
 起点课堂会员权益
起点课堂会员权益「小模型」有更多机会点
在人工智能领域,大模型因其强大的能力和广泛的应用前景备受关注。然而,小模型同样蕴藏着巨大的潜力和机会。本文将从“压缩即智能”的角度出发,探讨小模型在特定领域和垂直行业中的独特优势。

为什么要研究语言模型。
原因主要有两点:
一,乔姆斯基认为,语言是思考的工具。要理解人类的心智,必须研究语言,语言和心智是密切相关,我们的主要观点是“压缩论”,人工智能可以表现为一种压缩的形式。
二,语言非常重要。没有语言,人类的高级思考就无法进行。因此,语言不仅是知识的载体,还是一种高度抽象的符号系统。
那么,为什么选择语言模型进行研究,而不是研究图像、声音或其他类型的数据呢?很简单,语言文本的数据压缩更方便,也更省钱。
我把听课的内容总结了一下,仔细看后发现,历史发展脉络非常有趣,总结起来就是四个字:压缩即智能。
01
为什么这么说呢?
14世纪,英格兰有个逻辑学家,名叫威廉·奥卡姆(约1285年至1349年),他提出了一个很有名的原则,叫做「奥卡姆剃刀」。
这个原则的意思是:如果可以用简单的规则来解释一件事情,那么这个简单的解释通常是正确的。
听起来可能有点抽象,但很容易懂。中文里有句老话:“如无必要,勿增实体”,讲的就是这个道理。
举个例子:
在数学里,如果我给你一个数列:1, 2, 3, 5, 8,让你猜下一个数字,你可能会想到是13。因为这个数列是斐波那契数列,每个数字都是前两个数字的和。
这个解释很简单,也很合理。
那为什么我们觉得13是对的,而不是随便猜一个数呢?
我随便说一个数,然后编一个很复杂的理由来解释它,虽然我也可以写一个程序来证明这个数是对的,但这会很复杂。
奥卡姆剃刀告诉我们的就是,如果一个现象可以用简单的规则来解释,那它通常就是对的;因此,最初的研究者普遍遵循奥卡姆剃刀的原则。
后来,有个人提出了不同的看法。
这个人叫雷·所罗门诺夫(1926-2009)他曾经参加过达特茅斯会议,也是会议的发起者之一,他的研究相对冷门,他觉得,按照奥卡姆剃刀的原理,并不是所有数字都有可能成为正确答案。
通常情况下,如果一个规律更容易描述,那它就更可能是正确的。因为我们的世界可能本质上是简单的。宇宙的底层规则,很可能是一个简单的原理,而不是复杂的。
因此,生活中的大多数现象都可以通过规律来预测。但具体怎么做呢?
我们可以把这些规律写成图灵机(模型、公式)的形式,然后同时模拟所有可能的图灵机;简单的图灵机,我们给它更多时间去运行;复杂的,就给它更少时间。
通过这种方法,我们可以构建一个“普世分布”,这意味着,如果你给我一个数列,让我预测下一个数字,我虽然不能确定具体是哪个数,但我可以给出一个概率。
这个“普世分布”可以说是对任何序列推理问题的最佳预测;不过,虽然这个东西客观存在,也能被理解,但它实际上是不可计算的。因此,它更多是一种哲学上的思考,而非实际应用的工具。
后来,有一个人叫柯尔莫果洛夫(1903-1987),他说:
所罗门诺夫说得对,但我们怎么判断一个图灵机或者一个模型是简单的还是复杂的呢?不能只靠概率分布吧。
于是,他提出了柯氏复杂度的公式概念。简单来说,如果一个序列是正确的,那么可以用一个图灵机来描述它。图灵机越简单,这个序列的复杂度就越低。
柯氏复杂度的公式是这样的:
K(x) = min{|p| : T(p) = x}
这个公式里的 KK是用来预测某个东西 xx 的图灵机 CC 的长度。如果 CC 运行后结果是 xx,那么 CC 的长度越短,复杂度 KK 就越低。
举个例子:
设你有一个数列:2, 4, 6, 8, 10。你发现这个数列的规律是“每次加2”。于是,你可以用一句话来描述它:“从2开始,每次加2。”这句话很短,所以这个数列的“复杂度”很低。
再看另一个数列:3, 1, 4, 1, 5。这个数列看起来没有规律,你只能用笨办法描述它:“第一个数是3,第二个是1,第三个是4,第四个是1,第五个是5。”这句话很长,这个数列的“复杂度”很高。
需要注意的是,柯氏复杂度是一个理论上的概念,虽然可以定义,但在实际中无法精确计算。
02
后来,有个人对柯尔莫果洛夫的理论提出了质疑,他叫尤尔根·施密德胡伯,人们称他为长短期记忆(LSTM)之父。
他说:
柯尔莫果洛夫的理论并不完全正确。简单性不仅仅是用一个简单的图灵机生成序列,如果这个图灵机需要运行100年才能生成结果,那这还能算是成功的描述吗?
简单性应该包括图灵机的运行速度。
也就是说,生成序列所需的计算时间越短,复杂度就越低。”这就是他提出的“速度优先”原则。因此,计算的速度优先是很重要的。
为什么要速度优先呢?
还有一点,因为以前的研究是基于符号主义的。什么是符号主义(Symbolic AI 或 Logical AI)?简单来说,用符号和规则来表示知识,然后通过逻辑推理来解决问题。
举个例子,如果我们知道“鸟会飞”和“企鹅是鸟”,符号主义会推理出“企鹅会飞”。但实际上,企鹅是不会飞的。这就出问题了。
这里有两个主要困难:
一,柯尔莫果洛夫复杂度的限制。复杂的系统可以生成简单的东西,但简单的系统无法生成复杂的东西。这是一个基本的不等式。比如,一个复杂的程序可以生成简单的数列,但一个简单的程序无法生成复杂的数列。
第二,人类大脑是一个黑盒,要模拟人类大脑的功能,需要多高的复杂度呢?我们猜它应该是很高的复杂度,因为人类研究了这么多年,还没完全搞明白。这说明大脑的复杂度非常高,可能是一串很大的数字。
如果我们试图用符号主义的方法,通过编写规则或程序来模拟人类智能,这几乎是不可能的。
举个例子:
我们从互联网上抓取大量数据,把世界上所有网页的文字都抓下来。这些数据有多大呢?可能是几百PB(一种很大的数据单位)。它的复杂度非常高。
虽然这些文字是人类写的,可能有一定的规律,可以压缩得小一些,但它仍然有很大的复杂度。这个复杂度,甚至可能超过人脑的复杂度。
如果我们把这些数据加上某种模型,就有可能达到和人脑类似的智能功能,这样,就解决了符号主义的一个根本缺陷。因此,转向数据驱动的方法是必然的。如果没有数据,你根本不知道复杂度从哪里来。
既然复杂度已经很高了,我们还希望它是可解释的,这就比较难了。
你只能在某些特定方面解释它,但无法完全搞清楚它的原理。就像研究人脑,你可以研究一些局部的机制,但要想完全弄清楚整体原理,几乎是不可能的。因为人类只能理解简单的东西。
03
我们今天的大语言模型是什么呢?它就是用很高复杂度的数据,通过算法压缩,得到一个相对较小但仍然复杂的模型。这个模型可以比较准确地预测语言。
有了这个模型,我们只需要补充一点点信息,就能恢复原始数据。所以,大语言模型其实是一个数据压缩的过程,而模型本身是数据压缩的结果。
直到2019年3月,强化学习领域的重要人物,加拿大阿尔伯塔大学教授的Rich Sutton写了一篇文章,叫做《The Bitter Lesson》,中文翻译成“苦涩的教训”。
这篇文章总结了人工智能领域过去70年的发展历程。很多公司,比如OpenAI,都遵循这篇文章里的原理,Rich Sutton讲了一个重要的观点:
从1950年代开始,在人工智能的研究中,研究者们经常觉得自己很聪明,发现了一些巧妙的方法,然后把这些方法设计到智能算法里,短期内,这种做法确实有用,能带来一些提升,还能让人感到自豪,觉得自己特别厉害。
但长期来看,这种做法是行不通的,因为再聪明的人,也不可能一直聪明下去。如果只做这种研究,最终反而会阻碍进步。
真正取得巨大突破的,往往不是那些精巧的设计,而是在计算和学习上投入更多资源。这种方法虽然看起来笨,却能带来革命性的提升。
历史上,每次人工智能的重大进步,都伴随着这种“苦涩的教训”。但人们往往不喜欢吸取这种教训,因为它有点反人性。
我们更喜欢赞美人类的智慧,设计一些巧妙的算法,觉得这样才高级。而用大量数据和算力去训练模型,虽然能成功,却让人觉得不够“聪明”。
这种“大力出奇迹”的成功,常常被人看不起。但事实一次又一次证明,这种看似笨的方法,才是真正有效的;这也解释了为什么我们要做大模型——因为只有通过大规模的计算和学习,才能实现真正的突破。
因此,开发大模型并非为了展示技术实力,而是因为它确实能带来显著的成果,这就是为什么我们要在基础设施上投入更多资源,去支持这些大模型的训练和发展。
04
所以,压缩即智能。通过压缩数据,模型能够提取出更高层次的特征和规律,从而表现出智能行为。那么,这个“压缩即智能”的说法是谁提出的呢?
从2006年开始,德国人工智能研究员Hutter Prize每年都会举办一个比赛。这个项目叫,Hutter Prize for Lossless Compression of Human Knowledge(简称 Hutter 奖)
比赛的目标是:把1GB的维基百科数据压缩到110兆。
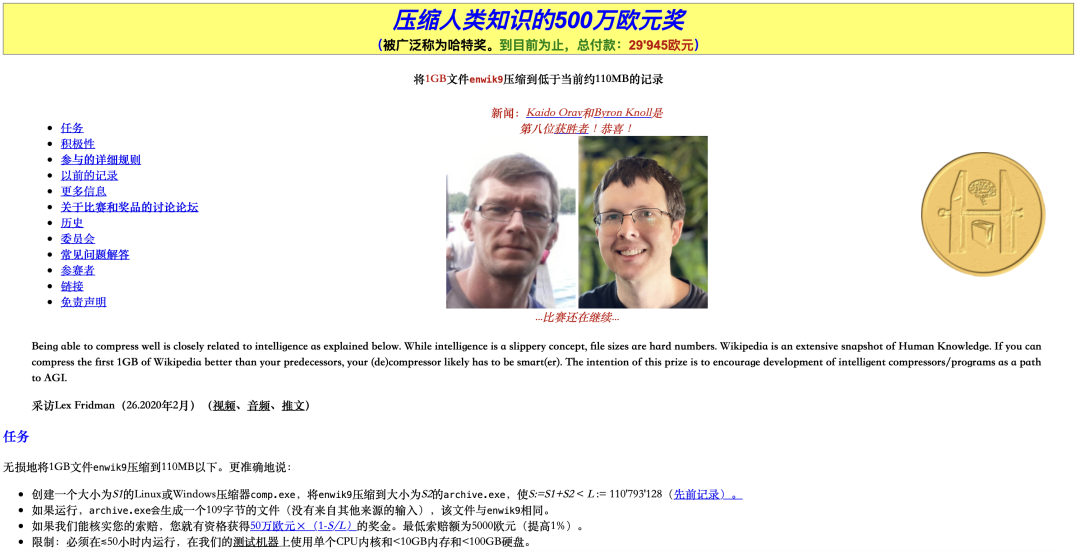
截图来源:hutter奖官网,地址:http://prize.hutter1.net
如果你能压缩得比这个更小,就说明你的压缩方法更聪明,这个比赛的总奖金是50万美元,目前已经支付了29万多美元。
不过,放在七八年前,这个比赛可能还挺有意义的。但今天再看,1GB的数据量显得有点小了,毕竟,现在的模型动不动就处理几百GB甚至更多的数据。
如果你有兴趣,可以去试试这个比赛,里面还有很多符号主义的方法,大模型的思路还没完全用上。
那么,怎么提高压缩的效果呢?主要有几条路:
一,更聪明的算法;以前用n-gram这种统计方法,效率很低。虽然数据量大,但模型效果一般。现在有了更聪明的算法,比如深度学习,能更高效地利用数据,训练出更大的模型,而且不会过拟合。
二,更多的数据;数据越多,模型效果越好。但问题是,互联网上的数据已经抓得差不多了,还能从哪里找更多数据呢?
两个维度,用更小的模型垂直到行业的本地知识(local knowledge)中让所有人用起来,然后,小模型投喂给大模型,最终加上训练时间。
尤尔根·施密德胡伯(LSTM之父)提出,速度也很关键。如果投入更多时间训练,模型的效果可能会更好。这也是OpenAI等公司走的路线。
所以,如果你相信“压缩即智能”的观点,那么在同样的数据量下,小模型如果能达到和大模型一样的效果,那小模型显然更聪明。
说到这,不妨思考下:为什么今天还要研究大模型?
因为根据柯尔莫果洛夫复杂度,只有足够大的模型,才有可能接近通用人工智能的目标,虽然小模型的研究也有意义,但最终要实现通用人工智能,大模型是不可避免的。
因此,一个结论是:如果你的目标是AGI,那做大无疑是最佳选择,你的目标是细分垂直,小模型最划算。理解这一点,也就理解了,大厂为什么追求大模型,但往往,小模型,有更多机会点。
本文由人人都是产品经理作者【王智远】,微信公众号:【王智远】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


