
 起点课堂会员权益
起点课堂会员权益
策略产品经理必懂标签生成策略及工程化逻辑
 B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等
B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等本文介绍了抖音推荐系统中的标签生成和迭代过程,以及如何通过用户行为数据构建标签体系,从而实现精准的内容推荐策略。
大家好,我是策略产品夏师傅。
男士的抖音里面为什么十个推荐里有八个是大长腿,它是怎么做的?
注意了,这个时候可能是你被打标了。
那么标签是怎么生成的,又是怎么迭代的,我们一起来看看。
其实,当你是新用户的时候,抖音并不知道你喜欢什么样的视频,这时候给你推荐的视频完全是随机推荐一些热度高的视频,在这些视频的背后贴满了一个个属性标签。
比如:一个小姐姐的热舞视频,视频的背后标签可能就是“美女”、“大长腿”、“跳舞”、“黑丝”等诸多标签;而一个做菜的美食视频标签可能就是“美食”、“家常”、“厨艺教学”等诸多标签。

随着你行为数据的丰富,你相应的行为会加深生产标签的权重。比如:你在某个视频的停留时间更长,观看次数更多,点赞、评论、转发等互动行为更多,那么这个视频背后的标签在你的账号上权重就会上升。
其实,一句话:推荐内容逐渐精准的过程就是一个贴标签、统计标签、匹配标签和结合其他维度属性的综合过程。
通过一定数量的行为数据统计,抖音就能大概知道你的喜好倾向,接下来的推荐视频会根据你的喜好倾向,推荐带有相同标签的高质量视频以做进一步的分析,逐步完善,针对你喜好的推荐会越来越精准,获得你更多停留时长的概率也就越高。
抖音围绕着标签体系、召回模型、融合模型、排序规则等其他维度属性排序做了一个综合的策略体系。
用户喜欢什么类型的视频我们是不知道的,并且计算机无法理解人们主观的思维,所以我们需要收集并分析用户在平台产生的行为数据,把这些行为数据进行精炼、归类,形成一套完整闭环的标签体系去描绘用户的数据形象。
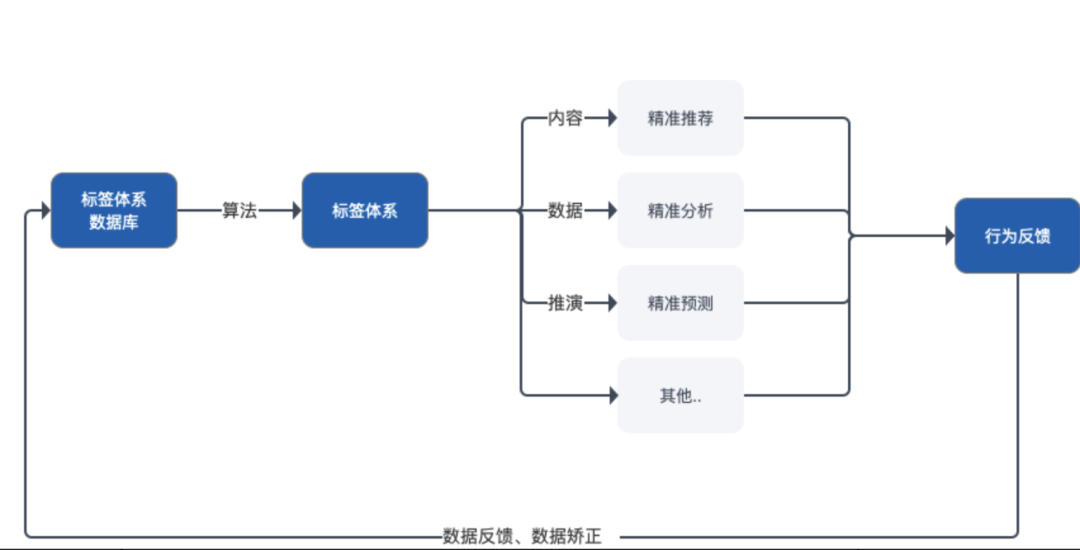
标签体系的应用流程
一套优秀的标签体系结构可以让计算机更好的理解这些行为数据,对于用户意图的判断和数据召回模型的优先级都有很重要的辅助作用。
整个标签体系的搭建围绕着三个步骤去展开:标签建模、标签提炼、标签聚合
01 标签建模
搭建思路是将数据分为四个层级模型,第四层为预测模型,但预测模型的算法需要大量数据进行演算,本次不做讨论,所以暂且分为三层进行构建。
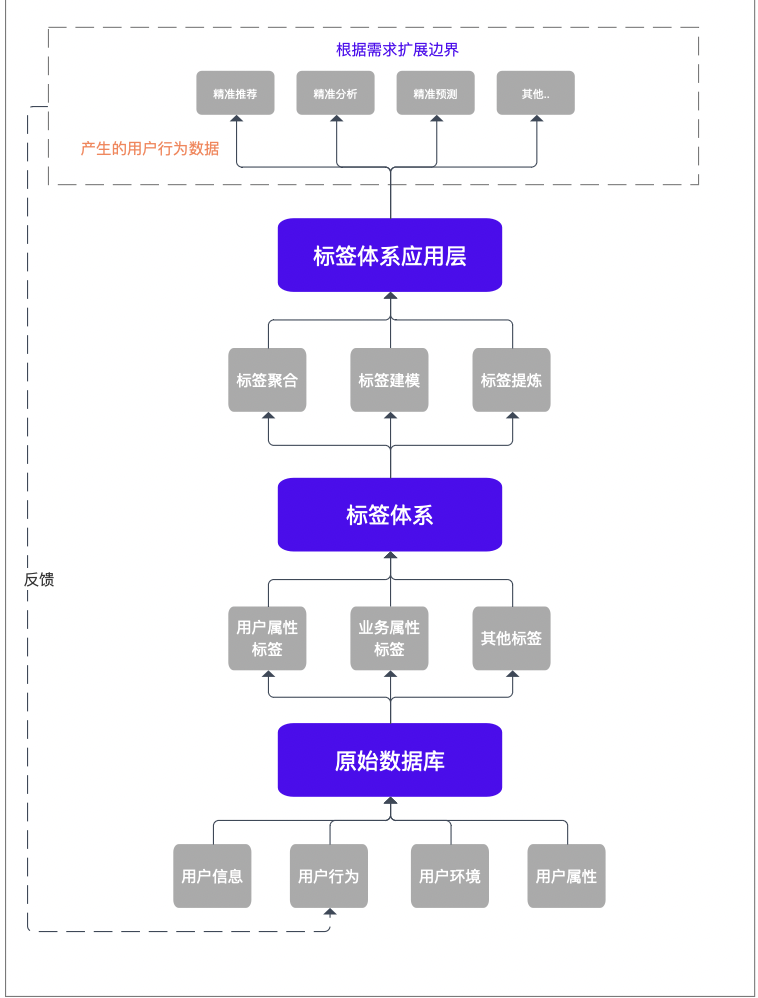
标签体系的流程架构
第一层主要是原始数据库,在这一层,我们考虑到数据存储、采集难度和成本方面的因素,尽可能在可控成本内获取到尽可能多的原始数据,因为后面所有标签体系构建都将依托于原始数据库的数据进行计算、分析、归类、建模,所以在收集阶段,原始数据库的搭建要尽可能的全面,故在这一层的关键词是:大量、数据。
而第二层级是根据第一层的原始数据通过算法计算、提炼、规划成可以组成标签体系的一系列通用标签,而这类标签的存在形式类似于矩阵或者多个类别的集合。
在业务需要时,该类标签从数量和维度都可以增加以满足业务需求。所以第二层的关键词是:通用、标签。
而对于第三层,我们可以通过对标签的聚合、提炼、建模等方式构成用户的多个“面”,并运用于多个场景。例如:说小明在听音乐时的画像是摇滚、年轻、流行、活泼;而在学习时的画像是认真、专心、投入、经济学等。
通过用户不同的角度实际运用于各类业务需求,实现精准化。所以在第三层的关键词是:聚合、运用。
02 标签提炼
获得了大量的原始数据后,我们想把这些数据运用起来,就需要把用户的数据更加具象化。因为已经把用户数据采集起来了,基础的标签可以直接运用内容的标签,通过对用户感兴趣的内容给用户贴标签。
1. 内容标签化
首先要把内容标签化了,根据行为的不同制定不同类别不同级别的标签,可以是描述性,也可以是具象性的,根据实际业务需求去适应即可,形式并不限制。但内容的标签最好具有通用性,可以是适用于采集到的用户数据的大部分的主体内容。例,房产类网站,这个类别的标签可以是房子的区域、单价、面积、数量等。
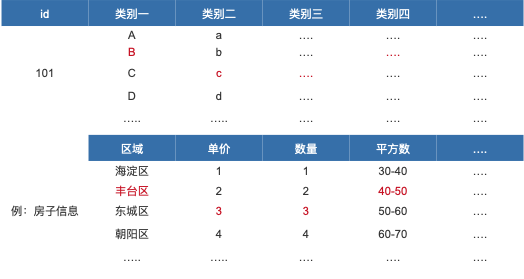
内容标签化
内容标签化的时候需要注意,标签值需要一个统一的维度,在维度统一的前提下,后期使用或者比较数据才具有对比性。例,图1-3,区域的维度需要统一,如果决定是以行政区为维度,那么每个房源信息中的“区域”都需要以这个维度去统计,不能以其他维度进行统计。这个逻辑下来,房源id为101的标签信息为:丰台区、3单价、3套房源、40-50平方、….
2. 用户标签化
接下来就是把内容所代表的标签根据用户的行为赋予在用户身上,这个过程就要研究用户的兴趣倾向,通过对用户行为的分析,判断出用户感兴趣的内容,把这部分内容的标签,提炼、聚合后赋予至用户身上。
在用户的行为数据中,我们可以根据记录用户对不同内容的不同互动数据,代表这个用户对于当前内容的兴趣倾向程度。例,用户的浏览(时长/频率)、点击、分享/收藏/关注等。
通过对不同行为进行赋值,我们就可以通过分值的计算得出用户最感兴趣的一组标签。
在用户的行为数据中,我们可以根据记录用户对不同内容的不同互动数据,代表这个用户对于当前内容的兴趣倾向程度。例,用户的浏览(时长/频率)、点击、分享/收藏/关注等。
通过对不同行为进行赋值,我们就可以通过分值的计算得出用户最感兴趣的一组标签。
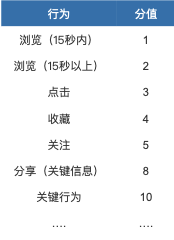
用户行为赋值计算表
完成对于关键行为的权重分值计算后,我们需要把用户数据按照上面内容标签化的方式打散成标签,并且赋予其中,关键行为的对应分值。
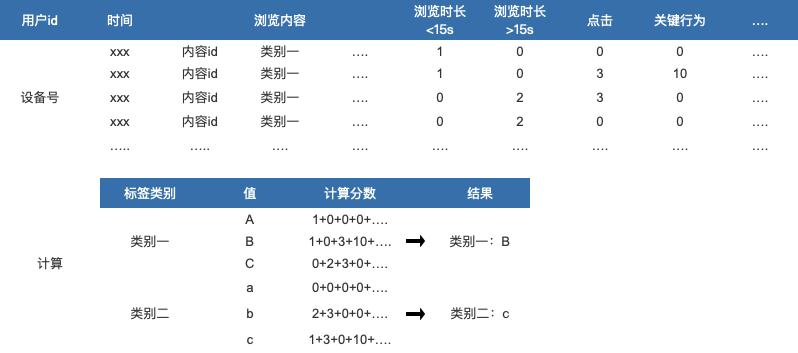
标签赋值后优先级排选逻辑
把标签与分值关联并进行计算。例,商品A的标签“商品产地”的值有“福建、广东、、云南、浙江、河北”等,通过分值计算,找到分值最高的值作为该用户此标签的值。
03 标签聚合
首先将数据分为几个大类,每个大类再进行逐层细分。在构建标签时,只需要构建最下层的标签,就能够映射出上面两级标签。
标签排序为一级>二级>三级,一级为上层标签,三级为最下层标签。
上层标签都是抽象的标签集合,一般没有实用意义,只有统计意义。例,我们可以统计有用户信息标签的用户比例,但用户有用户信息标签,这本身对精准的推荐没有任何意义。
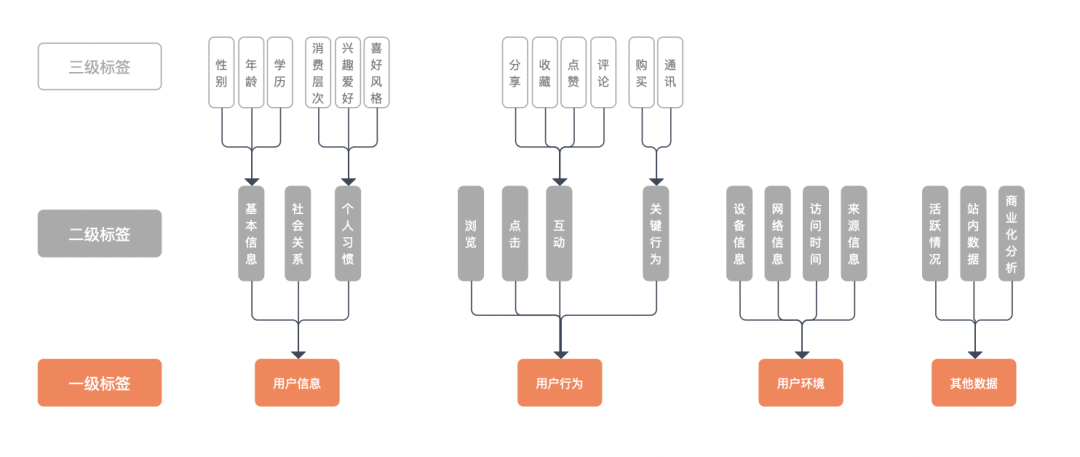
底层标签与上层标签的聚合关系
首先,对于底层标签有两个要求:一个是每个标签只能表示一种含义,避免标签之间的重复和冲突,便于计算机处理;另一个是标签必须有一定的语义,方便相关人员理解每个标签的含义。
其次,标签的粒度也是需要注意的,标签粒度太粗会没有区分度,粒度过细会导致标签体系太过复杂而不具有通用性。
下面这张图是我训练营当中的一个标签库资料,其中有很多标签都是比较独特的标签:
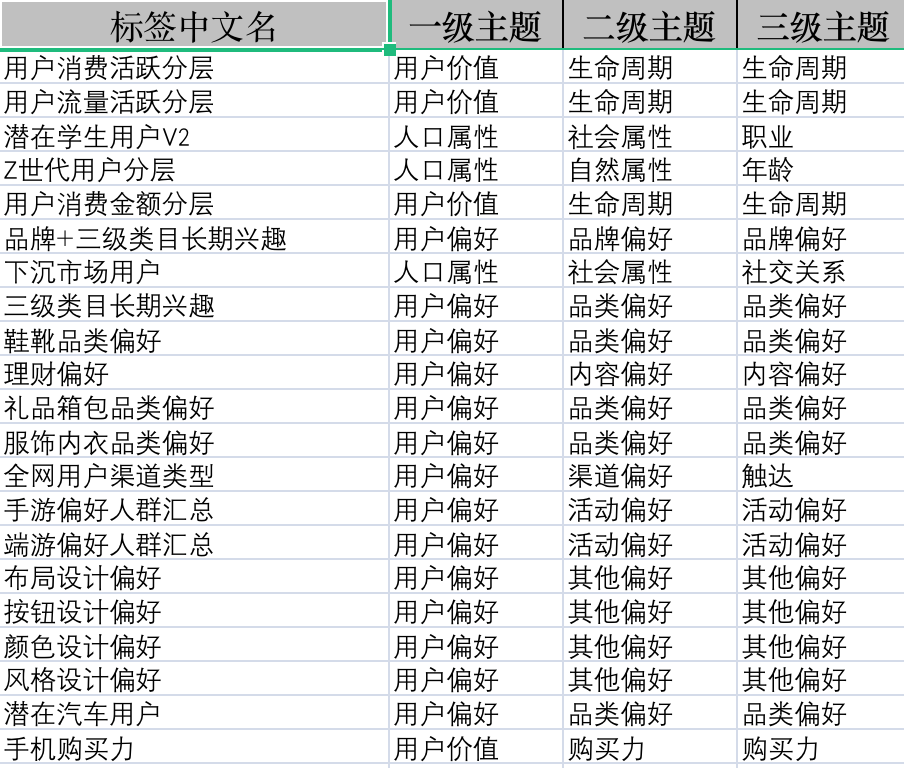
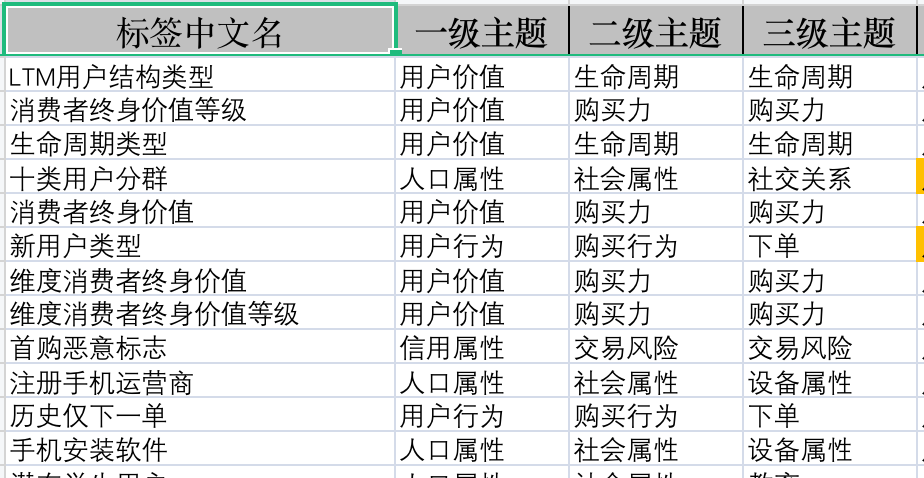
那么此时该如何生产自己的标签。
这里不得不说,在标签体系当中,对于推荐,精准营销等应用场景来讲,最常见,也是最常用的应该是偏好类标签,也就是用户喜欢什么。
因此,我们加工的思路也就很直接了,通过用户行为数据去进行偏好标签的加工,这是业界最常用的标签生产方式。
比如用户三级类目偏好,通过用户在平台的浏览,收藏,关注,加购,下单等行为,完全可以反映出用户的长短期兴趣偏好。

04 总结
推荐策略是解决互联网海量信息资源出现信息过载问题的方法,也是为了解决问题、提高效率的架构体系。在做推荐策略前先问问自己要解决哪方面的问题,这个推荐策略能提高哪方面的效率,不要为了做推荐而做推荐,推荐策略更多的是平衡商业化和用户体验的一个解决方案,要考虑自己业务整体情况去酌情调整。
本文由人人都是产品经理作者【夏唬人】,微信公众号:【策略产品夏师傅】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







- 目前还没评论,等你发挥!









