
 起点课堂会员权益
起点课堂会员权益浅谈AI视频厂商都在卷的拓展能力
在人工智能的浪潮中,AI视频工具正成为内容创作的新宠。文章从可灵AI的独立APP发布,到各大AI视频厂商的新功能盘点,揭示了AI视频工具如何在提高视频制作效率、降低成本的同时,也为内容创作者带来新的挑战和机遇。

前言
最近(24/11/11)刷到一个AI新闻,说可灵AI已经正式推出了独立的APP(原本挂载在快手的剪辑APP快影下方),并对外声称“目前可灵AI已经有超过360万用户,累计生成3700万个视频、超一亿张图片”。

3700个视频什么概念?如果全都按标准质量、5秒视频算,3700万个视频需要花费价值2590万的灵感值(可灵的抽卡货币)。不过这样算并不准确,因为:
1.存在额外增项:例如高质量生成需求、10s视频生成需求、拓展功能使用需求、1.5版本可灵使用需求等增购项目,这些内容会提高单个视频的收费。
2.存在灵感值赠送机制:可灵抽卡并非直接使用RMB,而是使用灵感值这个货币。除了充值获取,非会员每月登录都会送灵感值,而会员每天都会送灵感值。
所以实际收入多少,在缺乏更多数据的情况下,我这个门外汉也说不准。
但这让我想起三个月前(24年7月底)写的AI剪辑相关的分析《浅谈当前的AI剪辑工具》,当时俺对AI生成视频概括为“能一定程度上解决业务的需求,节省视频画面制作的成本”,但是存在诸如“指令识别不准”、“无法修改”、“模糊”、“人物动作合理性”、“身体细节错误”、“主体不一致”、“物理运动BUG”等问题,所以整体的使用上还“差点意思”。
而如今短短3个月过去,可灵就取得了一定的成绩。这一定程度上归功于可灵在近期发布的1.5版本,其中引入了新一代模型,画质和动态质量都得到提升,并且加入了运动笔刷、对口型、外放API等能力,生成效果和使用场景得到了加强和拓展。

同时随着各家AI视频能力的发展,网上AI视频相关的内容越来越多,这也说明用户们也在逐渐挖掘掘到的AI视频的应用场景。诸如小的在网上冲浪时候刷到的以下各种形式的AI视频:
1.人物转换视频:经常在短视频平台上刷到这种A转换成B,然后再转换成C的视频,给人一种很炫酷的感觉。这类视频主要是通过AI视频平台的首尾帧功能实现的,通过在首尾帧放上AB图片(也可以是AI生成的),就可生成A转换成B的视频。如此生成B转C、C转D……这些的视频后,通过剪辑拼接合成,就可以生成ABCD无缝转换的效果。

图片来自于抖音
2.人物互动:如果图片里面有两个人物,也可让AI视频生成两个互动的视频。如下图的A和B拥抱、A和B打架。拥抱的视频也经常被用于“和过世亲人互动”的场景,让人也能感受到AI的温度。

图片来自于百度
3.搞怪表情:最近有个比较火的AI魔法猫猫表情包,就是用图生视频能力实现的,还怪可爱咧~

截图来自于公众号“表情兔Bot”
4.超自然视频:小的看到有些人用AI生成一些超自然的视频,在微信上混淆视听。就比如有一天,家里长辈发了一个聊天记录,说“给大家开开眼”,结果俺点开一看是AI生成的。一开始长辈还不信,因为“视频没法P,所以是真的”。
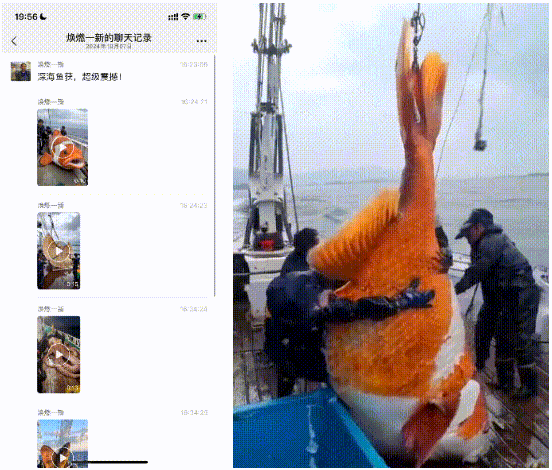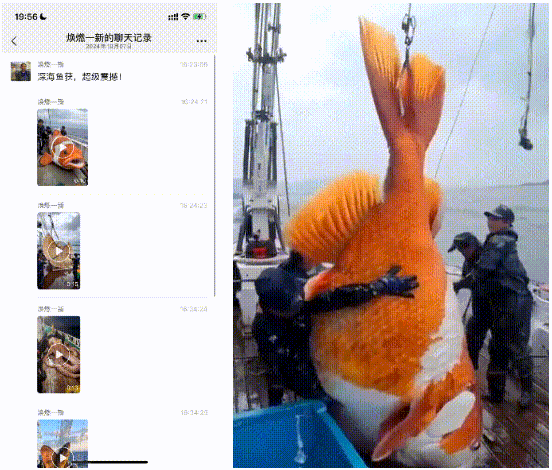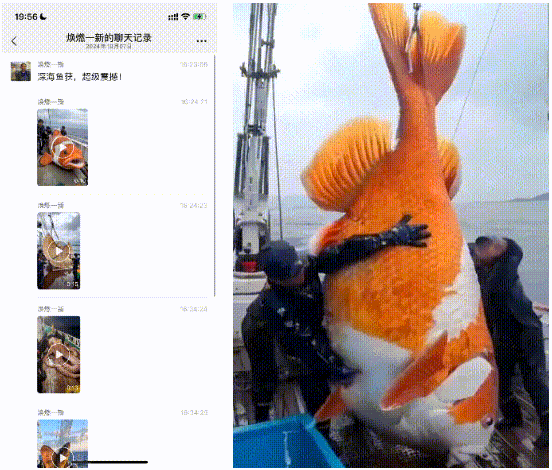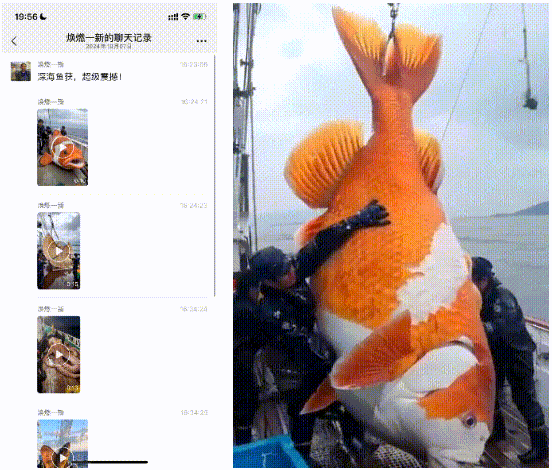
不得不感慨,AI视频仍旧对于大部分人来说,是超出认知的黑科技。万一这被利用来进行“针对老年人的诈骗”,那危险程度可想而知……
5.AI短片:这是AI视频一开始被认定的主流场景,用来进行视频的生产,也有不少厂商用其来生成AI短剧,比如抖音的《三星堆》。在可灵的“创意圈”上,我们也能看到有不少人生成的AI视频短片。
这些旺盛的用户需求说明随着会玩AI视频的人越来越多,这归功于各家AI视频厂商的共同努力,使得AI视频也开始走向真正走向“越来越多用户转化成消费者“的爬坡期。
图片来源于百度
但是AI视频生成的“指令识别不准”、“无法修改”、“模糊”、“人物动作合理性”、“身体细节错误”、“主体不一致”、“物理运动BUG”等问题还是阻碍其进一步发展的,这说明到达“成熟期”还有好长一段路要走。但是从各家AI视频公司的更新迭代中,我们也可以发现他们都是有尝试去通过各种各样的功能去解决当前阶段的“缺陷”的,而且除此之外,还会卷一些额外的拓展能力。
他们有尝试怎么样解决这些“缺陷”?这些功能又意味着什么?要下面这段就让小的来盘点一下。
当前的视频AI的能力
我们先分别讲讲每家AI视频厂商最近新增加的能力,拆解下他们是如何尝试解决AI视频的问题的。可灵AI
首先就是文首提到的可灵了,可灵最新的版本是1.5版本,其中引入了新一代模型,提高了画质和动态质量。
下面用一张图来分别对比1.5和1.0的效果,由于之前测试到可灵仅在真人视频上效果较好,所以测试的样本同样放了动漫和真人两种类型。

在动漫图片中,可灵1.0存在“生成的脸和手变形”、“手指和领带也穿模”等问题。而1.5虽然也有“嘴部动画瑕疵”、“电锯人拉环断了的物理BUG”等问题,但是手指变形和脸部变现问题得到了优化,可见其进步。
在真人图片中,可灵1.0存在“人物动作毫无逻辑”(这一堆人在干啥呢)、“米国旗飘动不自然”等问题。但是在1.5中可以看到,人物动作明显有一定的进步,自然且合理多了,而且米国旗的飘动显得十分自然。虽然还是存在“人物主体不一致”(女保镖变成了男的、人群中出现了两个未知的人)的问题。
可见,可灵1.5也一定程度上优化了“人物动作合理性”、“身体细节错误”、“主体不一致”、“物理运动BUG”的问题。
而且可灵还提供了以下额外的功能,以优化AI视频生成的效果和工具的能力边界:
1.尾帧:
该功能仅支持在1.0上使用,支持上传尾帧,以控制AI视频的走向,使得生成的视频不至于“太魔幻”。当然,这也是文首提到的生成A转B视频的工具。
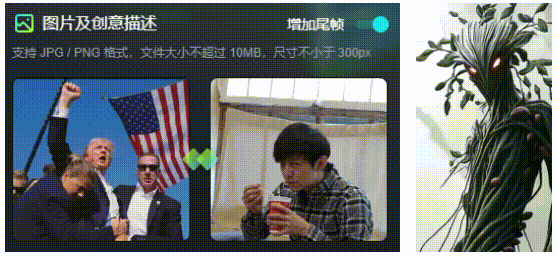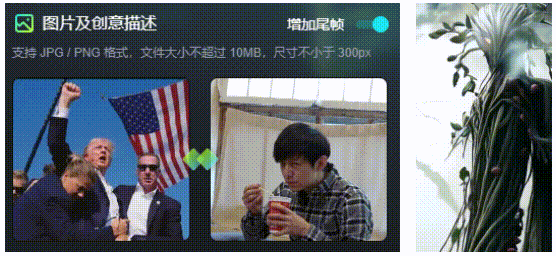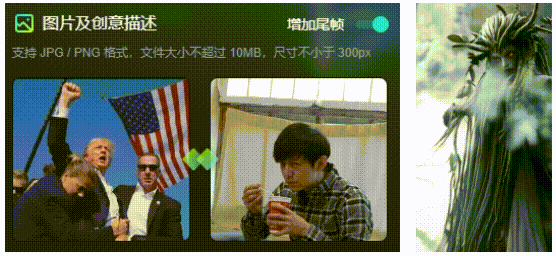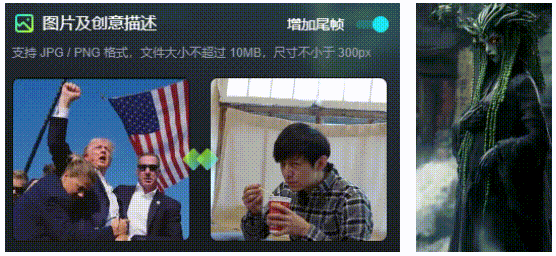
2.运动笔刷:
该功能仅支持在1.0上使用,该功能支持涂抹一定区域,并设定该区域的运动轨迹。也支持设定静止区域,该区域会保持不动。
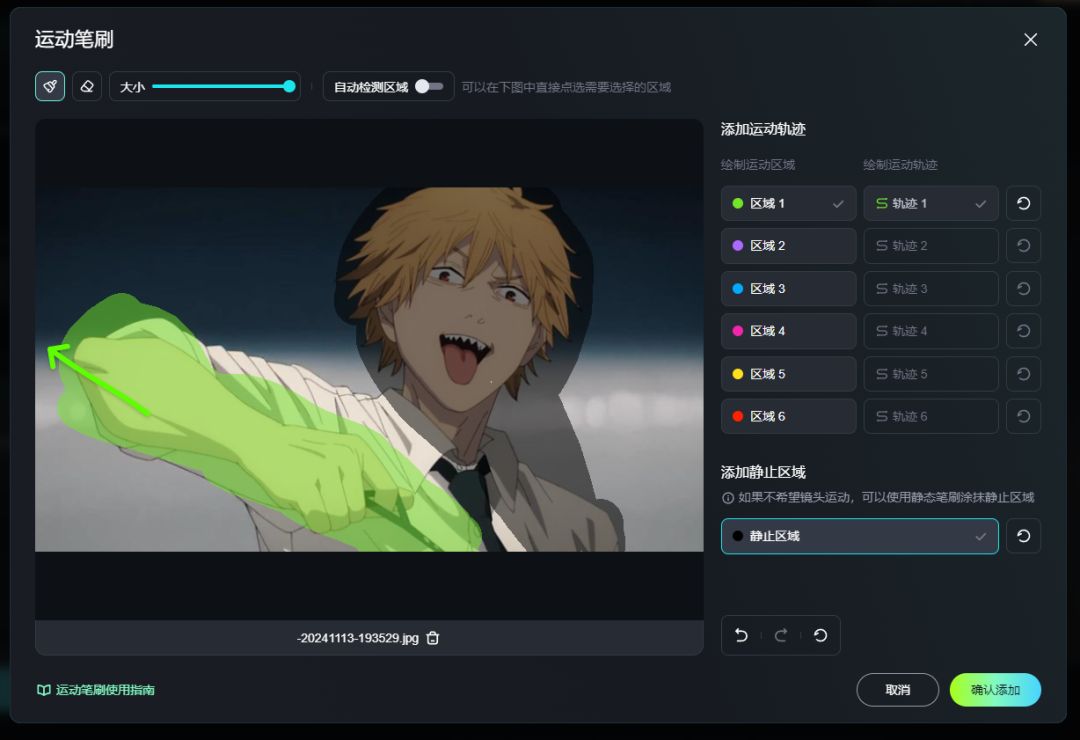
其中还提供了区域快捷选择的功能支持,方便快速选择区域。
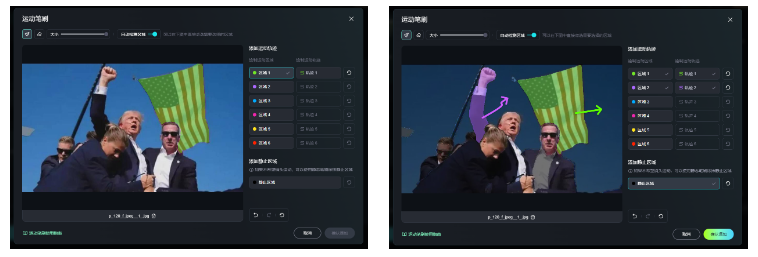
基于这个功能,就算是生成结果较差的可灵1.0,也能生成类似于1.5中的成品效果。(虽然存在“主体不一致”的问题,川建国的脸变现了。)

值得一提的是,使用该功能时,静止区域需要尽量选择多一点,否则会像下面一样,在莫名其妙的地方出现“物理运动BUG”。

3.参数控制:
然后是可灵支持了参数控制,包含“想象力/相关性”、“生成品质”、“生成时长”、“生成数量”。
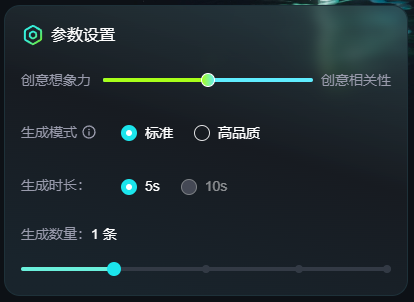
其中“生成品质”参数一定程度缓解了原本AI生成视频比较糊的问题。而“生成条数”解决了“AI生成准确度不足,需要多次抽卡”的问题,虽然解决方案是“让用户花N倍的钱抽多几次”,但是也能在使用时候,大大节省用户的操作时间。
4.运镜控制:
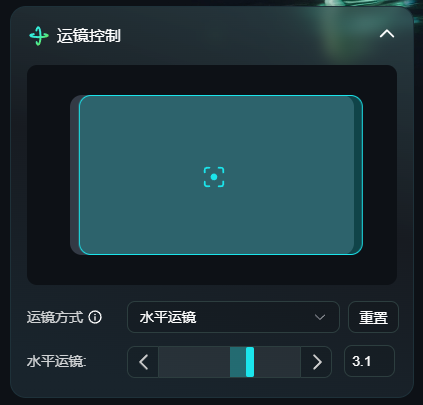
该功能可惜不支持图生视频,仅支持文生视频。该问题能一定程度解决AI乱运镜的情况。
先前在使用其他AI视频工具的时候,让人抽卡到崩溃的原因之一是“经常生成的谜之运镜”,比如:

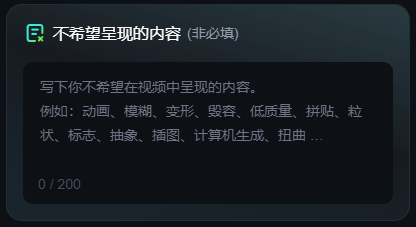
5.不希望呈现的内容:
这个就好像AI生图的负面提示词一样,通过描述不希望出现的画面内容,从而提高生成的准确度。
6.成品拓展修改:
对于已完成的成品,抖音支持二次进行拓展修改,其中支持“对口型”和“延长5s”。
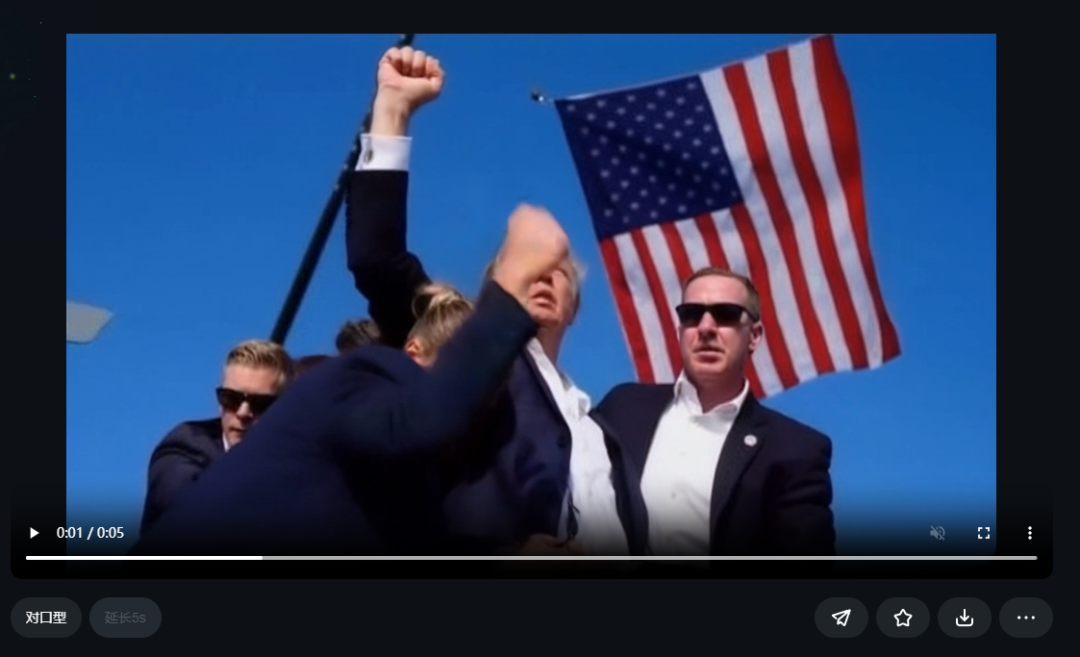
“对口型”支持识别到人脸的视频进行使用,可以自定义输入的文本,利用文生音技术和音频驱动口型技术生成说话的视频。或者自行上传本地的配音,实现生成说话的视频。
整体来说,说话的效果十分自然,比市面上能找到的开源方案效果更好。(川建国不能生成对口型的视频,看来风控做得还行啊哈哈。)

右图是人物在说话“你们吃了吗?”
7.API:
为了满足B端场景的大批量生成需求,可灵还提供了API接入服务。虽然价格有点贵,但是在AI准确度不够需要多次抽卡的当下,是一个能够让AI生成视频在业务场景上发挥价值的重要能力。因为这能避免人肉进行大批量的繁琐操作,也能避免生成后的超长时间等待,从而大大提高了B端场景上的AI视频使用效率。(BTW,花钱效率也上来了hhh。)
8.创意圈:
这是可灵推出的社区功能,用户可以在上面上传高质量的视频,也可以直接打开别人的视频,一键生成同款。
该功能同时起到了AI能力展现、用户教育、创作者挖掘的作用。即梦AI
紧接着是字节系的即梦AI,其在11/8号宣布了使用全新的视频模型S2.0,宣称其能有更快的生成速度和更高的品质效果。

我们来用同样的图片来验证下其效果。

在动漫图片中,1.2(旧版本模型)生成的结果基本都有问题,人物毫无动作,就算在2.0上也并没有优化这个问题,反而是生成了“谜之运镜”。
在真人图片中,1.2生成结果较为“保守”,人物动作基本没有BUG,但是“米国旗飘动不自然”。而2.0上反而有点“大胆到抽象了”,我不信邪地抽多了几次,得到的都是较为抽象的结果。其中存在较为明显的“人物动作合理性”、“身体细节错误”、“主体不一致”、“物理运动BUG”的问题。
由于测试样本有限,未能看到较为明显的提升,但是可能是我的测试样本并未在升级的方向上。
即梦也同样提供了以下额外的功能,以优化AI视频生成的效果和工具的能力边界:
1.尾帧:
和可灵一样,拓展功能暂不支持最新的模型使用。也是通过首尾帧图片来控制视频的走向,以保证成品的准确度。
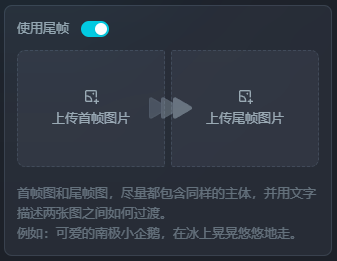
2.动效画板:
该功能同样仅支持1.2版本使用,用于框选主体位置,然后控制运动轨迹,以提高成品的准确度。
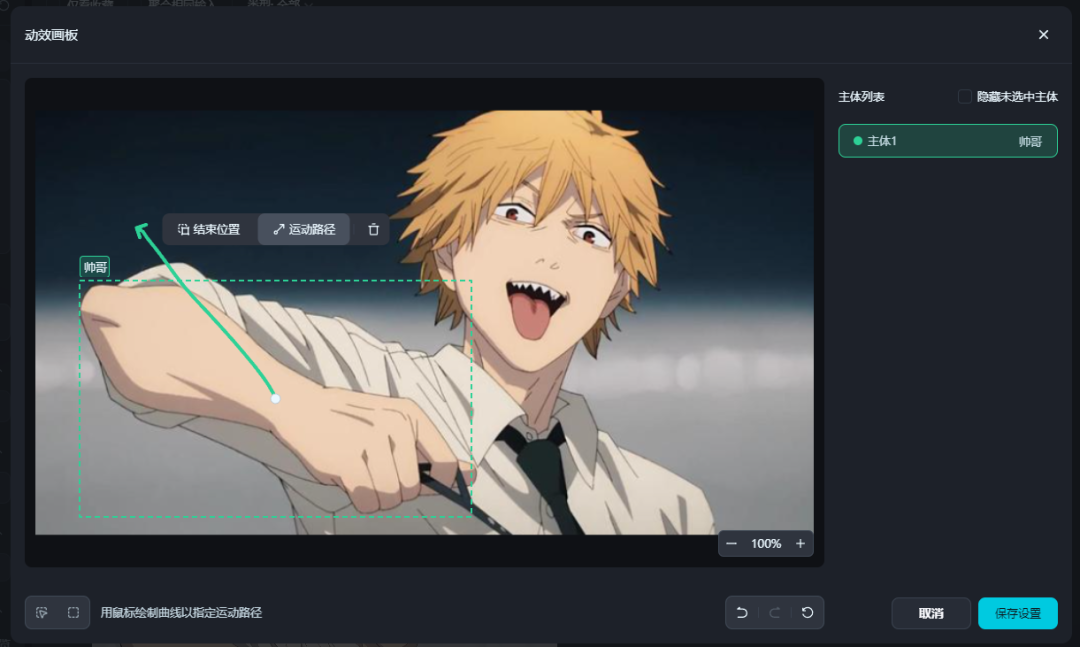
不过即梦仅支持控制主体的位置,不像可灵可以控制多个区域的动与静。

虽然BUG很多,但是手还是动起来了hhh。
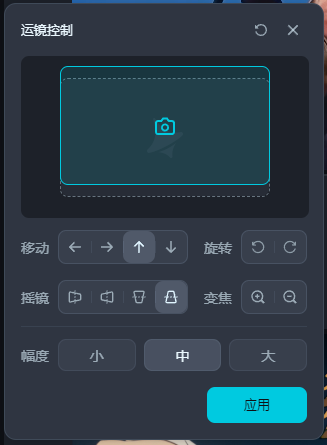
3.运镜控制:
该功能同样仅支持1.2版本使用,用于控制运镜方向,减少谜之运镜的生成。
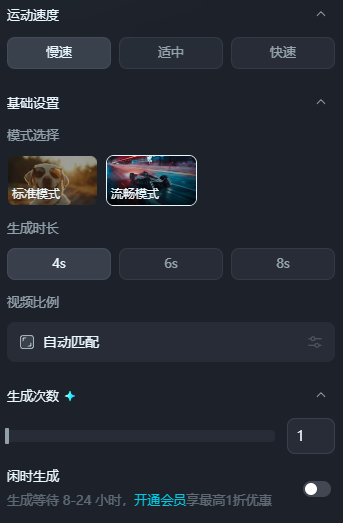
4.参数控制:
即梦提供了如“运动速度”、“生成模式”、“生成时长”、“视频比例”、“生成次数”、“闲时生成”等的参数,相比起可灵多了速度和模式的控制项目。
5.对口型:
即梦也有对口型能力,相比起可灵,该能力可以单独上传一张人物肖像进行口型生成,整体来说会更方便。(但是也增加了风险,因为非AI生成的人物也能用来对口型,可以用于一些侵权/造谣的违法场景上。)
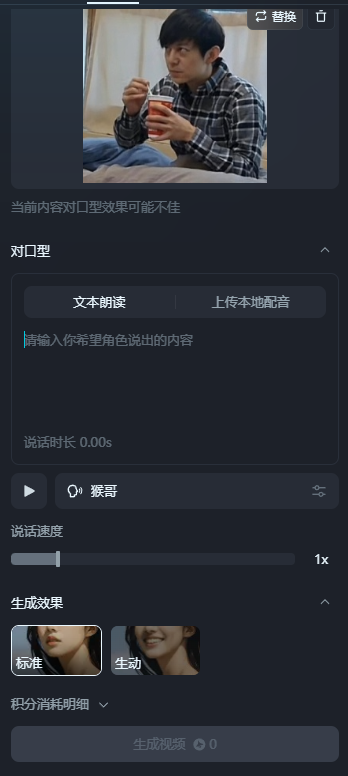
6.成品拓展修改:
对于已生成的视频,即梦支持“视频延长”、“对口型”、“补帧”、“提高分辨率”、“AI配乐”,这里的能力会相对比可l灵更多点,方便视频制作者生成满足其需求的视频内容。

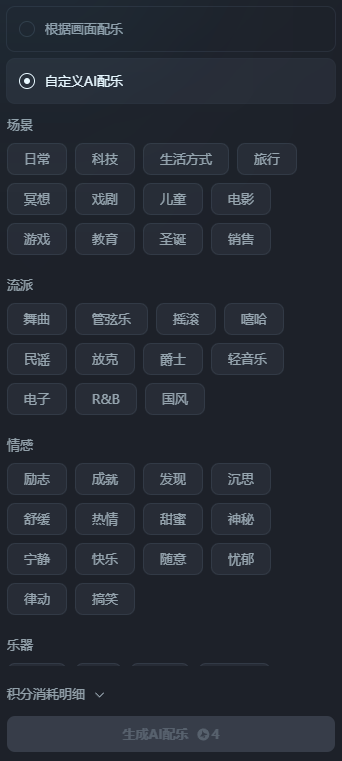
值得一提的是其中的AI配乐能力,可以由AI自由发挥,或者人工指定音乐的场景、流派、情感、乐器进行生成,以生成更符合需求的配音。
7.故事创作:
故事创作功能允许用户导入脚本,按分镜进行视频创作、图片创作,配合上音频编辑能力,以一键生成AI视频。
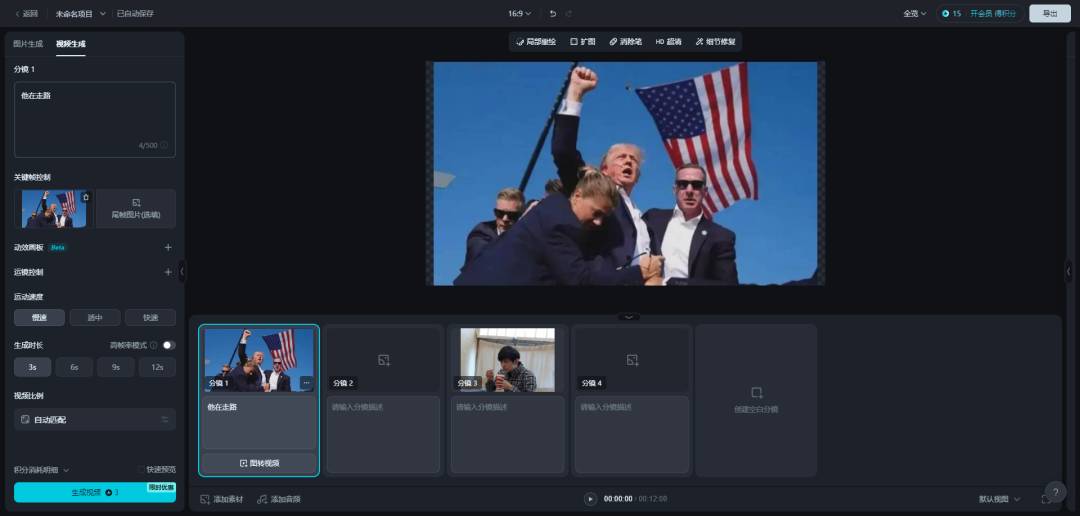
该能力与LTX Studio、SkyReels等AI视频短剧的建设思路是一致的,用脚本把多个AI视频串联起来,以生成一个完整的AI视频,节省用户二次剪辑的工作量。但是在AI生成的准确性不足的情况下,这个方式也会叠加各个视频的不准确性问题,从而降低成品质量,或者翻倍其中的“抽卡成本”。
8.探索:
与可灵一致,即梦提供了类似于创作圈的功能,用于展示高质量的成品,用于能力展现、用户教育、创作者挖掘。
Luma
Luma最新的版本是9月左右更新的1.6版本,其中发布了运镜控制功能。

为了验证其效果,我拿出了4个月前的抽卡结果进行对比。

无论是动漫还是真人图片,Luma两个版本的表现都存在很大的问题,并没有较好的优化。
Luma用于“优化AI视频生成的效果和工具的能力边界”的功能有:
1.尾帧:
和前面提到的可灵、即梦一样,Luma也支持上传尾帧,以控制AI视频的走向。

2.运镜控制:
相比起可灵和即梦的运镜控制,Luma的运镜相比起来十分简陋,仅支持输入文本进行控制,不能进行精细的幅度控制。
3.循环功能:
个人理解这个功能其实就是“尾帧”的一种应用,而且选择“Loop”之后,也不允许上传尾帧了。该设置项能让视频首尾一致,以进行循环播放。

4.API:
Luma支持API,可供大规模调用。
Runway
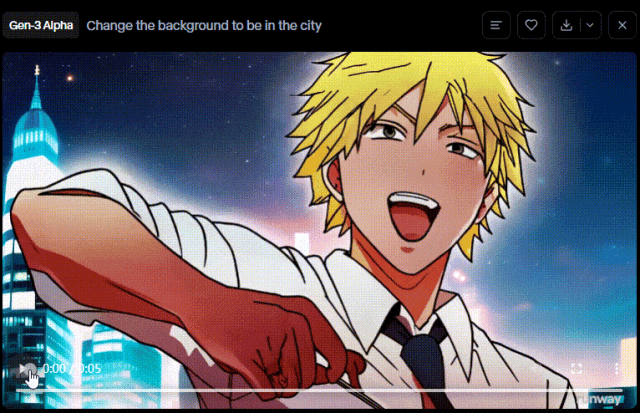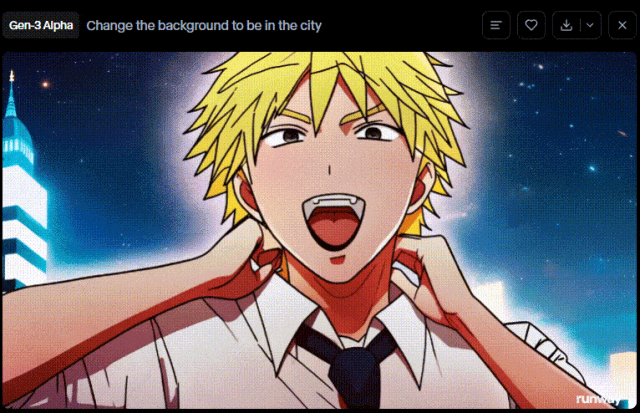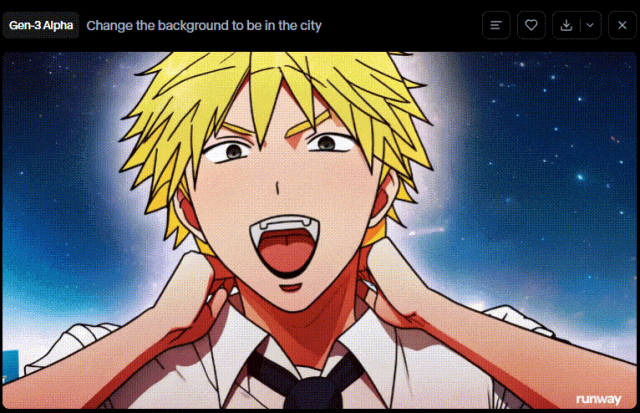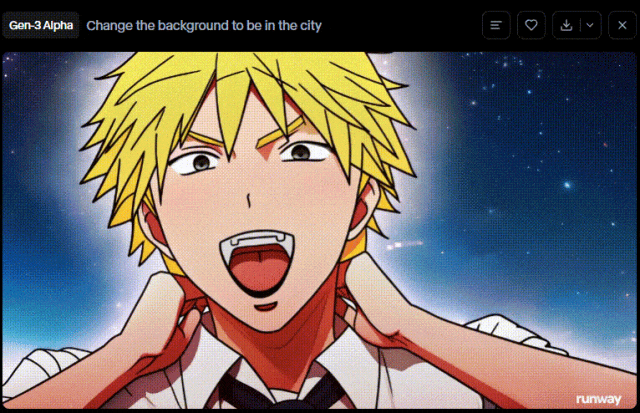
Runway在更新Gen-3 Alpha 和 Gen-3 Alpha Turbo之后,更新了一个Act-One的能力。
我们来用同样的图片来验证下其效果。

在动漫图片中,Gen-2存在“画面模糊”、“人物脸部异常变现”等问题。但是在Gen-3 Alpha上,这些问题被很好地解决掉了,虽然存在“电锯人拉环断了的物理BUG”,但是人物主体保持得很好。
在真人图片中,Gen-2的结果有点惨不忍睹,“主体不一致”(川建国都成国旗了)、“人物动作毫无逻辑”(他们在下沉?)。而这些问题,在Gen-3中的带了很好的解决,虽然还有点动作僵硬。
相比来说,Runway新版本的能力提升还是比较明显的。
那么下面小的汇总下Runway上的拓展功能点:
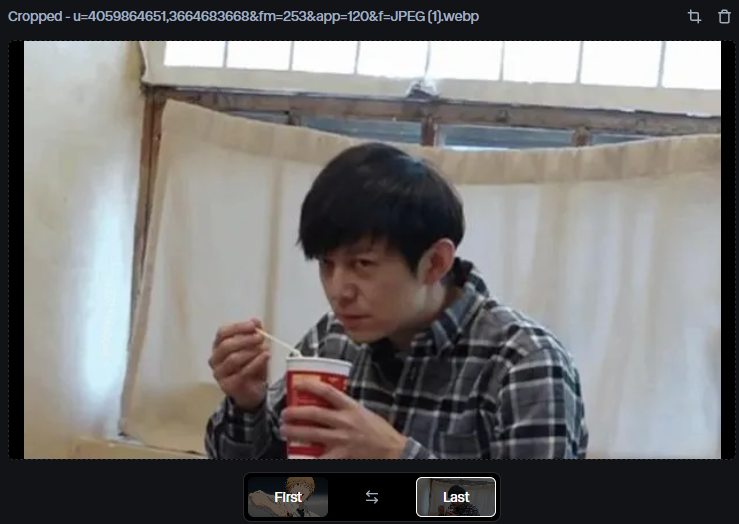
1.尾帧:
本质上和前面的功能一致,不赘述。
2.运动笔刷:
和前面的“运动笔刷”、“动效画板”一致,不赘述。
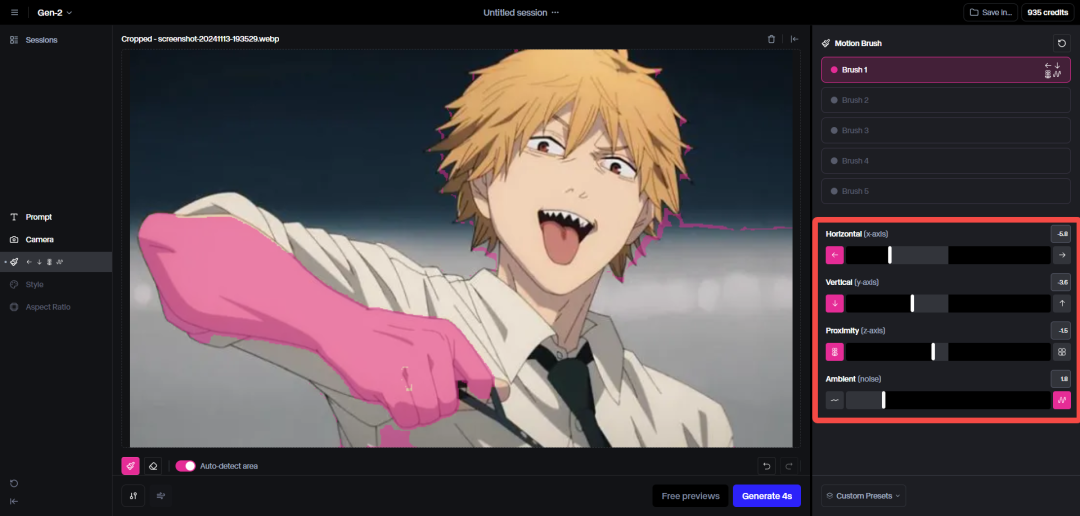
不过这个轨迹控制是用坐标参数控制的,有点反人类。
3.参数控制:
Runway的参数支持“清晰度”、“种子”、“水印”、“插帧”、“生成时长”……
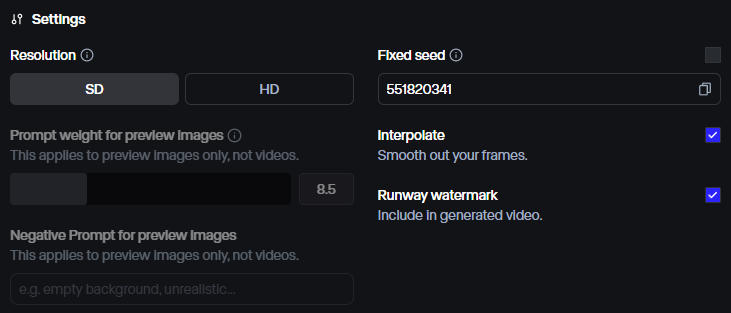
不像国内那样支持多轮抽卡,属实难受。
4.运镜控制:
和前面的“运镜控制”类似,不赘述。
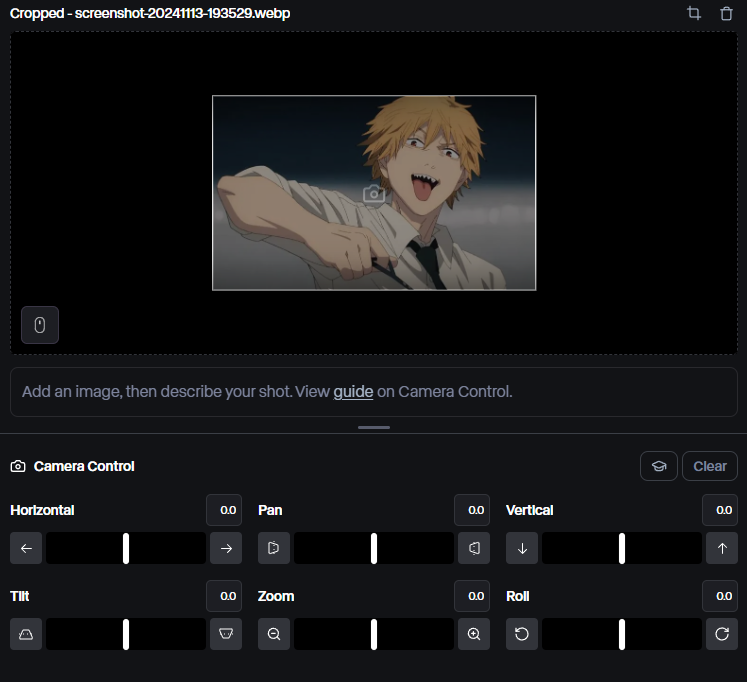
5.Act-one:
这是Runway最新推出的一个能力,可以上传一个“脸部清晰”、“身体动作较少”的视频,然后使用AI驱动一张目标图片进行脸部动作学习。
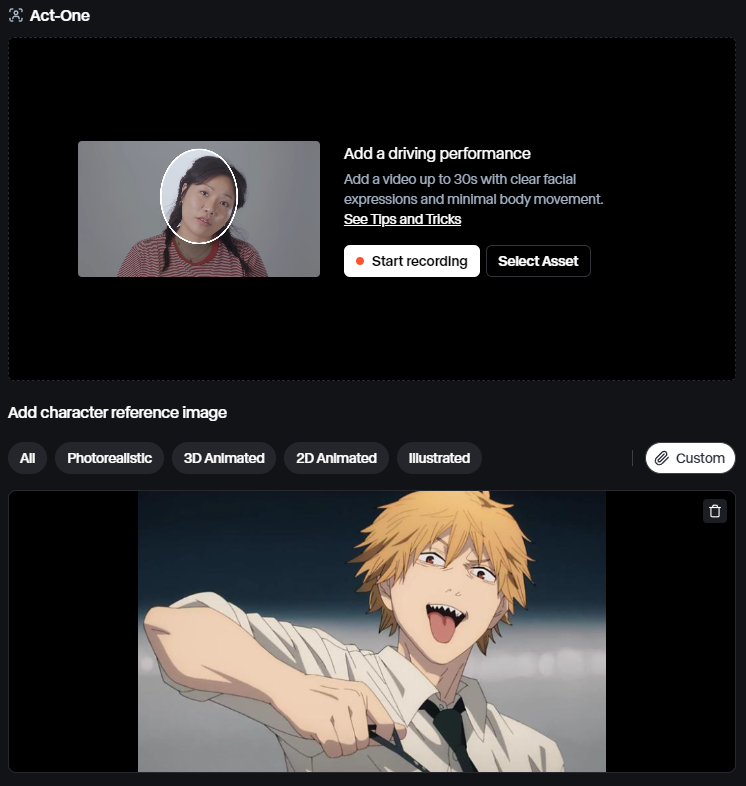
该能力其实和转口型能力是同源的,都同样是脸部动作转换。

(哈哈,2次元动漫图片的效果还是差点意思。)
6.成品拓展修改:
对于已完成的视频,Runway支持“视频拓展”(生成多N秒)、“对口型”(不赘述,和国内一致)、“视频生视频”(适用于重绘、转画风、细节补充等场景)、“时间剪辑”(改视频长度or速度)等拓展修改能力。
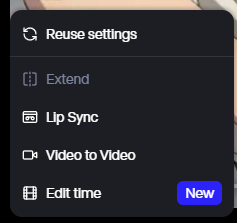
7.API:
Runway支持API,可供大规模调用。
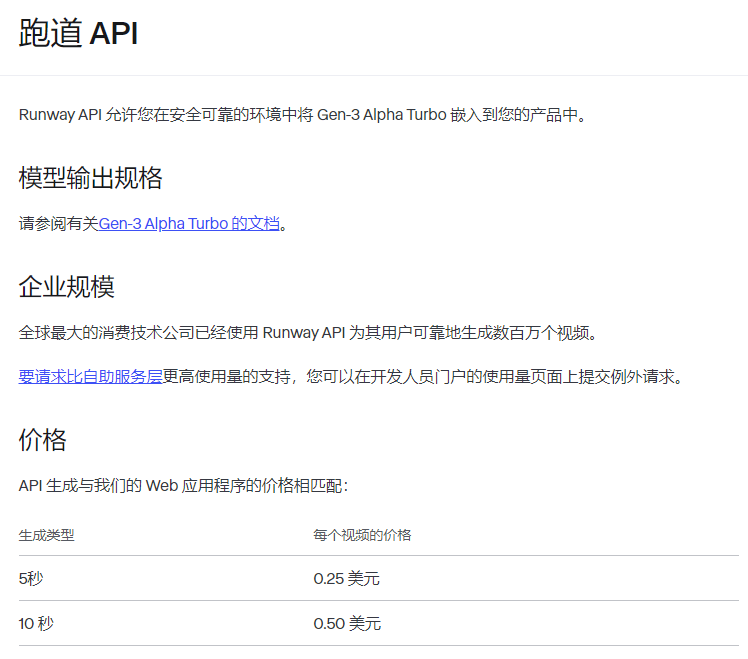
8.Runway watch:
等同于国内的“创意圈”,用于进行AI能力展现、用户教育、创作者挖掘。
其他特殊能力
本来还想把PixVerse、清影、PIKA、海螺等视频生成AI也都看一遍,但是普遍都需要充值会员,且拓展的功能除了上面提到的,主要就是以下这些了。下面列举一下:
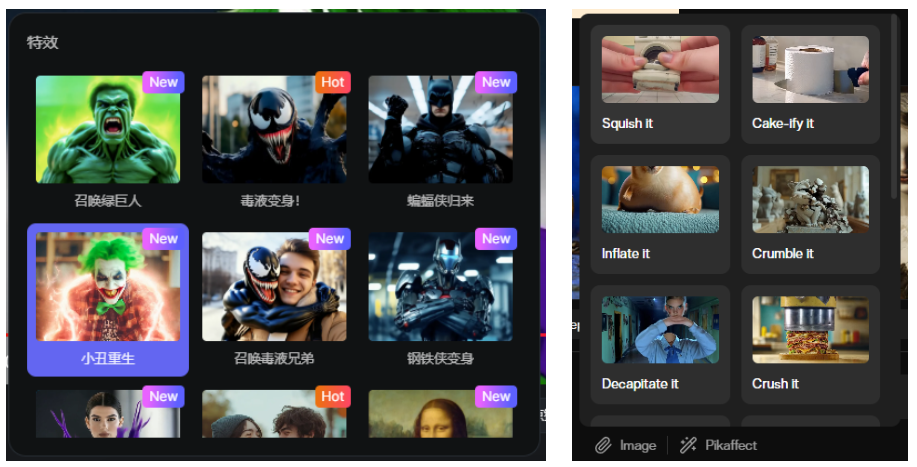
1.特效玩法:
目前该能力仅看到在PixVerse和PIKA上出现,该玩法支持生成各类好玩的特效视频,比如“捏碎一切”、“毒液变身”……

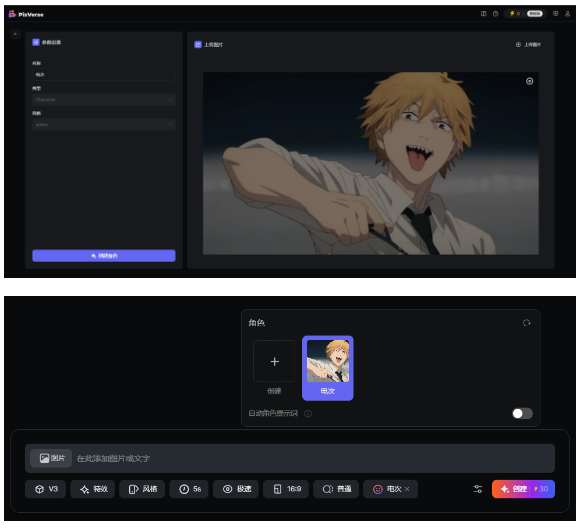
2.角色控制:
这是PixVerse上的能力,支持选定一个角色,然后AI会生成该角色的视频,以保证主体的一致性。
小结
为了方便对比各家的能力,我这边列了一个表格:
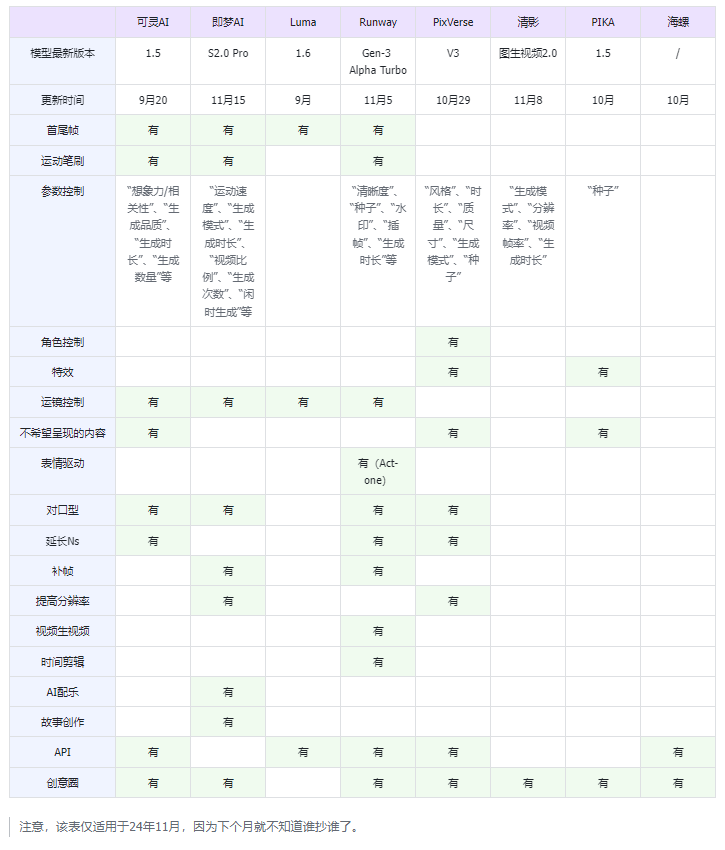
通过以上的调研,我们可总结出,各厂商为了解决AI视频的问题,推出的功能可以分为以下几类。
1.更牛的AI大模型解决根本问题:
针对AI视频的问题进行大模型训练,能从根本上解决视频AI的问题。这个虽然是个完美的解决方案,但也有问题,就是成本太高、周期太长。
特别是在如今这么多家同时竞争的情况下,如果把希望全部都放在“成本高、周期长”的新一代模型上,对一家企业来说风险很高。很有可能由于回收周期太长,看不到未来可行性,股东先行撤资。或者别家的“新一代模型”投入更多、速度更快,通过先发优势使得企业的投入全部白费。
2.更多的控制项目提高生成准确度:
在AI不能完全理解我们输入的意图前,需要通过一些固定格式的参数来控制AI输出的质量。这些固定格式的参数在“大语言模型”的使用上,又可称为“提示词工程”。
而在视频生成AI领域,我们可以利用“控制项目”来提高生成结果的准确度,以保证AI能尽可能满足业务的需求。虽然目前部分AI模型并不能完全遵循全部指令,但是也能一定程度上减少AI的“发散”,生成相对稳定的结果。
目前常见的控制项目有“首尾帧”、“运动笔刷”、“生成品质”、“生成时长”、“特效”、“运镜控制”等等。这些功能在AI大模型新版本出来之前,一定程度上能缓解视频AI的问题,并解决一定程度的需求。
目前AI视频越来越多,一定程度归功于这些功能的发明。就比如“首尾帧”功能造就的“A转B转C”这类视频。
3.拓展的视频能力满足更广泛的场景:
按照俺之前的梳理,视频制作流程分成了寻找灵感、制作草稿、收集素材、剪辑成稿。
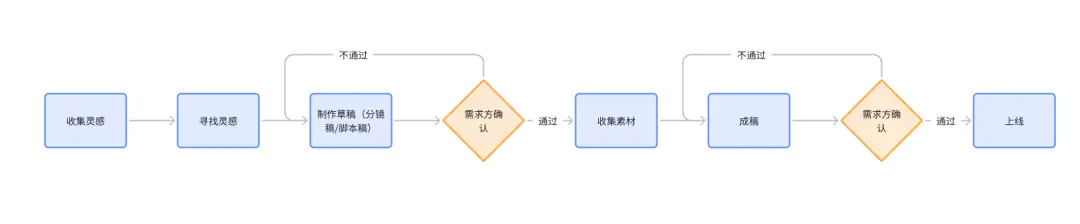
而前AI生成视频技术仅仅能解决“制作草稿”、“收集素材”环节的部分需求。因此部分AI视频厂商开始尝试拓展视频制作业务的上下游场景,从而提高视频AI工具的能力边界,以满足更多的用户需求。
比如,大部分厂商都推出了“对口型”能力,这是在试图满足视频制作过程中的“配音制作”需求,使得视频制作的效率更高

又比如,即梦推出的故事创作能力,这里将“寻找灵感、制作草稿、收集素材、剪辑成稿”环节全部整合到了系统上,包含了分镜稿、画面生成、配音生成环节,最终一键生成AI视频。
4.用户教育以让用户用得更好:
AI视频毕竟是一个复杂的工具,并不是所有用户都能用好的,如果无法完全发挥工具的全部实力,那么所有的开发成本、训练成本都会被白白浪费,因此需要一定程度的用户教育手段。目前各厂商主要是通过“创意圈”这类功能来实现用户教育目的的。
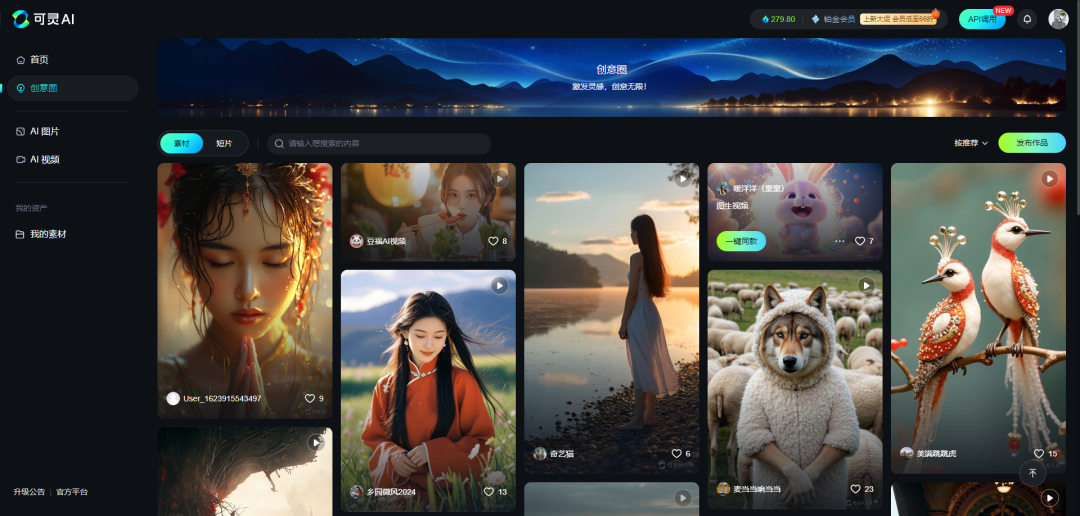
所谓创意圈,即创作者社区。通过在上面发布高质量的AI视频来展现AI的能力,让用户了解到“这个AI能做到这种程度”,并产生尝试的欲望。
同时,创意圈还会支持用户“一键生成同款”,这个过程中就起到对AI工具参数设置的教育作用。
此外,平台方还需要不断挖掘其中的KOL创作者,以打造优质的内容生成,并将其中的优质内容发布在社交媒体上,打造平台的影响力,吸引自然量用户。
5.大批量的调用方式以提升使用效率:
由于视频生成AI存在准确度问题,所以目前AI生成视频是必定需要多次抽卡的。
为了避免人肉手动操作进行多次抽卡而产生的“超长等待时间成本”,目前部分厂商提供了“一次性生成多个视频”和“API调用”这些方案。
虽然这些方式会增加平均的抽卡的费用,但是能提升抽卡的效率,也能提高“AI最终生成目标视频”的概率。为什么要卷这些拓展能力
整体来说,目前视频AI厂商拓展的这些能力都是共同为了“更好地满足视频制作需求”这个目的。
其中,更牛的AI大模型、更多的控制项目能够提升成品视频的质量,拓展的视频能力能够满足更广泛的视频制作场景,用户教育、大批量的调用方式能辅助用户更好地运营AI视频工具。
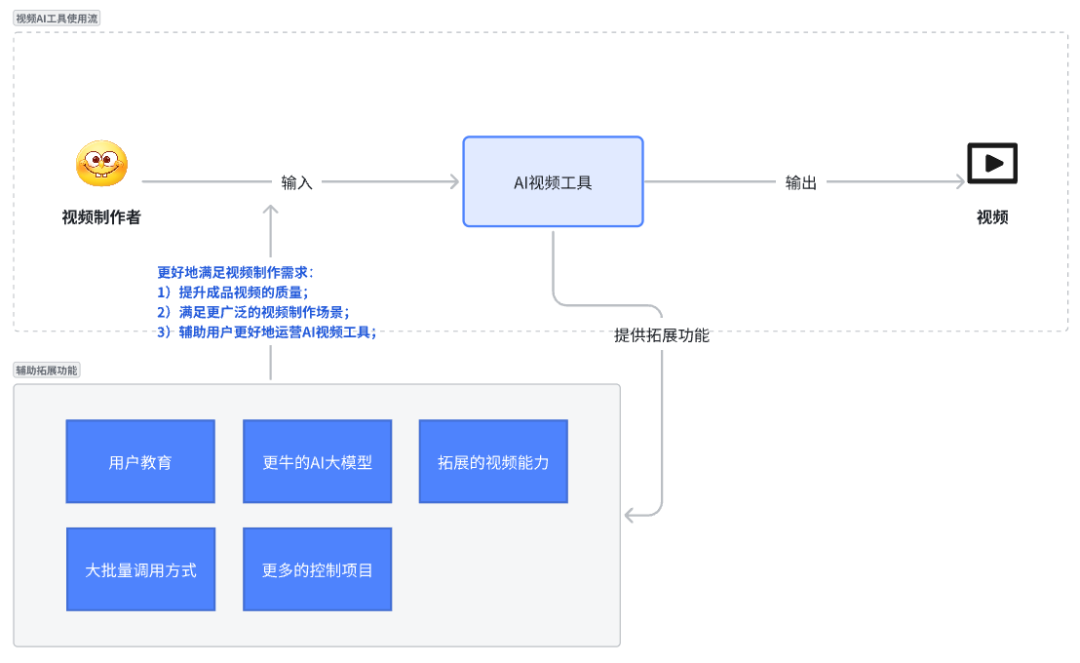
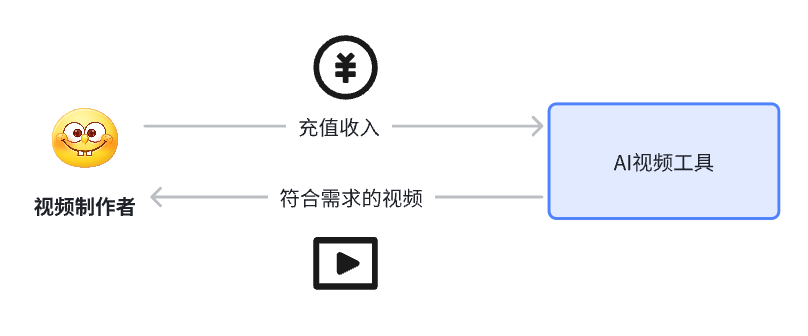
当用户的视频制作需求被满足时,用户就会留存在AI视频工具平台上,从而给厂商贡献充值收入。这就构成了“视频制作需求”与“充值收入”的价值交换模型。
但是“满足视频制作需求”这个其实是可以分为三个层次的,可以称之为视频制作需求的“点、线、面”。
1.视频制作需求的“点”:
所谓“点”,即仅仅满足视频制作环节的某个单点需求。比如“寻找灵感、制作草稿、收集素材、剪辑成稿”中的单个视频片段制作、配音生成、剪辑合成等。
个人理解目前大部分的AI视频厂商都处于这个层次,即AI视频能力的积累阶段。
2.视频制作需求的“线”:
所谓“线”,即通过多个单点需求的同时满足,满足了一整条工作流的需求,实现从0~1的工具辅助。即梦AI的“故事创作”功能就承载了即梦“点连成线”的野心,只不过由于AI视频的准确度问题,目前该能力只能满足极其有限的需求。
目前大部分AI视频厂商都在试图通过布局各种能力点,从而满足某个工作流的需求。
3.视频制作需求的“面”:
所谓“面”,即通过同时满足多个工作流程的需求,从而形成的一整套“视频行业解决方案”。这应该是所有AI视频厂商的终极愿景——用AI颠覆&垄断整个领域。
但是厂商是不可能一下子就发展成某个“面”的视频需求解决工具,而是需要逐渐积累,点连成线、线连成面,这也是我们看到不少厂商在拓展各种AI视频能力。
此外,部分能力还起到的一定的营销作用。通过其好玩的、有新意的新能力,吸引各种用户使用,并在社交媒体上发布,形成裂变效果。
就比如Pika的“捏爆一切特效”、PixVerse的“毒液变身特效”,这些新能力能结合热点(毒液电影),或者其本身足够好玩,能吸引一定的基础热度。其次能够让用户制作自身的专属视频,满足用户的好奇心、自我表达欲望。这些因素的叠加构成了一定程度的“裂变营销”,为AI视频平台积累了一定的知名度和影响力,吸引一定量的用户以及赚取一定量的会员收入。

值得一提的是,目前各家AI视频厂商的能力其实是难以一较高低的,因为AI视频模型是有擅长领域的区别的,有些模型擅长单人动作,有的擅长多人互动,有的擅长风景,有的会点猎奇画面,这与他们的训练样本相关,每个厂商的样本都会各有侧重,总之各有各的不同。
对用户来说,他们是较难选择一款合适自己AI视频产品的,他们只能选择能力较为齐全、口碑较好的产品。因此某种程度上,营销能力决定着AI视频厂商的生死。(但也不能瞎宣传,自身能力还需扎实,满足目标群体的需求,否则会留不住用户,也会让用户产生一些负面的认知。)小结
小结一下。“为什么要卷这些能力呢?”总的来说是三点:
1.更多的拓展能力能更好地满足用户的“视频制作需求”,能在当下吸引更多用户,赚取更多收益,为厂商在后续的竞争中积累优势。
2.这是厂商颠覆和垄断整个“视频制作领域”的前置步骤,需要积累足够多的能力点,然后点连成线、线连成面。
3.部分能力能够让厂商在竞争中“弯道超车”,毕竟营销做得好,能填补一定程度的产品能力差距。谁更容易卷成
如此看来,各家的思路其实也是大差不差的。那么谁更容易卷呢?
之前在《浅谈当前的AI剪辑工具》有提到过,目前我的想法还是和之前一样。主要是满足以下三点的厂商更容易卷成。
1.有用户:用AI视频工具能吸引到足够的目标用户。
2.能赚钱:能够跑通与用户价值交换的商业逻辑。
3.有壁垒:在前两个过程中构建自己的竞争壁垒,以源源不断进行价值交换。
这里再补充一些新的思考吧。
先讲讲第一点“有用户”的拓展思考。
就和AI剪辑工具一样,AI视频工具会有细分方向,比如不同用户类型、不同行业等等。不同方向的用户群体会具有不同的AI视频需求。

因此个人觉得,AI视频厂商必须围绕着目标用户群体的需求进行大模型训练,才能够积累到足够的目标用户。
对于已经领先同行好几个版本的头部厂商来说,他们只需要从已有用户中提炼一些高价值需求,针对这部分用户提供满足他们需求的AI能力,便能稳住他们的基本盘,并在此基础上拓展更多的领域。
但是对于还在刚刚起步的厂商,他们就必须进行目标人群的差异化竞争了。因为AI的规模效益存在,后发者往往需要更多的资源和投入才能赶超,因为想要在有限资源的情况下赶超是不可能的。只能瞄准头部厂商尚未覆盖的用户群体,针对他们的诉求训练专属的视频大模型,圈住自己的基本盘用户群体。
那么有什么可以差异化的区域吗?这里讲讲我个人遇到的一些痛点hh:
比如,目前测试过那么多家AI视频厂商,大部分都集中在真人视频方向(可能也和这个方向的训练难度有关系),具有卡通Q版AI视频生成需求的用户就无法用得上。
再比如,目前测试到的大部分AI视频的动作幅度都比较大,那些小幅度的动图基本很难生成出来,对于想要做广告展示图片的制作者来说,目前的AI视频较难满足需求。
再讲讲第二点“能赚钱”的拓展思考。
其实目前AI视频的商业模式基本上都是能赚钱的,只要圈住了目标用户群体,AI视频本身能满足他们的需求,他们就会源源不断地购买会员。
但是除了模型训练、功能开发、人力、设备机器相关的成本,这里还会需要考虑到“营销”和“竞争”层面的支出,由于竞争者众多,也需要在营销层面进行投入,也需要考虑进行一定程度的“价格战”。
比如可灵就在搞价格战。

最后一点“有壁垒”暂时没有补充。
壁垒内容主要在于大模型能力、用户量级、行业方案解决能力等方面上。
小结
以上,便是个人最近对AI视频工具一些观察和思考了,欢迎指教一二。
本文由人人都是产品经理作者【柠檬饼干净又卫生】,微信公众号:【柠檬饼干净又卫生】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


