
 起点课堂会员权益
起点课堂会员权益医疗AI应用为什么选Qwen
在医疗AI领域,选择合适的底层模型对于应用的成功至关重要。作者在本文分享了为什么在医疗AI应用中选择Qwen模型,而不是其他如百川智能或llama模型的原因。

Qwen2,上线仅1天,下载量已经超过3万次。而且最近使用率一直飙升,随着AI应用的落地数据应该还会比现在多几百倍,未来的使用率这些也会是个不小的数据。不过即便这样,大模型目前能赚的钱也不会太多,其根本原因是大类应用还没出现。
话说回来,同样在医疗领域为什么不选择百川智能或者llama来做我们的底层模型。
在我们初期选定技术方案的时候是有考虑过Llama405B来做的,我们也尝试过用这个快速做了一个MVP的前期产品,出现的BUG率还蛮多的,偶尔还有很多妖魔鬼怪的问题出现,有的时候并不是技术上面的问题,也有可能是我们技术团队的问题。
第二个原因就是Llama对中文的语义分析有歧义。
而Qwen2对于医疗类的AIagent来说可以用其超大规模的算力和多轮交互能力,为用户提供逻辑推理和代码编写的强大支持。最主要能快速的理解我们国内的一些真实场景。
那么对比Baichuan,擅长跨领域知识融合与自然语言理解,为用户提供全面的知识问答和信息整合服务。更多的场景应该是选择导诊和问诊方面的,解决一些深化的医疗问题。
第三个原因是我们目前面对的场景一般是数据不出库的情况下,并且要求私有化部署的商业化应用。Qwen2开源许可都换成了Apache 2.0,也就是说可以更加自由地商用。这是Llama 3系列都没做到的。
第四个原因是他们的开源 RAG 和代理框架QwenAgent,最初是作为内部实用程序代码来促进模型开发的,最近经历了快速开发。他们已经在框架中发布了上述长上下文代理的实现。
这种友好的框架是我们解决RAG幻觉问题很好的基础。
虽然Baichuan也有很好的RAG方案,百川自研的 Think Step-Further方法对原始用户输入的复杂问题进行拆解、拓展,挖掘用户更深层次的子问题,借助子问题检索效果更高的特点来解决复杂问题检索质量偏差的问题。用到的是Query拓展,Query拓展按照我的理解会影响回答的速度,按道理是需要经过几次分类模型和分析模型的,目前使用虽然没有影响回答速度,毕竟我还在测试这里面的优化逻辑,等我研究出来再告诉大家。
对于我们这种项目来说多种RAG方案我们肯定选择最容易解决问题的那一个,而我们团队中有人是擅长知识图谱的,所以我们还是选择了QwenAgent的框架毕竟开源。
第五个原因,嗯,说句可能被打脸的。
我认为Qwen的商业模式跟我们发展路线其实是一致的,可以共同成长。后续对我们最有帮助的点是一个重要的理论工具是Scaling Law,它而可以帮助我们理解和预测大模型的性能表现,并指导我们在模型设计和训练中做出更合理的决策。Scaling Law一定Agent里面核心的一环,推理逻辑的强大对工作流来说可以帮助稳定其主要的输出。
三个月创业来,我第一次有谨慎乐观的感觉。我的现在开始有点讲道理了,至少会推理出医生需要的是什么工作流了需要帮他干什么了,但是现在还是不会干。很多人以为AiAgent就是单纯的调用API,Agent有提示词可以对细分领域或者任务进行处理,按照接口对接程序中写好提示词不也是一样的吗?如果是这样理解的话,咱们做个脚本就可以了。
这种方法我们一般用在发布会上,比如演示Demo的时候失败了,立马换一个写死的程序,能演示。但我们做的是一款产品,它需要不断的对医生工作流思维进行交互,如果操作过autogen的话,就很容易明白这里面的区别了,区别是这里无法形成多代理。
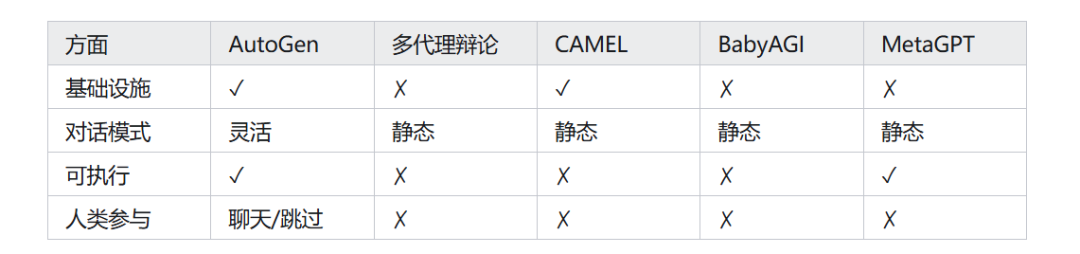
看起来做医疗类的AIAgent似乎成了大佬们的一个共识,就是不知道这个共识是否能星火燎原。
本文由人人都是产品经理作者【罗福如】,微信公众号:【罗福如】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


