
 起点课堂会员权益
起点课堂会员权益解锁AIGC产品经理转型秘籍–大模型知识
在过去的几十年中,人工智能(AI)从科幻电影中的异想天开,已经逐渐走进了我们的现实生活,以AI为核心的内容生成技术(AIGC)正在掀起一场创作领域的革命。

以下内容源于个人对AI相关领域的自学知识总结,如有专业人士还请指点。
让我们开启一场沉浸式的AI之旅吧~
一、基础概念
人工智能是什么
是一门研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的技术科学。它企图了解智能的实质,并生产出一种新的能以与人类智能相似的方式做出反应的智能机器。(来源:百度智能回答)
大模型是什么
大规模预训练模型,指具有大规模参数和复杂计算能力的机器学习模型(深度学习模型)。在深度学习领域,大模型通常是指具有数百万到数十亿参数的神经网络模型。这些模型通过在大量数据上进行预训练,能够捕捉复杂的数据模式和关系。
AIGC是什么
指通过人工智能技术生成内容的一种方式,人工智能通过学习大量的数据,实现自动生成各种内容,如文本、图像、音视频等。
AGI是什么
通用人工智能,指机器能够完成人类能完成的任何智力任务的能力,甚至超过人类,目前处于理论阶段。
AIGC与大模型的关系是什么呢?

二、大模型分类
按照输入类型分类:
1.大语言模型(NLP):
处理文本数据和自然语言,如文本生成、问答系统、语音转文字、情感分析、机器翻译等;
应用例如:GPT系列chatGPT(OpenAI)、Bard(Google)、文心一言(百度);
2.视觉大模型(CV):
用于图像处理和分析,如图像分类、图像生成、目标检测、医学图像分析等;
应用例如:VIT系列(Google)、文心UFO、华为盘古CV、INTERN(商汤);
3.多模态大模型:
能处理多种不同类型数据,如文本、图片、音视频等;
应用例如:DingoDB多模向量数据库(九章云极DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、midjourney。
三、语言大模型
初识语言大模型
这里着重介绍大语言模型(NLP),查阅大语言模型相关资料时,经常看到NLP、LLM、GPT、ChatGPT、Transformer……这些都是什么呢,之间又存在什么关系呢?
NLP自然语言处理,是人工智能领域的一个分支,是一种学科/应用领域。而LLM大型语言模型,是NLP领域中的一种特定类型的语言模型,是指一个广泛的分类,涵盖了所有使用大量数据进行训练的、能够处理和生成自然语言的AI模型。而GPT是这一类模型中的一个特定例子,是LLM的一种实现,通过海量数据训练的深度学习模型,能够识别人的语言、执行语言类任务,并拥有大量参数。它使用Transformer架构,并通过大规模的预训练,学习语言的模式和结构;ChatGPT则是基于这些内容而实现出来供我们使用的产品。
1.基于以上的了解,可将LLM、GPT、Transformer、ChatGPT的关系用下图表示:

Transformer是基础架构,LLM是建立在这种架构上的一类复杂系统,GPT是LLM中的一种特定实现,并通过大量的预训练,获得了强大的语言处理能力。而已发布的ChatGPT使用了GPT技术进行了产品的呈现。
2.为了更好理解LLM、GPT、Transformer三者的关系,我们可将他比作建筑的不同部分:
1)Transformer:基础结构
将其想象为一座大楼的框架,Transformer提供了基本的支撑和形状,里面详细设计为空,决定了建筑的整体设计和功能;
2)LLM:整体建筑
可理解为是建立在前面框架上的整体建筑,不仅有框架(即Transformer架构),还包含了房间、电梯、装饰等,使建筑完整,功能丰富;
3)GPT:特定类型的建筑
可被视为大型建筑中的一种特定类型,如一座特别的摩天大楼,他不仅使用了Transformer架构,还通过特定的方式进行了设计和优化(即大规模预训练),以实现特定的功能,如高效的文本生成和语言理解。
语言大模型原理
基本关系如下:

其构建过程简单描述可以为:
数据预处理(如数据清洗等)➡️ 模型结构设计(Transformer架构)➡️ 模型训练 ➡️ 模型部署
1.模型结构:
为解析句子,预测下一个单词;
LLM模型主要用到了Transformer架构,语言大模型中设置了多层规则,为从不同的角度理解与分析句子,试图预测下一个将要出现的单词;
简单分层来说:
第一层规则:理解句子中的单词或短语的含义;
第二层规则:理解句子之间是怎样关联的;
第三层规则:从前面的句子内容,来理解下个句子;
2.模型训练:
用海量数据训练模型,提高语言的准确度;
下文会举例GPT的训练过程,此处不做赘述。
核心Transformer
语言大模型的核心是Transformer,是基于注意力机制的深度学习模型(神经网络架构),用于处理序列到序列的任务。简单来说,就是捕捉句子中不同位置的词之间的关系,用于如理解上下文信息、生成连贯逻辑一致的文本等,且能高效并行计算。
1.Transformer主要核心结构如下:

1)其核心组成部分包含:
2)主要涉及的工作原理:
2.基于以上的了解,我们来补全一下Transformer的内部结构如下:
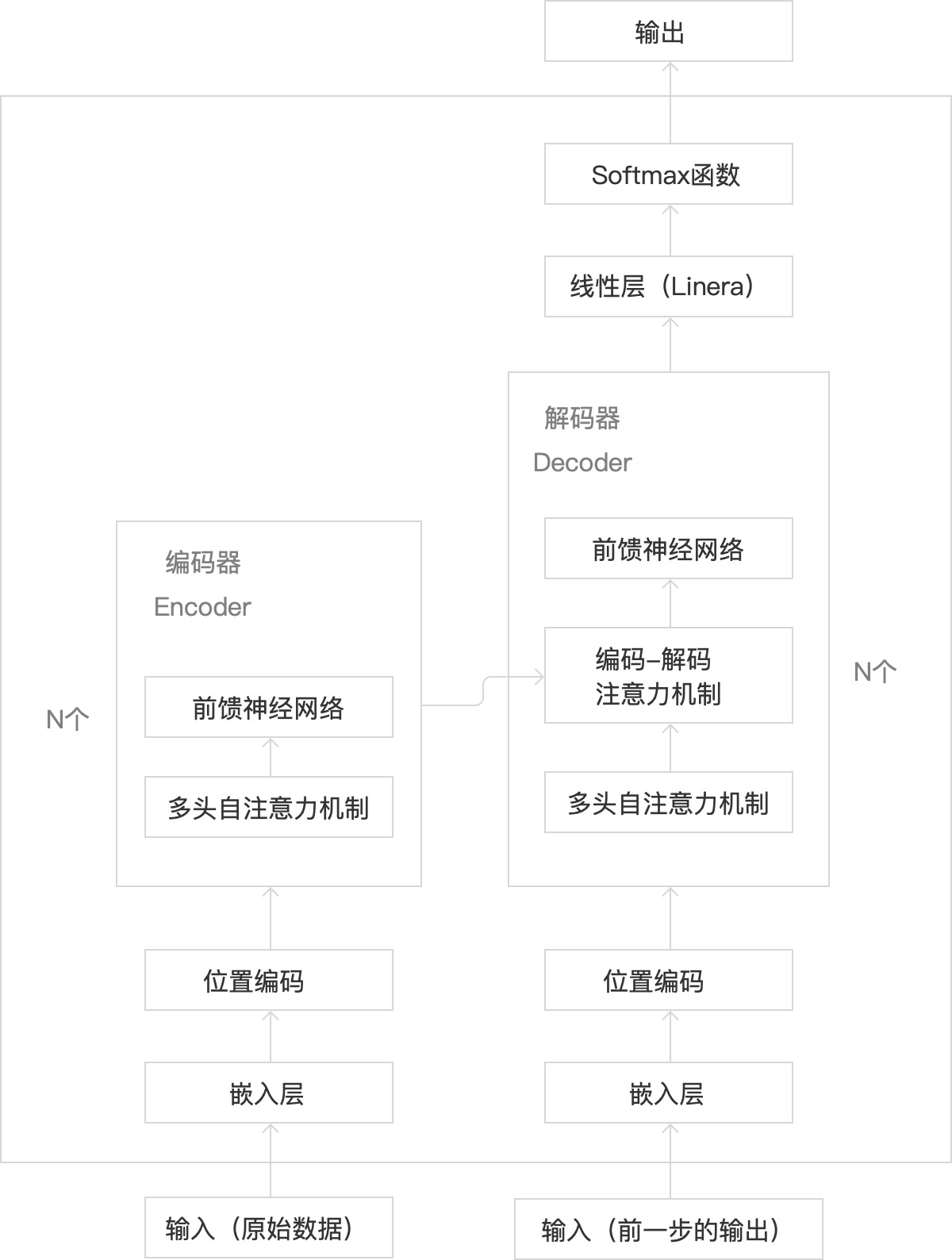
前馈神经网络:增强模型表达能力
·前馈神经网络:增强模型表达能力
4.Transformer与其他神经网络模型的对比
1)Transformer:基于自注意力机制的模型
能够高效处理序列数据
优点:
i.并行处理能力强:可并行处理整个序列,显著提高计算效率
ii.捕捉长距离依赖关系:能直接访问序列中的任意位置,有效捕捉长距离(上下文)依赖关系
iii.通用性强:能处理复杂任务,不仅适用于自然语言领域,还适用于图像处理等其他领域的序列建模任务
缺点:
i.资源消耗大:对于长序列处理时,计算和内存资源需求较高
ii.训练数据量要求高:通常需要大量的训练数据来获得良好的性能,特别是在处理复杂任务时
2)CNNs:卷积神经网络
主要适用于图像识别任务,提取图片的空间特征(图片中各部分之间的空间布局和相对位置,如连接、包含等关系)
优点:
i.空间特征提取能力强:无论图像如何移动,都能提取到相同的特征;
ii.参数共享和局部链接:减少模型参数数量,降低计算成本;
缺点:
i.无法处理序列数据:不适合捕捉长序列内的依赖关系;
ii.平移不变性:可能导致某些任务表现不佳
3)RNNs:循环神经网络
主要用于处理序列数据,能够捕捉数据中的时间依赖关系,适合处理如时间序列数据(如近3个月的股票价格数据、近一周的气温数据);
优点:
i.处理序列数据:擅长处理具有时间关系的序列数据,如文本、语音
ii.参数共享:在时间步上参数共享,减少了模型的参数数量
iii.短期记忆:能够记住短句子中前面的信息,理解上下文依赖关系
缺点:
i.长依赖问题:难以捕捉到远距离的时间依赖关系,如长句子中距离远的词,依赖关系无法捕捉;
ii.计算效率低:难以并行计算,导致训练速度较慢;
4)LSTM:是RNN的一种变体,长短期记忆网络
适合处理时间相关性较强的短序列数据;
优点:
i.处理长期依赖:有效处理序列处理中的长期依赖关系
ii.梯度问题:相比RNN,LSTM更好的解决了梯度消失/梯度爆炸的问题
缺点:
i.训练时间长:计算复杂度高,且难以并行
ii.资源消耗大:随着序列长度的增加,训练难度与资源消耗也会增加
5.应用现状
在Transformer原始架构的基础上后续出现了变种:
主要分为3类:
1)仅编码器:如 Bert,适用于理解语言的任务,如掩码语言建模(让模型猜被遮住的词是什么)、情感分析(让模型猜文本情感是积极还是消极)等
2)仅解码器:如GPT系列(ChatGPT),擅长通过预测下一个词,来实现文本生成等
3)编码器+解码器:如T5、BART,适用于把一个序列转换成另一个序列的任务,如翻译、 总结等
语言大模型训练过程
接下来我们用ChatGPT举例,来了解一下大模型的训练过程如下:

1.其中“无监督预训练”阶段是整个模型训练的核心部分,基于Transformer架构的GPT模型,作为预训练模型。这一步骤是整个训练过程中,最耗时、耗力、烧钱的环节。
过程是通过对海量数据的学习,自行学习人类语言的语法、语意,了解表达结构和模式。
这步训练后,会得到一个基座模型,可进行文本生成,模仿上文生成更多类似的内容,并不回答你的问题,如发问“法国首都是哪里?”,他会回复“英国的首都是哪里?”。
2.为解决上一问题,会进行下一步“监督微调”。
过程是从人类撰写高质量的对话数据学习,相当于既给了模型问题,又给了模型我们人类中意的答案,对基座模型进行微调,过程不需要从海量的数据中学习了。
这步训练后,模型更加擅长对问题做出回答了,这步得到的模型一般称为SFT模型。
3.为了让模型的实力继续被提升,再进行下一步“强化学习”。
过程涉及到两部分内容:
1)训练奖励模型:使用上一步得到的SFT模型对问题生成多个对应答案,人类标记员对答案进行质量排序,基于这些数据训练出一个能对答案进行预测评分的奖励模型;
2)强化学习训练:接下来让第二步得到的基座模型(SFT)对问题生成回答,通过奖励模型给回答评分,利用评分作为反馈,进行强化学习训练。
这步训练后,模型回答的质量会进一步提升。
以上就是对AI领域部分知识的分享,希望可以帮到大家。
最后分享一个我在学习过程中脑子里冒出的奇怪问题:哈哈

本文由 @不知名产品露 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


