
 起点课堂会员权益
起点课堂会员权益
从“半个宇宙”看未来的AI互联网
 产品经理专业技能指的是:需求分析、数据分析、竞品分析、商业分析、行业分析、产品设计、版本管理、用户调研等。
产品经理专业技能指的是:需求分析、数据分析、竞品分析、商业分析、行业分析、产品设计、版本管理、用户调研等。半个宇宙公司提出了一个大胆的构想:构建一个去中心化的AI互联网世界,让每个人都能拥有自己的“第二大脑”。这篇文章将深入探讨半个宇宙的使命、愿景和差异化定位,以及它如何应对数据垄断的挑战。无论你是对AI技术感兴趣,还是对未来互联网的发展充满好奇,这篇文章都将为你提供一个全新的视角。

之所以写这篇文章,是源自自己对每个领域的专家养成未来需要依赖外部“第二大脑”帮助的这个构想,与半个宇宙对未来AI互联网定位存在千丝万缕的关联;
在“第二大脑”关联性方面看,半个宇宙尝试打造一个由个人AI计算机(PAIC)连接而成的、去中心化的AI互联网世界,每个人都可以有属于自己的“第二大脑”,提升信息获取和分享的效率,进而改善人和人之间的交流和沟通;
在半个宇宙自身定位方面看,它尝试以kOS系统架构为基础,打造个人AI计算机来打破数据垄断,让数据为个人创造价值,做AI互联网时代的苹果;
这篇文章主要从运营视角重新理解这家公司的定位,相关内容源自网络公开资料及基于公开资料的个人思考和猜想。
一、半个宇宙为何而来?
每一次社会性的变革和革命,都是在解决一个社会性的矛盾,都是在尝试保障更广大群体的切身利益。
半个宇宙也是。
1. 它试图解决的根本矛盾是什么?
半个宇宙解决的是信息聚集导致的数据垄断和人们对自由、开放、共享、平等的网络环境的向往之间的矛盾;

但这并不意味着信息聚集百害无利,存在即合理,它的存在当时也是为了解决社会性的矛盾,即低效的供需匹配(包括信息、商品、服务等)和供需双方希望高效地、低成本地匹配之间的矛盾,只不过在商业和资本驱动之下引发了大公司数据垄断和互联网公司数据壁垒割裂导致“人找信息”效率依然低下的问题。
2. 这个矛盾呈现的现象有哪些?
1)对于整个互联网科技行业来讲:
- 用户数据被大公司垄断:互联网带来便利的信息访问,但也导致了信息在某些超级节点(如大型互联网公司)的聚集,进而形成了数据垄断,进行推动广告等商业模式对用户价值的榨取,帮助大互联网公司盈利;
- 互联网地盘化:互联网公司为了保护“流量”和“数据”给自己创造的商业价值,相互之间形成了割裂的状态,降低了人找信息的效率,也降低了用户体验;
- 平等关系被打破:小的个体难以在互联网上出头,而大型公司则失去进取动力,导致腐朽;
2)对于个人来讲:
- 数据为他人所用:大量的个人信息、行为数据、个人偏好等数据信息并没有为个人创造价值,而一直被数据垄断方用来榨取个人价值(包括但不限于广告干扰、数据售卖等);
- 信息茧房:当下每个人所处的是一个信息爆炸但知识匮乏的环境,大部分人处于一个忙于被动接收、怠于独立思考的状态,信息收敛在自己关注或专注的领域并不可怕,可怕的是失去了发散思考和独立思考的意识甚至权利。
二、半个宇宙要打造怎么样的宇宙?
1. 它的使命是什么?
- 原话:让数据成为个人资产,通过AI互联网高效互联20亿人,从而打破大公司的数据垄断,消除数据孤岛;
- slogan:我们志在发明新型的个人AI计算机(PAIC,Personal AI Computer),打破当代互联网大公司的数据垄断,让数据为个人、小微企业创造价值,最终实现自由、开放、共享、平等的AI互联网
- 延伸:我们尝试拆解一下原话中的“个人资产”、“高效互联”这个2个关键词
首先是个人资产,半个宇宙主张的是“人人都是数据的主人”,你创造的数据应该更多为己所用、为自己创造价值,而不是更多地在被垄断方使用、反过来榨取自己的价值,这个主张更多映射的是互联网“平等”“开放”的特征;
再者是高效互联,半个宇宙尝试把当下“人找信息”的互联网时代向“信息找人”的互联网时代推进升级,这个尝试更多映射的是互联网“自由”“开放”“共享”的特征,提升信息获取和分享的效率,让人们更加专注在沟通和交流上;
2. 它构想的用户、开发者、半个宇宙之间的关系是怎么样的?
- 用户提供数据,且拥有数据;
- 开发者提供算法;
- 半个宇宙提供算力,通过售卖算力实现商业化。
3. 它如何打破数据垄断的格局?
- 整体来说,通过新型技术架构(个人AI计算机)调节网络结构,改变互联网的信息流动方向,消除信息聚集,制衡资本的无序扩张;
- 具体来说,将互联网设计成一个类似于人类社会关系网络的模型, 构建一个更加公平的、去中心化的,局域化的网络,再通过长程连接把各个局域连接起来,避免了信息超级节点的出现。
4. 它在互联网演进长河中的里程碑意义
在第一财经《前阿里云高管吴翰清再创业,如何解决大模型幻觉、打破数据垄断?》这篇报道中提到:来到AI互联网时代,人们也需要个人计算机及AI时代新的程序开发形态来定义、修正、约束AI的动作,AI的能力、行为和性格也将在未来具备可塑性和成长性,他将这种个人AI计算机上的新的算法程序定义为“ACT”。在KMind 推出的个人AI计算机的架构kOS里,程序员可以开发自定义的“ACT”,用于定义AI的某种自主行为。在未来,当AI成熟到可使用某种形式化语言来自动编程时,普通用户也可以实现使用自然语言和个人AI计算机交互。
三、它怎么应对“自己变成数据垄断者”的困局?
- 对公司的原则:推荐、检索算法以及ACT开源,由一个开源社区维护(这个动作还没执行,因为系统还不成熟);
- 对消费者的原则:保护用户隐私(如快找找kfind这款产品的匿名设置,识别用户身份的唯一凭证是Cookie,如果用户清掉了Cookie,那么对半个宇宙来说将完全是一个新的陌生人。这意味着kFind未来有了App和Web站点后,删除App或者清掉浏览器的Cookie,所有的用户行为偏好和推荐都将被重置);
- 对行业的原则:公众监督(算法开源就是一种公众监督的体现);如果某一天半个宇宙选择把推荐算法给闭源掉,替换了开源算法,号召所有用户来推翻半个宇宙。
四、半个宇宙的差异化定位是什么?
1. 结论
- 不作跟随者,不和大模型厂商正面交战;
- 打造个人AI计算机(PAIC),采用kOS架构操作系统,作为中间环节来统一整合基础层(大模型)和应用层(场景应用),把大模型当做其整体的一小部分(可以理解为是CPU、心脏);
- 做AI互联网时代的苹果或微软,定义新的程序开发形态。
2. 理念
- 唯有独一无二才能生存。
3. 逻辑
1)对标谁?
从定位的理念层面看,其实并没有所谓的对标的对象,因为半个宇宙属于引领者而不是跟随者;一定要有一个对象,那大概是挑战对象,而现在AI领域需要直面挑战的就是OpenAI,因为它的目标是让AI变得越来越强大、实现AGI以及进一步的数据、信息、知识的垄断,是半个宇宙绝对的“打击对象”;
2)怎么打?
基于理念的定位,不跟随大模型创业的路,而是选择薄弱点来另辟蹊径,薄弱点即AI大模型的2个致命问题:
(1)幻觉问题:当用户提出一些请求时,大模型有时会给出一些与事实不符的回答,甚至胡编乱造的错误回答;
(2)精准控制问题
- 数:比如这个问题:“在《甄嬛传》这本书中,‘甄嬛’这个名字一共出现了多少次?”,或者更难一点的问题“在《甄嬛传》这本书中,一共出现了多少个女人?多少对夫妻?”,所有的大模型都无法回答;
- 修改: 比如用大模型文生图画了一张图,然后跟它说“请把背景里天上的那个月亮改成紫色的”,这时候所有大模型只会给你重画一张不一样的,而不会在现有图片上做细节修改,而修改局部内容远比一次性创作发生的频次要高得多;
- 安全红线:大模型试图满足和讨好用户,缺乏精确的安全红线,会伤害到用户的对话体验、甚至泄露隐私数据信息。
(3)根本问题
- 自然语言大模型依赖神经网络,它代表的是连接主义,具有较强的泛化能力、较弱的逻辑推理能力,导致出现幻觉问题和精准控制问题;虽然代表符号注意的高级编程语言具有较强的逻辑推理能力,但它的整体泛化能力较弱,无法适应不同的场景;
- 大模型是CPU,而无论是ToB还是ToC的AI应用,都需要一个中间环节来将其与大模型联系起来,不可能指望应用直接跑在CPU上
(4)解决路径
- 通过kOS(操作系统,即根本问题中提到的中间环节)统一神经网络和高级编程语言(Python、Java等,较强的逻辑能力,较弱的泛化能力,它代表的是符号主义),来模拟人的思考过程,从整体上解决幻觉问题和精确控制问题;
- 这样的系统架构,让大模型发挥其神经网络的泛化能力、让程序员编程发挥逻辑能力,通过人机交互和系统流程中反复的请求&返回的闭环设计,实现更好的意图理解,规避掉了“特定场景下高级编程语言需要足够的泛化能力”、“局部的神经网络需要精确的逻辑推理能力”的问题;
- 同时,通过数据的脱水和数据的浸泡产出结构化数据来更好地解决精度问题。
3)为什么能打?
- AI大模型自己解决不了;关于幻觉问题,目前LLM在解决幻觉问题上主要还是靠对齐,来源于它的提示词工程和微调,但这类技术治标不治本,无法从原理上根治幻觉问题;关于精准控制的问题, 单靠LLM也是无法解决精确控制的问题的;
- 系统可行性:kOS的设计符合计算机的信息论、控制论和系统论。
五、基于整体差异化定位,半个宇宙的客户是谁?客户在哪?
从PAIC的视角或者kOS的视角看,半个宇宙的客户分供给端和需求端两类:
- 供给端:以kOS为开发平台的开发者,包括个人和公司,活跃在各大成熟的技术交流平台以及主流社交媒体平台上;
- 需求端:以C端产品为具体的消费者/使用者,即所有的手机、个人电脑、互联网用户,活跃在各大主流社交媒体平台上。
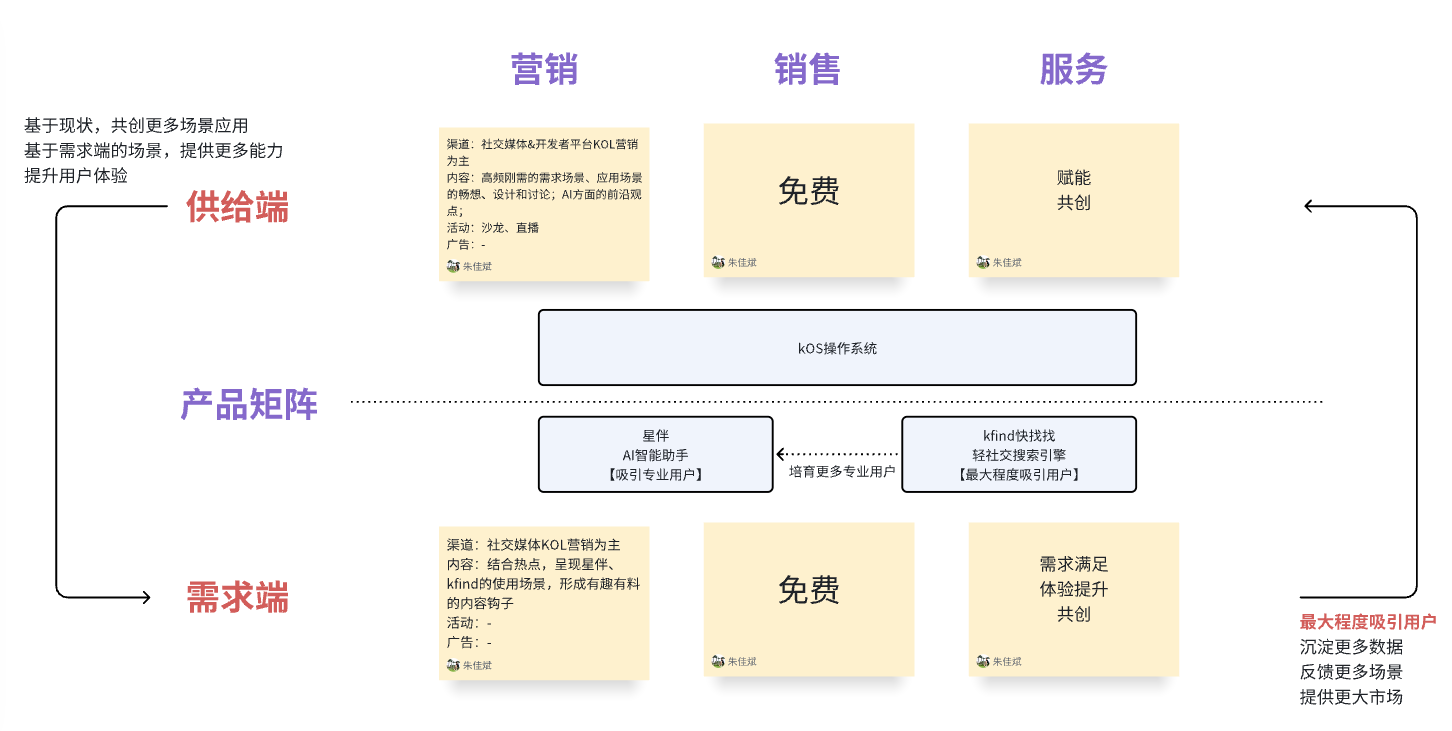
六、基于整体差异化定位,半个宇宙当前的产品、营销、销售、服务模式长什么样?(猜想)
- 需求端需要有刚需高频的场景最大程度吸引用户,形成更加丰富的数据和需求池,反哺供给端开发者生态有更加精准的需求设计和共创意愿;
- 供给端需要有更多的入驻,以kOS为平台,共创更多具有市场价值的能力,完善整个产品矩阵;
- 以此为基础,当前以营销和服务为主,形成供需两端的良性正向增长,通过时间、数据、技术能力和基于星伴的场景能力的持续积累,形成壁垒,最终实现以售卖算力形成商业化闭环。
本文由 @朱佳斌Plus 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!









