
 起点课堂会员权益
起点课堂会员权益【AI 的领域应用】CV、NLP和Audio的深度学习突破
我们都知道大模型都是由各种算法组成的,那怎么看似简单的代码,如何变成让人惊艳的“智能大脑”的?这篇文章,我们来分析下算法、结构的路程和进步。

想象一下未来的世界,AI不仅仅是你的助手,甚至可能成为你的同事! 伴随着科技的飞速发展,AI已经从科幻走进现实,它可以帮你下单外卖、陪你对话,甚至替你完成工作。
而这一切背后,AI的核心驱动力究竟是什么?
人工智能正在日益渗透到所有的技术领域,而深度学习(DL)是目前人工智能中最活跃的分支。最近几年,DL 取得了许多重要进展,其中一些因为事件跟大众关系密切而引人瞩目,而有的虽然低调但意义重大。深度学习在计算机视觉 CV、自然语言处理 NLP、语音识别 Audio 这三大领域方向中都取得了显著的成果。
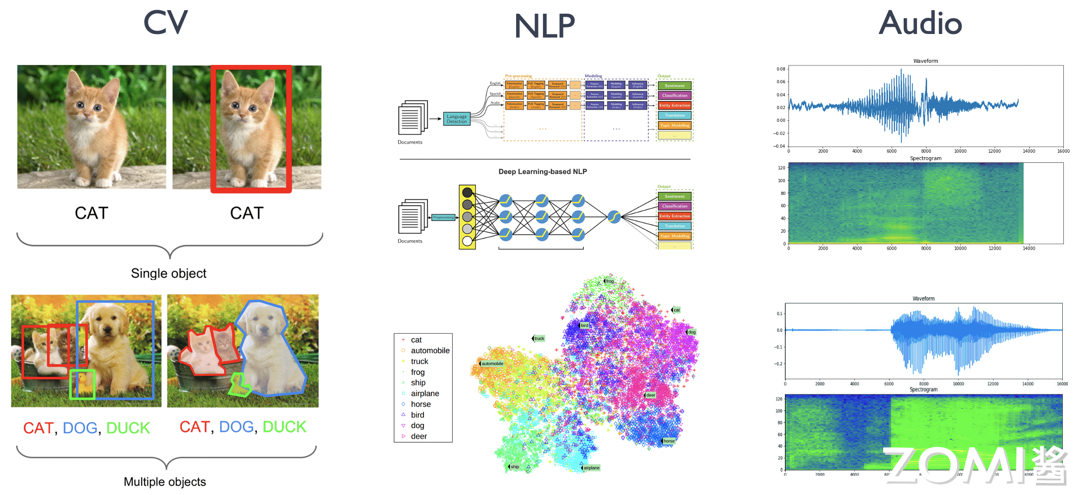
01 CV 领域应用
深度学习因其可信度而得到广泛认可。计算机视觉,尤其是图像识别,是深度学习能力的一些最早重要演示的主题,最近在人脸识别和物体检测方面。
物体检测与跟踪:
深度学习算法已用于各种应用,例如自动驾驶汽车、无人机和安全摄像头的实时检测和跟踪对象。
图像与视频识别:
深度学习模型可以非常准确地识别和分类图像和视频,从而支持图像搜索引擎、内容审核和推荐系统等应用。例如,谷歌和 Bing 等搜索引擎使用深度学习算法,根据图像查询提供准确且相关的搜索结果。
面部识别:
深度学习算法可以高精度识别和匹配人脸,实现安全访问控制、监控甚至个性化营销等应用。例如,出于安全目的,机场和政府大楼使用面部识别来筛查乘客和员工。同样,零售商使用面部识别来分析客户行为和偏好,并提供个性化的购物体验。

02 NLP 领域应用
深度学习与 NLP 有着密切的联系。深度学习是一种机器学习方法,它通过建立多层神经网络来模拟人脑的学习过程。NLP 则是一种人工智能技术,它研究如何让计算机更好地理解和处理自然语言。NLP 的基本概念主要包括文本处理和自然语言理解。
- 文本处理:对文本数据进行的一系列处理过程,包括分词、词性标注、句法分析和语义分析等。这些处理过程可以帮助计算机更好地理解和处理自然语言文本数据。自然语言理解则是让计算机能够理解自然语言文本数据的含义和上下文信息,从而能够做出相应的响应和决策。
- 词向量表示:词向量表示是将词语转化为计算机能够处理的数据格式。深度学习可以通过建立神经网络模型,利用大量语料库进行训练,从而学习到词向量表示。这种表示方式可以更好地捕捉词语的语义信息,为后续的自然语言处理任务提供更好的基础。
- 文本分类与情感分析:深度学习可以通过建立卷积神经网络(CNN)或循环神经网络(RNN)等模型,对文本进行分类或情感分析。
- 机器翻译:机器翻译是 NLP 领域的一个重要应用,它是将一种自然语言文本自动翻译成另一种自然语言文本的过程。深度学习可以通过建立神经网络模型,利用大量双语语料库进行训练,从而实现高质量的机器翻译。
03 Audio 领域应用
随着深度学习技术的快速发展,智能音频处理作为其中的一个重要应用领域,利用深度学习技术可以实现音频信号的分析、识别和合成等任务。深度学习技术在智能音频处理中的应用与创新为音频信号的分析、识别和合成等任务提供了强大的工具和方法。
- 音频信号分析:深度学习技术可以用于音频信号的分析,如音频分类、音频分割和音频降噪等。通过训练深度神经网络模型,可以提取音频信号的特征,并对音频进行分类或分割。此外,深度学习技术通过学习噪声模型和信号模型,实现对噪声的自动去除。
- 语音识别:深度学习技术在语音识别领域取得了重大突破。通过使用深度神经网络模型,可以将语音信号转化为文本信息。深度学习模型可以自动学习语音信号的特征,并通过大规模的训练数据提高识别准确率。语音识别技术的应用包括语音助手、语音翻译和语音控制等。
- 音频合成:深度学习技术可以用于音频合成,如语音合成和音乐合成等。通过训练深度神经网络模型,可以生成逼真的语音合成结果。此外,深度学习技术还可以用于音乐合成,通过学习音乐的模式和结构,生成新的音乐作品。
- 端到端的音频处理:传统的音频处理方法通常需要多个步骤和模块,而深度学习技术可以实现端到端的音频处理。通过训练端到端的深度学习模型,可以直接从原始音频信号中提取特征并完成音频处理任务,简化处理流程并提高效率。
- 跨模态音频处理:深度学习技术可以实现跨模态的音频处理,将音频信号与其他模态的信息进行融合和处理。例如,可以将音频信号与图像或文本信息进行联合处理,实现更加丰富和准确的音频分析和合成。
本文由 @章鱼AI小丸子 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


