
 起点课堂会员权益
起点课堂会员权益预训练——ChatGPT背后的关键技术
这篇文章介绍一下什么是预训练,并通过预训练了解一连串和ChatGPT相关的常见名词解释,监督学习,无监督学习,自监督学习,强化学习以及微调。

不知道大家会不会好奇,ChatGPT为什么会叫ChatGPT?反正一开始我们的好几个项目里都在引入GPT模型,看名字就知道ChatGPT和GPT有千丝万缕的关系,但本着产品经理的好奇心,我还是去搜索了下……
- Chat:因为就像和人一样在聊天,理解~
- G:Generative;嗯,因为是生成式人工智能,没毛病~
- P:Pre-trained;预训练,预先就先训练好了很多东西?
- T:Transformer;嗯,深度学习中很有名的一个架构,合乎情理~
同时我也搜索了下,GPT的发展史,在这里顺便总结下供大家参考~
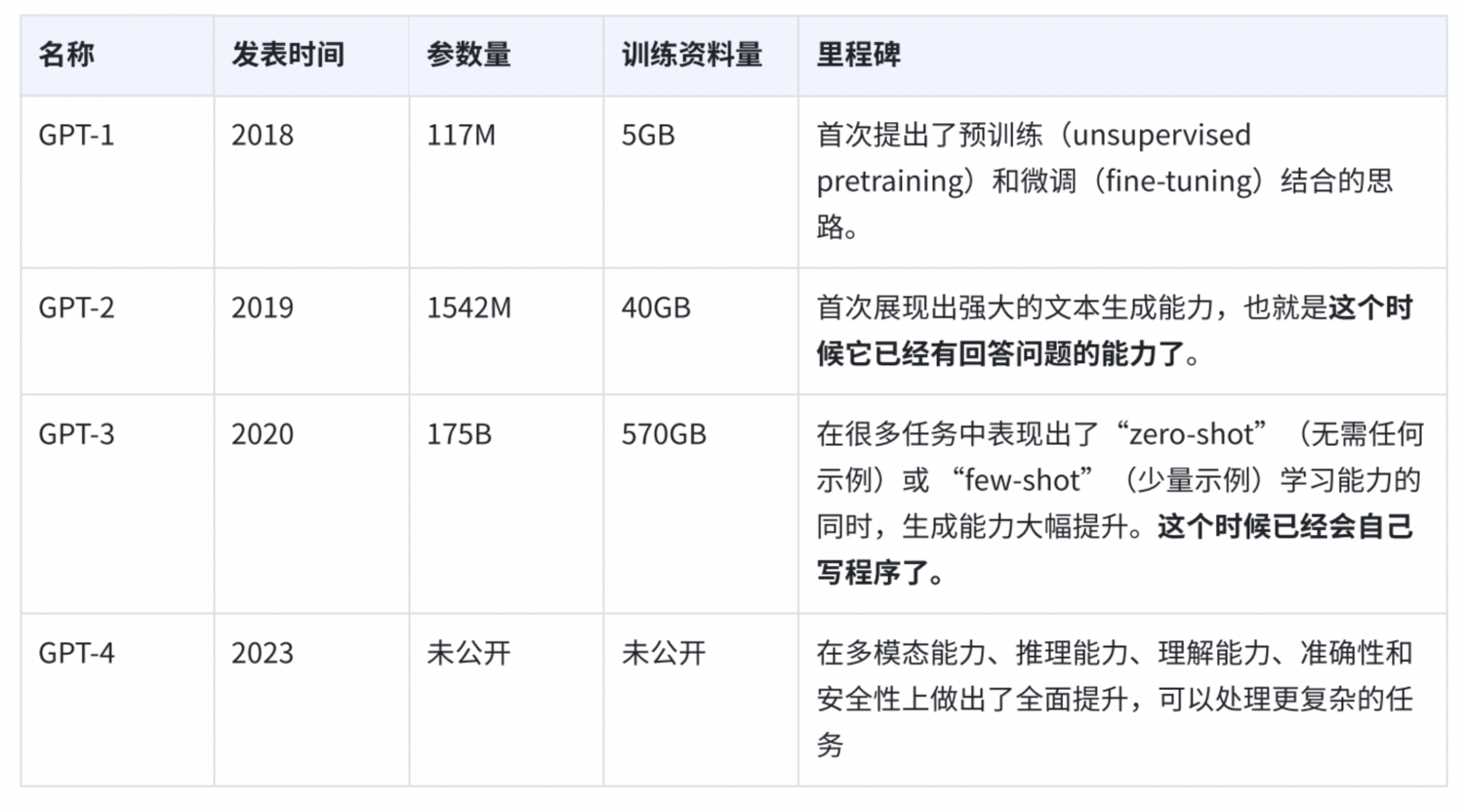
可能有人会问GPT-3.5,GPT-4o,这些又是什么,其实,简单总结来说,把GPT-3拿来做微调再用的都叫GPT-3.5,GPT-4o是GPT-4的一个优化版本,更适合用于大规模、高效的应用场景。
这次搜索也同时引发了一个问题,GPT-1提出了预训练的概念,其中用到了unsupervised这个词,不禁让我想到了监督学习(Supervised learning)。
一、什么是监督学习?
简单来说,就是人类提供成对的资料让机器学习的技术叫做监督学习(Supervised learning),它是实现人工智能目标的一个重要技术。
成对资料就是给定输入(Input)和输出(Output),让机器学习输入和输出之间的Mapping关系。
比如
- 输入为用户的产品评价,输出为正面评价/负面评价
- 输入为一封Email,输出为垃圾邮件/不是垃圾邮件
- 输入为汽车前面的照片+雷达信息,输出为其他车辆的位置
通过学习输入和输出之间的Mapping关系,使得机器在给定输入(Input)时,能够生成相应的输出(Output)。
这些成对资料都需要人类提供,不难想象,这需要大量的人力资源,而且还会有一个问题,就是人类可以提供的成对资料是有限的。一旦有一个新的问题是之前人类没有提供的,就可能回答不了。
二、预训练:更高效的成对学习
有没有一种更简单的方式获得大量的成对资料呢?
在前面好几篇文章中,我们都提到了ChatGPT在做的事就是预测下一个token,然后做文字接龙,从而可以提供一个不错的回答给到你。有没有可能,网络上的每一段文字都可以教机器怎么做文字接龙。
比如
中国的首都是北京。
床前明月光,疑是地上霜。
夏天天气真热。
这样,机器就可以从网络上这些巨大量的资料中开始勤奋的学习了~
比如
输入“中国的首都是”,那输出“北”的概率越大越好;输入“中国的首都是北”,那输出“京”的概率越大越好。
输入“窗前明月光”,输出“逗号”的概率越大越好;输入“窗前明月光,”,输出“疑”的概率越大越好,以此类推。
输入“夏天天气”,输出“真”的概率越大越好;输入“夏天天气真”,输出“热”的概率越大越好。
通过大量网络资料学习的过程,我们称之为预训练(Pre-trained),有时候也叫自监督学习(Self-supervised Learning),因为这些成对的学习资料不是人类提供的,自监督学习通过数据本身来生成监督信号,是一种无监督学习(Unsupervised learning)方法。
预训练可以从大量无标注数据上学习到普遍适用的特征,而GPT非常专注的在做这件事情,就是去网络上获取大量的资料学习做文字接龙这件事,也就是可以反复预测下一个单词。
三、预训练的优缺点
1. 好处
- 加速训练过程
- 提高泛化能力:如果我们在多种语言上做了预训练之后,只要教某一个语言的一个任务,其他语言也会自动学会相同的任务。
3. 缺点
从GPT-1开始就这么学习一直学习到了GPT-3,可以看到GPT-3已经的训练资料量已经庞大到很难想象了,但问题也随之产生,GPT3虽然能力很强,但是不受控制,不一定会给出我们想要的答案。
比如,当我问一个问题想要获取答案的时候,很有可能它在网络上大量的资料学习的时候,曾经在某张试卷上看到这个问题被出了一道考题,它就把这道考题当作答案回复给了我。
那怎么可以让它更受控制,给出我们想要的答案呢?
那就需要人类的介入了。
人类说,输入“中国的经济中心是哪个城市”,输出是“上海”。
GPT就透过人类提供的资料继续学习,就变成了ChatGPT。
所以ChatGPT是通过监督学习(Supervised learning)产生的,也就是这个时候人类提供了成对资料让它继续学习。
而继续学习很多时候叫微调(finetune)。
四、强化学习:从依赖到超越
我们前面也有提到,人类提供成对资料还是比较辛苦的,那有没有更轻松的办法呢?
有,这个办法叫强化学习(Reinforcement Learning),人类不需要准备正确答案,只需要告诉机器答案好还是不好。这种方法特别适用于连人类产生正确答案都比较困难的时候,比如,请挑选二十四节气中的一个写一首诗,这个时候人类给出这首诗是否符合要求相对轻松,但是自己写一首这样的诗就会相对困难。
五、总结
让我们来梳理一下在这篇文章中出现的概念吧~
ChatGPT学习的三个步骤
1. 预训练(Pretraining):通过大量的网络资料学习让模型学习如何预测下一个词,有时候也叫自监督学习(Self-supervised Learning),而自监督学习是一种无监督学习(Unsupervised learning)方法。
2. 监督学习(Supervised learning):使用了人工标注的成对资料微调(finetune)模型以适应特定的任务,特别是对话任务。
3. 强化学习(Reinforcement Learning):人类对模型的输出进行评分,并根据这些评分来优化模型,使得模型逐步学会生成更加符合人类偏好的回答。从而更精确地满足用户需求。
本文由 @AI 实践干货 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


