
 起点课堂会员权益
起点课堂会员权益o1 能带我们走进 AGI 吗?
OpenAI 推出的 o1 模型,以其独特的推理模式,在编程和数学领域展示了显著的能力,引发了对通向 AGI(通用人工智能)新路径的广泛讨论。

最近,OpenAI 突然发布了 o1 模型,也就是传闻中的“🍓”模型,可能也是早先提到的 Q* 模型。
虽然这并非最强的原始版本,只是一个预览版,但它展示了一种不同于以往语言模型的推理模式:1 在生成结果前会先生成一条思考链,经过“思考”后再给出回复,这使得它在编程和数学方面的表现明显提升。
o1 的发布这些天引发了广泛的关注和讨论。
有些人非常激动,认为 o1 开辟了一条通向 AGI(通用人工智能)的新路径;也有人感到失望,觉得 o1 的实际表现还不如 Claude 3.5 或 GPT-4o,等待了这么久却只得到一个性能平平的模型。
我倾向于前者,对 o1 这个方向持乐观态度。并非因为 o1 的数学能力特别强,或者它能理解晦涩的小说内容,而是 o1 似乎真的探索出了大力出奇迹的一条新的方向,那就是在推理上的大力出奇迹,或者有学术一点的说法,叫推理规模扩展定律(inference scaling law)。
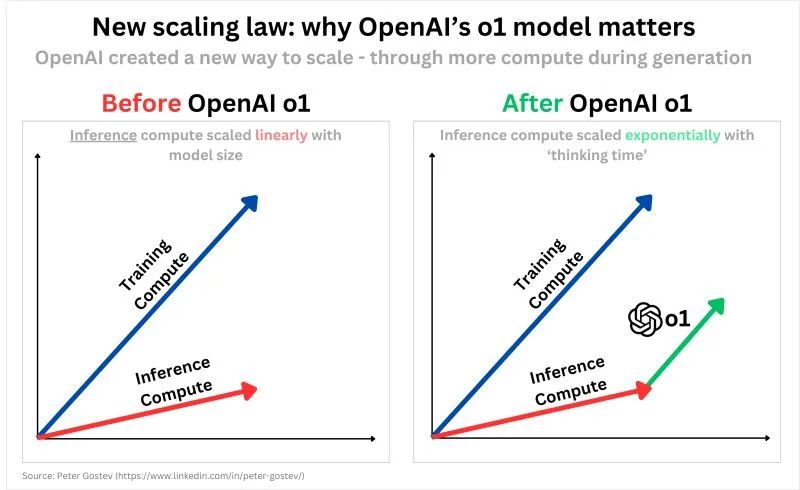
以前我们谈论的大力出奇迹或者说规模扩展定律(Scaling Law),主要针对的是训练过程,意味着训练数据越多、算力越强、模型参数越大,最终的模型性能就越好。因此,我们一直在追求更大的规模。
而推理规模扩展定律则是另一条路径,就是模型训练完成后,它会在推理上消耗很多算力,用算力和时间换取推理能力的大幅提升。
从 OpenAI 新发布的 o1 上就可以看到这条路径的实际应用:在生成结果前,要花大量的算力和时间在推理上,先生成思维链(Chain of Thought,CoT),借助思维链提升推理能力,得到更好的结果,甚至连复杂的奥数题都可以轻松解出来。
很多人对 o1 的思维链不屑一顾,觉得:“这不就是‘让我们一步一步思考’么?我在提示词让模型按照给定步骤生成也能类似的效果!”也有的找了一堆模型相互 PK,认为就是达到推理模型的效果了。
对于某些特定任务,这可能可行。例如,我曾设计过一个翻译提示词,让模型分三步:先直译、再反思、最后意译,效果相当不错。
但问题在于,大语言模型需要应对各种各样的任务,我们不可能为每一种任务都编写一套思维链提示词,这不现实。所以,我们需要模型自己生成思维链,能够针对每个任务自主搜索最佳路径,生成最合适的思维链,达到最好的推理和生成效果。
要训练模型自己生成思维链并不是意见容易的事情,因为你需要大量的思维链训练语料,还要有合适的奖励模型,奖励模型生成的好的思维链,惩罚生成的不好的思维链。但 o1 的发布证明这条路是可行的,我们可以让模型自己生成思维链。
OpenAI 并未透露他们的具体训练方法,但推测是在后期训练阶段,通过强化学习,利用大量的数学题和代码库,训练模型生成解题的思维链。然后,根据结果和过程,对模型的行为进行奖励或惩罚,提升其生成思维链的能力。
当像 o1 这样的推理模型训练成功后,它就具备了强大的推理能力。对于输入的任务,能够生成高质量的思维链,通过增加算力和时间投入,可以显著提升模型的推理效果,大力出奇迹。
那么,是否意味着只要拥有无限的计算能力和时间,推理模型就能超越人类,完成许多复杂的任务呢?
这让我想到了 AutoGPT——一个可以自主规划和分解任务,自动完成目标的智能体。最初,人们期望只要给它足够的 Token 和时间,它就能帮助人类完成复杂的任务。
但现实并不如人意,AutoGPT 很少能产生可靠的结果。限制它的正是其推理能力;面对许多任务,它无法有效地规划和分解,因而无法取得理想的结果。
o1 也是如此。能否通过计算能力换取智能,取决于其推理能力是否足够强大,能否在各种任务中生成高质量的推理过程。
目前,o1 在数学和编程领域表现突出,文字解密方面也有不错的表现,但在其他领域的推理能力尚未展现出来,还需要看后续的发展。不过从 OpenAI 内部人士的发言来看,他们自己是信心满满。
Greg Brockman: 根据我们的发布数据,在今年的国际信息学奥林匹克竞赛(IOI)中,模型在模拟人类条件下(每道题 50 次提交)取得了第 49 个百分位/213 分。但在每道题 10,000 次提交的情况下,模型得到了 362.14 分——超过了金牌线。因此,模型的潜力远比表面看起来的要大得多。
Jason Wei:AIME 和 GPQA 的结果确实很好,但这不一定能转化为用户可以感受到的东西。AI 使用人类语言来建模思维链在很多方面都很棒。
该模型可以做很多类似人类的事情,比如将复杂的步骤分解为更简单的步骤、识别和纠正错误以及尝试不同的方法。游戏已被彻底重新定义。
Shengjia Zhao:它不会完美,也不会适合所有事情,但它的潜力再次让人感到无限。再次感受到 AGI。
William Fedus:「ChatGPT 现在可以先仔细思考,而不是立即脱口而出答案。最好的类比是,ChatGPT 正在从仅使用系统 1 思维(快速、自动、直觉、容易出错)进化到系统 2 思维(缓慢、深思熟虑、有意识、可靠)。
这让它能够解决以前无法解决的问题。从今天 ChatGPT 的用户体验来看,这是向前迈出的一小步。
在简单的提示下,用户可能不会注意到太大的差异(但如果您遇到一些棘手的数学或编码问题,您会注意到的🙂 )。但这是未来发展的重要标志。
也许他们已经实现了类似于 AlphaGO 那样自己训练自己的模式,让模型的推理能力可以持续提升。如果未来 o1 能在大部分领域展现出强大的推理能力,那么我们就可以在任务中,通过增加算力和时间上的投入,换取超越人类的智能,实现大力出奇迹,真正迈向 AGI。
至少就目前而言,o1 已经在编程和数学领域展示了强大的能力。尤其是在编程方面,如果能通过算力和时间换取高质量的代码,也能创造巨大的价值!
目前推理规模扩展定律这方面 OpenAI 还是走在前面,他们也没有透露太多细节,但就像 Sora 一样,只要我们知道在推理上大力出奇迹这个方向是可行的,开源模型将会很快跟进,很快就会有接近 o1 推理能力的开源模型出现。
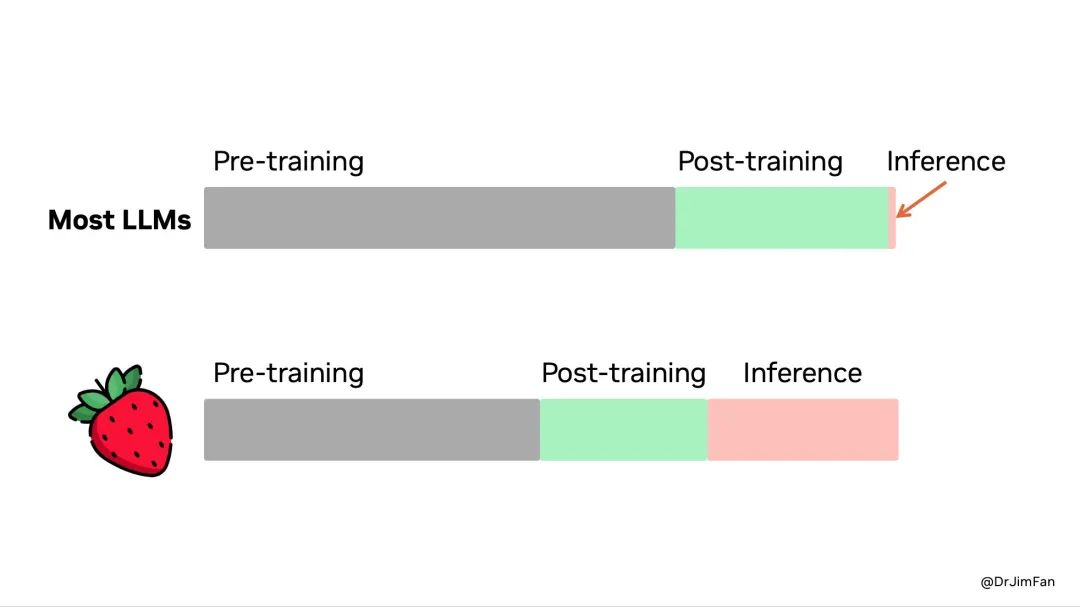
看来,未来对算力的需求还会进一步增加。
来自大聪明:
我之前写了这两篇,和宝玉在陈述同一事实,但角度不同。
《「草莓」实测:可能只是工程 Trick,且有扣费陷阱!》
《150 行代码,复刻「草莓」,青春版支持联网》

另一点,也是我和宝玉的一致结论:
o1 的对齐,应该是推理部分完全不对齐。
它的推理部分,有点像有多个模型,各司其职,有专门审查的模型。
没有隐藏的推理token做不到,现在就可以了,毕竟不需要马上输出。
顺着给大家看一个《来》的测试:
微小说《来》解读测试:
这是一篇著名的微小说,思想没那么纯洁的成年人都能懂这部小说隐含的那种意思,但是 AI 能吗?测试下来 GPT-4o 是懂的,但是表达的很隐晦,Claude 似乎是懂装不懂,o1 mini 就完全不懂,o1 preview不止懂,还直白的描述出来了。
 小说《来》
小说《来》

o1 的解读

Claude 3.5 Sonnet
可以发现,只有 o1 是答对了的,然后告诉你,你这个问题违反了使用规范。
如果用 gpt-4o 进行回答 + cot&react 进行呢?

模棱两可的「o1 青春版」
本文由人人都是产品经理作者【赛博禅心】,微信公众号:【赛博禅心】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


