
 起点课堂会员权益
起点课堂会员权益AI大模型实战篇:Reflexion,为AI Agent开启强化学习之路
前面的文章中,作者分享了一种偏重反思的AI Agent设计模式,即Basic Reflection。但面对复杂度很高的产品时,还有另一种框架可以解决。就是本文介绍的Reflexion设计模式。

在文章《AI大模型实战篇:Basic Reflection,AI Agent的左右互搏之术》中,风叔结合原理和具体源代码,详细介绍了第一种偏重反思的AI Agent设计模式,即Basic Reflection。Basic Reflection 的思路非常朴素,就是通过左右互搏让两个Agent相互进化,实现成本也较低。
但是在实际应用中,Basic Reflection的Generator生成的结果可能会过于发散,和我们要求的结果相去甚远。同时,当面对一些复杂度很高的问题时,Basic Reflection框架也难以解决。有两种方法来优化Basic Reflection,一种是边推理边执行的Self Discover模式,一种是增加了强化学习的Reflexion模式。
上篇文章《AI大模型实战篇:Self Discover框架,万万想不到Agent还能这样推理》,风叔沿着“边推理边执行”的优化路线介绍了Self Discover。这篇文章中,风叔沿着“强化学习”这条优化路线,详细介绍下Reflexion设计模式。

01 Reflexion的概念
Reflexion本质上是强化学习,可以理解为是Basic reflection 的升级版。Reflexion机制下,整个架构包括Responder和Revisor,和Basic Reflection机制中的Generator和Reflector有点类似。但不同之处在于, Responder自带批判式思考的陈述,Revisor会以 Responder 中的批判式思考作为上下文参考对初始回答做修改。此外,Revisor还引入了外部数据来评估回答是否准确,这使得反思的内容更加具备可靠性。
下图是Reflexion的原理:
- Responder接收来自用户的输入,输出initial response,其中包括了Response、Critique和工具指示(示例图中是Search)
- Responder将Initial Response给到执行工具,比如搜索接口,对Initial Response进行初步检索
- 将初步检索的结果给到Revisor,Revisor输出修改后的Response,并给出引用来源Citations
- 再次给到执行工具,循环往复,直到循环次数
- Revisor将最终结果输出给用户

02 Reflexion的实现过程
下面,风叔通过实际的源码,详细介绍Basic Reflection模式的实现方法。关注公众号【风叔云】,回复关键词【Reflexion源码】,可以获取到Reflexion设计模式的完整源代码。
第一步 构建Responder
在下面的例子中,我们先构建一个Responder
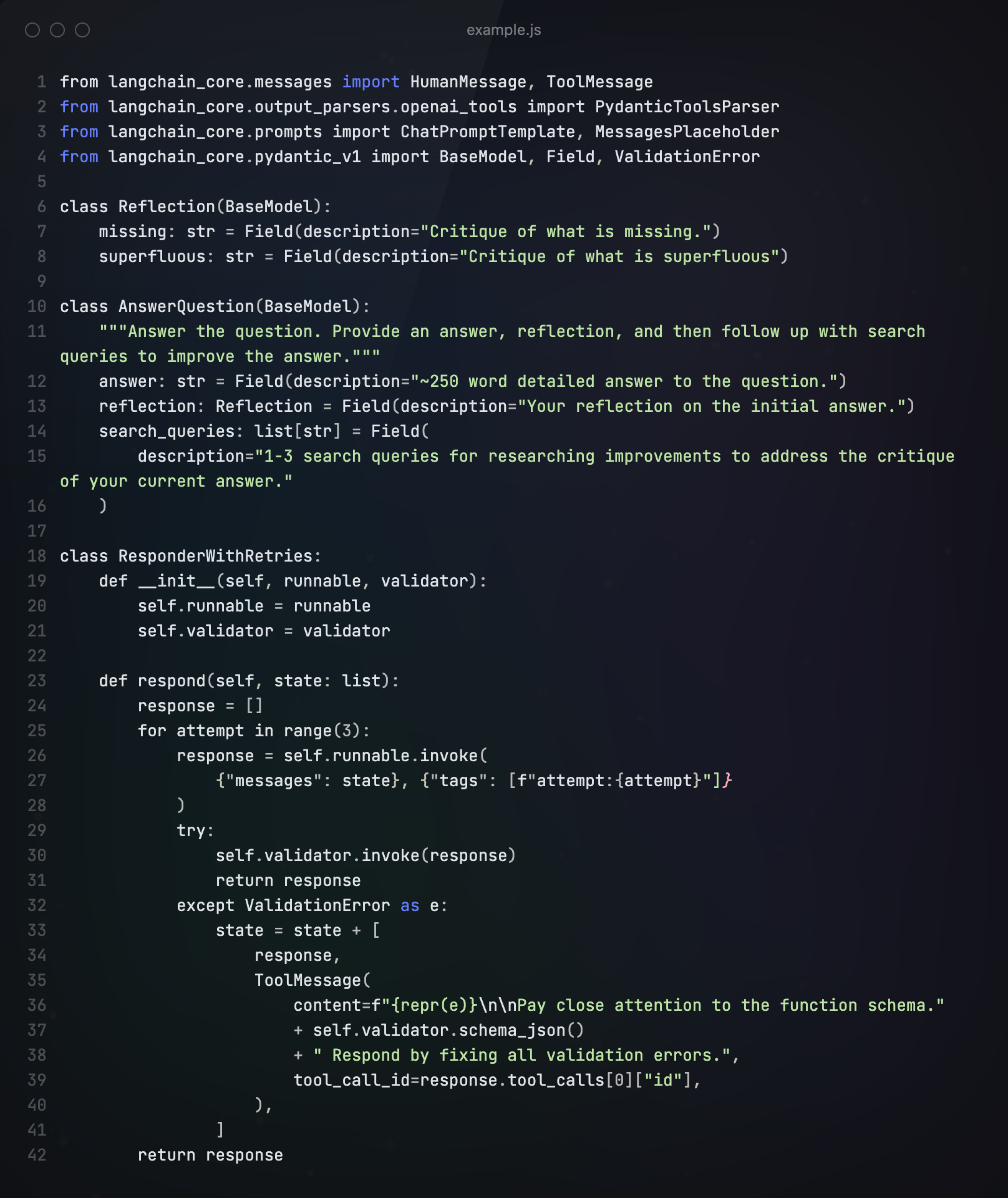
为Responder确定Prompt模板,并建立一个Responder。通过Prompt,我们告诉Responder,“你需要反思自己生成的答案,要最大化严谨程度,同时需要搜索查询最新的研究信息来改进答案”。
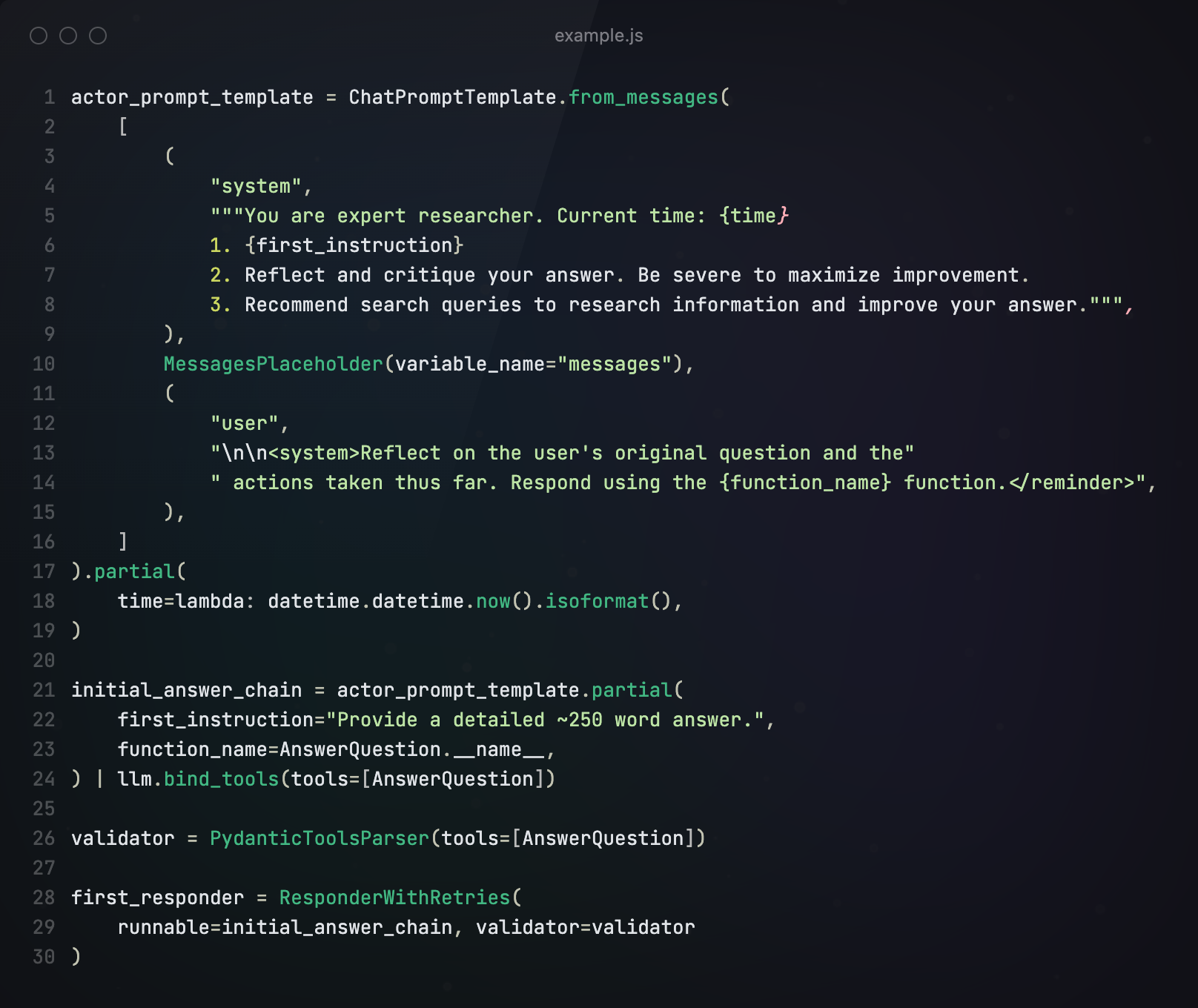
第二步 构建Revisor
接下来我们开始构建Revisor,通过Prompt告诉Revisor
- 应该使用之前生成的critique为答案添加重要信息
- 必须在修改后的答案中包含引用,以确保答案来源可验证
- 在答案底部要添加参考,形式为[1] https://example.com
- 使用之前的批评从答案中删除多余的信息,并确保其不超过 250 个字。
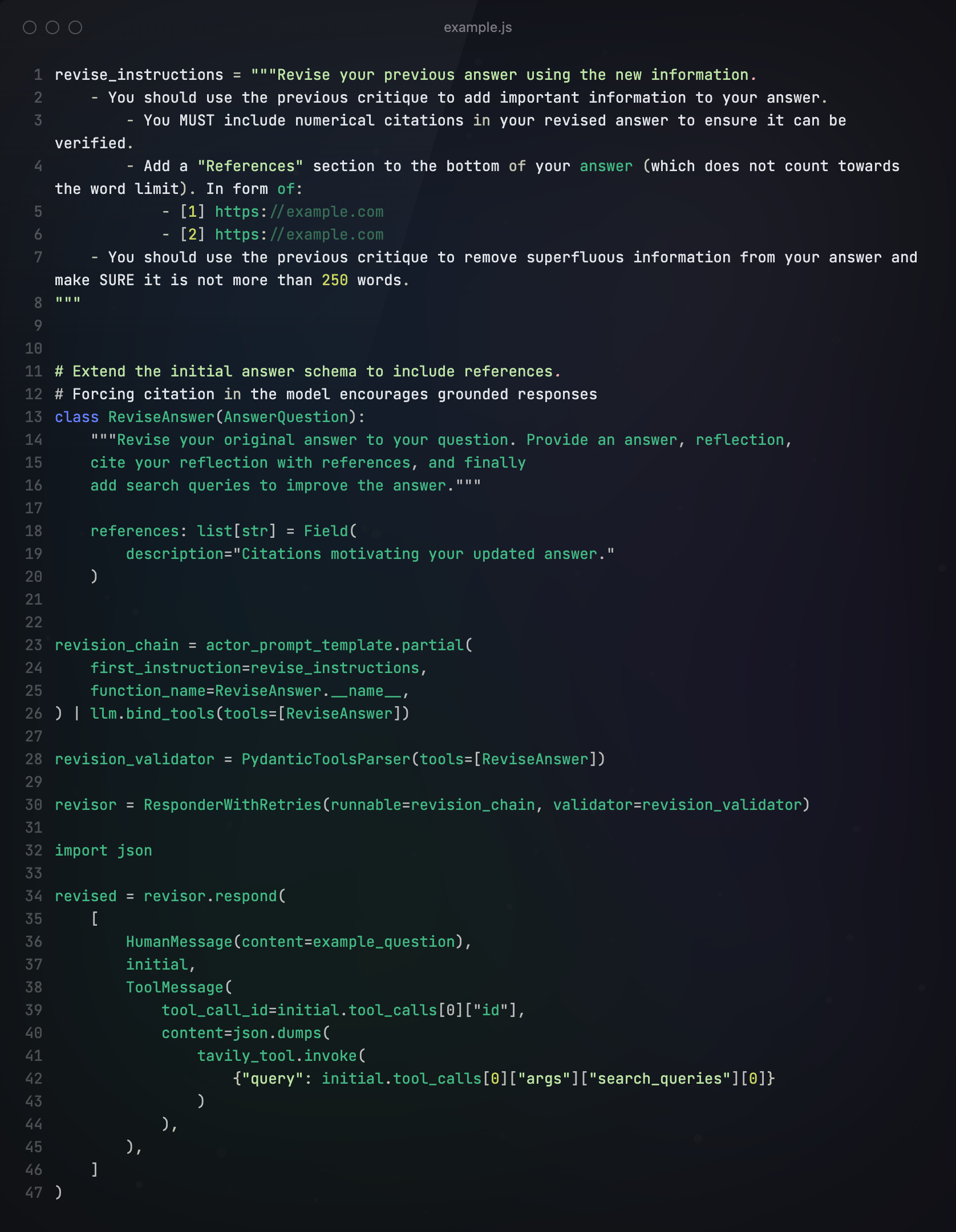
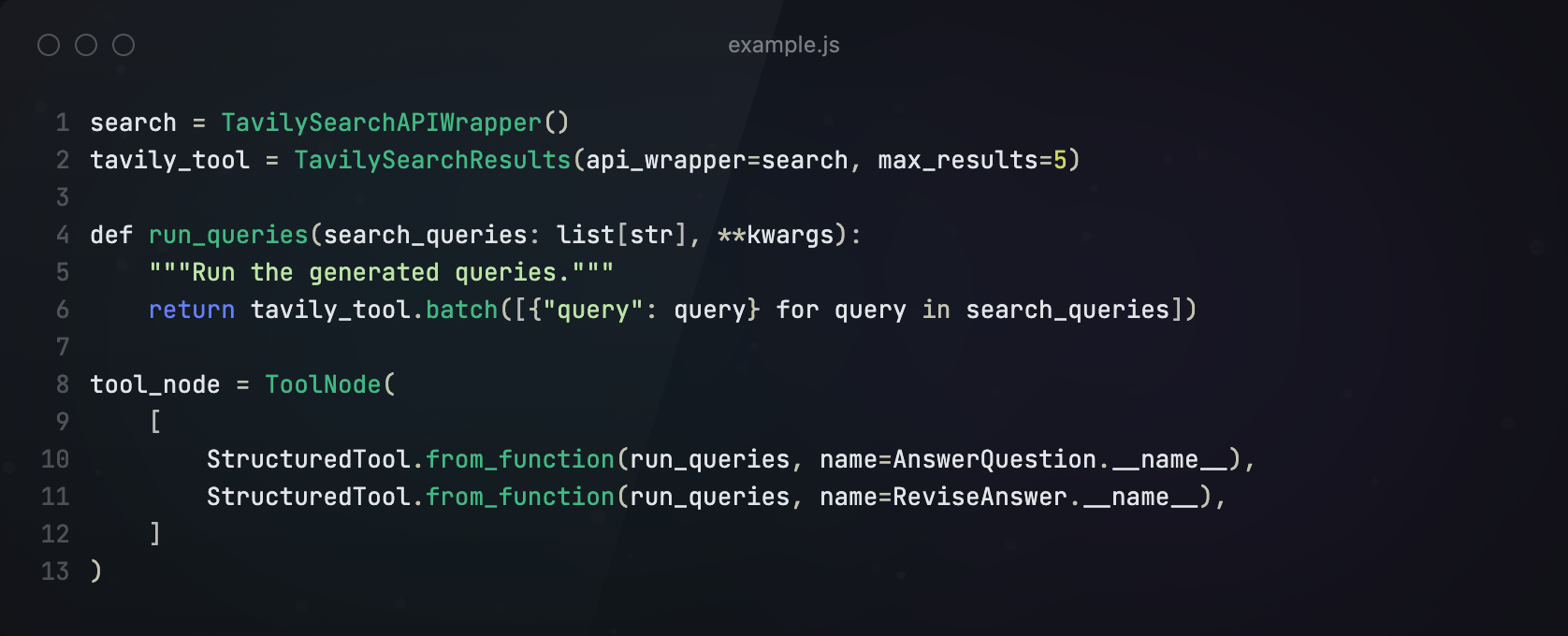
第三步构建Tools
接下来,创建一个节点来执行工具调用。虽然我们为 LLM 赋予了不同的模式名称,但我们希望它们都路由到同一个工具。
第四步构建Graph
下面,我们构建流程图,将Responder、Revisor、工具等节点添加进来,循环执行并输出结果。
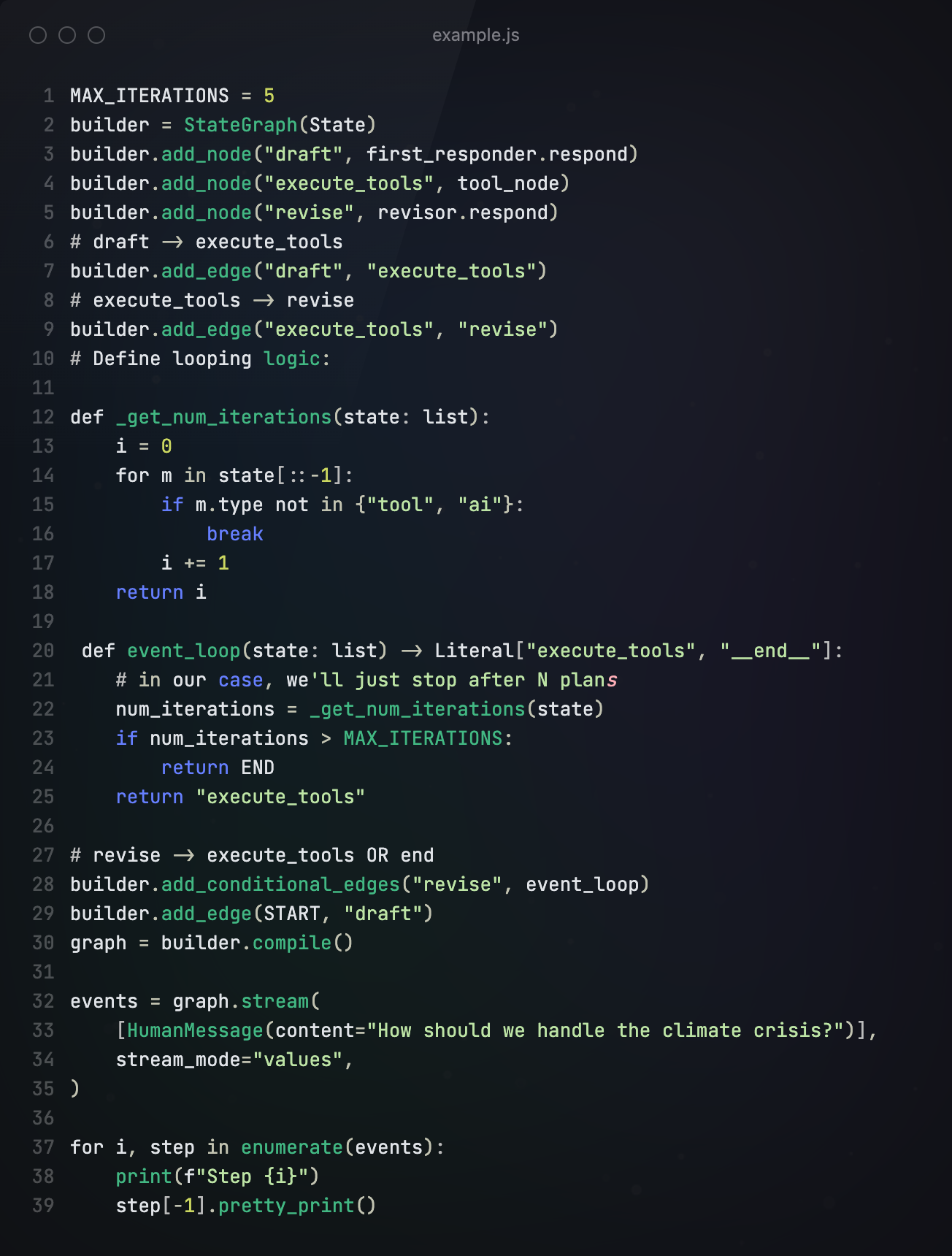
以上内容就是Reflexion的核心思想,其实完整的Reflexion框架要比上文介绍的更复杂,包括Actor、Evaluator和self-Reflection三块,上文的内容只涵盖了Actor。
- 参与者(Actor):主要作用是根据状态观测量生成文本和动作。参与者在环境中采取行动并接受观察结果,从而形成轨迹。前文所介绍的Reflexion Agent,其实指的就是这一块
- 评估者(Evaluator):主要作用是对参与者的输出进行评价。具体来说,它将生成的轨迹(也被称作短期记忆)作为输入并输出奖励分数。根据人物的不同,使用不同的奖励函数(决策任务使用LLM和基于规则的启发式奖励)。
- 自我反思(Self-Reflection):由大语言模型承担,能够为未来的试验提供宝贵的反馈。自我反思模型利用奖励信号、当前轨迹和其持久记忆生成具体且相关的反馈,并存储在记忆组件中。Agent会利用这些经验(存储在长期记忆中)来快速改进决策。

关于Reflexion完整的实现方案可参考:https://github.com/noahshinn/reflexion
总结
Reflexion是我们介绍的第一个带强化学习的设计模式,这种模式最适合以下情况:
智能体需要从尝试和错误中学习:自我反思旨在通过反思过去的错误并将这些知识纳入未来的决策来帮助智能体提高表现。这非常适合智能体需要通过反复试验来学习的任务,例如决策、推理和编程。
传统的强化学习方法失效:传统的强化学习(RL)方法通常需要大量的训练数据和昂贵的模型微调。自我反思提供了一种轻量级替代方案,不需要微调底层语言模型,从而使其在数据和计算资源方面更加高效。
需要细致入微的反馈:自我反思利用语言反馈,这比传统强化学习中使用的标量奖励更加细致和具体。这让智能体能够更好地了解自己的错误,并在后续的试验中做出更有针对性的改进。
但是,Reflexion也存在一些使用上的限制:
- 依赖自我评估能力:反思依赖于智能体准确评估其表现并产生有用反思的能力。这可能是具有挑战性的,尤其是对于复杂的任务,但随着模型功能的不断改进,预计自我反思会随着时间的推移而变得更好。
- 长期记忆限制:自我反思使用最大容量的滑动窗口,但对于更复杂的任务,使用向量嵌入或 SQL 数据库等高级结构可能会更有利。
- 代码生成限制:测试驱动开发在指定准确的输入输出映射方面存在限制(例如,受硬件影响的非确定性生成器函数和函数输出)。
在下一篇文章中,风叔将介绍目前最强大的AI Agent设计模式,集多种技术的集大成者,LATS。
本文由人人都是产品经理作者【风叔】,微信公众号:【风叔云】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


