起点课堂会员权益
起点课堂会员权益
什么是顶级的数据分析方法?
 B端产品经理需要更多地进行深入的用户访谈、调研、分析,而C端产品经理需要更多地快速的用户测试、反馈、迭代
B端产品经理需要更多地进行深入的用户访谈、调研、分析,而C端产品经理需要更多地快速的用户测试、反馈、迭代在数据驱动的商业时代,数据分析成为了企业决策的重要工具。然而,面对众多复杂的数据分析方法,如何选择合适的工具来解决实际业务问题,成为了一个挑战。

经常有同学疑惑:
“什么是顶级的数据分析方法”
“面试的时候,被人问:用过什么方法,怎么回答好?”
“为什么我讲的分析方法,会被人嫌弃简单?”
今天系统盘点下数据分析方法,大家也好对号入座,看看自己讲的水平如何。
首先,并不是名字带“分析”俩字的,就是数据分析方法。有很多XX分析,是统计学、运筹学、数学的专业工具,并不直接指向业务问题的答案。当人们在问:“有什么分析方法”的时候,更多期望听到一个能给出结论的方法。
所以想回答好这个问题,要回到:数据分析到底解决哪些业务问题上去。
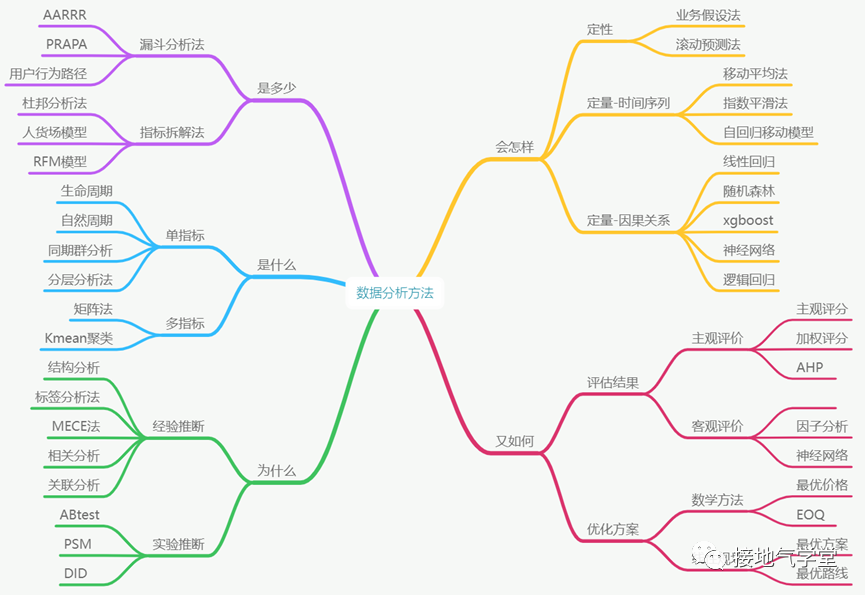
从业务用途上看,数据分析可以解决5大类问题
1、是多少(数据描述状况)
2、是什么(树立数据标准)
3、为什么(探索问题原因)
4、会怎样(预测业务走势)
5、又如何(综合判断状况)
围绕每个问题场景,有特定的方法组合(如下图)
一、解决“是多少”的方法
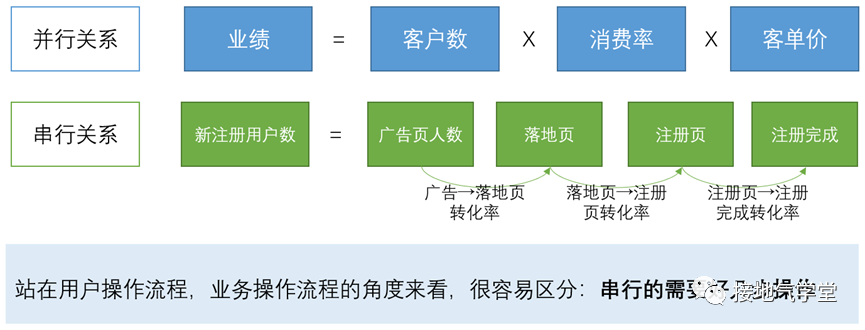
用数据描述状况,需要建立完善的数据指标体系。建立数据指标体系,则需要梳理清楚数据指标之间的逻辑。数据指标间有两种基本的逻辑:串行逻辑和并行逻辑,因此衍生出两种基本的分析方法:漏斗分析法&指标拆解法。
拆解的业务多了,人们发现,某些数据指标可以固定的组合使用,比如:
- 用户运营场景:AARRR指标、RFM指标
- 零售门店场景:人、货、场指标
- 商品管理场景:进、销、存指标
这些也习惯性被称为:分析模型。
但注意,这些都只是在展示数据。

数据+判断标准,才有分析结论。有关判断标准的分析,就是:是什么类问题。
二、解决“是什么”问题的方法
判断标准可以很简单,比如领导的指令、KPI要求、过往同期数据,都能作为标准。这些统称为:简单标准。但很多时候,指标走势是否正常,并无明确的KPI约束,甚至KPI达标,但是走势奇特,领导们还是会觉得有问题。这时候就需要找其他参照物。因此衍生出一系列分析方法。
比如:
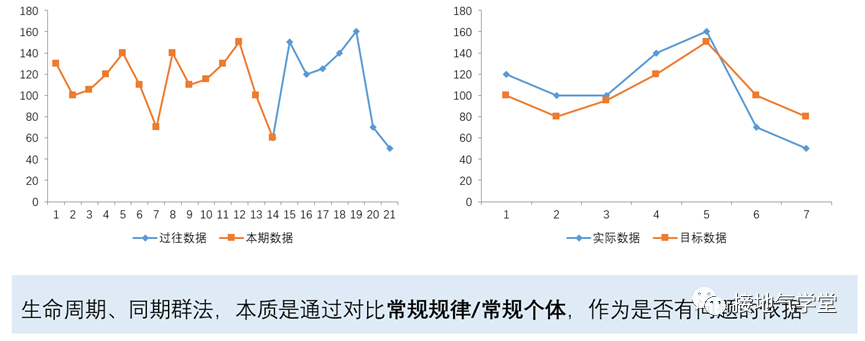
- 与业务自身规律比较,判断好坏:生命周期法、自然周期法
- 与同类型,同期发展的业务比较:同期群分析法
- 与其他业务个体进行比较:分层分析法
这样对比,即使只有1个数据指标,也能得出好坏判断。如果业务发展违背过往规律,明显比其他个体更差,则可以判定为:不好。
当然,也可以使用2个指标,比如经典的矩阵分析法,通过两指标交叉+两指标平均值,分出四类业务,从而得出好坏判断。
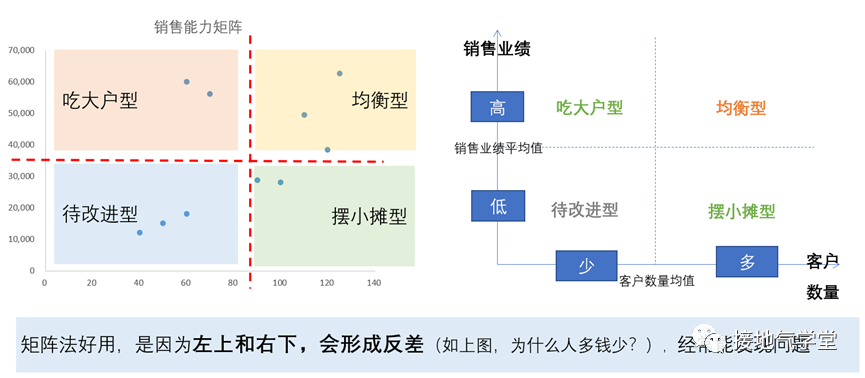
如果用更多指标也行,比如常用的Kmean聚类,可以先利用多个指标对业务个体聚类,之后再看各类型之间表现优劣。
以上这些方法,都能将业务的好/坏区分出来,从而在一定程度上辅助判断。
三、解决“为什么”问题的方法
“分析下这个问题是什么原因导致的……”是常见的要求,这就是“为什么”问题。
解决为什么问题,有两大基本思路:
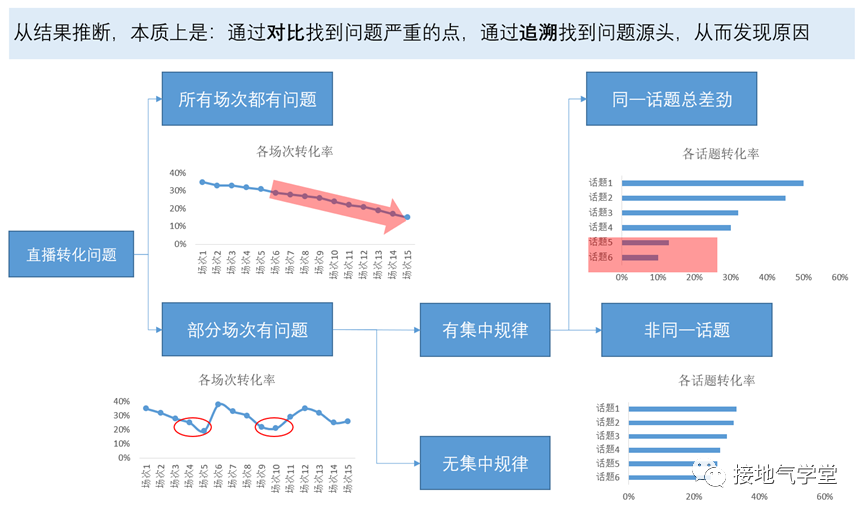
1. 结果推断:问题发生后,用各种数据寻找差异,建立假设。
常见的,比如:
- 结构分析法:通过结构分析,找到问题发生点
- 标签分析法:通过打标签,做个体对比,找到问题原因
- 相关分析法:通过计算指标相关关系,找到相关指标,再形成假设
- MECE法:讲多个业务假设,按MECE原则合并成分析逻辑,一一验证
结果推断,可以把业务口中“我觉得这是XX原因”,抽象成一个数据可验证的假设,因此适用范围非常广。但结果推断只是单方面从结果做归纳,有可能有偏颇,还需要实验验证。
2. 实验推断:先有假设,然后通过实验/分组对比,验证假设。
常见的方法包括ABtest、DID、PSM、RDD、Uplift等方法。
这些方法更接近传统统计学的实验,大部分都要求:
- 开展数据实验,验证假设
- 设参照组/实验组,且参照组/实验组特征相似
- 区分控制变量、环境变量,重点测控制变量的影响
实验推断有统计学依据,计算过程复杂,看起来更量化一些。但是对实验条件要求太高,比如大促销类ALL in的业务,比如商品、店铺这些无法控制环境的业务场景,比如业务员行为、内容传播等难采集数据的领域,都很难用。
理想的状态,肯定是两者结合,事实-假设-验证,不断循环,接近真相。但现实中有很多条件制约。导致我们只能从一个角度切入,慢慢靠近真相。四、解决“会怎样”问题的方法
预测类问题,是所有人都感兴趣的话题,也是统计学/算法最有可能发挥作用的地方。唯一限制方法使用的,是:到底有多少数据&业务人员要不要参与。
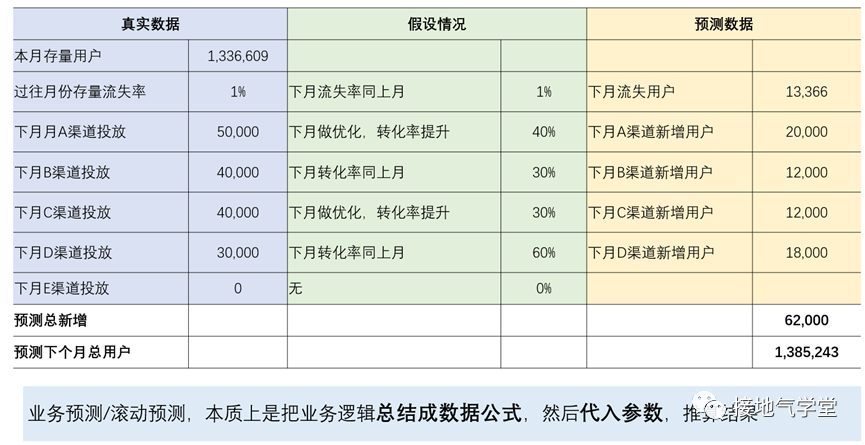
如果业务人员坚持参与预测过程,就只能用业务假设法或者滚动预测法,这些方法把影响结果的参数都列出来,方便业务人员拍脑袋,也能帮他们清晰:我要做多少。
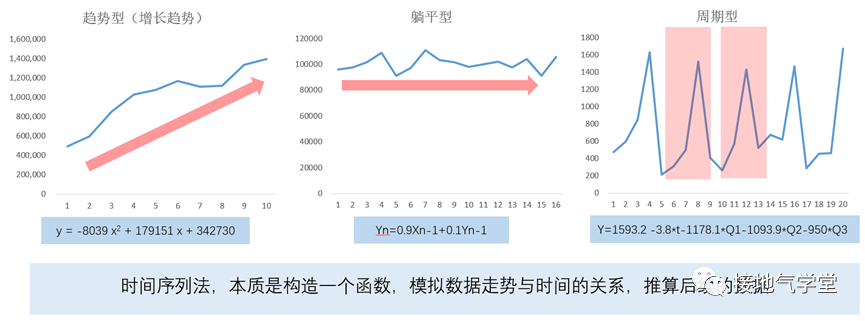
如果业务人员不参与,则视数据量的多少。数据少,则使用时间序列预测,数据多,且有影响结果的原因数据,则可以用诸如回归模型一类算法预测。
五、解决“又如何”问题的方法
综合评估与分配问题,统称“又如何”问题。这是决策的最后一步,决定是否对业务做动作,做多大动作。有些简单的评估是很容易的,比如销售签了生死状,达不成业绩目标就炒鱿鱼。
但大部分情况,评估很复杂,要考虑方方面面。这里最大的区别,在于要不要考虑领导的主观意见。如果要,果断使用主观评分法!满足领导的打分欲是第一位的。如果不要,再考虑使用有监督的机器学习算法,或者因子分析法,DEA法(求的是相对效率)等客观方法。
至于:做多少,谁来做。就是更复杂的问题了。想做好分配,得先把前边几步分析做完,对每个业务线基础能力有充分认识,才好下判断。这里,线性规划的方法,可以用来做支持。

六、为什么感觉没用上方法?
综上可见,数据分析的方法是非常多的。但为什么很多同学感觉自己没用上方法呢?因为每种方法是和业务场景、领导风格、数据质量、息息相关的。
比如因果推断算法大多基于分组测试展开,而实际业务中,很多因果分析是事后再查原因,也不给二次实验的机会。
比如很多公司的分配方案,根本就是领导拍脑袋,一言堂,根本没机会让分析师用算法。
比如预测问题,很多公司根本没有足够数据积累,只有一条销售数据,那撑死了也只能用时间序列法。
这种理想与现实的差距,让很多同学很痛苦。一方面不清楚到底这些方法该如何用,另一方面不了解,自己该如何应对业务需求。面试和工作都很吃力。
本文由人人都是产品经理作者【接地气的陈老师】,微信公众号:【接地气的陈老师】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







- 目前还没评论,等你发挥!