
 起点课堂会员权益
起点课堂会员权益RAG实战篇:优化查询转换的五种高级方法,让大模型真正理解用户意图
在这篇文章中,我们将深入探讨如何通过高级查询转换技巧,优化大型语言模型的理解能力,从而更准确地把握用户的意图。

在《RAG实战篇:构建一个最小可行性的Rag系统》中,风叔详细介绍了Rag系统的实现框架,以及如何搭建一个最基本的Naive Rag系统。
在这篇文章中,围绕Query Translation(查询转换)环节,如下图红框所示,风叔详细介绍一下如何让大模型更准确地理解用户输入意图。
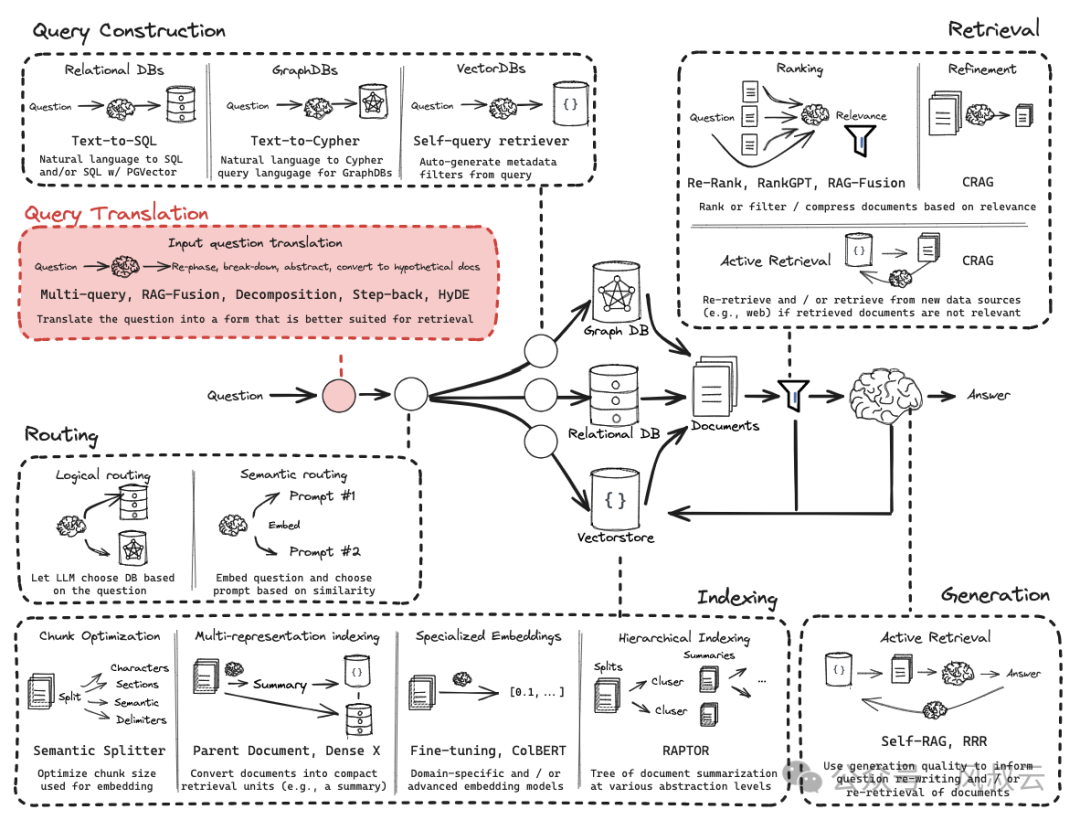
Query Translation(查询转换)主要处理用户的输入。在Naive Rag中,往往直接使用原始Query进行检索,这样会存在三个问题:
第一,原始query的措辞不当,尤其是涉及到很多专业词汇时,query可能存在概念使用错误的问题;
第二,往往知识库内的数据无法直接回答,需要组合知识才能找到答案;
第三,当query涉及比较多的细节时,由于检索效率有限,大模型往往无法进行高质量的回答。
下面,我们结合源代码,在查询转换环节实现Multi-query(多查询)、Rag-Fusion、Decomposition(查询分解)、Stepback和HYDE这五种优化方案。
一、Multi-query(多查询)
Multi-query是指借助提示工程通过大型语言模型来扩展查询,将原始Query扩展成多个相似的Query,然后并行执行,是一种非常简单直观的优化方案,如下图所示。
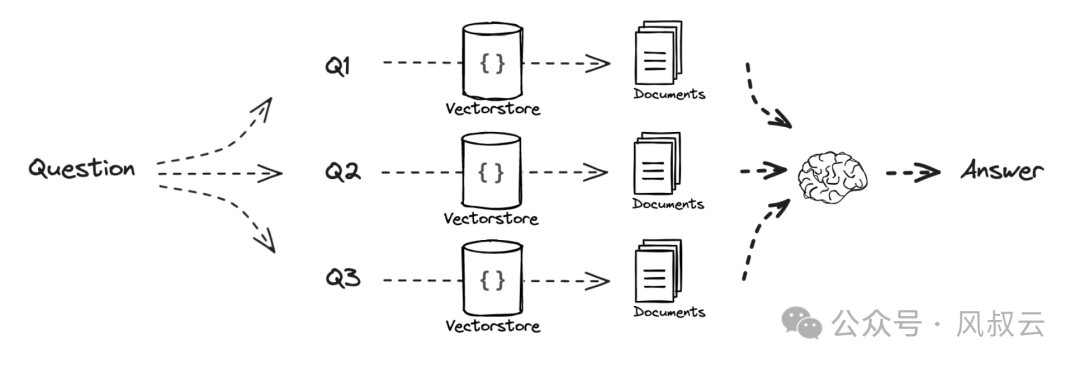
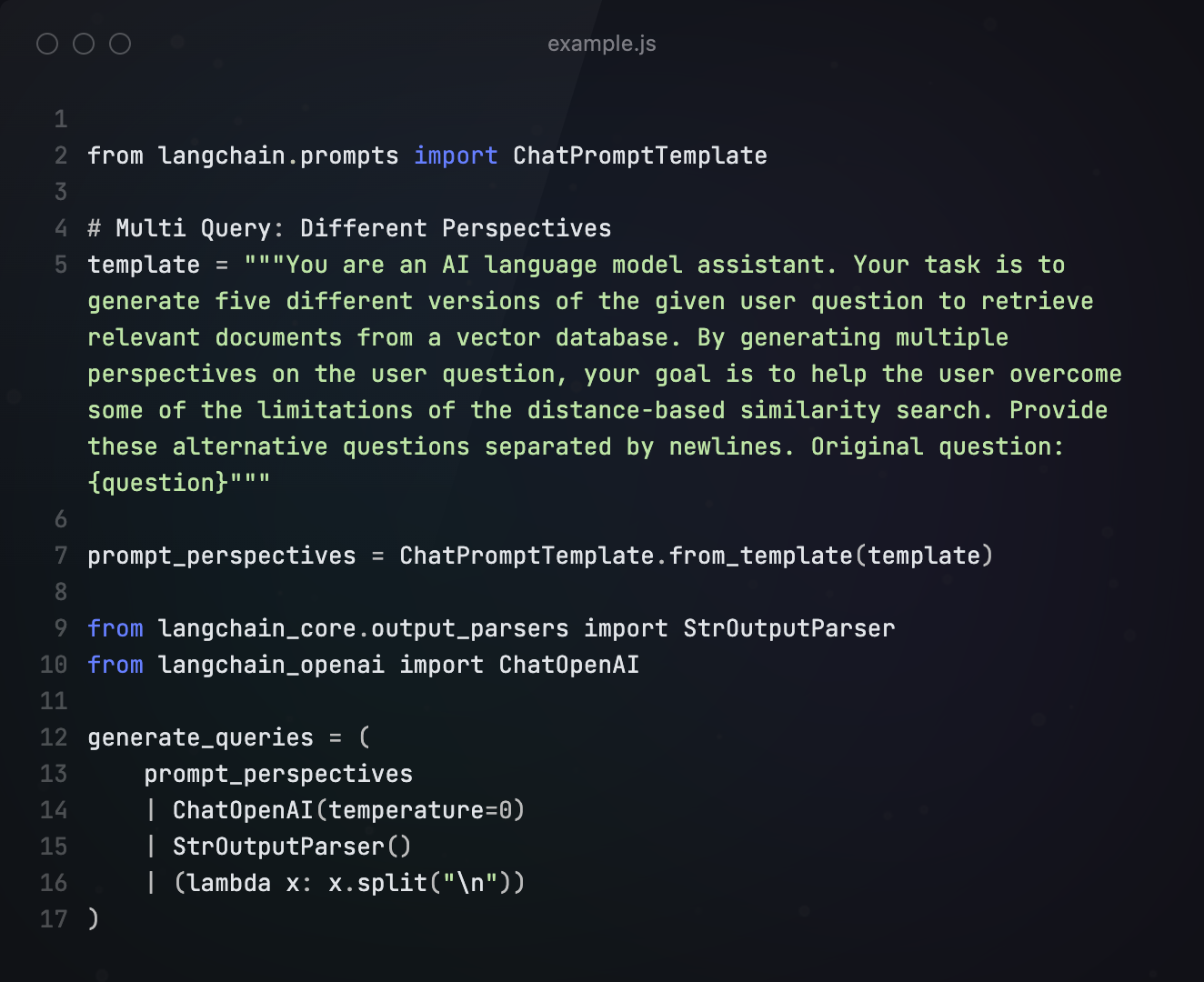
通过构建Prompt,告诉大模型在收到Query之后,生成5个相似的扩展问题。后续的步骤和Naive Rag一样,对所有Query进行检索和生成。
二、Rag-Fusion
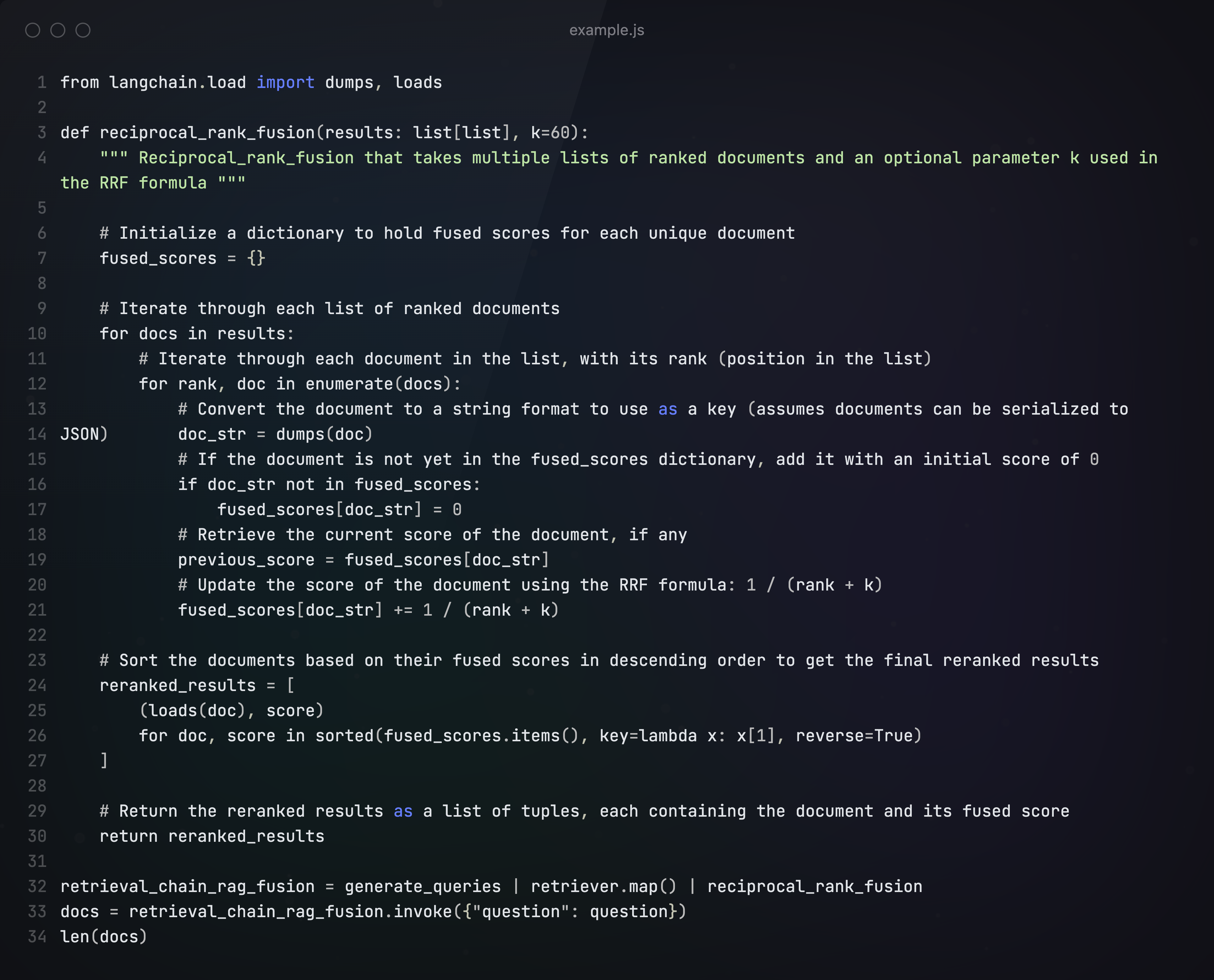
Rag-Fusion也是Multi-Query的一种,相比Multi-query只是多了一个步骤,即在对多个query进行检索之后,应用倒数排名融合算法,根据文档在多个查询中的相关性重新排列文档,生成最终输出。
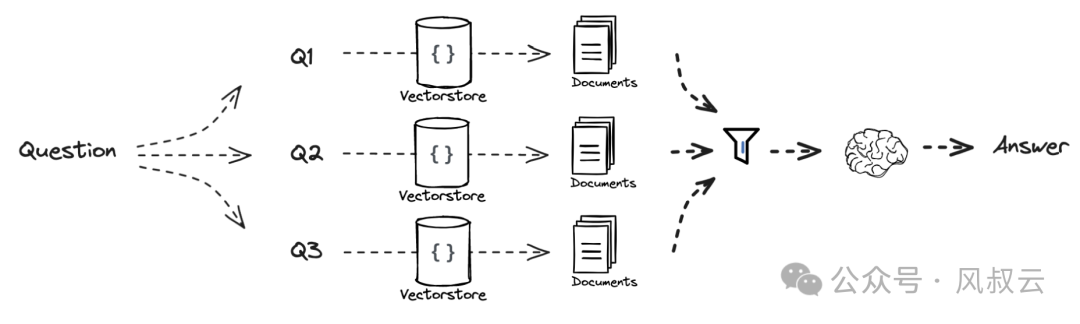
以下代码中的reciprocal_rank_fusion,就是rag-fusion多出来的一步。
三、Decomposition(问题分解)
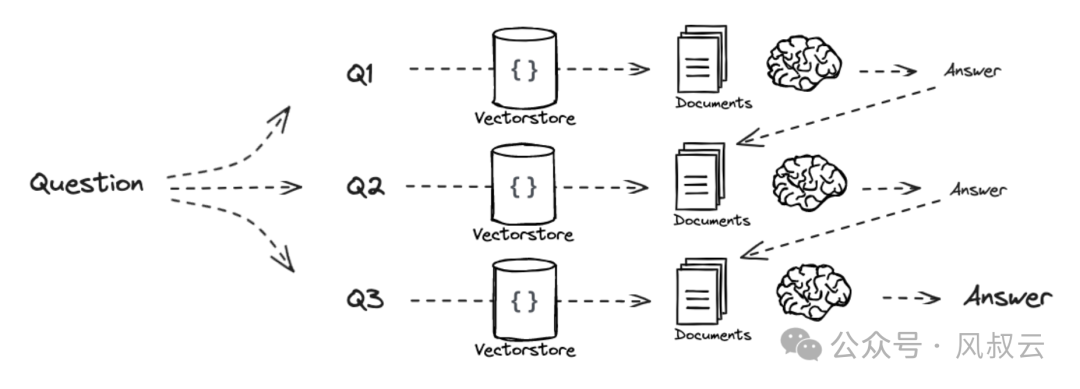
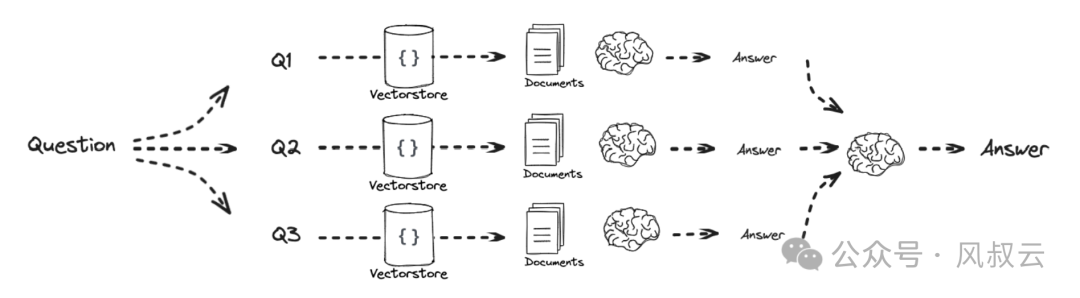
通过分解和规划复杂问题,将原始Query分解成为多个子问题。比如原始Query的问题是“请详细且全面的介绍Rag“,这个问题就可以拆解为几个子问题,“Rag的概念是什么?”,“为什么会产生Rag?”,“Rag的原理是怎样的?”,“Rag有哪些使用场景”等等。
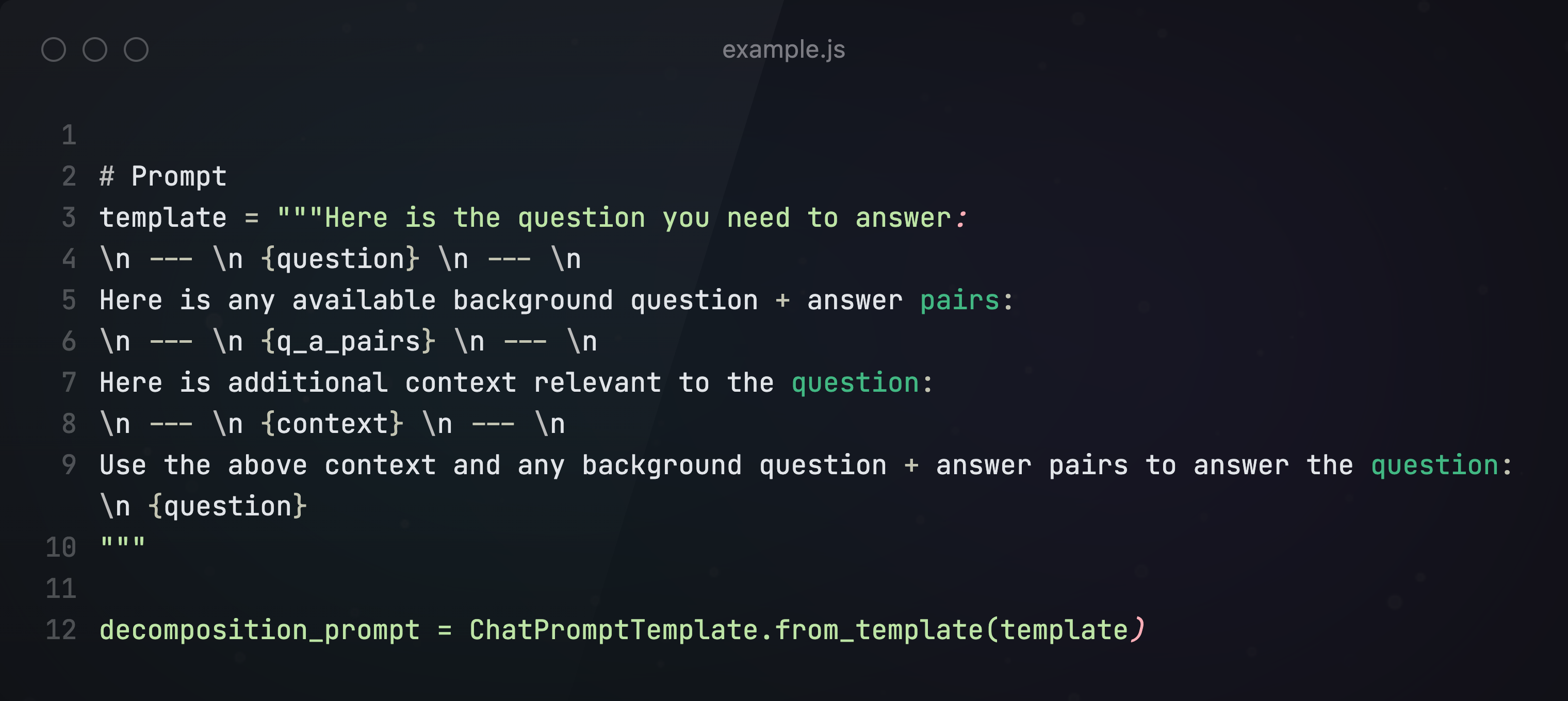
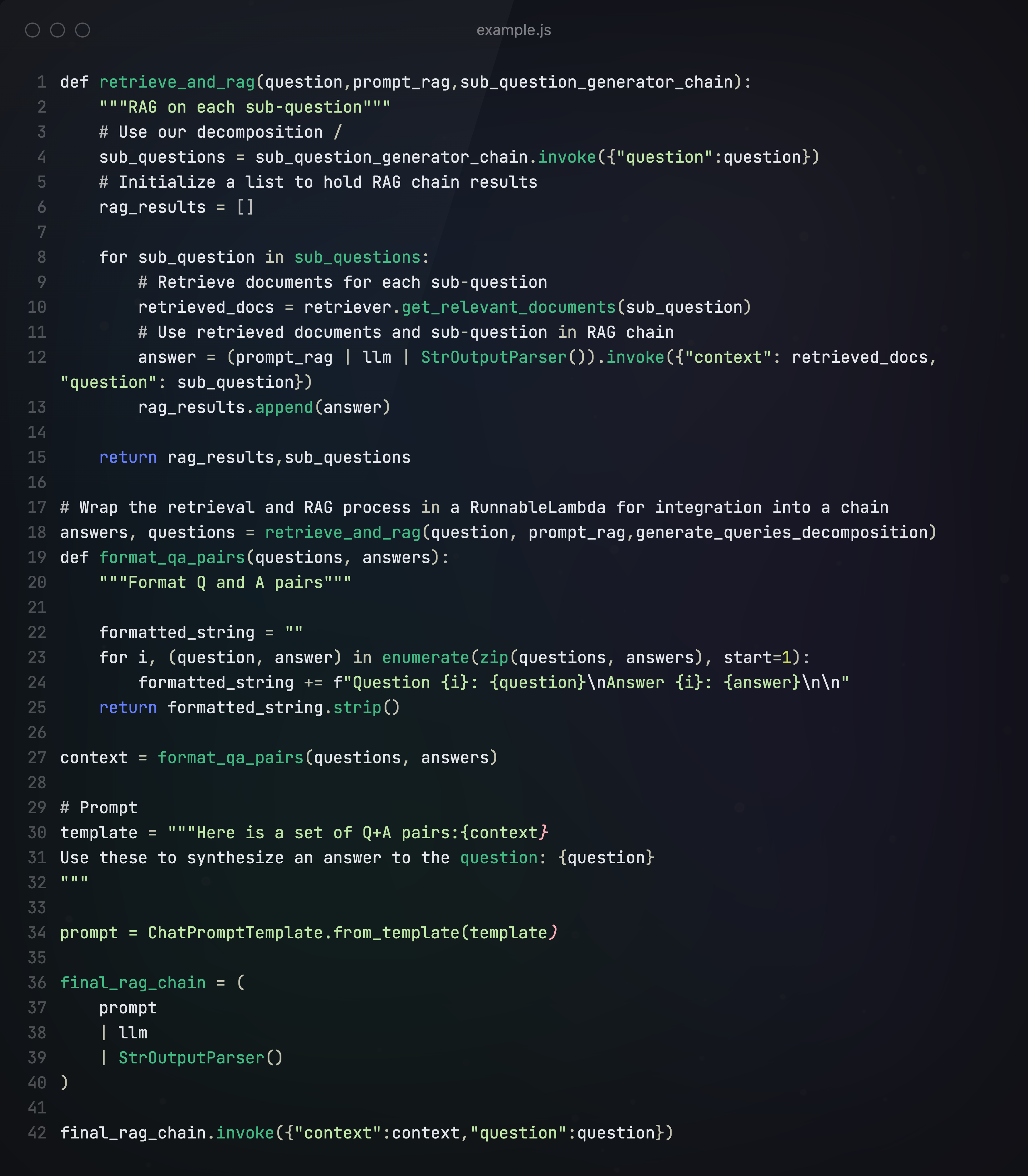
首先,构建Prompt,告诉大模型要将输入的问题分解成3个子问题。

在最终回答子问题的时候有两种方式。
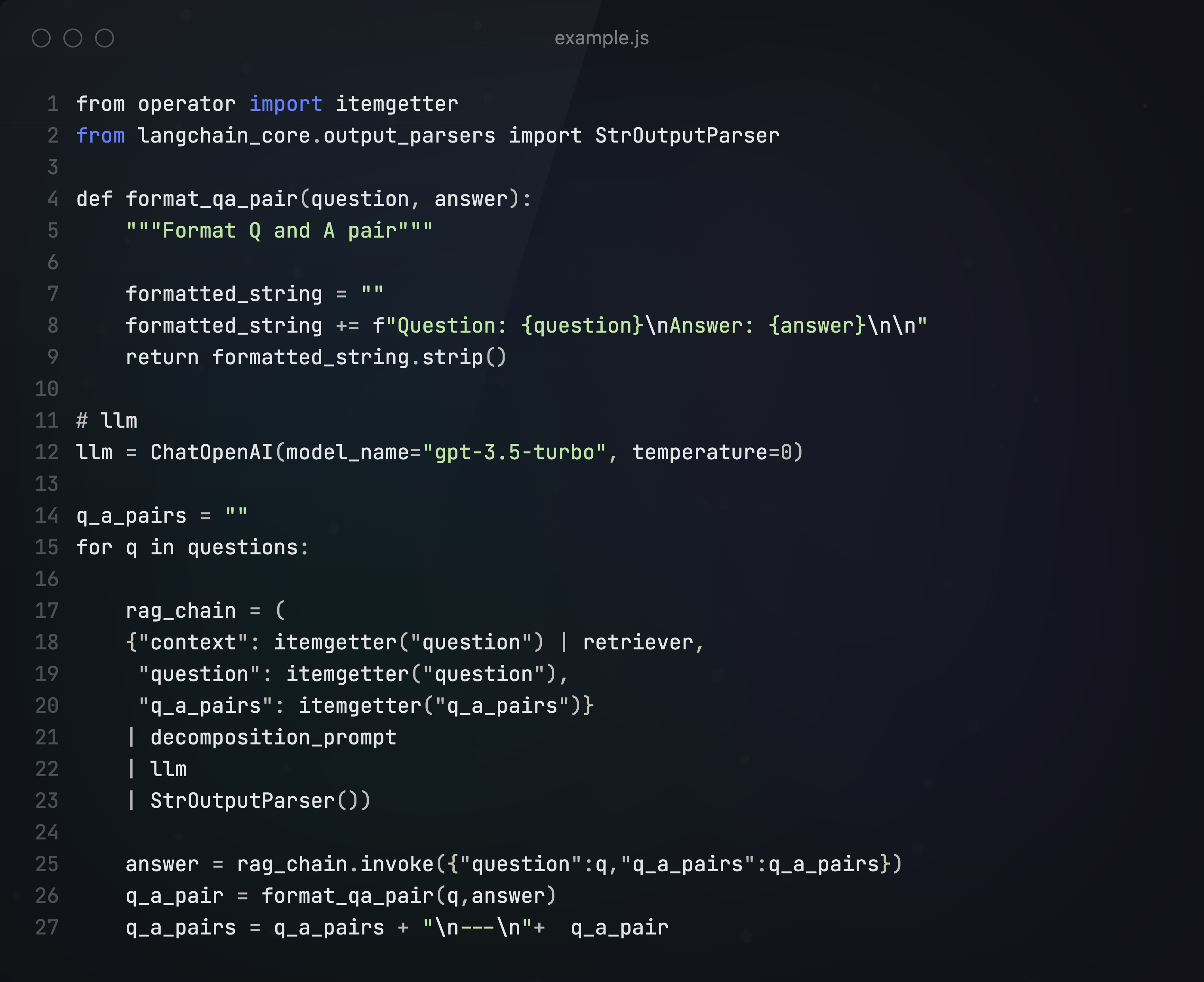
第一种是递归回答,即先接收一个子问题,先回答这个子问题并接受这个答案,并用它来帮助回答第二个子问题。
给出prompt:
下面是递归回答的主逻辑,生成最终回答:
第二种方式是独立回答,然后再把所有的这些答案串联起来,得出最终答案。这更适合于一组有几个独立的问题,问题之间的答案不互相依赖的情况。
四、Step-back(Query后退)
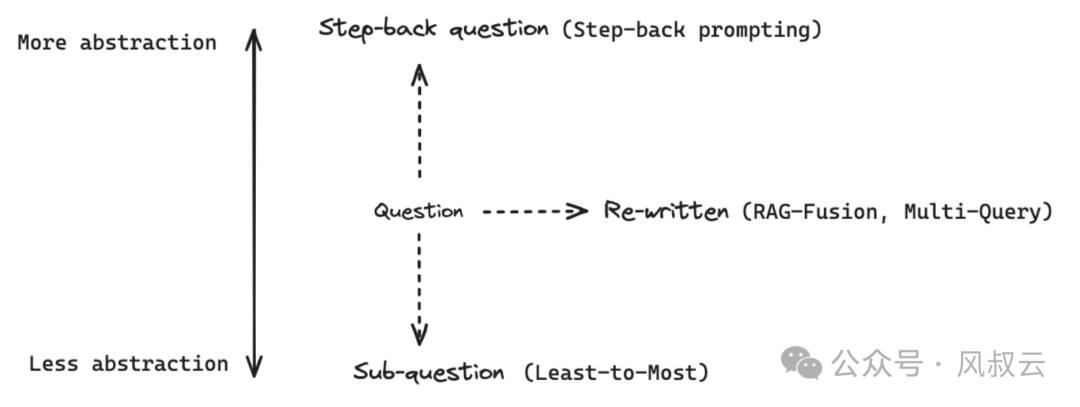
如果原始查询太复杂或返回的信息太广泛,我们可以选择生成一个抽象层次更高的“退后”问题,与原始问题一起用于检索,以增加返回结果的数量。
例如,对于问题“勒布朗詹姆斯在2005年至2010年在哪些球队?”这个问题因为有时间范围的详细限制,比较难直接解决,可以提出一个后退问题,“勒布朗詹姆斯的职业生涯是怎么样的?”,从这个回答的召回结果中再检索上一个问题的答案。
先给大模型提供一些step-back的示例:
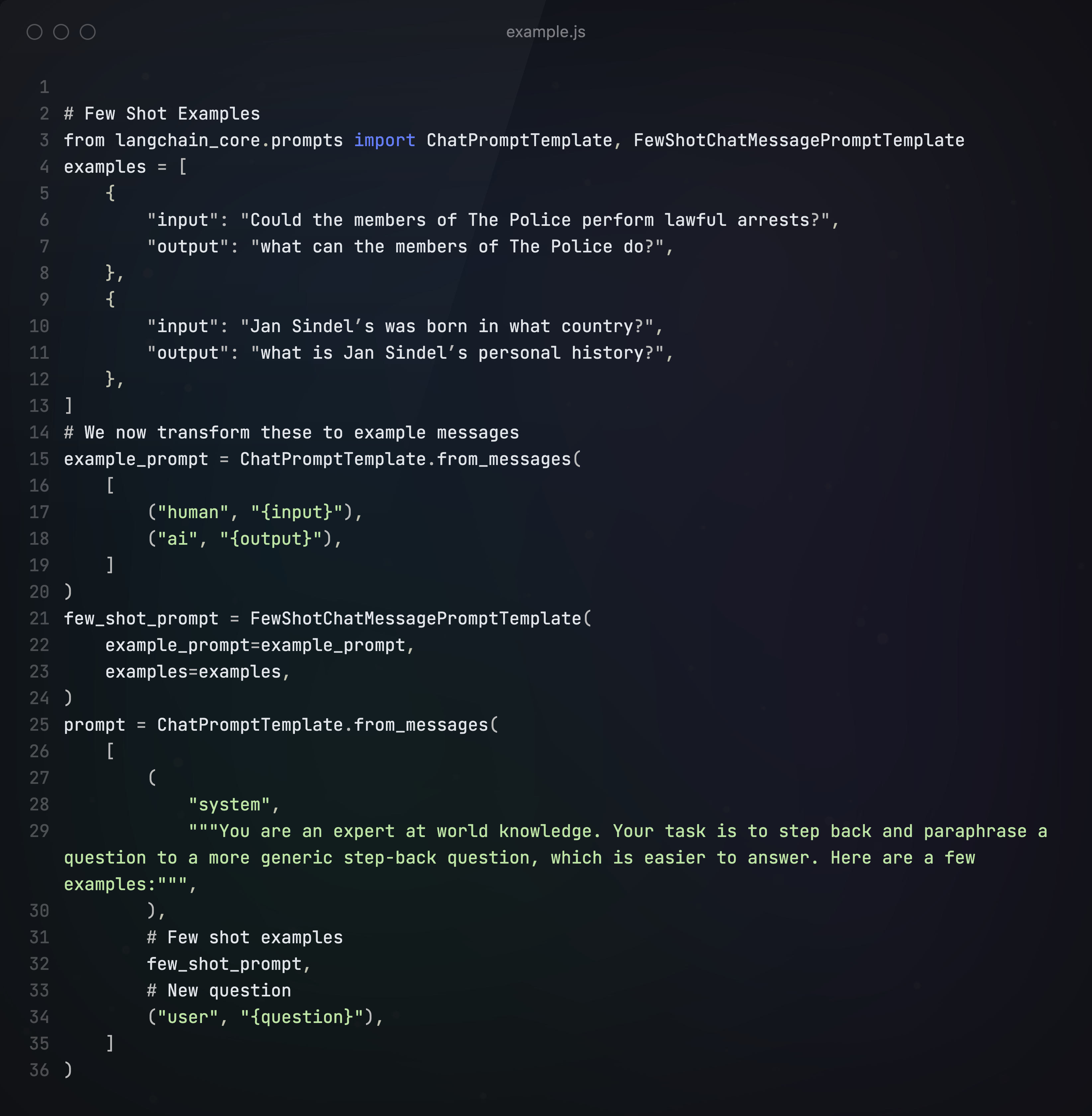
然后对输入问题进行step-back
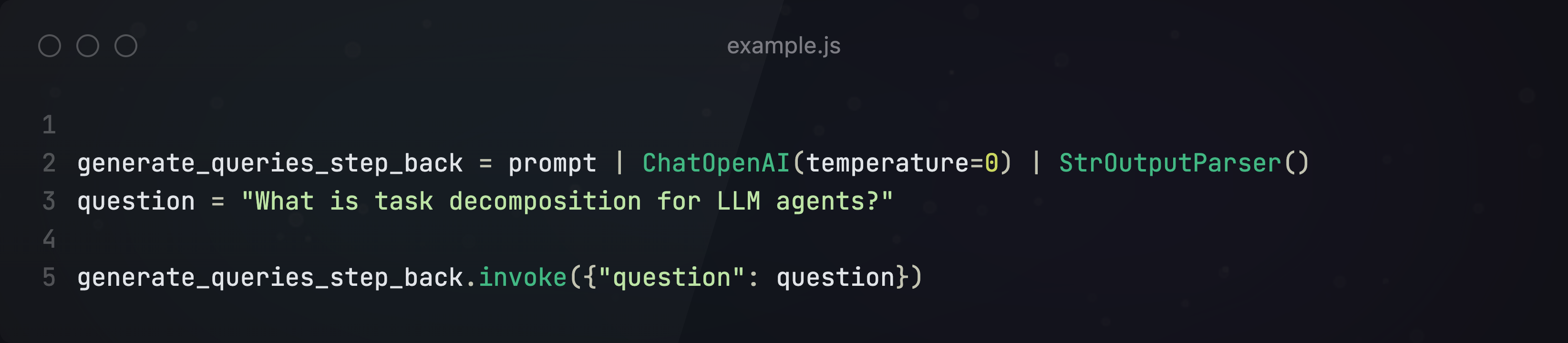
结合prompt,生成最终回答
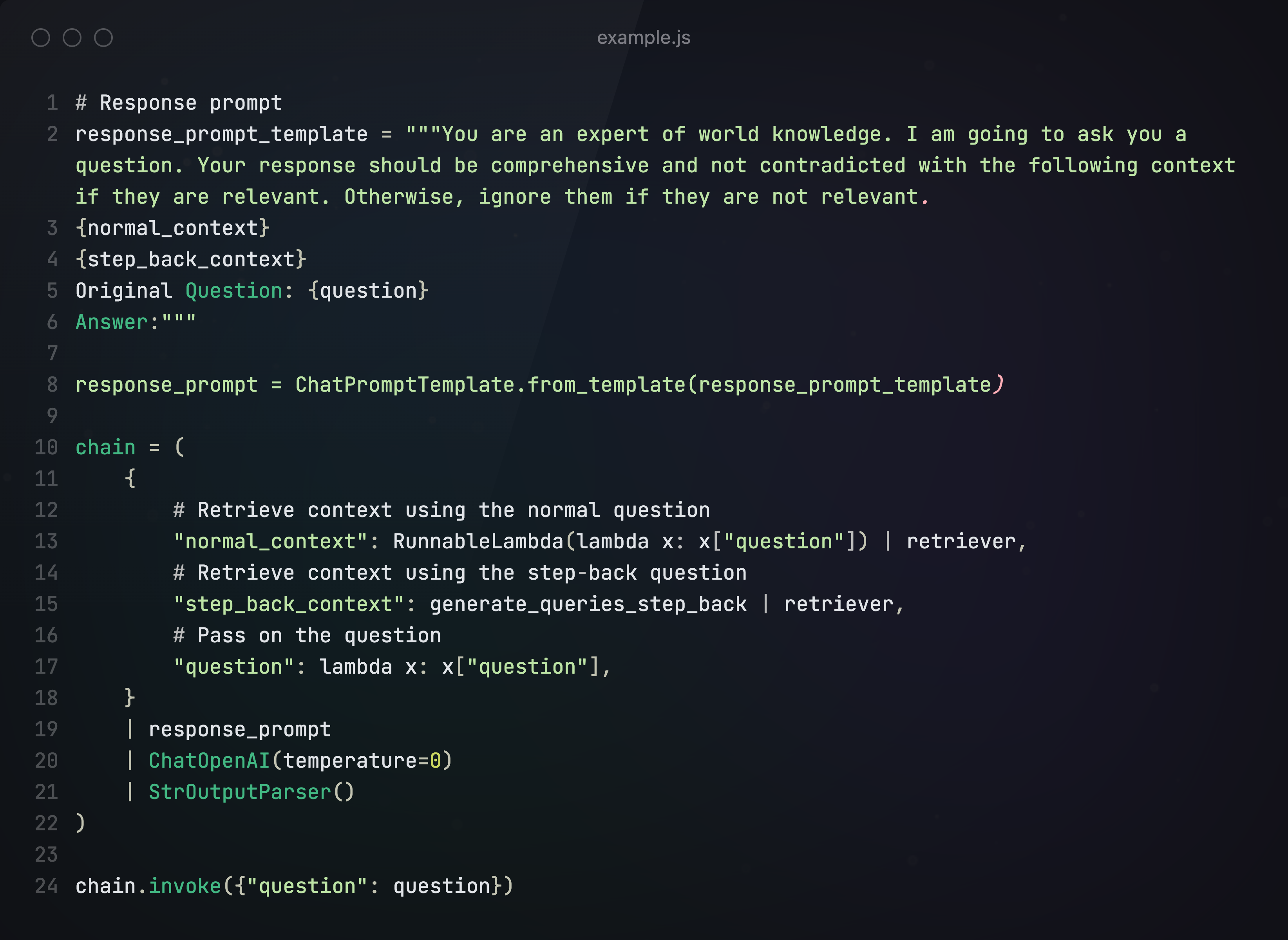
五、HYDE
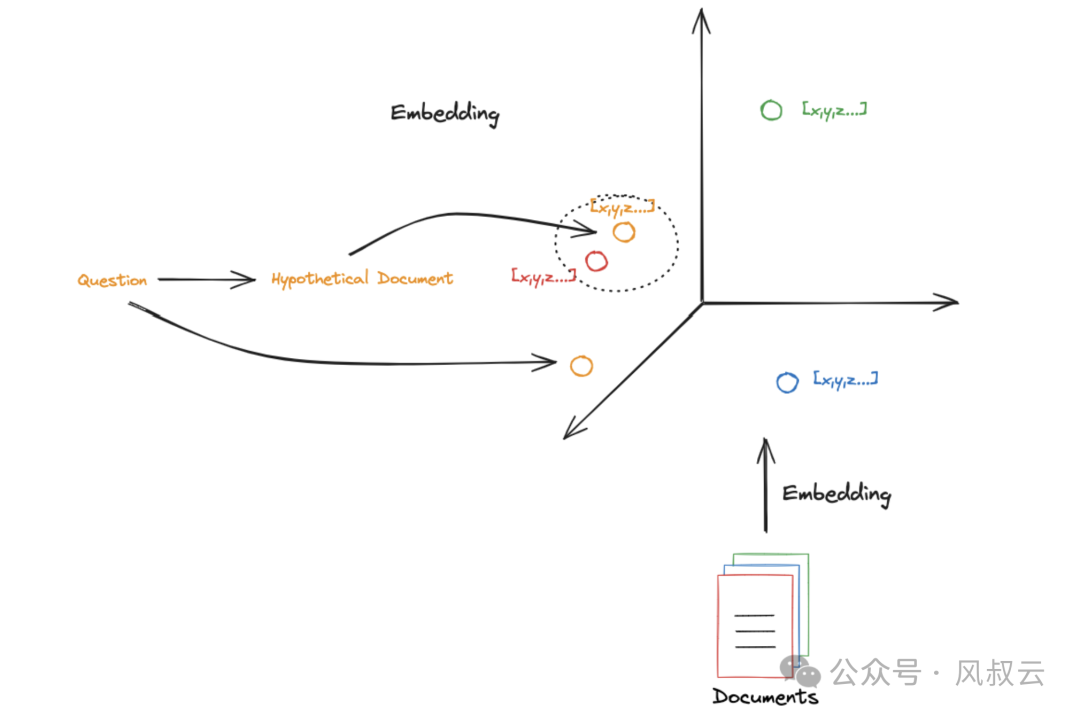
全称是Hypothetical Document Embeddings,即用LLM生成一个“假设”答案,将其和问题一起进行检索。
HyDE的核心思想是接收用户提问后,先让LLM在没有外部知识的情况下生成一个假设性的回复。然后,将这个假设性回复和原始查询一起用于向量检索。假设回复可能包含虚假信息,但蕴含着LLM认为相关的信息和文档模式,有助于在知识库中寻找类似的文档。
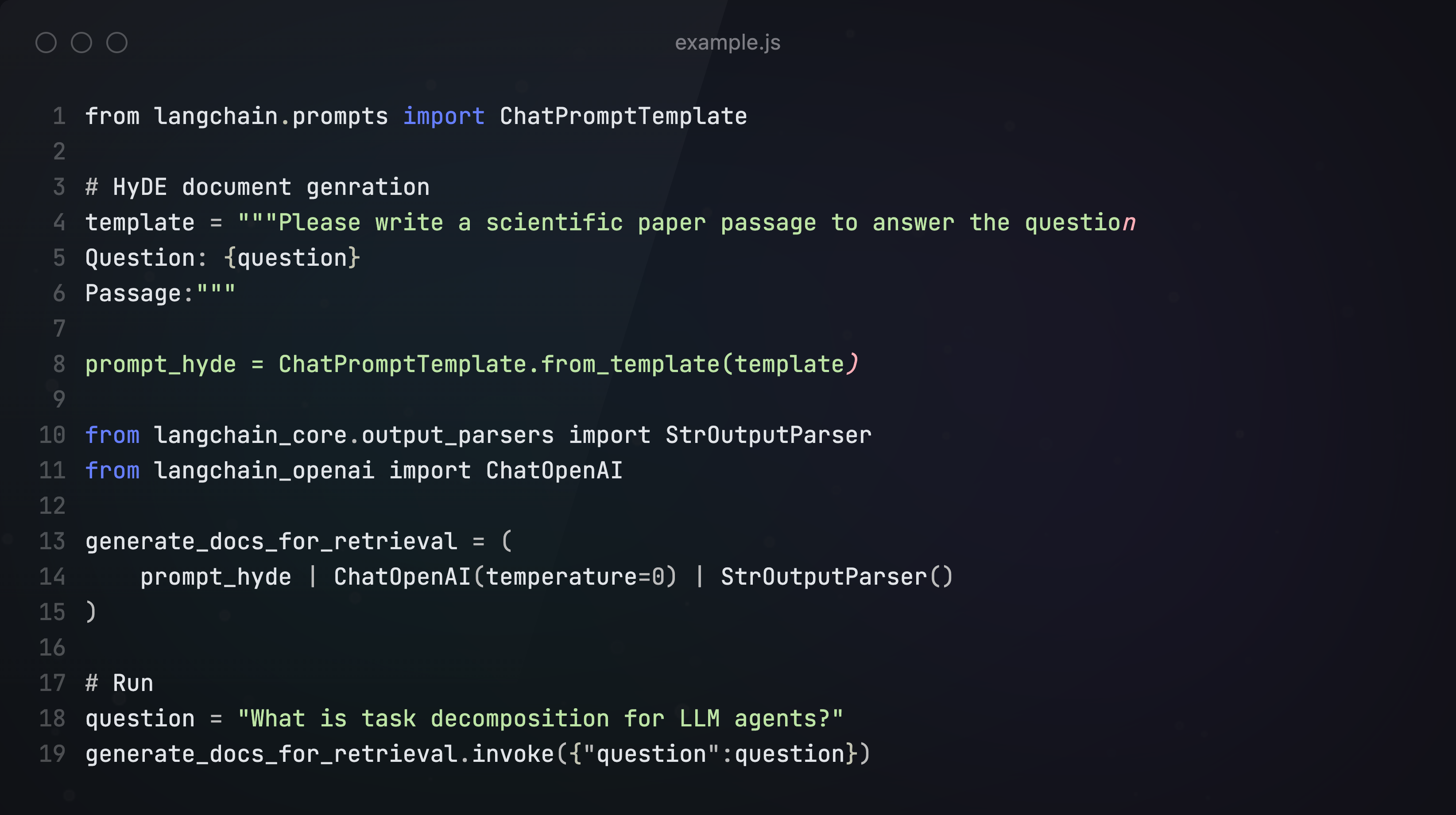
到这里,优化查询转化的五种高级方法就介绍完了。
六、总结
在这篇文章中,风叔详细介绍了优化Query Translation(查询转换)的具体方法,包括Multi-Query、Rag-Fusion、Decomposition、Step-Back和HYDE这五种比较高级的方法。
在下一篇文章中,风叔将重点介绍Routing(路由)环节,通过对用户输入进行路由,从而让系统自动选择最合适的处理方案。因为Routing的存在,RAG系统具备了处理复杂问题和场景的能力。
本文由人人都是产品经理作者【风叔】,微信公众号:【风叔云】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


