
 起点课堂会员权益
起点课堂会员权益【AI系统的出现】数据、算法与计算力的完美交响
在数字化时代的洪流中,人工智能(AI)如同破茧的凤凰,展翅高飞。这篇文章深入剖析了AI系统崛起的三大支柱:海量数据的积累、计算能力的飞跃以及机器学习算法的突破性进展。

随着移动互联网的发展,移动应用积累了海量的用户行为数据,这些数据不仅推动了AI算法的进步,也促进了AI系统的发展。
一、规模数据驱动
随着数字化的发展,各种信息系统沉淀了大量的数据。AI算法利用数据驱动(Data Driven)的方式解决问题,从数据中不断学习和提取规律与模型,以完成分类和回归等任务。
互联网公司拥有大量的用户,规模庞大的数据中心,信息系统不断完善,因此可以较早沉淀出大规模的数据,并应用人工智能技术,投入研发创新人工智能技术。
互联网服务和数据平台给深度学习带来了大数据。随着移动互联网的日益普及,移动应用的发展可谓日新月异,应用商店中(谷歌 Play、App Store,还有众多的移动应用分发渠道上),已经积累了海量的用户行为数据。
这些数据随着时间的流逝和新业务功能的推出,数据量越来越大,数据模式越来越丰富。所以互联网公司较早的开发和部署了的大数据管理与处理平台。
基于这些海量数据,互联网公司通过数据驱动的方式,训练人工智能模型,进而优化和提升业务用户体验(如点击率预测让用户获取感兴趣的信息),让更多的用户使用服务,进而形成循环。
不同的数据类型和任务,驱动模型结构的复杂性,驱动AI框架和针对AI的编译体系,需要更灵活的表现能力对AI问题进行表达与映射。
例如,以下几种服务中沉淀和形成了相应领域代表性的数据集:
- 搜索引擎(Search Engine):在图像检索(Image Search)邻域出现了如 ImageNet,Coco 等计算机视觉数据集。在文本检索(Text Search)出现了 Wikipedia 等自然语言处理数据集。
- 移动应用(Application):移动应用数据分析是用户获取和留存的强劲引擎。如图所示,国内出现了优质的数据源的公司如知乎和小红书,传统的贴吧如天涯论坛、百度网吧等充斥广告等地方已经不再是优质数据源。各家移动互联网如淘宝、拼多多收集了大量的用户购买和浏览记录,形成庞大的推荐系统数据集,广告数据集。
同样是图像分类问题,从最开始数据规模较小的 MNIST 手写数字识别数据集其只有 6 万样本,10 个分类,到更大规模的 ImageNet,其有 1600 万样本,1000 个分类,再到互联网 Web 服务中沉淀了数亿量级的图像数据。
海量的数据让人工智能问题变得愈发挑战的同时,实质性的促进了人工智能模型效果的提升,因为当前以深度学习为核心的代表性 AI 算法,其本身是数据驱动的方式从数据中学习规律与知识,数据的质与量决定了模型本身的天花板。

海量数据集为 AI 系统的发展产生了以下的影响:
- 推动 AI 算法不断在确定任务上产生更高准确度与更低的误差。这样产生了针对 AI 系统发展的用户基础,应用落地场景驱动力和研发资源投入。
- 让 AI 有更广泛的应用,进而产生商业价值,让工业界和学术界看到其应用潜力并投入更多资源进行科学研究,持续探索。
- 传统的机器学习库不能满足相应的需求,海量的数据集让单机越来越难以完成 AI 模型的训练,进而产生了 AI 系统中分布式训练和 AI 集群的需求。
- 多样的数据格式和任务,驱动模型结构的复杂性,驱动 AI 开发框架和针对 AI 的编译体系,需要有更灵活的表达能力对 AI 问题进行表达与映射。
- 同时伴随着性能等需求得到满足,数据安全与模型安全问题挑战也变的日益突出。
综上所述,AI 系统本身的设计相较于传统机器学习系统有更多样的表达需求,更大规模和多样数据集和更广泛的用户基础。
二、AI算法的进步
研究人员和工程师不断设计新的AI算法和AI模型,提升预测的准确性,不断取得突破性进展。但是新的算法和模型结构需要AI框架提供便于对AI范式的编程表达和灵活性,对执行性能优化可能会改变原假设,进而产生对AI系统的新需求。AI框架和针对AI的编译对前端、中间表达和系统算法协同设计的演进和发展。
精度超越传统机器学习
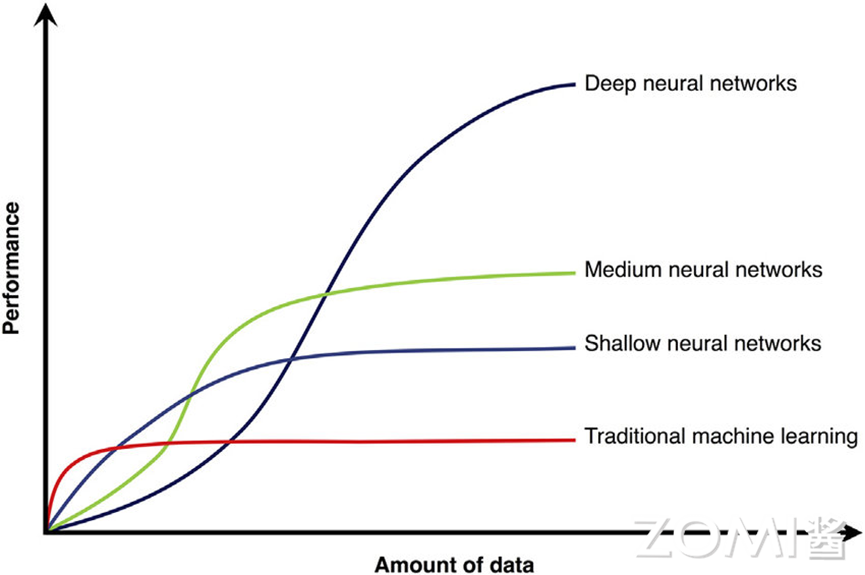
以 MNIST 手写数字识别任务为例,其作为一个手写数字图像数据集,在早期通常用于训练和研究图像分类任务,由于其样本与数据规模较小,当前也常常用于教学。从图中可以观察了解到不同的机器学习算法取得的效果以及趋势:1998 年,简单的 CNN 可以接近 SVM 最好效果。2012 年,CNN 可以将错误率降低到 0.23% (2012),这样的结果已经可以和人所达到的错误率 0.2% 非常接近。
神经网络模型在 MNIST 数据集上相比传统机器学习模型的表现,让研究者们看到了神经网络模型提升预测效果的潜力,进而不断尝试新的神经网络模型和在更复杂的数据集上进行验证。神经网络算法在准确度和错误率上的效果提升,让不同应用场景上的问题,取得突破进展或让领域研发人员看到相应潜力,是驱动不同行业不断投入研发 AI 算法的动力。
公开数据集上突破
随着每年 ImageNet 数据集上的新模型取得突破,新的神经网络模型结构和训练方式的潜力。更深、更大的模型结构有潜力提升当前预测的效果。1998 年的 Lenet 到 2012 年的 AlexNet,不仅效果提升,模型变大,同时引入了 GPU 训练,新的计算层(如 ReLU 等)。到 2015 年的 Inception,模型的计算图进一步复杂,且有新的计算层被提出。2015 年 ResNet 模型层数进一步加深,甚至达到上百层。到 2019 年 MobileNet3 的 NAS,模型设计逐渐朝着自动化的方式进行设计,错误率进一步降低到 6.7% 以下。
新的模型不断在以下方面演化进而提升效果:
1)更好的激活函数和层,如 ReLU、Batch Norm 等;
2)更深更大的网络结构和更多的模型权重;
3)更好的训练技巧: 正则化(Regularization)、初始化(Initialization)、学习方法(Learning Methods),自动化机器学习与模型结构搜索等。
上述取得更好效果的技巧和设计,驱动算法工程师与研究员不断投入,同时也要求 AI 系统提供新的算子(Operator)支持与优化,进而驱动 AI 开发框架和 AI 编译器对前端、中间表达和系统算法协同设计的演进和发展。
三、算力与体系结构的进步
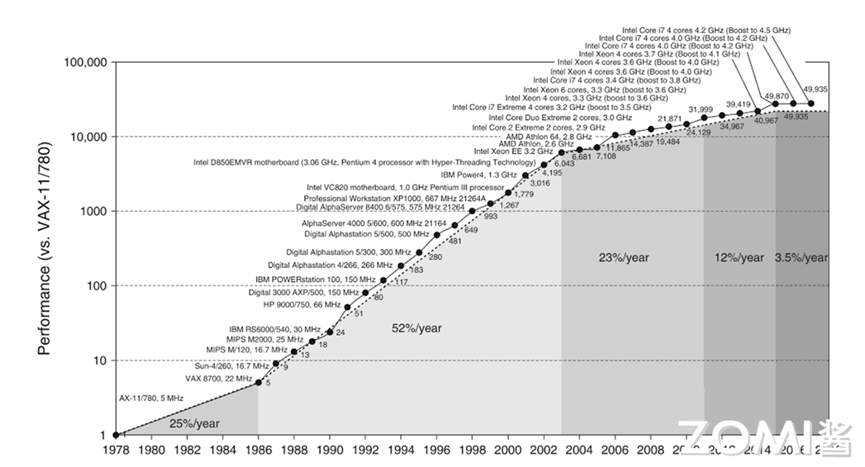
计算机性能的增强主要来自于摩尔定律,但到了二十世纪末,由于摩尔定律的停滞,性能的提升逐渐放缓。
于是,人们开始为应用定制专用处理器,通过消除处理器中冗余的功能部分来进一步提高对特定应用的计算性能。
例如,图形处理器GPU就对图像类算法进行专用加速。后来出现的GPGPU、TPU等,都是针对特定计算任务进行优化的处理器,它们通过深度学习模型中的算子进行抽象,转换为矩阵乘法或非线性变换,根据专用芯片进一步定制流水线化的脉动阵列,进一步减少访存提升计算密度,提高了AI模型的执行性能。
如图所示后来出现 GPGPU,即通用 GPU,对适合于抽象为单指令流多数据流(SIMD)或者单指令多线程(SIMT)的并行算法与工作应用负载都能起到惊人的加速效果。
这些进步不仅推动了AI系统的发展,也为AI技术的广泛应用奠定了坚实的基础。随着技术的不断进步,AI系统将继续演化,以适应更加复杂和多样化的应用场景。
AI芯片近年来因性能提升而备受关注。谷歌的TPU通过将深度学习模型算子转化为矩阵运算和脉动阵列,提高了计算密度和模型执行效率。
华为的昇腾NPU和达芬奇架构针对矩阵运算进行了优化,提供了强大的AI计算能力。
硬件厂商也在将稀疏性和量化等算法加速手段集成到专用加速器中,如英伟达的Transformer Engine,进一步提升了专用计算领域的性能。尽管处理器性能大幅提升,但AI芯片执行的代码仍是预设的,智能程度不及生物大脑。
未来,AI系统的性能提升不仅依赖于芯片的迭代和分布式计算的扩展,还需算法和硬件的协同设计,以应对算力瓶颈并提升计算效率。
本文由 @章鱼AI小丸子 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Pixabay,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


