
 起点课堂会员权益
起点课堂会员权益RAG实战篇:优化数据索引的四种高级方法,构建完美的信息结构
在构建高效的检索系统(RAG)时,优化索引是提升系统性能的关键步骤。这篇文章深入探讨了如何通过高级技术手段对索引进行优化,以实现更快速、更准确的信息检索,供大家参考。

在《RAG实战篇:构建一个最小可行性的Rag系统》中,风叔详细介绍了RAG系统的实现框架,以及如何搭建一个最简单的Naive Rag系统。
Indexing(索引)是搭建任何RAG系统的第一步,也是至关重要的一步,良好的索引意味着合理的知识或信息分类,召回环节就会更加精准。在这篇文章中,围绕Indexing(索引)环节,如下图蓝色部分所示,风叔详细介绍一下如何对输入文档·构建合理的索引。
![]()
在实际应用场景中,文档尺寸可能非常大,因此需要将长篇文档分割成多个文本块,以便更高效地处理和检索信息。
Indexing(索引)环节主要面临三个难题:
首先,内容表述不完整,内容块的语义信息容易受分割方式影响,致使在较长的语境中,重要信息被丢失或被掩盖。
其次,块相似性搜索不准确,随着数据量增多,检索中的噪声增大,导致频繁与错误数据匹配,使得检索系统脆弱且不可靠。
最后,参考轨迹不明晰,检索到的内容块可能来自任何文档,没有引用痕迹,可能出现来自多个不同文档的块,尽管语义相似,但包含的却是完全不同主题的内容。
下面,我们结合源代码,介绍Chunk optimization(块优化)、Multi-representation indexing(多层表达索引)、Specialized embeddings(特殊嵌入)和Hierachical Indexing(多级索引)这四种优化索引的高级方法。
1. Chunk optimization(块优化)
在内容分块的时候,分块大小对索引结果会有很大的影响。较大的块能捕捉更多的上下文,但也会产生更多噪声,需要更长的处理时间和更高的成本;而较小的块噪声更小,但可能无法完整传达必要的上下文。
第一种优化方式:固定大小重叠滑动窗口
该方法根据字符数将文本划分为固定大小的块,实现简单。但是其局限性包括对上下文大小的控制不精确、存在切断单词或句子的风险以及缺乏语义考虑。适用于探索性分析,但不推荐用于需要深度语义理解的任务。
text = "..." # your text
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size = 256,
chunk_overlap = 20)
docs = text_splitter.create_documents([text])第二种优化方式:递归感知
一种结合固定大小滑动窗口和结构感知分割的混合方法。它试图平衡固定块大小和语言边界,提供精确的上下文控制。实现复杂度较高,存在块大小可变的风险,对于需要粒度和语义完整性的任务有效,但不推荐用于快速任务或结构划分不明确的任务。
text = "..." # your text
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 256,
chunk_overlap = 20,
separators = ["nn", "n"])
docs = text_splitter.create_documents([text])第三种优化方式:结构感知切分
该方法考虑文本的自然结构,根据句子、段落、节或章对其进行划分。尊重语言边界可以保持语义完整性,但结构复杂性的变化会带来挑战。对于需要上下文和语义的任务有效,但不适用于缺乏明确结构划分的文本
text = "..." # your text
docs = text.split(".")第四种优化方式:内容感知切分
此方法侧重于内容类型和结构,尤其是在 Markdown、LaTeX 或 HTML 等结构化文档中。它确保内容类型不会在块内混合,从而保持完整性。挑战包括理解特定语法和不适用于非结构化文档。适用于结构化文档,但不推荐用于非结构化内容。以markdown为例
from langchain.text_splitter import MarkdownTextSplitter
markdown_text = "..."
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])第五种块优化方式:基于语义切分
一种基于语义理解的复杂方法,通过检测主题的重大转变将文本划分为块。确保语义一致性,但需要高级 NLP 技术。对于需要语义上下文和主题连续性的任务有效,但不适合高主题重叠或简单的分块任务
text = "..." # your text
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter()
docs = text_splitter.split_text(text)2. 多层表达索引
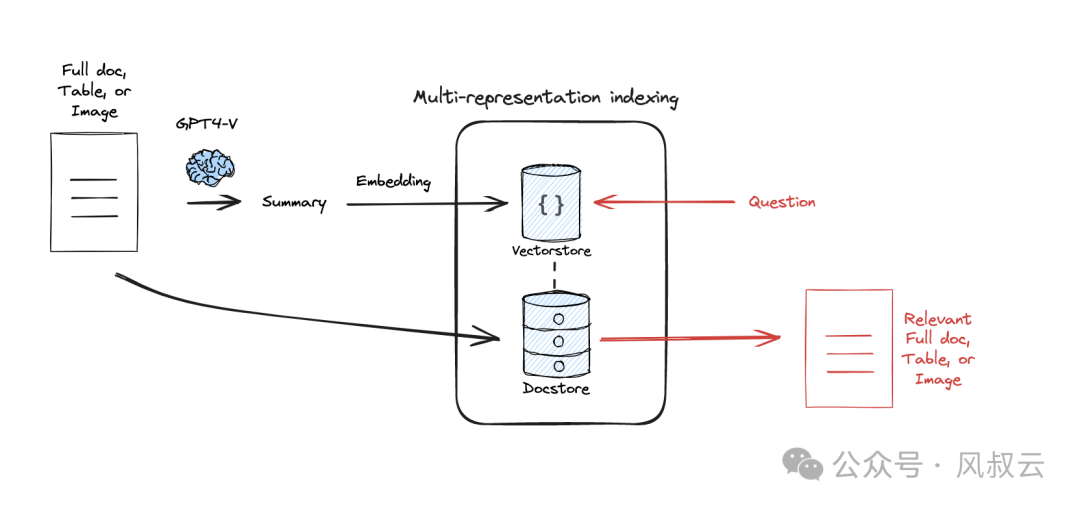
多层表达索引是一种构建多级索引的方法,在长上下文环境比较有用。
这种方法通过将原始数据生成 summary后,重新作为embedding再存到summary database中。检索的时候,首先通过summary database找到最相关的summary,再回溯到原始文档中去。
首先,我们使用 WebBaseLoader 加载两个网页的文档,在这个例子中,我们加载了 Lilian Weng 的两篇博客文章:
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
loader = WebBaseLoader("https://lilianweng.github.io/posts/2024-02-05-human-data-quality/")
docs.extend(loader.load())模型使用 ChatOpenAI,设置为 gpt-3.5-turbo 版本,利用 chain.batch 批量处理文档,使用 max_concurrency 参数限制并发数。
import uuid
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("Summarize the following document:nn{doc}")
| ChatOpenAI(model="gpt-3.5-turbo",max_retries=0)
| StrOutputParser())
summaries = chain.batch(docs, {"max_concurrency": 5})我们引入了 InMemoryByteStore 和 Chroma 两个模块,分别用于存储原始文档和总结文档。InMemoryByteStore 是一个内存中的存储层,用于存储原始文档,而 Chroma 则是一个文档向量数据库,用于存储文档的向量表示。
from langchain.storage import InMemoryByteStore
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.retrievers.multi_vector import MultiVectorRetriever
#The vector store to use to index the child chunks
vectorstore = Chroma(collection_name="summaries", embedding_function=OpenAIEmbeddings())
#The storage layer for the parent documents
store = InMemoryByteStore()MultiVectorRetriever 类帮助我们在一个统一的接口中管理文档和向量存储,使得检索过程更加高效。
id_key = "doc_id"
#The retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,)
doc_ids = [str(uuid.uuid4()) for _ in docs]将总结文档添加到 Chroma 向量数据库中,同时在 InMemoryByteStore 中关联原始文档和 doc_id。
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(summaries)]#Add
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))执行检索操作,对于给定的查询 query = “Memory in agents”,我们使用 vectorstore 进行相似性检索,k=1 表示只返回最相关的一个文档。然后使用 retriever 进行检索,n_results=1 表示只返回一个文档结果。
query = "Memory in agents"
sub_docs=vectorstore.similarity_search(query,k=1)
#打印sub_docs[0]
retrieved_docs=retriever.get_relevant_documents(query,n_results=1)
#打印retrieved_docs[0].page_content[0:500]3. 特殊向量
特殊向量方法常用于多模态数据,比如图片数据,利用特殊的向量去做索引。
ColBERT是一种常用的特殊向量方法,它为段落中的每个标记生成一个受上下文影响的向量,同时也会为查询中的每个标记生成向量。然后,每个文档的得分是每个查询嵌入与任何文档嵌入的最大相似度之和。
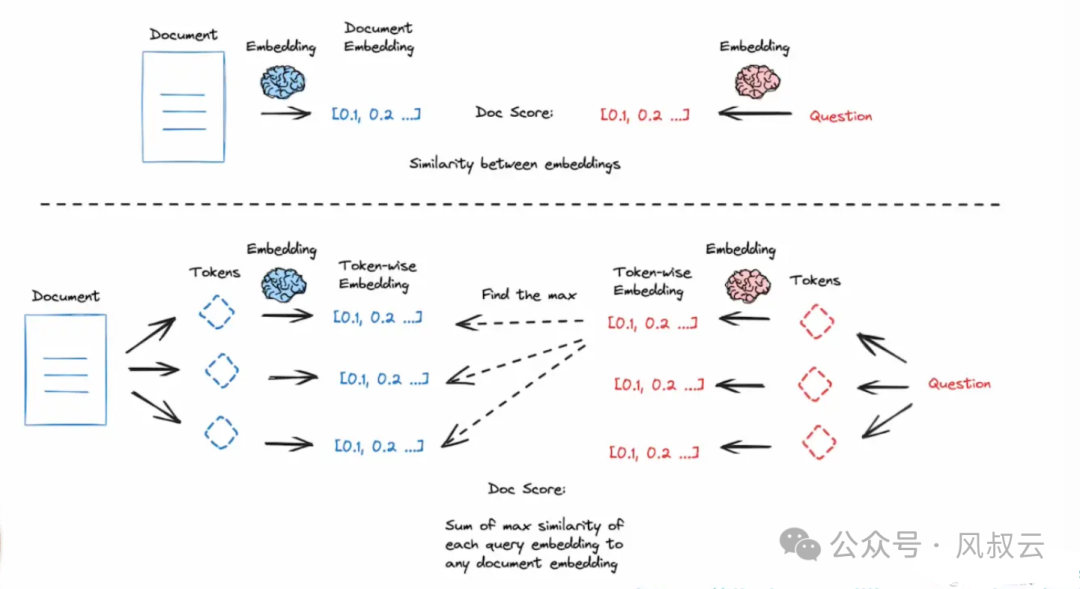
可以使用RAGatouille工具来快速实现ColBERT,首先引入RAGatouille。
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")然后我们获取文档数据,这里我们选择了使用wiki页面
最后,完成索引的构建,自动使用ColBERT方法完成索引。
RAG.index(
collection=[full_document],
index_name="Miyazaki-123",
max_document_length=180,
split_documents=True,)4. 分层索引
分层索引,指的是带层级结构的去索引,比如可以先从关系数据库里索引找出对应的关系,然后再利用索引出的关系再进一步去搜寻basic数据库。前文介绍的多层表达索引也属于分层索引的一种。
还有一种更有效的分层索引方法叫做Raptor,Recursive Abstractive Processing for Tree-Organized Retrieval,该方法核心思想是将doc构建为一棵树,然后逐层递归的查询,如下图所示:
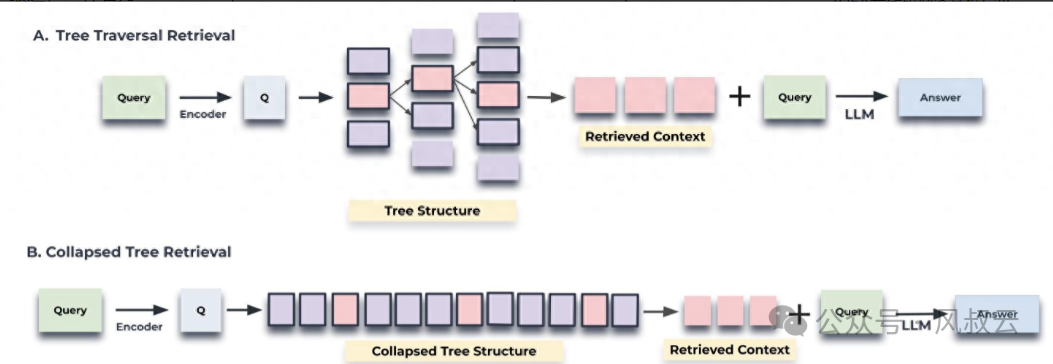
RAPTOR 根据向量递归地对文本块进行聚类,并生成这些聚类的文本摘要,从而自下而上构建一棵树。聚集在一起的节点是兄弟节点;父节点包含该集群的文本摘要。这种结构使 RAPTOR 能够将代表不同级别文本的上下文块加载到 LLM 的上下文中,以便它能够有效且高效地回答不同层面的问题。
查询有两种方法,基于树遍历(tree traversal)和折叠树(collapsed tree)。遍历是从 RAPTOR 树的根层开始,然后逐层查询;折叠树就是全部平铺,用ANN库查询。
Raptor是一种非常高级和复杂的方法,源代码也相对比较复杂,这里就不贴出来了,只从整体上介绍一下Raptor的逻辑。大家可以通过上文介绍的方法来获取源码。
首先,我们使用LangChain 的 LCEL 文档作为输入数据,并对文档进行分块以适合我们的 LLM 上下文窗口,生成全局嵌入列表,并将维度减少到2来简化生成的聚类,并可视化。
然后,为每个Raptor步骤定义辅助函数,并构建树。这一段代码是整个Raptor中最复杂的一段,其主要做了以下事情:
- global_cluster_embeddings使用UAMP算法对所有的Embeddings进行全局降维,local_cluster_embeddings则使用UAMP算法进行局部降维。
- get_optimal_clusters函数使用高斯混合模型的贝叶斯信息准则 (BIC) 确定最佳聚类数。
- GMM_cluster函数使用基于概率阈值的高斯混合模型 (GMM) 进行聚类嵌入,返回包含聚类标签和确定的聚类数量的元组。
- Perform_clustering函数则对嵌入执行聚类,首先全局降低其维数,然后使用高斯混合模型进行聚类,最后在每个全局聚类内执行局部聚类。
- Embed_cluster_texts函数则用于嵌入文本列表并对其进行聚类,返回包含文本、其嵌入和聚类标签的 DataFrame。
- Embed_cluster_summarize_texts函数首先为文本生成嵌入,根据相似性对它们进行聚类,扩展聚类分配以便于处理,然后汇总每个聚类内的内容。
- recursive_embed_cluster_summarize函数递归地嵌入、聚类和汇总文本,直至指定级别或直到唯一聚类的数量变为 1,并在每个级别存储结果。
接下来,生成最终摘要,有两种方法:
- 树遍历检索:树的遍历从树的根级开始,并根据向量嵌入的余弦相似度检索节点的前 k 个文档。因此,在每一级,它都会从子节点检索前 k 个文档。
- 折叠树检索:折叠树检索是一种更简单的方法。它将所有树折叠成一层,并根据查询向量的余弦相似度检索节点,直到达到阈值数量的标记。
接下来,我们将提取数据框文本、聚类文本、最终摘要文本,并将它们组合起来,创建一个包含根文档和摘要的大型文本列表。然后将该文本存储到向量存储中,构建索引,并创建查询引擎
最后,用一个实际问题进行检验,可以看到实际的回复内容还是比较准确的。
# Question
response =rag_chain.invoke("What is LCEL?")
print(str(response))
############# Response ######################################
LangChain Expression Language (LCEL) is a declarative way to easily compose chains together in LangChain. It was designed from day 1 to support putting prototypes in production with no code changes, from the simplest "prompt + LLM" chain to complex chains with hundreds of steps. Some reasons why one might want to use LCEL include streaming support (allowing for the best possible time-to-first-token), async support (enabling use in both synchronous and asynchronous APIs), optimized parallel execution (automatically executing parallel steps with the smallest possible latency), retries and fallbacks (a great way to make chains more reliable at scale), access to intermediate results (useful for letting end-users know something is happening or debugging), input and output schemas (providing Pydantic and JSONSchema schemas inferred from chain structure for validation), seamless LangSmith tracing integration (maximum observability and debuggability), and seamless LangServe deployment integration (easy chain deployment).到这里,优化索引的四种高级方法就介绍完了。
总结
在这篇文章中,风叔详细介绍了优化Indexing(索引)的具体方法,包括Chunk optimization(块优化)、Multi-representation indexing(多层表达索引)、Specialized embeddings(特殊嵌入)和Hierachical Indexing(多级索引)这四种优化方案。
在下一篇文章中,风叔将重点围绕Query Translation(查询转换)环节,介绍精准识别用户查询意图的五种高级优化方法。
本文由人人都是产品经理作者【风叔】,微信公众号:【风叔云】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


