
 起点课堂会员权益
起点课堂会员权益看懂OpenAI o1背后玄机!打破数据瓶颈,AI也能像人一样思考
OpenAI发布的o1系列模型标志着AI推理能力的飞跃,它在数学解题、代码生成等复杂任务上展现出了前所未有的能力,为AI向通用复杂推理的迈进铺平了道路!

今天凌晨,OpenAI发了一个新模型——OpenAI o1系列模型。
对比以往发布的模型,o1模型可以说相当有特色。用官方的说法,o1代表了现阶段AI最强的推理能力,尤其擅长解决数学解题、代码生成等等复杂推理任务。
OpenAI也很重视这个模型,没有用GPT继续给这个模型命名,而是采用了一个新名字:OpenAI o1。
Sam Altman更是将OpenAI o1的发布比作一个新阶段的开始:
可以进行通用复杂推理的AI。
那么,为什么AI学会复杂推理这么重要?o1的发布,又对AI通往AGI有着什么样的意义?
01 AI也会慢思考了
与之前发布的模型相比,o1最大的特点就是推理能力很强。
打个比方,之前大模型更像是文科生,擅长文本类工作,但逻辑推理和复杂计算方面差点意思,遇到奥数题目就歇菜。而o1则更像一个理科生,不仅能推理复杂任务,还能解决科学、编码和数学领域中比以往更为困难的问题。
o1的逻辑能力有多强?用OpenAI发布的一组图,你就明白了。
第一个图是o1参加AIME 2024的成绩。AIME 2024是国际数学奥林匹克竞赛(IMO)的资格考试,难度不言而喻。在这个比赛里,o1的准确率是83.3%,而GPT4o的准确率只有13.4%。
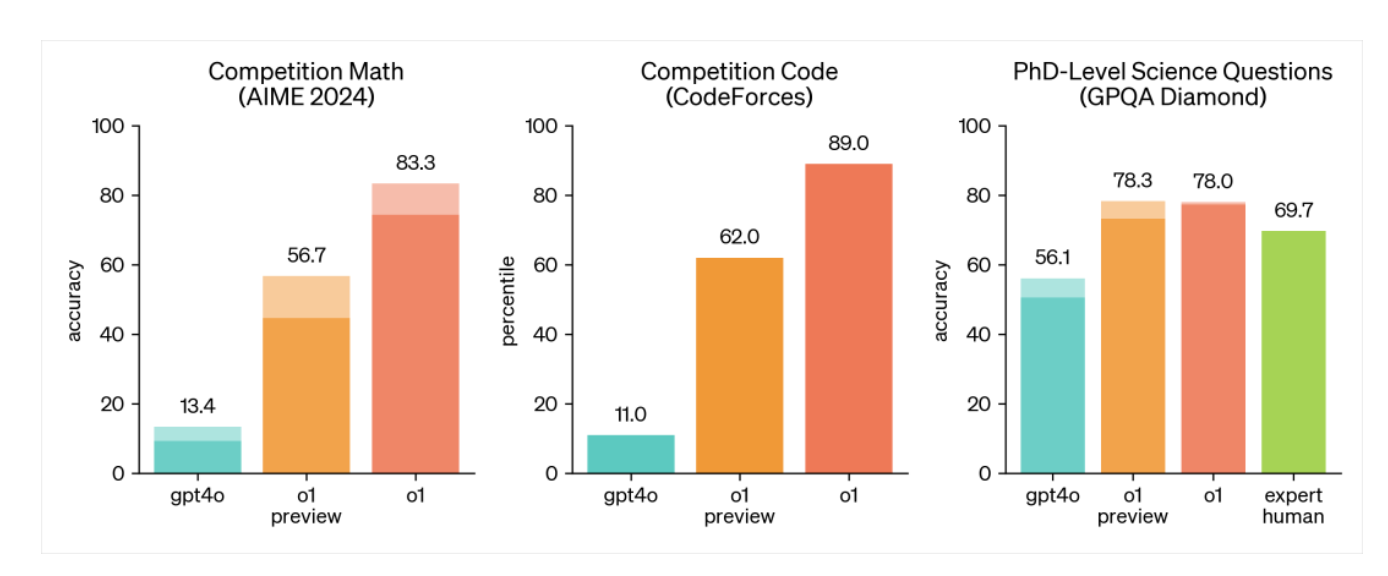
第二项是编程竞赛,o1的准确率高达89%,而GPT4o准确率只有11.0%。最后一项测试是GPQA Diamond,主要测试的是化学、物理和生物学方面的专业知识。在这个测试里,o1超越了人类专家的表现,成为第一个在这个测试中表现优于博士级别专家的模型。
这些测试结果表明,o1在数学、编程、科学等推理类任务上达到了新高度,甚至在某些任务上已经超过了人类专家的水平。
为什么o1的推理能力这么强?这得益于思维链的构建。
思维链,最早出现在2022年谷歌发布论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中,是大模型提示词(Prompting)工作的一种。
在o1回答问题前,会产生一个内部的思维链,思维链会把大模型没办法直接回答的复杂问题,分解为一个个简单的任务各自计算,然后把这些答案拼接在一起进行求解,而不是直接给出计算结果。
对于思维链的价值,知乎答主绝密伏击打过一个很形象的比喻:
 标准 Prompting
标准 Prompting
给大模型一道数学题,在标准Prompting下,模型无法做出正确的回答。但如果我们给模型一些关于解题的思路,在CoT提示下,它就会像我们数学考试,都会把解题过程写出来再最终得出答案,比如下图:
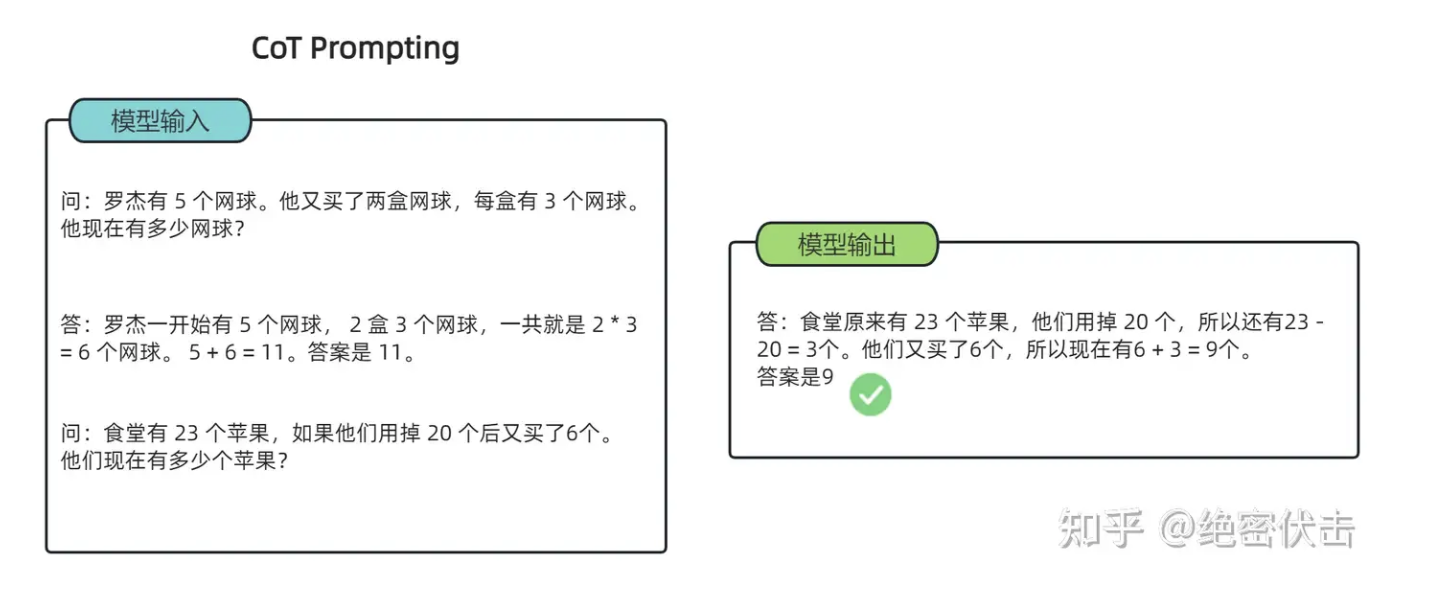 CoT提示
CoT提示
在这个过程中,大模型能够识别和修正自己的错误,不断改进推理策略。这种思维过程不仅让它的推理能力得到显著提升,还让模型在回答问题时更加可靠。
不过这种思维方式,需要更长的响应时间。理论上,大模型思考的时间越长,推理任务上的表现就越好,可以理解为用时间换取推理深度。
o1的发布补足了GPT模型在推理方面的缺陷,让AI更接近人类双系统的思考方式。
人类大脑在处理信息和做出决策通常有两种方式:快思考(系统1)和慢思考(系统2)。前者无意识且快速的,它依赖直觉、记忆和经验迅速作出判断。后者则有意识的、需要调动注意力的思考方式,它通过分析和解决问题,并作出决定,虽然较慢,但不容易出错。
这种互补性,也极有可能会出现在GPT和o1上。
GPT系列对应系统1,负责快速、直接决策,依赖于经验和情感,而o1则对应系统2,复杂较慢的思考和推理,依赖于逻辑和理性分析。
两种系统协同运作,当系统1快速反应不足以面对复杂情况时,系统2会介入进行更深入的分析,进而让AI最终能够让人一样思考。
当然,让AI像人一样思考,还不是o1唯一的意义。
02 智能提升的另一种路径
在o1发布后,OpenAI研究员诺姆·布朗(Noam Brown)在X上写下:
o1模型,意味着一种新的扩展范式。
这是o1发布的另一个重要意义。大模型将进入了一个新的扩张范式:从模型参数增大,转向强化学习的探索。
众所周知,过去一年里,大模型的升级全靠“大力出奇迹”的方式,也就是说,随着计算量、模型参数和数据集大小的增加,模型的性能通常会显著提高。
但现在这条路越来越不好走了。因为在这种训练模式下,大模型需要大量且优质的训练数据,但这带来了两个问题:
一是随着训练需要的数据量越来越大,去哪找这么多高质量数据是个问题。二是喂了这么多数据,大模型学习方式本质还是归纳总结,但并没有真正搞懂事物的逻辑。
举个例子,大模型发现人渴了,就需要喝水。大模型理解了口渴和喝水之间的关联性,但它可能没办法理解,为什么人渴了,要喝水。这也是为什么大模型面对复杂问题时,经常出现逻辑错误的原因。
在这种情况下,就需要新的扩张范式来提升大模型的智能能力。于是,强化学习进入了AI大厂的视野。
所谓的强化学习,是让AI在一个环境里自己探索。在探索过程中会得到很多反馈,这些反馈有好的,也有不好的,AI再根据反馈不断调整自己的策略和对环境的认知。
这样的策略以前在AlphaGo身上也用过。为了提高AlphaGo的围棋水平,研究员让AlphaGo自己和自己下棋,从而产生大量高水平的棋谱,这有点像金庸武侠小说里老顽童周伯通的左右互搏武功。再通过下棋输赢(或者平棋)的结果对走棋路径进行评估。
在后来的AlphaZero训练里,模型进行了大约500万局自我对弈,每局大约200步,做好每一步平均需要1600次模拟。这使得总的模拟次数达到了1.6万亿次。大量的高质量合成数据,最终让AI探索出和人类不一样的游戏套路,并战胜了大部分职业选手。
从本质上说,这个方法是用AI无限的计算能力,来补足它数据利用效率不够的短板。也就是说,只要扩张推理计算能力,就能实现大模型智能水平的提升。
这更符合当下AI发展的现状。相比寻找更大规模的优质数据,通过基建实现推理算力的增长是一条更可行的路径。
如今,有了思维链,大模型可以把推理过程中的每一步思考都记录下来,并进行打分,再根据评分高低反馈给模型进行调整。在这个过程中,大模型不仅能学到如何给出正确答案,还能举一反三获得更多的数据反馈,进而提升其智能水平。
当然,作为刚刚发布的新模型,o1仍然有很多的缺陷。但在GPT5遥遥无期的情况下,这至少给行业带来了新的思路。至于这条路线究竟是否会将我们带向AGI,我们可以拭目以待。
文/林白
本文由人人都是产品经理作者【乌鸦智能说】,微信公众号:【乌鸦智能说】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


