
 起点课堂会员权益
起点课堂会员权益如何高效的利用低代码技术进行数据建模
在数字化转型的过程中,业务与开发团队之间的沟通常常存在障碍,特别是在数据治理等专业领域。数据建模作为连接双方的桥梁,能够帮助双方更好地理解和沟通需求。本文将探讨如何利用低代码技术进行有效的数据建模,以促进业务与开发之间的协作。
在数据需求沟通中,业务与开发之间往往存在“鸡同鸭讲”,出现无法语言对齐的情况。业务抱怨开发语言太技术,听不懂;开发也苦于业务表达太含糊,无法转化为需求。尤其在数据治理等专业性领域,沟通问题成为了业务与开发之间一道无形的壁垒,急需通过某种有效的手段进行打破。而数据建模,恰好成为了数据需求梳理及系统设计的有效手段,能够帮助业务及开发双方更好地进行需求理解和沟通。
通过进行数据建模,我们能解决数据之间血缘脉络,并且清楚影响数据质量的关键属性,最关键的是,解决了业务与系统开发人员的统一语言。
01 什么是数据建模?
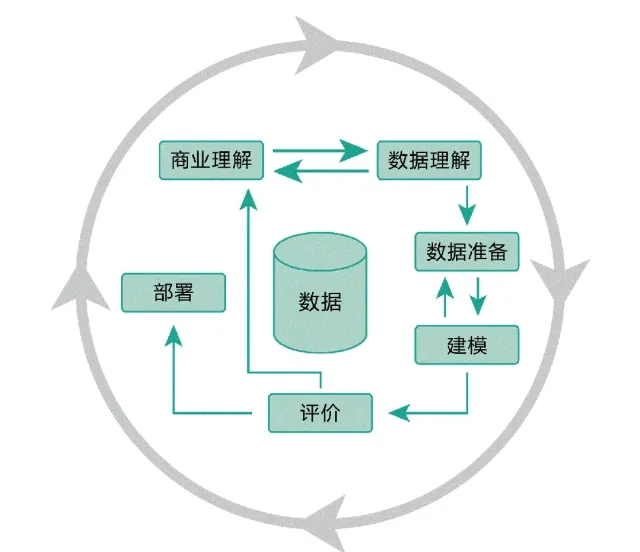
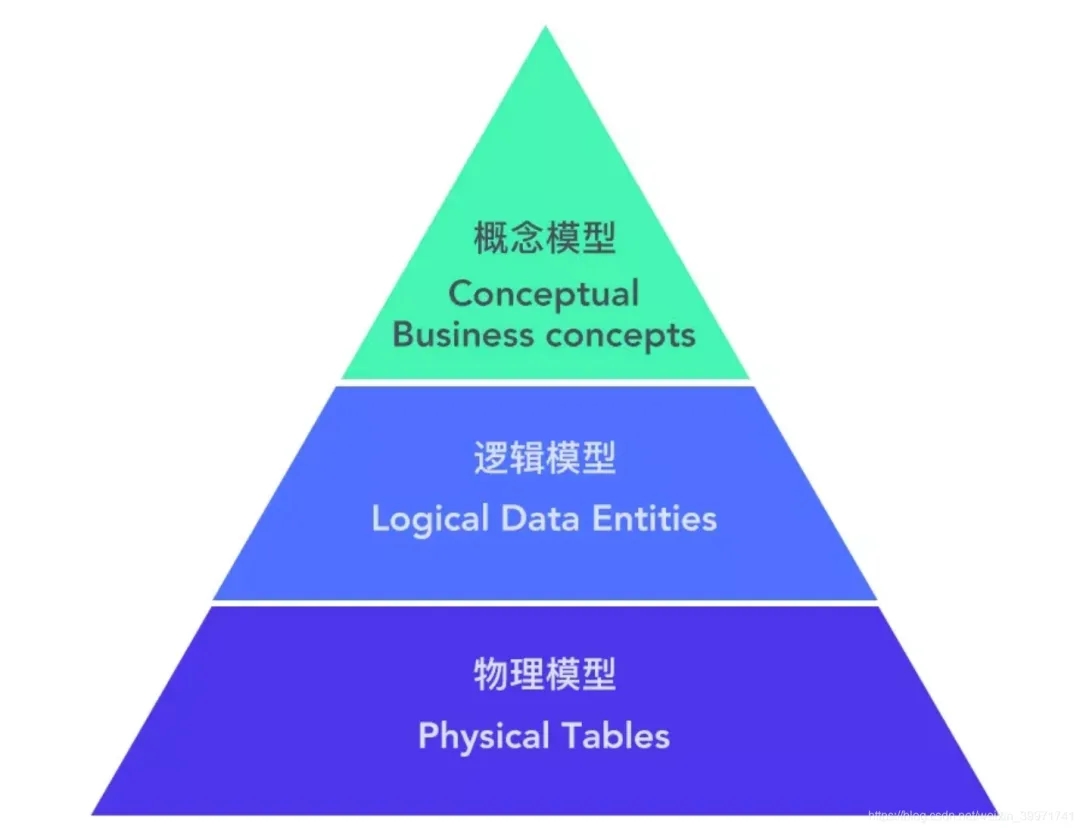
数据建模,简而言之就是明确业务场景以及流程后,抽象实体和之间的关系,确定实体涉及的主从表以及对应的属性字段,然后进行存储计算。一般分为概念模型、逻辑模型、物理模型。
当然,目前数据建模的方式不少,有维度建模,范式建模,Data Vault模型、Anchor模型。这里我们不展开一一介绍,重点分享一下基于低代码技术进行维度建模的方法。(常见的建模工具有PowerDesigner、ER/Studio,当然直接用Visio、Excel也是可以的)
02 低代码建模
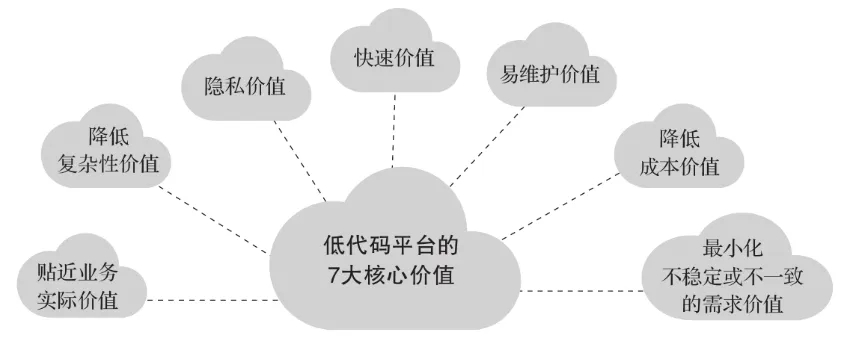
为什么要通过低代码技术进行数据建模呢?主要还是针对性解决“统一语言”、“高效”的目标。低代码技术进行数据建模的优势主要体现在以下几个方面:
首先,低代码技术能够显著缩短开发周期。传统的代码开发方式,需要严格遵循算法和数据结构的组合,这种方式如同手动拧螺丝,既费时又费力,且对非专业开发人员而言上手难度极大。相比之下,数据建模对时效性要求极高,无论是增加实体对象还是调整字段属性,其影响都是深远的。而低代码技术则让这一过程变得如同“搭积木”一般简单快捷,极大地提升了开发效率。
其次,低代码开发能够迅速响应变革场景。随着企业应用的预期爆炸性增长,潜在场景的数量也数以千计,这些场景都蕴含着为企业创造价值的可能。低代码开发方式使企业能够更好地应对这些挑战,一方面能够减少代码开发工作量,同时还能弥补现有技术能力的不足,而无需将每个人都培养成专业开发人员或在内部进行大量的软件开发投入。
最后,低代码开发还能够推动业务部门更深入的参与数据管理、数据治理相关工作。例如数据建模的过程中,我们首先需要清楚业务逻辑,形成概念模型,并基于物理世界进行数字孪生进行逻辑模型。而传统上这些任务是由IT部门负责的。然而,现在越来越多的企业开始认识到,数据的使用、标准定义需要业务部门深入的参与甚至主导。因此,一个简单易懂、能够让业务部门轻松上手并参与管理的系统显得尤为重要。低代码技术正是实现这一目标的理想选择。
利用低代码技术进行数据建模实际上主要三个步骤:划分主题域、创建模型、形成表单。我们可以理解,这三个步骤实际就是概念模型、逻辑模型、物理模型的三个组成部分。
第一步:用户可以根据业务需要对数据按域划分。各域之间既相互独立又可交叉引用;按控制层级将数据域分为组织和全局的属性,例如一家公司里面涉及到的人力域数据、供应商域数据以及物料域数据等等,这些域相互引用,相互依赖影响,最终形成整体的数据流。
通过将数据按域进行划分,从内部组织到外部环境、从上游供应商到下游客户、从组织架构到日常业务等统一纳入数据各域管理范畴。有利于理清企业业务脉络,重构企业核心价值链。
从源头划清不同数据之间的界限,层次分明地界定多域之间的关系,同时还可以将不同域之间的数据交叉引用,实现数据域之间横向纵向立体管理。
第二步:创建模型。建立主表、子表和独立三种类型的模型,支持主表模型和子表模型的嵌套以及主表模型和独立模型的引用,构建统一的数据属性管理视图。
- 模型1:主表模型。定义数据的主表模型,数据的核心属性集,与子表模型和独立模型通过可视化配置表单实现关联,构建数据统一视图。
- 模型2:子表模型。定义数据的子表模型,实现数据的数据明细行管理,支持可视化配置实现数据的星型模型,主表模型的创建,是根据数据管理的需要,如果模型属性是多行数据,可以通过创建子表模型进行管理,因此子表模型不能独立定义对应的表单,必须要依赖主表模型进行相关的数据管理。
- 模型3:独立模型。定文辅助数据的模型,作为数据主表模型,子表模型的数据来源(类似于参考数据,行政区划等),独立模型的创建,是根据业务管理的需要,可以进行独立的模型定义,不受主表模型的约束,可以独立定义数据管理的表单和流程。
第三步:构建模型相应表单。表单配置中可以提供业务组件库和多样的属性库,并辅之以视图、流程、权限等,用户可以根据业务需要灵活地构建。
可视表单: 表单可视化无代码定制,多类型组件提供复杂业务场景解决方案,街接数据模型及应用功能及菜单。
表单类型1:数据表单。可视化表单,其主要功能是将模型中的属性字段与前端应用界面进行映射。数据表单是以主表模型作为基础,可以关联多个子表模型和多个独立模型,通过表单组件及其属性与子表模型和独立模型建立联系。
表单类型2:独立表单。独立表单是以独立模型作为基础,可以关联多个其他独立模型,构建符合业务需要的复杂前端管理界面。例如产品类型、行政区划等参考数据码表。独立表单单相较于数据表单,功能上相对简化,目的在于高效、便捷。
03 写在后面
数据建模其实往往很容易被忽略,特别是提倡敏捷开发的背景下。虽然在开始阶段,数据建模费时费力,但从长远来看,对我们的基础架构是易于升级和维护的。其次是,业务人员与开发人员能够通过数据建模的过程中,在概念、物理和逻辑层面设计数据库达成一致意见,有助于识别缺失项和冗余数据。
我们会发现,利用低代码技术去构建数据模型,方便业务人员与IT人员进行沟通交互,且操作更加便捷,高效。后续再进行一系列录入功能的开发,菜单的定制是非常快捷的。当然低代码技术不能解决业务转化成数据的过程,针对业务场景和流程,我们需要进一步解析挖掘对应的数据需求。
本文由人人都是产品经理作者【老司机聊数据】,微信公众号:【老司机聊数据】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


