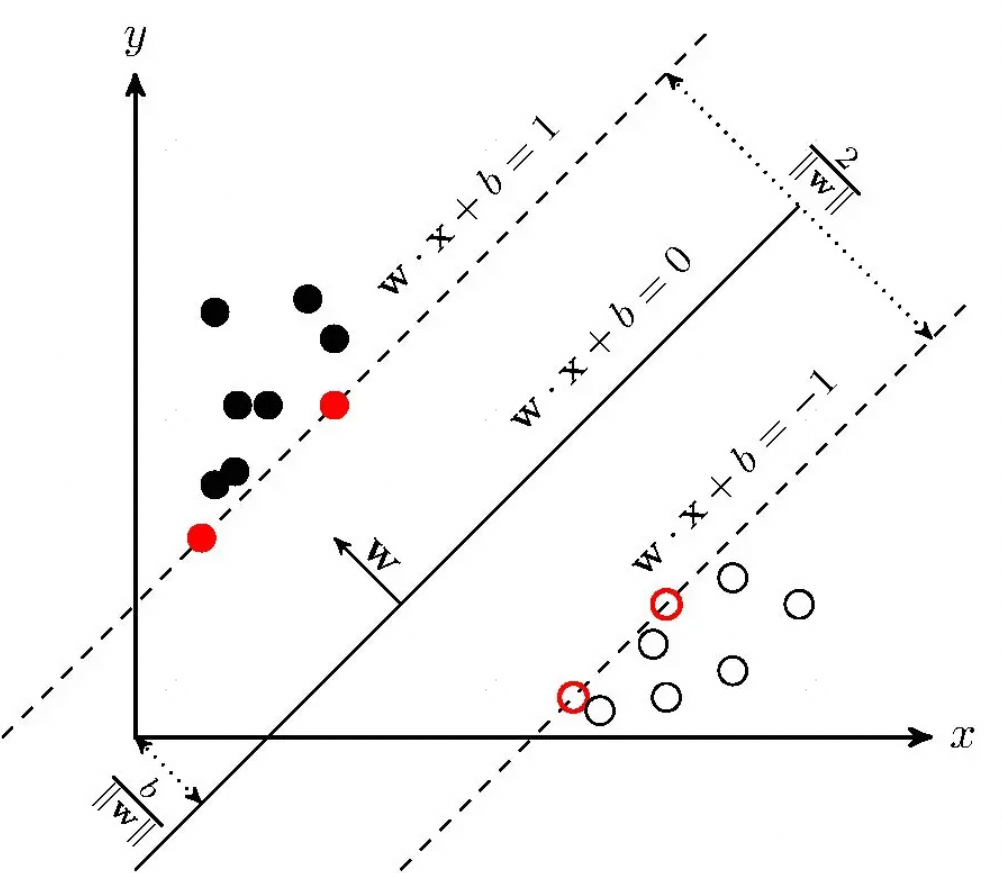
2. 支持向量机算法的分类过程
支持向量机(SVM)算法的分类过程主要包括以下四个关键步骤:
- 数据预处理:首先,我们需要对原始数据进行特征提取和特征选择,以将这些数据转化为适合进行进一步分析的格式。
- 特征映射:接着,我们需要将原始的特征空间通过某种映射函数推广到高维特征空间,这样才能使得数据在这个新的空间中变得线性可分。
- 最优超平面选择:在高维特征空间中,我们需寻找一个最优的超平面,使该超平面能有效地将不同类型的数据点分隔开。此处的“最优”超 平面定义为离超平面最近的数据点到超平面的距离最大。
- 确定支持向量:在确定最优超平面後,我们还需要确认支持向量,即这些距离超平面最近的那些数据点。
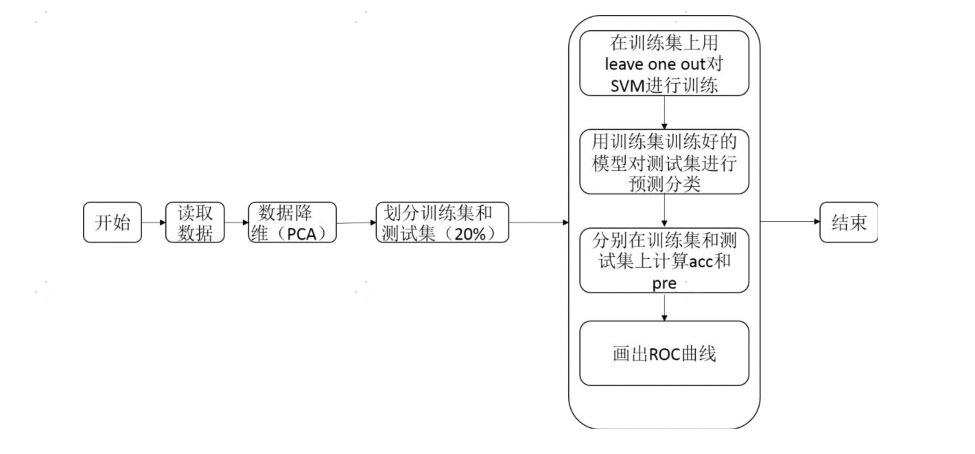
3. 支持向量机算法的模型构建流程
如下,支持向量机(SVM)模型构建的流程图:
三、应用案例
联动地区,进一步加大对精准潜力用户的运营跟进(例如在端午节活动期间,通过“赏金活动”分发特定的高潜用户名单,然后由相应的地推人员进行专门跟进维护)。这样不仅能够有效放大策略效果,还有助于我们发现新的业务机会。
要识别出具有潜力的用户,我们可以依赖用户的过去行为数据和用户属性。应用支持向量机(SVM)分析工具,对某用户是否是潜力用户进行高效判断。在这个过程中,我们使用二值系统(是:1,否:0)进行简化标注。 核心代码如下:
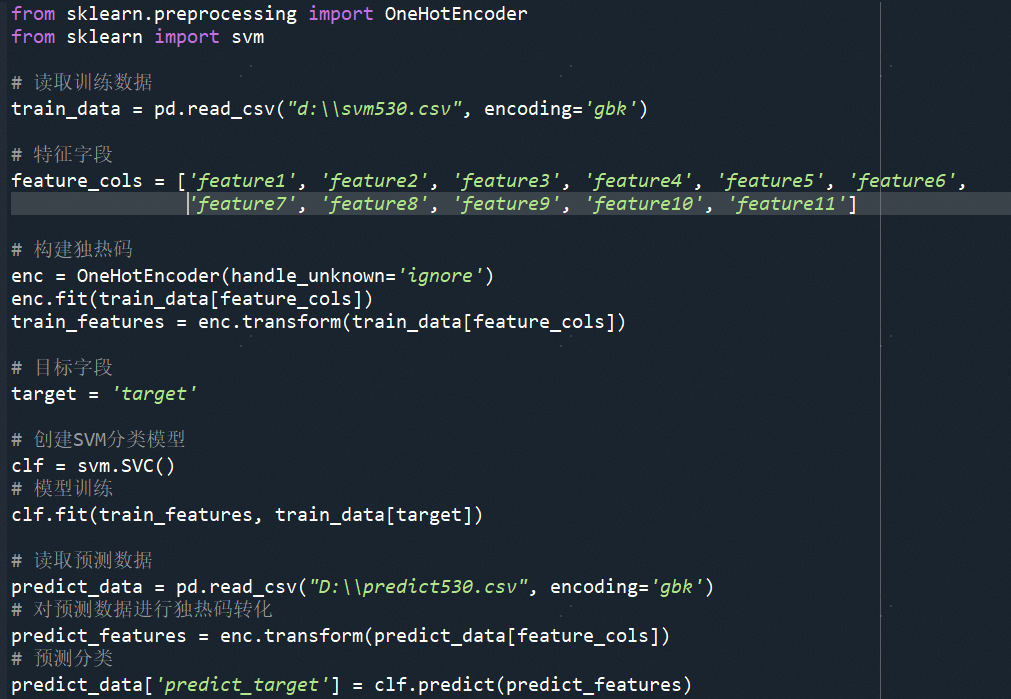
最终模型效果表现优良:在对147046条记录进行分类预测后,我们达到了99.2%的准确率。
本文由 @佑佑和博博~ 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


