
 起点课堂会员权益
起点课堂会员权益【数据治理】主数据识别的影响因素和识别方法
在当今数据驱动的商业环境中,对数据的有效管理变得尤为重要。其中,主数据管理(MDM)作为确保企业数据质量和一致性的关键环节,一直受到数据管理者的重视。

01.影响主数据判定和识别的因素
上一篇文章(【数据治理】主数据的基本概念和未来展望),在说明主数据的基本概念时,给出了主数据的一些关键词:稳定、复用、高价值。
但是主数据的判定和识别不能脱离具体场景和情况。某一个数据,在不同的情况下,可能会有不同的判定和识别结果。这也是之前文章提到过的。
“在具体实践过程中,主数据并没有一个金科玉律般的标准。同一行业不同企业、同一企业不同发展阶段,主数据都可能是不一样的。”
那么,有哪些影响主数据判定和识别的因素呢?
一般情况下,主数据是相对稳定的。比如,公司的产品信息、供应商信息、组织架构、用户信息等。但是主数据也会随着业务发展阶段、业务运营模式和业务管控策略发生变化,这种情况下,企业就需要根据具体情况进行主数据的增删操作。
1. 业务发展阶段
随着业务的发展,某些数据的重要性开始提升并开始在不同系统内被重复使用,业务对这些数据的稳定性提出了更高的要求。因此,这些数据就需要纳入主数据管理的范畴。
比如,现在有一个商店,业务发展初期维护了基本用户信息。随着业务更好地发展,推出了会员体系。此时,会员信息会被很多其他业务系统重复使用,因此,用户的会员相关数据,就需要纳入到主数据管理范畴。
2. 业务运营模式
随着市场需求的变化,技术的进步,外部竞争环境的变化等,企业也不得不主动或被动地转变业务运营模式,而运营模式的转变,会影响主数据的划分。
比如,京东在初期,以线下销售为主。在2004年开始尝试线上销售,后逐步发展为以线上销售为主。
如果京东从一开始就有主数据管理的话,可能在初期,更关注实体店铺的运营,主数据可能主要集中在商品信息、供应链信息、库存数据等方面。
线上销售时期,除了初期的主数据,还会把线上的商铺信息、用户信息等都纳入到主数据管理。
同样的一个案例,也是因为业务运营模式的调整,导致主数据划分发生了变化。只不过是对现有主数据进行删减。
2022年比亚迪宣布自2022年3月起停止燃油汽车的整车生产。这次调整,可能会对产品信息数据、零部件数据产生影响。
3. 业务管控策略
对于一些大型的集团,想要掌控各个分公司的客户数据,是非常困难的,阻力很大。所以,即使集团总部想掌握这些重要的客户数据,但是因为没有办法被总部利用,没有办法在总部流通和使用,所以分公司的客户,销售数据,不算主数据。
02.主数据识别方法
主数据的识别是主数据管理中最终的一项工作。主数据不是拍脑袋确定的。需要有比较科学合理的方法。接下来介绍两种主数据识别的方法。
1. 主数据特征识别法
「如果有一个动物长得像鸭子,叫声像鸭子,走路像鸭子,那么它是鸭子」
主数据特征识别法就是这种思路。假如某个数据完全符合主数据的特征,那可以肯定的说,这个数据就是主数据。
在定义的基础上,扩展一下,可以从以下的几个角度来判断数据是否是主数据。
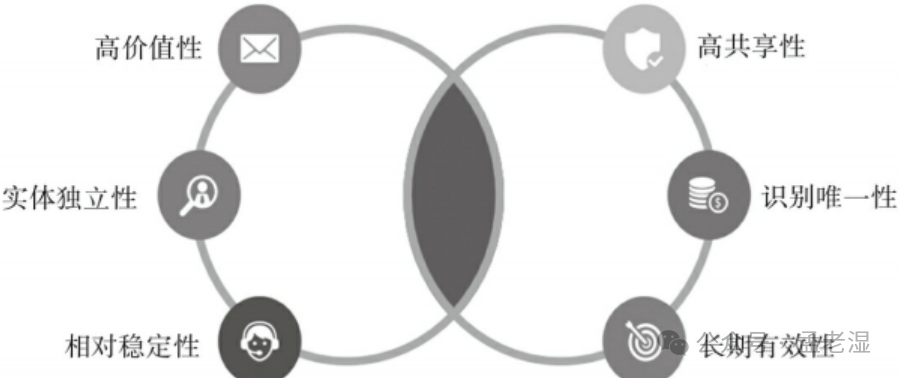
- 高价值性:主要看是否体现业务的核心价值。客户的基本信息肯定是具有核心价值的,但是客户的配送地址所在省份就不是核心价值数据了;
- 实体独立性:主要体现在不可分割性和完整性。例如,主数据管理中比较高频的客户主数据。客户主数据是作为一个整体被管理的,其包含的各个信息项(名称、联系方式、账户等)不会被单独查分出来作为独立的数据实体进行管理。完整性指的是,公司在维护相关实体数据时,会尽可能全面地收集信息,以确保数据的完整、准确;
- 相对稳定性:主数据在时间范围内保持相对稳定、不频繁发生变更是主数据的一个重要特征。在线教育行业会维护用户的基本信息,其中年龄是一个每年都会变更的数据,那么年龄就不是主数据,而可以把不变更的生日数据维护进主数据;
- 高共享性:是否被其他系统引用是一个很重要的特征,即使某个数据具有非常高的价值,但是,它只在某一个系统内流转,那也不能算是主数据;
- 识别唯一性:主数据具有权威性,而权威性体现在识别唯一性。有些数据在系统内是不具备识别唯一性的。比如,用户昵称;
- 长期有效性:短期、临时使用的数据,一般不会作为主数据。
可以做一个表格,对数据进行判断。对各个维度进行评估,然后根据每个维度的评估情况判定是否是主数据。

2. 业务共享矩阵法
在特征识别法中,有6个特征。那么,这6个特征是否可以简化一下,这样主数据识别也会更简便些。
在6个特征中,可以只选取高价值和高共享。
其他的4个特征,从某种层面讲,是这两个特征的衍生。高共享在一定程度上决定了,数据一定是识别唯一性的。其他的特征也可以推理出。
基于此,有了评估数据的重要程度和共享程度的业务共享矩阵法。
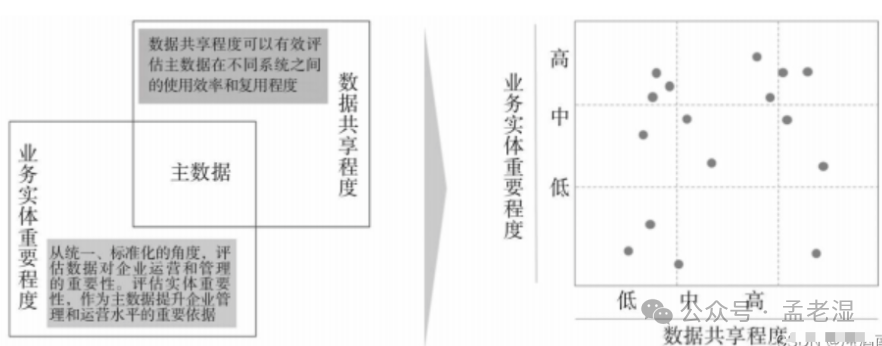
根据两个维度对字段进行评估,双高的大概率是主数据,双低的大概率不是主数据,难点就在于如何区分那些中间状态的。
我自己总结了一个方法。可以从原点到最右上角画一条直线。越靠近线右上角的,越有可能是主数据,不过,采用这个办法也有可能拿不准,这就需要有业务经验,数据治理经验的专业老师进行区分了。这个步骤,主要是把那些明显是,大概率是,明显不是,大概率不是的数据区分出来。
本文由 @孟老湿 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


