
 起点课堂会员权益
起点课堂会员权益LLM的范式转移:RL带来新的 Scaling Law
LLM(大型语言模型)的范式转移正在由RL(强化学习)引领,带来全新的Scaling Law。传统上,LLM的发展依赖于模型规模、数据量和计算资源的扩展,而RL的引入为这一领域注入了新的活力。通过强化学习,LLM能够更好地适应复杂环境和任务,实现更精细化的控制和优化。这种范式转移不仅提升了LLM的性能,还为其应用开辟了新的可能性。随着RL与LLM的深度融合,我们有望见证一个更加智能、高效和适应性强的大型语言模型时代的到来。

从几周前 Sam Altman 在 X 上发布草莓照片开始,整个行业都在期待 OpenAI 发布新模型。
根据 The information 的报道,Strawberry 就是之前的 Q-star,其合成数据的方法会大幅提升 LLM 的智能推理能力,尤其体现在数学解题、解字谜、代码生成等复杂推理任务。
这个方法也会用在 GPT 系列的提升上,帮助 OpenAI 新一代 Orion。
OpenAI 不是唯一重视 RL 和 Self-Play 的公司,Google 用 AlphaGeometry 2 + Alphaproof 夺得 IMO 银牌之后,基于 LLM 做 reward model 的思路发了多篇 paper。Anthropic Claude 3.5 的代码能力显著提升,我们猜测也是以这样的思路去引领变化。
今年以来我们观察到 LLM scaling up 的边际收益开始递减,用 RL self-play + MCTS 提升 LLM 推理能力成为下一个技术范式。在新范式下,LLM 领域的 scaling law 会发生变化:计算量变大仍会带来模型智能的提升,但会从模型参数量变大,转移到 inference-time compute 增加,也就是模型进行更多 RL 探索。
本文正是在这样的背景下分析和思考 RL 会如何给 LLM 带来新一波的智能提升,以及这对我们未来投资、创业有着怎么样的 implication。
一、为什么我们期待 RL 改变 LLM 范式?
1. LLM 利用现有数据,RL 探索长距离推理
2018 年,Lex Fridman 邀请 Ilya 来 MIT 客座讲一节课,Ilya 选择的主题是 RL 和 self-play,因为他认为这是通往 AGI 的路上最关键的方法之一。Ilya 在讲座中用一句话概括了强化学习:让 AI 用随机路径去尝试一个新的任务,如果效果超出预期,就更新神经网络的权重让 AI 记得多使用成功的实践,然后开始下一次尝试。
这个概括中可以看到强化学习和其他 AI 范式的重要区别,经典三大范式(监督学习、非监督学习、强化学习)中只有强化学习的假设是让 AI 进行自主探索、连续决策,这个学习方式最接近人类的学习方式,也符合我们想象中的 AI agent 应该具备的自主行动能力。
强化学习的核心在于”探索”(Explore)和”利用”(Exploit)之间的权衡。LLM 在”利用”现有知识上做到了现阶段的极致,而在”探索”新知识方面还有很大潜力,RL 的引入就是为了让 LLM 能通过探索进一步提升推理能力。
在实现 RL 的过程中,有两个核心组件。他们之间一直在反复交互,agent 在环境中执行 action,并且根据环境的变化评估 reward:
• Environment:AI 探索完成任务的环境,当 Alphago 下围棋时,环境就是 19×19 的棋盘。环境会发生变化,AI 会从环境变化中收到 reward value 判断过去的那一系列探索是否有明显的收益,例如距离下围棋胜利是否更接近了。
• Agent:agent 会根据对环境的观测和感知来输出一个动作,目标是得到更高的 reward。agent 这个概念最早就是来自强化学习。
如果把这里的 agent 主体换成 LLM,那么会在探索的过程中做很多 LLM inference。因此这里 RL 在 LLM 中应用的思路本质是用 inference time 换 training time,来解决模型 scale up 暂时边际收益递减的现状。这势必也会对 scaling law 带来很多变化,详细的变化我们会在 2.3 节进行分析。
2. self-play + MCTS:高质量博弈数据提升 reasoning 能力
要让 RL 算法能够在连续推理任务上做到最好,理解 self-play + MCTS 的思路是最重要的。放到 LLM 语境下,self-play 是让 LLM 同时扮演一个或多个 agent model 去做推理任务,并由另一个 LLM 作为 reward model 来给出打分评价,一定次数后更新 LLM 权重让其多记住做得好的推理方式。
Self-play 是 AlphaZero 等强化学习算法的合成数据方法,最早可以追溯到 1992 年的 TD-Gammon 算法。这个方法的本质是利用 AI 无限的计算能力来补足它数据利用效率不够的短板,更符合当下 AI 的优势。好的 self-play 能合成大量高质量的数据,甚至可能比人类历史上见过的棋局、游戏数更多,用数据量来做到 super human:AlphaGo, Dota Five 都探索出了和人类不一样的游戏套路,并战胜了大部分职业选手。
让我们以 AlphaZero 为例,在每一局对弈中,模型使用蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)来选择动作。MCTS 结合了当前神经网络提供的策略(policy)和价值(value),从而在每个游戏状态下评估出最优的行动。其具体步骤如下:
- 随机初始化: 模型从完全随机初始化的状态开始,没有任何人类先验知识。
- 自我对弈 (self-play): 模型自己与自己进行对弈,生成大量的游戏数据。这些对弈中好的结果用于更新模型的参数。
- 蒙特卡洛树搜索 (MCTS):在每一次对弈中,AlphaZero 会使用 MCTS 来搜索最佳动作。MCTS 使用策略网络 (policy network) 提供的动作概率分布和价值网络 (value network) 提供的局面评估结果来引导搜索。
- 策略更新 (policy network): 根据自我对弈的结果,使用强化学习的方式来更新神经网络的参数,使得模型逐步学习到更优的策略。
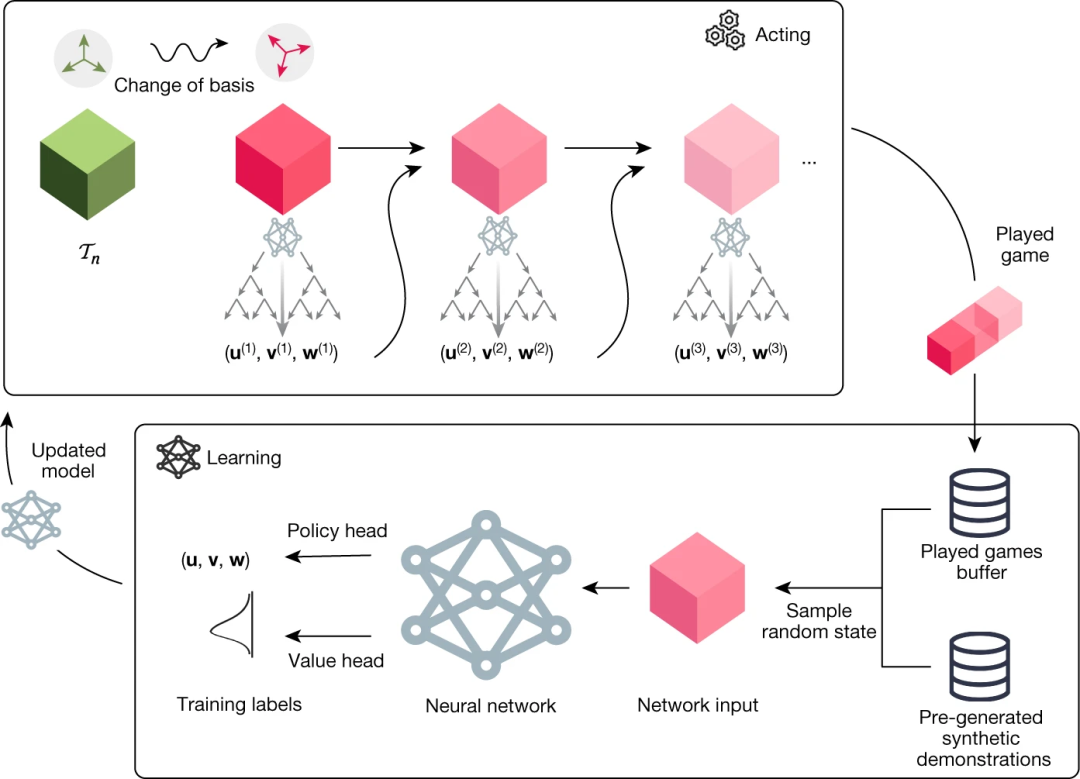
这张图来自 AlphaTensor 论文,是Alphazero 在矩阵运算解题时的变种。图中的 acting 包含了上文中的前三步任务,learning 步骤对应着第4步:策略更新
AlphaZero 的神经网络架构就是 policy network,包含了 policy head 和 value head。这是 self-play 定义的来源:policy 是负责下棋的部分,value 是负责评估的 reward model,他们来自同一个神经网络。
• 策略网络 (Policy head): 输出当前棋盘上每一个可能走子的地方的概率分布,表示模型在当前状态下认为的最佳行动。
• 价值网络 (Value head): 输出一个标量值,表示当前棋盘状态的评估,即模型认为从当前状态到达游戏结束的胜负概率。
对比 LLM,AlphaZero 强调从零开始的自我学习,不依赖任何人类的历史数据或先验知识。所有知识均通过自我对弈产生和优化,在 explore 上做到了极致;LLM 依赖于大量的预训练数据,这些数据所有互联网文本和代码内容,反映了人类知识和语言模式,在 exploit 上做到了极致。
可能会问,为什么 RLHF 中的 RL 很难进一步给模型很强的探索推理能力,因为 RLHF 的任务目标并不是机器智能,而是人机对齐。在像 average human 的偏好数据上做 RL 能做到“更像人”,但不能做到 super human 的智能。举个例子,人类总是更喜欢好理解而不是逻辑严谨的内容。
3. 如何评估 RL reasoning model 的能力?
当 OpenAI 和 Anthropic 的 reasoning model 发布时,应该怎么评估其模型的智能程度呢?我们可以想到这样几个重要的 milestone,难度从低到高:
• Milestone 1:强推理能力的“理科生”
RL reasoning model 一定能在这两个垂直领域达到很强的可用性:90%+ 复杂数学问题正确率,完整生成 1000+ 行代码的 github repo。
• Milestone 2:能规划执行 long horizon task 的 AI agent
如果 self-play 有可能通过自由探索互联网数据,在一些任务上能为用户执行浏览器/操作系统级的 autopilot,这时 AI agent 就真正来到了 ChatGPT 时刻。
• Milestone 3:AI society 对话系统
RL reasoning model 可以模拟两个角色的对话,发现和优化对话策略。例如一个 LLM 可以扮演销售和客户、老师和学生、各国外交官等各种角色,通过自我对话学习如何在各种语境下的社交、沟通技巧,从中获得真正的语言理解和共情能力。如果这里有 emergent capability 涌现,AI 智能能真正的社会化。
总结来说,self-play 给了模型一个自己“卷”自己不断进步的框架,MCTS 方法让模型在连续决策中更容易“打出连招”,self-play+LLM+MCTS 会成为 LLM post-training 中新的范式。至于能走到哪一个 milestone,这里的核心 bottleneck 就是 reward model,我们在下一节中将重点讨论。
二、Reward model
RL reasoning 的核心难点
Self-play RL 是要在好的策略上持续探索,怎么定义“好”就尤其重要。因此, Reward model(奖励模型) 是 RL 中最关键的模块之一,有两个关键的卡点是需要解决的,那就是 reward model 的泛化性和连续性。
1. 可验证的 reward model 让 code & math 提升路径明晰
Self-play RL 在棋牌、电子游戏、数学竞赛上之所以有效,是因为这些领域都有明确的胜负标准,可以作为 reward model 的基础。有了 LLM 的 in-context learning,我们相信代码、数学是可以通过 LLM + self-play RL 来持续进步的。根据 The information 报道,strawberry 目前能力最强的领域就在 math 和 code 上,Sonnet 3.5 在代码的提升也是很好的佐证。
这两个领域具有准确、快迭代的评判标准,使得模型能够获得明确的反馈:我们可以把 code script 放进 Python Interpreter/ compiler,把 math proof 放进 Lean(Lean 是一种编程语言,通过计算机验证数据定理,广泛用在 AI 形式化数学证明中帮助 AI 理解数学题),就能自动验证其准确性。
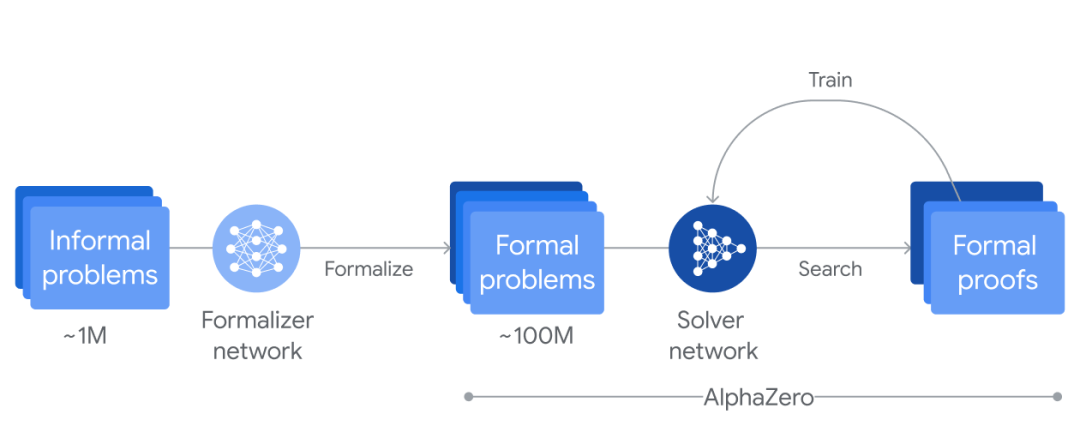
数学作为形式化逻辑的典范,拥有一套可验证、精准的符号系统。在这次 IMO 中,DeepMind 用 Alphaproof + AlphaGeometry 2 的方案成功获得银牌,Alphaproof 解决了 3 道题目,alphageometry 解决了 1 道题。其进行 做 RL 的方法有几个值得关注的点:
- Fine-tune Gemini 用于对数学问题形式化,生成了~100M 用于训练的数据。这个数据量远比人类解数学题需要的量大。
- 用 AlphaProof 和 Lean Compiler 作为外部监督信号告诉 solver network 其答案是否正确(今年 IMO 的题目是可以验证答案是否错误的),再利用 MCTS 搜索更好的答案并训练。
- 由于问题很难,Alphaproof 在推理过程中也会训练网络(这可能是为什么他耗时那么久),即针对特定问题 MCTS 采样后,会把采样中较好的 reasoning path 再投入训练,这种做法相当于对特定任务 finetune。
- AlphaProof & Alphageometry 2 拆成了两个策略网络来达到最好的效果。因为不同特定任务可能需要分别设置 prior,比如 AlphaGeometry 需要增加辅助线。
Code 领域的可验证性也非常强,AI 能通过 compiler/interpreter 自行验证可用性。如果不成功,报错信息也能帮助 AI 自己去发现和理解错误在哪里。而且 coding 领域相比 math 还有两个独特的优势:
• 海量高质量数据。开源领域已经有很多项目代码,而且其数据质量很高:有代码项目的文件结构、优化历史、遇到问题时的修复方案,还有大量基于自然语言的注释。
• 明确的分工方式。math 是一个比较个人英雄主义的领域,顶尖优秀的数学家进行自己的思维实验,能够与其同频协作的人非常少。而 code 领域已经出现了复杂分工:PM 理解需求设计原型、SWE 开发程序、QA 验证代码、SRE 进行运维。前面提到 self-play 其实是一个 multi-agent 分工环境,高效的分工影响了 RL 的质量上限。
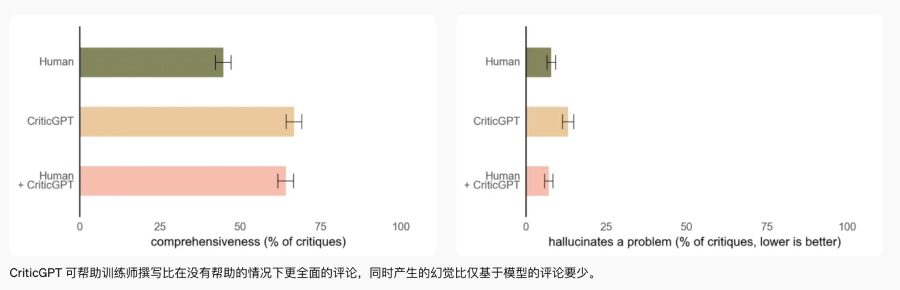
OpenAI 在今年 6 月宣布内部训练了 CriticGPT 用于 post-training,是一个 AI code verifier:CriticGPT 能够对 ChatGPT 生成的代码进行评估,识别出错误并提修改建议。其训练方式也比较直接:通过在代码中故意设置 bug 并进行详细标注,训练出能够 debug 的模型。尽管没有说明,我们相信其目标一定是给 Q-star 训练 reward model。
Anthropic Artifact 也是这个领域非常好的案例:Sonnet 3.5 从能生成 20 行可靠代码进化到可以生成 200 行,自然也就带来了这个产品 UI 上的创新。Anthropic 也完全有可能把这里的用户数据作为 reward model 喂回给模型,是比 ChatGPT 的数据飞轮更高效的。
如果说 ai for math 可能对人类的科学探索有很大帮助,ai for coding 是更能产生直接的经济价值的。知识工作者有非常多的任务可以用代码来定义并实现,只是目前没有公司能为个性化长尾需求写代码。这一部分可能是 RL 成熟之后最大的创业机会,这将在文章的第 4 部分继续深入。
2. reward model 对其他领域的泛化性并不明确
在数学和编程等领域,我们有明确的正确性标准,但在文本的开放域我们没有,很多时候任务的目标是模糊的、没有最优解,这让我们对智能通过 RL 在所有语言任务上产生泛化感到悲观:
• 物理、医药有明确的标准答案,但需要很长的实验验证周期。这两个领域看似是最接近 math、code 的,但缺少实验数据验证的 synthetic data 可用性无法保障。
• 法律、金融的问题往往没有通用解法,很难用通用的 reward model 实现。例如在科技投资中,一级市场研究就会 reward 前瞻性强的研究,而二级市场研究则对前瞻性的 reward 就相对少一些,reward 需要分配给很多强时效性的判断。
• 文字创意领域的 reward 很多时候不符合马尔可夫模型,也就是其 reward 常常会有跳变。一本好的小说、剧本,会讲究反转,试想 LLM next-token prediction 到一个反转之前其 reward 函数还很低,一个精彩的反转让 reward 函数突然大幅提升,self-play RL 很难捕捉这个突然的变化。
因此这里孕育着新范式下的第二个创业机会:垂直领域的 reward model,同样会在第 4 部分详细展开。
而要让 reward function 能捕捉到更多的信号,在垂直领域之外泛化,最重要的方向就是怎么用好 LLM 作为 reward model,并同时输出数字和文字评估。
3. LLM as a PRM (process reward model):通往泛化的重要路线
要实现泛化,背后的核心问题是怎么设计 reward function 才让数据信号能被更高效地运用,才能让 AI 循序渐进的学习。在 code 和 math 领域已经有了一些解决方案:使用 LLM 作为 PRM + curriculum learning。这套方法的持续突破,一定会让 reasoning model 训练得更好,配合 LLM 的语义表达能力甚至有可能实现 reward model 的泛化。
PRM (Process reward model) 是奖励好的推理步骤,而不仅仅是正确的结果。这更接近人类的学习和推理方式,实现方式常常是用 chain-of-thought 来表示推理过程,对每一步进行打分。这是因为 LLM 的语义理解能力才成为可能的。在传统 RL 中,我们按照最终结果评分,其评分模型称为 ORM(outcome reward model);而通过专门训练 LLM 成为 process verifier ,新的评分模型叫做 PRM,往往是使用娇小 LLM fine-tune 得到。
OpenAI 的 verify step-by-step 也是最近最重要的 paper 之一。他们训练的 PRM 在解决 MATH 数据集测试集中 78.2%的问题时表现优于 ORM。在今年 Google Research 的一篇 paper 中提到,PRM 在过程中一旦成功发现第一个错误,就能使 RL 训练效果显著提升。
而且在 process supervision 过程中,reward 的形式也不止限于数值,文字评价也可以作为指导模型继续行动的 reward。Google DeepMind 最新发布的 Generative Verifier 中,他们微调的 verifier 可以把问题每一步都用数值和文字评估,给模型作为 reward。
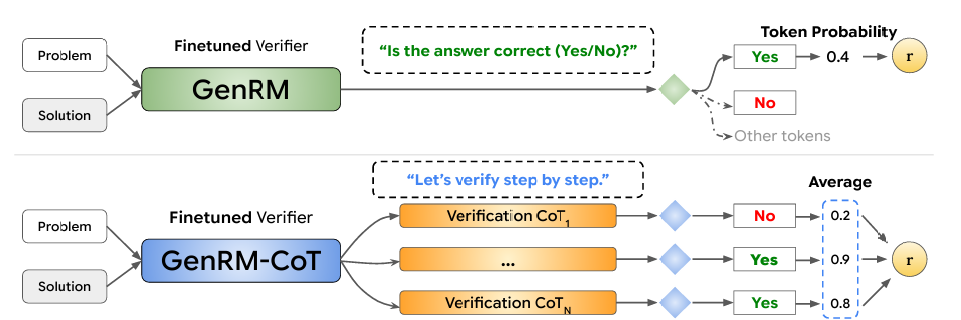
Process learning 保证了推理思考过程得到评估,而 Curriculum learning 是为了让思考过程得到由浅入深、循序渐进的引导,其核心理念是将复杂任务分解为多个难度递增的子任务,让智能体逐步学习。这样由简单到难的设计过程是很有必要的,这样一方面避免了 reward model 在早期过于稀疏的问题,一方面可以通过数据的多样性来使 LLM 学习最适合其能力的课程,防止出现下棋时能赢李世石、但不能赢公园老大爷的过拟合情况。
在课程学习中,有两种关键的奖励机制:探索奖励和竞争奖励。探索奖励是在完成简单子任务时给予的,旨在鼓励智能体学习基础技能。竞争奖励则是在完成最终复杂任务时给予的。为了平衡这两种奖励,课程学习引入了奖励退火机制:随着训练的进行,探索奖励逐渐减少,而竞争奖励的比重逐渐增加。课程学习的设计原则遵循一个渐进的过程。在训练的早期阶段,系统提供稠密的探索奖励,帮助智能体快速掌握基础技能。随着训练的深入,探索奖励逐步减少,竞争奖励的比重逐渐增加。
三、Scaling Law 范式变化
1. RL 合成数据的 unit economics 估算
在 RL 的新范式下,LLM 训练的 scaling law 需要被重写。因为训练时计算量不再只是和参数量的上升有关,还多了一个新变量:self-play 探索时 LLM inference 的计算量。RL 的思路本质是用 inference time 换 training time,来解决模型 scale up 暂时边际收益递减的现状。最近 DeepMind 也发布了一篇paper 叫做:Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters,正是在讨论这个范式变化。
在 MCTS 这样的树状搜索算法中,在树的每个节点多次模拟。在围棋这样范围相对确定的任务里,AlphaGo 的计算量已经很大。其训练过程模型通过反复进行 self-play,不断优化其 policy 和 reward 评估能力。在 AlphaZero 的训练中,模型进行了大约 500 万局自我对弈,每局大约 200 步,做好每一步平均需要 1600 次模拟。这使得总的模拟次数达到了 1.6 万亿次。
MCTS 中的树状结构示例
但 AlphaZero 只是一个千万参数量级的神经网络,和 LLM 差了 3-4 个数量级。要想搜索所有人类思考过程的可能性,还得处理更多数据和更复杂的参数,计算量只会更加庞大。要让 LLM 做这样大样本量的 self-play 的算力需求是非常大的。好在我们大部分的推理问题都可以拆解为一个 3-10 步的 chain-of-thought,接下来我们就计算一下 LLM 需要的推理成本,每一次模拟需要以下数据:
• context:问题和之前的推理过程。
• action:基于 context 接下来的行动选择。这里是和传统 RL 差异最大的地方,文字可以用无限开放的方式进行组合,而传统任务比如下围棋有着有限的决策空间。实践中一些 paper 提到 会用 temperature sampling 来生成 k 种回答(k 是一个固定数字,具体值需要实践),把这 k 个回答作为决策空间。我们可以按 k = 32 进行计算,也就是每一步推理需要 32 次 inference 模拟。
• reward:对每一步行动,需要输出 reward 来评估其效果。输出的 process reward 一定包括数值,可能也包括文字。
那么这三部分数据的推理成本我们可以做一个大致的简单估算:
• Agent model 是一个 50B LLM($0.5/M tokens),reward model 是一个 10B LLM($0.1/M tokens);
• Reasoning 任务有 5 步推理深度,每步会模拟 32 种结果,选取 top 10% 的推理结果往下推理,那么总计需要大约 10000 次模拟;
• 每一次模拟平均 1000 tokens;
那么一个推理任务的总成本为 6 美金。由于大部分 token 都是在重复 context,高质量比例不会很大,可以认为 10000 次模拟中有 1% 也就是 100 次模拟是有价值的(包括正例和负例,RL 中负例同样很有帮助的),也就是 100k tokens。
2. 新的scaling law 正在浮现:算力周期性从 scaling 转移到 inference-time compute
对于 GPT-4, Claude-3.5 水平的模型,我们推测要合成 1-10T 量级的高质量推理数据才能真正让模型大幅提升其推理能力,对应的成本大致需要 6-60 亿美金,这个在模型训练实验的算力中占的比例也是比较大的。
因此 RL 范式下,scaling law 仍然存在,计算成本仍然会大幅提升来获得更优的智能,但提升不再是模型的参数量本身的持续增长,而是通过 RL reasoning model 的方式来 scale up。今年中 OpenAI 正式推出了 mid-training 这个岗位,可能就是通过 RL reasoning model 合成大量高质量数据做继续学习。
但与预训练需求不同的是,inference 对单张卡性能和集群规模的需求相对低一些,也就是说不一定要最顶尖的卡、3 万卡以上的集群才能再能跑 RL inference。因此各家大厂要追求 RL 范式下的 scaling law 还是需要在 GPU 算力上持续投入,但一年内不会再去追求超大 H100 集群了。下一次大模型从 scaling up parameters 中获取智能的时间点,可能是明年下半年 NVidia B 系列的发布,可以实现更大的 20 万量级互联集群。
因此并不是未来 foundational model 就不再需要 scale up 了,未来的趋势可能是周期式的:2 年的 model scaling-up 周期,2 年的 RL reasoning 提升周期。硬件更新、类 transformer 架构优化、next token prediction 目标有关,都可能再次点燃模型 scale up 的趋势。
3. 推理成本大幅上升:MCTS 搜索加入 LLM inference
在去年的 LLM 范式预测中我们提到过,LLM 直接生成是可以类比系统 1 的慢思考。而 RL 就为 LLM 带来了系统 2 慢思考。
引入了 MCTS 之后,LLM inference 会变得更慢、更贵、更智能。因为每一次回答问题时都会推演很多种可能的思考路径,并自行评估哪一个能获得最高的 reward,然后再将最终的生成结果输出给用户。理想中越难的问题需要分配更多的算力和时间:简单问题 1s 直接输出答案,复杂问题可能需要 10min 甚至 10h 来思考最佳的解决方式。MCTS 实际推理中,可能是和之前我们预测成本的范式类似:把任务拆解成 5 步推理,每一步尝试 k 次模拟,搜索一整个决策树中的最佳方案。Alphago 下围棋时也是这么在推理时深度推演之后的下棋决策的,只是应用到 LLM 上对算力的要求更高了,需要更多智能剪枝等优化方式。
因此这一部分很难定量的计算其实际对推理需求带来了多大数量级的提升:理论上 MCTS 推演的策略集越全面一定是效果越好的,但是推理算力、用户体验的角度来说一定需要 LLM 厂商去做严格的资源约束,来达到性能和成本之间的平衡。
四、RL 新范式带来了什么创业和投资机会?
1. AI for coding 带来编程能力民主化
代码开发是最近 AI 提升最大、热度最高的领域,背后最重要的原因就是 sonnet3.5 的发布带来的推理能力的提升。这个提升最直接的 benchmark 就是写出可靠代码的行数:原本 4o 只能可以写 20 行可靠的代码,Sonnet 3.5 可以写 200 行。
如果 reasoning model 的突破把这个 benchmark 扩大到 1000 行,那么很多简单的代码项目其实不需要专业的开发者来完成,而是 ai 独立完成一整个项目。这时使用这类产品的用户数,都会有一个数量级的提升,每个项目的平均 DAU 会下降,对代码的性能要求也会降低。
我们会把 AI for coding 分为两类。第 1 类目前已经有比较成熟的产品了,而第 2 类在 reasoning model 出现前后才刚刚开始:
• AI for developers,为专业开发者的 ai 提效。这个领域已经有一些比较成熟的产品了,我们比较看好 AI IDE 的入口级效应和 e2e coding agent 对工作流的颠覆,Cursor 是目前明显的领先者。
• No-code AI developers,人人都成为产品经理,为自己的需求设计软件。完成一个软件项目的无代码开发品牌。
AI for developers
Cursor
Anysphere 是一家专注于开发 AI 驱动工具以提升软件开发效率的初创公司,其旗舰产品是名为 Cursor 的 AI IDE。加持了 Sonnet 3.5 之后,Sonnet 的产品口碑特别优秀,就像去年上半年我看到 Perplexity 的用户口碑那样。他们的产品对用户正在开发项目的 context 做了非常深入的理解,同时也有优秀的 chat UI,和各种支持 AI 协同编辑的快捷键。由于其产品体验很优秀,甚至可以在 Youtube 上看到一个美国的 8 岁女孩用 cursor 在 45 分钟内实现了一个自己想要的哈利波特 chatbot。
Cursor 团队下一步的开发目标也是 AI 自动化提升,减少 human in the loop。比如他们提到正在开发后台独立运行的 shadow workspace,AI 可以在其中持续自由修改代码、运行测试和获取反馈,而不会影响实际项目文件,并再将最终的建议反馈给用户。这样的 AI 沙盒的下一步就是 AI 能够独立完成所有代码,届时 Cursor 团队也完全有可能去切入一个更大的普通用户开发市场。
Zed
Zed 是一款由 Atom 和 Tree-sitter 的创建者开发的高性能多人代码编辑器。他们主打的特点是支持多人甚至 AI 实时协作编辑代码。开发者可以实时看到其他用户的编辑操作,同时多人修改同一个文件,并通过聊天、语音、视频会议等工具进行实时沟通。在发布了 Zed AI 之后,这样一些协同功能都有可能成为 AI 开发使用的重要 context。
这里盘点的还只是应用工具层的典型产品,还有 4-5 家 e2e agent 公司尚未发布产品,会在之后另外发布相关研究。

No-code AI developers
这个新赛道不是服务专业开发者的,而是能用低门槛方式服务普通用户的,设计出低门槛的交互方式非常重要。这就像摄像头在手机上便携之后,出现了 Instagram、Tik tok 这样的产品,产品的主要价值就在其前端交互帮助普通用户都能拍出高质量的照片视频并形成内容平台。
Websim
Websim 是这个领域中重要的交互创新,其 vison 是 no-code 的方式用 AI 生成模拟出一个新的互联网。其产品形态用内嵌的浏览器做交互,用户可以通过多次的 prompt 生成复杂度还不错的网页。
这个项目从今年初就已经出现了,而 Sonnet 3.5 让这个 idea 可以实现了。现在 Websim 社区中已经有各种 hobbyist 在开发产品,甚至由用户在其中开发出了一个完整的 3D 建模编辑器。用户可以在产品上不断迭代测试网站的原型,也可以浏览其他用户创作出的产品,有一些从工具到平台的转移。
用户在 Websim 上创作的 Google2.0
Wordware
Wordware 也在从工具到平台转移上做得很好。他们的产品用类似 notion 的方式做交互,把 IDE 的门槛降低,普通用户能像用 notion 文档一样构建一个好玩的 app。
Wordware 是 ProductHunt 最成功的发布之一,发布当天获得了 6151 票。他们在 10 天内有 700 万用户用了 twitter agent,新增 25 万 wordware 用户,总计注册用户达到 27.2 万。
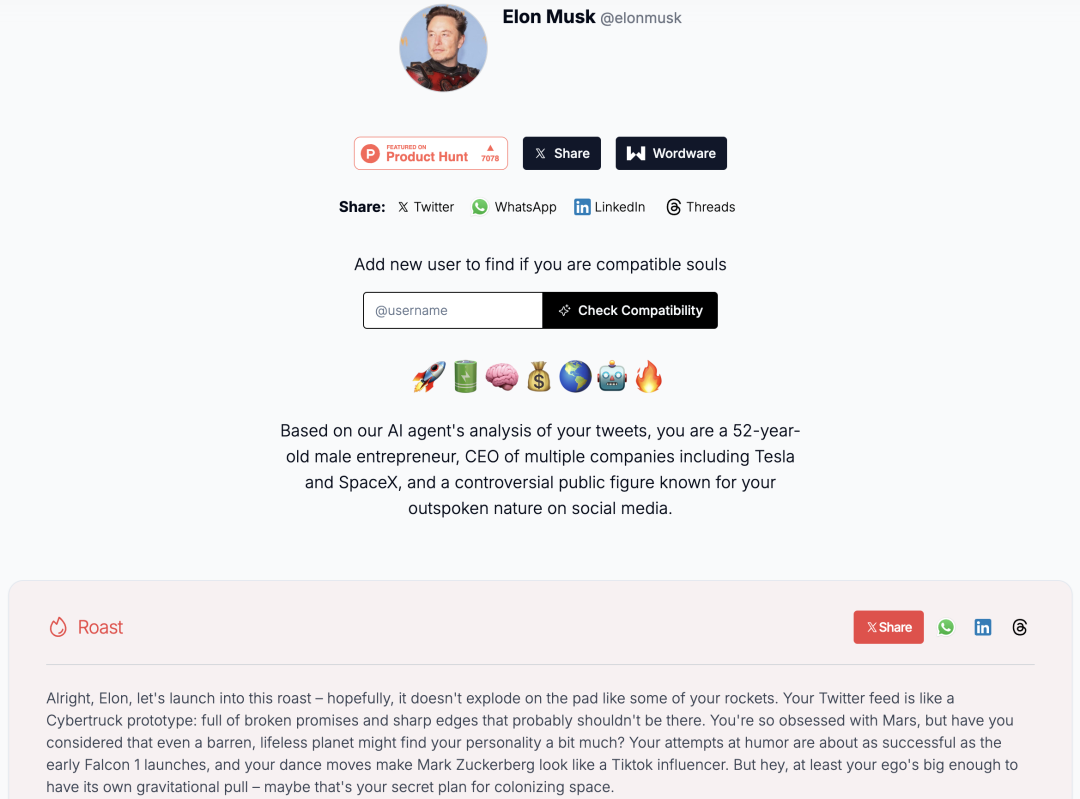
Wordware 团队擅长用自己的产品去推出病毒式传播的内容:twitter.wordware.ai。Wordware 的增长负责人 Kamil Ruczynski 提出了这个 idea:可以阅读你所有推文,对你的个性进行吐槽和分析的 AI Agent。这款 Agent 产品的核心逻辑非常简单:提示词 + 推特 API + AI,主打犀利吐槽、猎奇有趣,命中了最大量的 18-29 岁推特用户群体。
2. Reasoning model Lab 有新的模型层机会?
上一波范式下的 startup 开始收敛,Inflection、Adept、Character 都被收购。在新范式下又有新的 research lab 又涌现出来,其中我们认为最值得关注的有以下三家。
SSI
Safe Superintelligence Inc. (SSI) 是由 Ilya Sutskever、Daniel Gross 和 Daniel Levy 共同创立的公司,专注于开发安全的超级人工智能。他们公司还在 lab research 阶段,选择的很可能就是从有 self-play RL 的 LLM 路线开始。
Chief scientist Ilya 的前瞻性无需多言,从 AlexNet、Seq2seq、Dota Five 到 ChatGPT,他完整地引领了过去十年中所有 AI 领域的 milestone。SSI 是有了 Ilya 离开 OpenAI 才成为可能。
CEO Daniel Gross 在硅谷核心圈子的影响力很大。他出生于耶路撒冷,曾是 Y Combinator 的合伙人,投过 Uber、Instacart、Figma、Github 等项目。从 YC 离开后他和 Nat Fridman 一起创立了 AI grant,投资了 CAI、Perplexity 等项目。做投资人之前他 cofound 过搜索引擎公司 Cue,后来被苹果收购。这次和 Ilya 联合创立公司,他和 Sam Altman 的定位类似,为公司笼络足够多的商业资源。
CTO Daniel Levy 是 22 年加入 OpenAI 的 researcher,在 GPT-4 报告中定位是 Overall vision co-lead, optimization lead,并参与了 Training run babysitting,在多模态研究上担任了很核心的工作,离开前是 OpenAI optimization lead。此外关于他的信息不多,在 researcher 之间有着很好的口碑。
Harmonic
Harmonic 是一家由前 Robinhood CEO Vlad Tenev 和前 Helm AI CTO Tudor Achim 于 2023 年底 cofound 的公司。该公司专注于 AI for 数学推理的人工智能平台,并通过数学推理智能能力的不断提升去解决可验证的问题,未来可能通过 math + code 去解决医药、科学、金融等行业的问题。
他们最新的数学证明模型 Aristotle 已经在 MiniF2F 任务上做到了 90% 的准确度(MiniF2F 是一个数学规范问题 benchmark,问题来源于数学竞赛和大学课本)。他们还提到 Harmonic 开发了一种自动将自然语言问题和解决方案翻译为其形式表示的能力,称为自动形式化。这使得 Aristotle 能够与可能不熟悉 Lean 的数学家和教育工作者合作。优秀的模型能力和对 reasoning interpreter 交互泛化性的重视都是他们值得关注的原因。
Symbolica
严格来说,Symbolica 要做的事情和上文中的 RL 路线不同,他们更偏向符号主义方法论。不过由于他们主攻的方向也是基于代码、math 等形式化逻辑的 reasoning model,也应该放在这里作为一个差异化路线进行介绍。
Symbolica 的 vision 是将传统符号人工智能(通过定义的符号、规则集来解决任务)的数学抽象与神经网络结合起来,来开发开发可控、可解释的 AI 模型。他们模型最先解决的任务也会是生成代码、证明数学定理。
不过这个领域的竞争会非常激烈和 capital intensive, OpenAI、Anthropic、Google DeepMind 这三个 LLM 的头部玩家在 RL 领域的技术积累非常深,是否有其他创业公司弯道超车的机会还有待时间验证。
3. Vertical reward model 会成为应用层的新主题
Reward model 能泛化到整个文本推理领域的概率是比较小的,因为不同行业领域对 reward value 的定义非常不一样。这就留给创业公司去建立垂直领域 reward model 的创业机会,其具体如何与 LLM 结合还得看 Anthropic/OpenAI 是否会为公司开放 reward model fine-tune 的接口。但每一个垂直领域都是值得建立 reward model 的,因为大部分领域现在都会遇到 fine-tune 和 RAG 能解决问题有限的问题。
这个领域和 No-code AI developers 一样才刚刚开始,我们判断会有两类机会:
• 给一个垂直行业建立 reward model,比如金融/法律。以 Harvey 为代表。
• 给一类 agent 使用场景建立 reward model,比如操作浏览器。以 Induced AI 为代表。
Harvey
Harvey AI 我们之前发过一个独立的研究。他们的首个产品是一个在 GPT4 底座模型上加入大量法律专业数据 finetune 的 AI Chatbot,它的主要能力包括:
• 法律写作:撰写长篇、格式化的法律文件,帮助起草合同,撰写客户备忘录,作为工作起点;
• 掌握专业法律知识,可以回答复杂的法律问题等;
• 进行合同及文件的理解与处理。
这些任务都是在处理法律行业最 junior 的工作。如果要深入到行业中更为复杂、需要决策和行动的任务,需要与这些顶级律所持续合作制定一个法律行业专用的 reward model。由于 Harvey 是所有垂直领域中与 OpenAI 合作最为密切的(常常在 PR 中提到互相合作的案例),他们很可能也是最早有机会开始合作垂直领域 reward model 的。
Induced AI
Induced 是一个 AI-native 的浏览器自动化 RPA 平台。其收集用户使用数据的过程可以认为是在做 browser 领域的 reward model。
使企业能够用简单的自然语言输入 workflow,或给 AI 观看操作录屏视频,就能将指令实时转换为伪代码,模拟人类的网络浏览行为,自动浏览网页,收集并有效地处理和分析关键信息,来处理通常由后台管理的许多重复性任务,如销售、合规、内部运营等方面。它应用了一种双向交互系统,允许人类根据需要在某些步骤中进行干预,而其余步骤则由 AI 自主管理。
Induced AI 通过云优先构建,意味着自动化的任何任务都在后台运行,不会影响本地计算机。同时,在 Chromium 上专门构建了一个浏览器环境,用于自主工作流程运行。它拥有自己的内存、文件系统和认证凭证(电子邮件、电话号码),能够处理复杂流程。
总的来说,我们期待用 RL self-play + MCTS 提升 LLM 推理能力的方式能成为下一代技术范式,并实现智能的泛化,扮演 LLM 思考中的系统 2。这样一定能带来 AI reasoning 能力大幅提升,解锁很多 AI 应用 use case 的落地,带来新的一波 AI 创业投资机会。
本文由人人都是产品经理作者【海外独角兽】,微信公众号:【海外独角兽】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


