
 起点课堂会员权益
起点课堂会员权益万字长文:DeepSeek 647天铸就的登神长阶
这篇文章深入剖析了DeepSeek在大语言模型(LLM)领域的发展历程,详细回顾了其从2023年4月踏上AGI征程到2024年1月发布震惊世界的R1模型的647天。文章以时间为线索,梳理了DeepSeek在技术创新、模型迭代与公司文化等方面的诸多细节,展现了其如何通过一系列坚实的技术突破和战略决策逐步构建起强大的技术壁垒,并最终实现登顶。

过完元宵节从老家回到深圳,我用三天时间,读完了Deepseek在LLM领域的13篇论文,从里面发现了一些细节,分享给你们。
首先,震惊世界的R1,不是一日铸就的,里面用到了很多过去项目中独创的技术突破。
其中一些突破在逐步验证后,反复迭代升级,最终成为了R1的牢固基石,例如他们当前所用的MoE框架,经历了四次升级。又比如GRPO,最开始其实是在一个数学模型,DeepSeek-Math-7B上首次提出的。
当然也有一些技术选择或技术突破,他们在后续工作应用时失败了,或者放弃了。例如令牌丢弃策略,例如他们提出的RMaxTS(蒙特卡洛树变体)。
所有13篇论文组成了我眼中的“登神长阶”,这里面每个台阶都是极其坚固和富有创意的。我相信这条登神之路,远远未到终点。
其次,从论文的非技术部分我还发现了一些有趣的地方。可以用来佐证外界所传言的DeepSeek独特公司文化。
最后,关于内容的专业性和友好性问题。我会尽力做不失精确的科普。但由于以下限制:
1)部分技术内容需要大量前置知识,展开说明篇幅会爆炸;
2)我自身不可避免带有知识诅咒;
3)我个人的技术理解偏差。所以只能说尽可能保证精确和科普友好。
如果有看不懂的概念,建议使用这个prompt问问DeepSeek-R1:

接下来我的内容将按时间线组织,以论文为核心主线,但也会少量穿插一些重要事件(特别是开头)。
论文中出现的技术创新点,我会尽可能用通俗科普的方式解释清楚。但我不希望这篇内容过长,所以如果需要查看完整的亮点和科普内容,请移步这13篇论文的翻译&注释文档。
01 DeepSeek的647天
23年4月14日,开始
DeepSeek前身幻方量化在公众号发布文章幻方新征程,宣布将以研究组织的形式投入AGI征程
文章引文——“务必要疯狂地拥抱雄心,同时要疯狂地真诚”
文章阅读量8387,剔除其过去旧用户日均的3000阅读,可以说除了AI核心圈的人士,几乎无人知晓。
这一天离ChatGPT发布135天,离DeepSeek-R1发布647天。
23年5月24日,官宣
暗涌采访了DeepSeek梁文峰,在公众号发布《疯狂的幻方:一家隐形AI巨头的大模型之路》
网络上关于这篇文章的解读非常多,我就不重复阐述了,感兴趣的可以看看原文
大家可以分享一下最喜欢哪句话。我喜欢的可能和多数人不太一样,是下面这句
“我们希望更多人,哪怕一个小 app都可以低成本去用上大模型,而不是技术只掌握在一部分人和公司手中,形成垄断”
这篇文章标志着DeepSeek的筹备接近完成,梁文峰开始认真招人了。
相近的时间线上,ChatGPT IOS版在5月18日发布,迅速登上TOP1。
这一天距离R1发布607天。
23年7月17日,公司成立
DeepSeek注册成立,全称杭州深度求索人工智能基础技术研究有限公司。
很多人可能是第一次看到这个公司的全称。是的,DeepSeek是DeepSeek,AI六小龙是AI六小龙,他们是不一样的公司。
这一天距离R1发布553天。
23年10月25日,第一篇论文
DeepSeek发布论文:DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior,支持从图像生成3D模型。这篇论文中的7位作者后来有6位出现在了DeepSeek Visual系列模型中。
这也是唯一我没有深入阅读的DeepSeek论文,因为看起来他只和图像有关,与LLM没有太大关系。我也不清楚为什么这个方向是DeepSeek的第一篇论文。
这也是DeepSeek在X上注册后发布的第一条公告信息Introducing #DreamCraft3D
这一天距离R1发布453天。
但接下来,真正的狂飙开始了!
你将看到DeepSeek是如何一步步打磨他们的技术栈,并创造出R1这样的惊艳产品。
下面是我梳理思路用的思维导图,每个灰色的小块是一篇论文,绿色块则是独创的技术点,虚线是技术点在不同论文(模型)之间的引用。
当然,别害怕,这个图只是让你建立一个模糊概念,接下来我们还是按时间线讲。

23年11月2日,狂飙开始:Coder-V1
DeepSeek公众号注册,发布首篇文章:可能是最强的开源代码大模型!深度求索发布 DeepSeek Coder,阅读量4.3W
24年1月25日,发布论文:DeepSeek-Coder: When the Large Language Model Meets Programming — The Rise of Code Intelligence
这篇论文尝试在储存库级别组织预训练数据。即我不是简单让大模型学习单一的代码文件,而是要让大模型认识到代码之间的组织关系。例如一个代码项目中,某个代码文件是需要调用另一个代码文件的,又或者Readme、接口文档这类描述整体逻辑的文档。
补充技术原创判定规则:我并非专业的算法人员,所以我很难判断某个方法是否DeepSeek首创。我的判断标准为——如DeepSeek在论文中附加了其他论文引用,则为非原创;如DeepSeek大幅描述,且无相关引用,则为原创。
补充时间线判定规则:当DeepSeek公开发布一个项目,然后公开论文,以项目为时间线,因为论文的发布可能具有滞后性。但若无相关项目,则以论文为第一时间线判定节点。
这一天距离R1发布445天。
23年11月29日,DeepSeek-67B(V1)
DeepSeek发布第一个通用大模型 DeepSeek-67B。
24年1月5日,7天后,DeepSeek发布对应论文,也是LLM系列第一篇:DeepSeek LLM Scaling Open-Source Language Models with Longtermism。
这篇论文中,有如下亮点:
① 使用GQA(Grouped-Query Attention)取代传统的MHA(Multi-Head Attention)。注意力机制是Transferfomer中一个重要模块,很难快速解释清楚。如果不懂的朋友,你搞清楚一点即可:GQA相对MHA,在成本上会更低,但是效果会下降——为此他们增加了模型深度,以缓解模型效果的下降,但效果还是不如MHA。
② 他们使用了多步学习率调度器来取代余弦学习率调度器。学习率可以近似理解为模型以多快的速度学习数据,通常在刚开始训练的时候可以让他猛猛学,随着时间推移就必须逐步降低。他们设定的多步学习率是前80%进程中固定最大值,80%~90%为31.6%,90%~100%为10%。这样做的好处是,如果你想搞N个模型做实验,那么前80%是可以复用的,你只需要针对后20%进行实验,从而把每次实验成本从100%压低到20%。
③ 在GQA和多步学习率调度器这种方案组合下,他们的实验成本非常低。因此他们做了大量实验来验证一个事情:到底Scaling Law的公式到底是什么?(Scaling laws:模型的性能与计算量、参数量、数据规模存在关联,越大越好)
④ 首先他们重新定义了C=6ND公式,这是过去流传甚广的计算资源计算公式。N是参数规模,D是数据规模,C是计算资源。但他们发现这个公式是不精确的,在小参数模型的情况下,偏差率最高能达到50%。于是他们用M(FLOPs/token) 来取代6N,以实现更精确的计算资源估算。
⑤ 然后他们做了一堆实验,推导出超参数的Scaling laws公式,当计算资源C确定时,可以推导出对应Batch Size和学习率。附图如下:
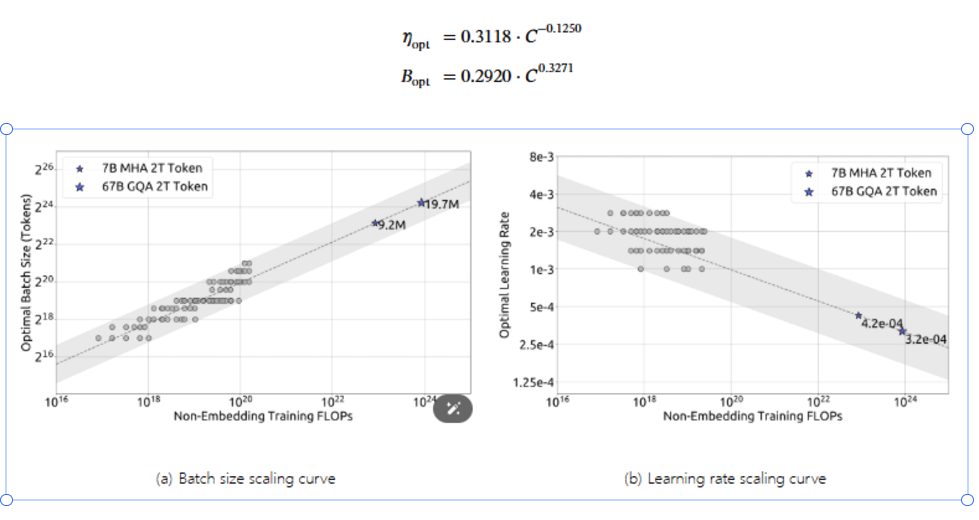
⑥ 他们还做了一堆实验,推导出最佳的模型和数据分配策略,即计算资源确定,模型大小和数据大小的关系。
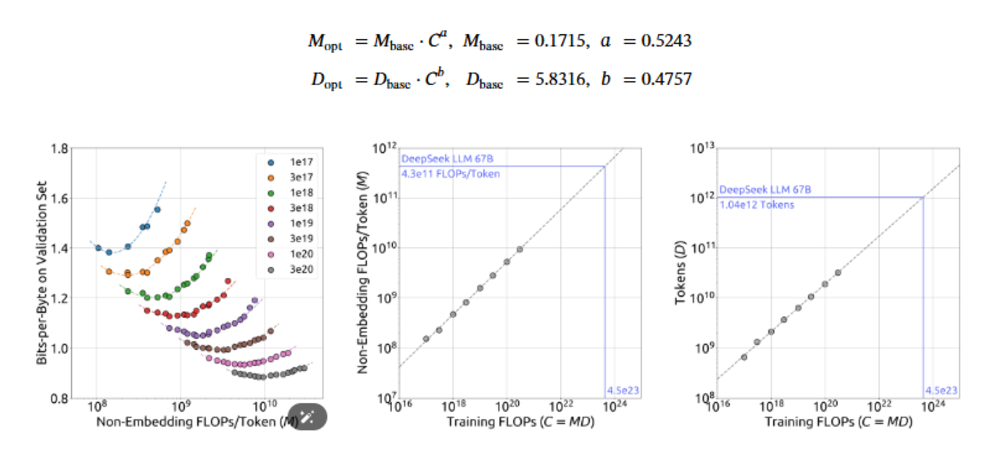
回到论文的标题:DeepSeek LLM Scaling Open-Source Language Models with Longtermism。基于长期主义的开源大语言模型。
当我全部读完整篇内容的时候,我才知道DeepSeek眼中的长期主义是什么——“这个事情我可能要做很久,不着急,我把我的基础打好,把最简洁,最基础,最底层的公式、定理推导好,验证好,一步步做就是了”。
事实上,在后续的12篇论文里他们也是这么做的,一点点用实验和实践,趟出了通向AGI的道路。
这一天离R1发布418天。
24年1月11日,MoE系列第一篇
DeepSeek发布了第2篇论文:DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models。这也是他们关于MoE架构的第一篇论文。
这篇论文的亮点是:
① 精细化专家分割:把专家的数量从传统如GShard等MoE方法再次进一步细分。专家越细分,每个专家的专业化程度就会越高,模型能力越强。
② 共享专家:有一些知识可能是高频出现的,为了避免专业专家也学到这些知识,他们特地隔离出来一些专家作为共享专家。
通俗来讲,可以理解共享专家就是医院前台,全能但无用,精细化分割后的专家就是专科医生,专业但垂直。
另外为了避免有朋友被我误导,从而以为MoE里的专家就是数学专家、代码专家。事实上并非如此,LLM里的专家,更多是Token层面的,他们的专业知识是人类难以理解的。
例如下图,每个颜色就是一个专家。图片来自论文Mixtral of Experts

另外MoE架构允许模型仅使用部分参数就能激活完整能力——例如R1模型,他的参数是671B,但每次推理的时候只需要激活37B的参数,仅为5.5%的参数规模,这就让训练和推理的成本骤降。
② 但是MoE会遇到两个问题:不同的专家之间训练可能会失衡,就是有的专家老是没被训练到,最后变成弱智。如果专家在不同设备(GPU)上这种情况就更严重了。甚至保证为了训练充分,计算过程会疯狂跨设备通信,拼命找专家塞知识,哪怕送知识的路都塞死了(通信问题)也不停下,这就会导致性能浪费,成本升高。
为此他们设置了专家因子、设备因子来避免这个情况的发生。
这篇论文后来被用在DeepSeek-V2和DeepSeek-Coder-V2两个模型上,并有了一些改进,后面会说到。
这一天离R1发布375天。
24年2月5日,进入数学领域
Deep发布了第4篇论文:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models,在这篇论文中首次出现了GRPO(Group Relative Policy Optimization,组相对策略优化)用以替代PPO。如果你不知道PPO,那么换一个名字——OpenAI的RLHF就是PPO方法。
这篇论文有如下亮点:
① 提出了GRPO。传统的强化学习(PPO),假设你要训练一个67B的模型,需要在训练中维护3~4个67B的模型,分别是:1) 被训练的模型;2)一个不变的模型,用来与训练模型做参考,避免训歪了;3)奖励模型,用以对被训练模型的输出打分,用以训练。这个部分可以用规则,也可以用模型;4)价值模型,用以评估被训练模型的结果,给出价值判断。
其中价值模型的训练非常困难和麻烦,并且他占用了大量的内存和计算负担,所以DeepSeek干脆把他干掉了。DeepSeek认为,价值模型本质上就是给模型训练提供一个参考基线而已,那么我让模型回答很多次,把多个回答的平均值当成基线也可以啊。在这里GRPO的逻辑就是“鼓励与平均基线不同,格外突出”的回答。
如果你觉得上面的东西很难理解,你就记住:GRPO让模型训练的困难下降,并且成本降低。
注意,从GQA、MoE、到现在的GRPO,这已经是DeepSeek在降低成本上提出的第三项尝试,这种尝试后面会越来越多
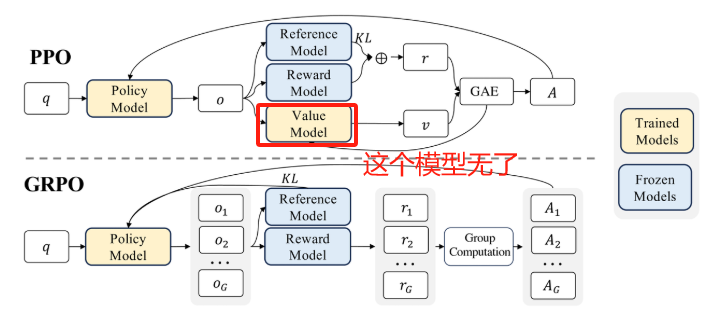
② 此外,他们发现在强化学习的过程中,不断实时生成的数据比固定不变的数据训练效果更好(在线采样VS离线采样),为此,后来他们在DeepSeek-V2中,实现了在线强化学习框架。
值得一提的是,这个Math模型非常厉害,以至于全球第一届AI奥数竞赛,TOP4团队全用的这个作为基础模型。
这一天离R1发布350天。
24年2月8日,无人问津的新年祝福
DeepSeek在公众号上基于DeepSeek-67B生成了新春祝福:辞旧迎新,扬帆起航|DeepSeek送来AI新年贺词,阅读量仅有5K。
有趣的是,发布的IP来自四川,看来DeepSeek的运营同学可能来自四川。
这一天离R1发布347天。
24年3月8日,视觉模型第一篇
DeepSeek发布了第5篇论文:DeepSeek-VL: Towards Real-World Vision-Language Understanding,这是他们视觉模型系列的第一个版本。
DeepSeek的视觉模型系列论文共两篇,但和V2、V3、R1至少在论文技术点上看不到太多的关联性。
为了减少阅读这篇内容的负担,在这里不对这篇论文进行亮点陈列和科普,感兴趣的朋友可以在文末找到我全部13篇论文的中-英双语+批注解释版本,那里会更详细。
24年5月6日,V2发布,价格屠夫
DeepSeek发布了DeepSeek-V2-236B(激活参数21B),性能上超过所有开源模型,并极度逼近闭源模型如GPT-4-1106-preview
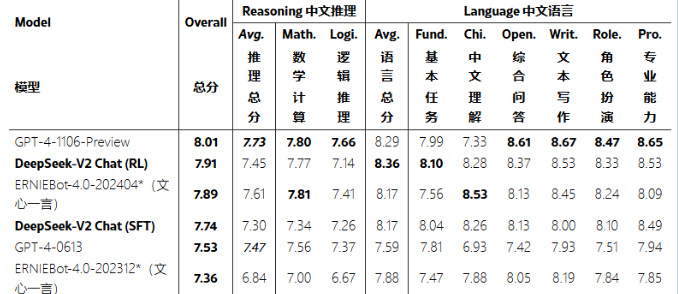
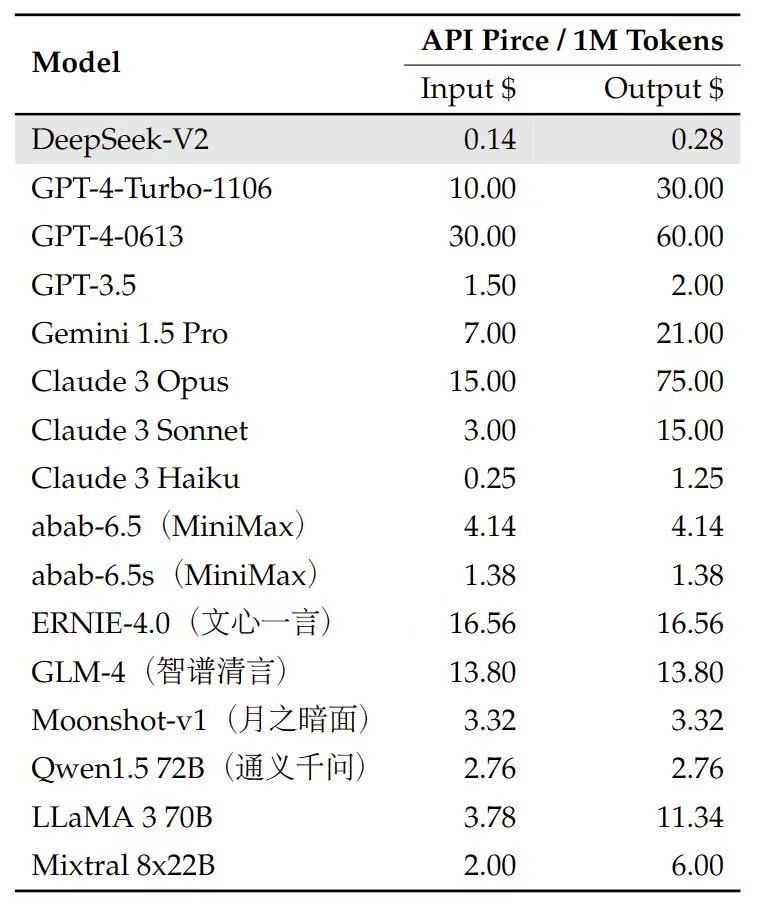
而在价格上,更是让西方惊叹,经典的中式价格屠夫又来了。
随后,在5月7日,他们发布了第6篇论文:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model,这篇论文中的亮点我列出来的有14个,全部写出来各位脑浆可能都要沸腾了,我只挑一些重要、有代表性的说一下。
本篇论文亮点如下:
① 提出了MLA(Multi-head Latent Attention)取代DeepSeek-67B中使用的GQA。而GQA一开始就是处于降低成本目的取代的传统的MHA(Multi-head Attention)。注意到没有,MLA比MHA的差别只在于多了一个latent。他的区别就是把KV缓存,进行了低秩压缩成为潜向量(latent空间)。你可能觉得好难理解,没关系,看下面这张图:
左侧是原本的KV缓存,右侧是低秩压缩后的KV缓存,数据变得非常小,但是精髓的语义全部保留。

在完成压缩后,MLA的成本和原本的GQA相当。但GQA原本就是成本低,性能差,而MLA成本和GQA一样,性能却比GQA乃至传统的MHA更强!
② 相较1月11日发布的MoE论文,他们做了一项改进:在Token选择MoE 专家的时候,先计算一下这个Token对每个专家的亲和力,然后只选择其中的部分专家。就是说你去医院,要会诊的时候,传统MOE给你安排8个专家,现在通过计算你的病情,只找3个专家就行了——这又进一步降低了成本。
③ 然后他们在MoE上还做了一个改进。前面不是提到怕专家训练失衡,导致有的专家变得弱智吗?为此加了专家因子和设备因子做平衡,这次他们多加了一个通信因子——就是避免因为设备间通信的原因,导致专家训练不够或成本上升。
④ 就算他们加了这么多控制因素,专家毕竟在多个设备上,还是很容易出问题。他们又设置了一个Token丢弃策略,根据Token和专家的亲和分来判断:如果设备爆了,那么亲和分低的Token就不训练了丢掉。——显然,这是为成本而做出的性能妥协,这肯定会导致模型能力下降。怎么办呢?放心,他们在3个月后近乎完全解决了这个问题。
⑤ 前面Math那篇论文提到过,他们确认了实时获得RL数据比离线的效果更好,为此花费大量精力做了一个RL框架(原话:we invest tremendous efforts哈哈哈,是多痛苦才在论文里这样写)
这一天离R1发布259天。
此外,补充一点,5月15日,DeepSeek通过大模型备案,全面对国内开放。
24年5月23日,进入定理证明领域
DeepSeek发布第7篇论文:DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data,这是关于定理证明(Theorem Proving)的。
Prover系列是我看得最头痛的论文,因为他解决的问题是“数学定理证明”,DeepSeek的工作暂时集中在高中、大学范畴,还不涉及特别高深的数学难题——但他们的大学是清北,我的大学是二本,我们眼中的大学数学可能不是一个东西……
为方便大家理解,要先对“数学定理证明”做一个科普
如下图左侧,这是我们高中时需要进行的证明题,大家可能还有一些印象。要让计算机计算1+1=?是简单的,这只是一个计算题。但是要让计算机完成加法交换律,证明A+B=B+A,却需要一套专门提供给计算机使用的语言。这就是“形式数学语言”(如下图右侧)。

数学定理证明领域是大模型推理难度非常高的领域,在这个方向的积累会极大程度有助于大模型的推理能力提升。事实上,我也确实看到很多Prover系列的技术思路被复用在V3/R1上。
本文亮点如下:
① 通过LLM将自然语言表达的数学问题,转为计算机可识别的“形式数学语言”
② 为加快训练效率,让大模型同时进行定理的证明和反证,这样有一条路走通,另一条路就不用走了
③ 通过Self-instruct的方式,用自己合成的数据来训练自己。——这个方法后来用在了R1当中
④ 通过高级模型蒸馏一些高质量的数据,作为冷启动数据。——这个方法后来用在了R1当中
这一天离R1发布242天。
24年6月17日,Coder-V2,不幸撞车
DeepSeek发布DeepSeek-Coder-V2-236B(激活参数21B),在DeepSeek-V2-Base的基础上训练而成。论文:DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
本文亮点:
① 是首个开源的100B以上的代码模型
② 之前建立的代码/数学数据收集管道,由于V2模型进化,导致精度变高,数据的质量更高了——现在V3版本出现了,数据精度可能会进一步提升,值得期待。
模型在性能上超越了所有开源模型,并极度逼近GPT-4——而且成本依旧是爆炸性的低。
非常可惜的是,仅仅过了4天,6月21日,Claude 3.5 Sonet发布,代码领域的神登基了——直到今天,它仍未陨落。客观地说,V3和R1在jason输出,代码格式等方面仍然稍弱Claude3.5一筹。
这一天离R1发布217天。
24年8月15日,Prover1.5
DeepSeek发布Prover系列第二个模型,DeepSeek-Prover-1.5-7B:Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search
本文亮点:
① 为定理证明引入CoT数据+lean状态数据。即整个输入包括:数学问题+自然语言描述的解题思路(CoT)+当前解题步骤中Lean的状态反馈(Lean是专用于形式化数学定理证明的工具)
② 提出RMaxTS(蒙特卡洛树搜索的一种变体)。因为整个证明过程是一步步推敲的,类似下围棋一样,一步步下,所以可以用搜索算法来判断证明的下一步。他们的核心设计在于:1)为搜索附加了一个“内在奖励”,用于鼓励模型去探索未知节点。2)随着探索推进,大部分节点都是失败结果,这会导致奖励很稀疏(大量失败,少量正确),为此他们引入DUCB(discounted upper confidence bounds),即越往后发现的正向奖励越高
这篇论文中的CoT数据的构造思路最后用在了R1模型上面。R1还尝试使用了RMaxTS,这很符合OpenAI之前论文中提及的过程奖励——即判断模型每一步的价值,而不是判断最终结果。
这一天离R1发布158天。
24年8月28日,MoE系列第二篇
DeepSeek发布MoE系列第二篇论文:Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts,在这篇论文中,他们升级了MoE负载均衡的控制方法(就是怎么让每个专家充分训练,又避免成本上升)
本文亮点:
① 回忆一下上个MoE版本可以称为“有损负载均衡控制”,他们的方法是通过专家因子,设备因子,通信因子三个超参数来控制负载均衡。但实际使用中,并不能完全解决问题,为此他们还引入了Token丢弃策略,在一些专家实在学不过来的时候,丢掉一些不适配的Token。——可以想象这种MoE方案必定是会损害性能的
② 在这个版本中,他们引入了一个模型来控制负载均衡。模型会观察每个训练批次中专家的“劳累情况”,如果某个专家太累,后续就少派学习任务,如果太闲,就多派点学习任务。
③ 实验表明,这种方法在训练成本上实现了极大的提升,同时对模型的性能(能力)也导致了轻微的提升。
这个MoE方案是当前他们最终的MoE方案了,最后用在了V3和R1中
这一天离R1发布145天。
24年12月13日,视觉模型第二篇
DeepSeek发布了视觉模型的第二篇论文:DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding,这是一个MoE架构的模型,DeepSeek-VL2-27B(激活4.1B)
同样的,由于视觉模型系列,看起来似乎未与V3、R1有太大关联,我们不在这里展开说明论文亮点。
这一天离R1发布38天。
24年12月26日,V3发布,登神在即
DeepSeek发布了DeepSeek-V3-671B(激活37B)
一天后,12月27日,发布论文DeepSeek-V3 Technical Report
本文亮点:
① 前面提到的最新MoE方案,GRPO,MLA,Prover中的CoT实践,Self-instruct全部都用上了
② 实现了MTP(Multi-Token Prediction)方法,即让模型同时预测下一个+下下一个Token。这个方法将提升模型训练的效果,同时降低训练成本和推理成本,并且他是可拆卸的。原理科普有点长,我不想再敲一遍,把注释截图过来

③ 在开放性问题上,他们使用基于模型的奖励。重点是在奖励模型的训练中,他们并不是让模型学习“如果xxx,就是好的”,而是“如果xxx,那么因为xxx,所以他是好的”——即引入了奖励的CoT思考过程。
④ 基于R1-lite的推理数据进行自身的二次微调优化,从而提升表现推理表现。需要注意的是,V3并不是使用R1数据进行微调,而是R1-lite,真正的R1实际上是在12月26日V3发布后,用了几周时间训练出来的。
⑤ 实现FP8混合精度训练。对于FP8,你可以近似把他看成小数点位,即FP8允许计算、储存8位小数点,FP32则允许32位,很显然,FP8计算性能更低,但精度也更低。——补充,以上仅为方便理解,实际上例如FP32支持的不是32位小数,而是1个符号位+8个指数位+23个小数位。
所以DeepSeek做的是FP8“混合”精度训练,而不是FP8训练,即在实践中,他们将有的操作放在FP32环境进行,有的放在FP8进行,甚至先在FP8,发现算不过来然后放过去FP32。
这里再补充一个知识,我们经常听到模型量化,或者说A模型的FP4版本,这其实就是说把模型的参数从FP8的精度降到FP4的精度。这样模型的计算成本会极度降低,从而节约成本。
⑥ 除此以外还有大量的Infra优化细节,例如通过一套Dualpipe管线,将计算和通信完全重叠,定制的PTX以自动调整通信块大小,反向传播期间重算部分工作以节约内存,利用CPU存放EMA等等
整篇论文最大的特点就是大量的Infra优化细节,再叠加前面MoE、MLA、GRPO等形成了成本的进一步骤降。
还记得前面那篇暗涌对梁文峰的采访吗,再重复一遍我最喜欢的那句话:我们希望更多人,哪怕一个小 app都可以低成本去用上大模型,而不是技术只掌握在一部分人和公司手中,形成垄断。
如果社会的未来注定走向近赛博朋克,那反抗军的火苗也未尝不能烧遍旷野。
这一天离R1发布25天,留给DeepSeeker们加班训练R1的时间不多了!
24年1月15日,席卷全球
DeepSeek APP上架,席卷全球应用商店榜单
这一天离R1发布5天
24年1月20日,登神
DeepSeek-R1发布,当时的盛况可能很多人还历历在目,这股浪潮一直席卷到今天。
2天后,1月22日,DeepSeek发布R1论文:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
附带说一句,1月23日,是英伟达股价最高点,而后在1月24日开启了暴跌之路(可能老外们花了一天读论文吧)
本文亮点:
① 前文已提过的MoE、GRPO、MLA等等不再提及和描述
② R1-Zero,完全通过强化学习来实现模型的能力挖掘。但需要澄清:R1-Zero只在推理任务领域进行了优化学习,即代码、数学等常见的推理领域,这符合DeepSeek一直以来在Math、Prover、Coder等系列的尝试,也符合他们通常先做面向推理的强化学习对齐,再做面向人类偏好的强化学习对齐习惯。
③ 完全公开了能力上匹敌OpenAI-o1级别模型的训练流程:1)先对R1-Zero的数据进行筛选&人为标注,去掉了过长、语言重复等严重的问题,获取高质量的种子数据,进行微调(来自Prover),以让模型一开始就靠谱一点;2)进行面向推理的强化学习(和R1-Zero一样),其中引入语言一致性目标;3)进行SFT,其中推理数据来自当前阶段的R1数据(但还是经过了过滤和处理),非推理数据来自V3模型的数据集,并且部分数据额外附加了CoT;4)最后再进行一次面向人类偏好的强化学习,目标为有用性(针对摘要部分内容),无害性(针对全部回答内容)
整个过程非常有意思,SFT→RL→SFT→RL,和常见的SFT→RL很不一样。
④ 使用R1的800KSFT数据对市面上的开源模型进行了SFT,结果发现性能上极度增强
⑤ 并且他们一度尝试将他们这套RL方法用在开源模型上,试图看看效果怎么样,结果发现两个有趣的现象:1)对开源模型先SFT,再RL,性能还能再强,但论文中没有提供结果,只是提了一嘴;2)对开源模型完全复用R1-Zero的模式,效果还不如就用R1的800K数据蒸馏,他们觉得这可能和基础模型的智力水平有关——让一个人自由学习VS填鸭学习,对于天才和学渣的效果是完全不一样的。
⑥ 最后他们坦诚地公开了两个失败方向:1)OpenAI提出的PRM(过程奖励)很难搞,反正他们搞不定;2)基于MCTS(蒙特卡洛树搜索)的强化学习也不现实(这个方法来自Prover1.5)
02 一些有趣的发现
到这里,我们走完了DeepSeek 在647天内所塑造的登神长阶。
其实日期后面的文字简述是我最后才补上的。在写的时候我突然想到了一个网文圈的陈年老梗:“第1000章 天下无敌”→“第1001章 天上来敌”。
到1月20日R1发布,是DeepSeek在我这篇文章中登神长阶的结束,但绝不是他们证神之路的终点,希望他们会越来越好。
然后,让我分享一些没那么有价值,但很有趣的发现。也舒缓一下大家被技术术语、概念轰炸的大脑皮层。
新年祝福,可怜的运营同学
24年2月8日,DeepSeek发布了新春祝福,阅读量5K,IP在四川,运营同学疑似回四川过年了。
25年1月27日,DeepSeek发布了新春祝福,阅读量10W,IP在北京运营同学疑似陪着整个团队一起加了个跨年班。
梁文峰在公司做啥
我整理了DeepSeek14篇论文(含一篇2D转3D的)的作者名单
除了DeepSeek-67B,V2,R1这三篇全员大集合的论文外
他只出现在两个地方:MoE论文和Coder系列论文
我不认为DeepSeek是一家需要给老板让渡署名权的公司,梁如果出现,一定是在其中有所贡献
所以梁文峰看起来比较喜欢Coder这个领域方向,我等AI编程小白有福了,就等DeepSeek搞一个碾压3.5又便宜的Coder-V3出来!
小米千万年薪挖走的罗福莉
通过作者名单检索
罗福莉出现在:MoE,Coder序列,Prover-1.5这些论文中,看起来她擅长代码、数学这些推理领域的工作
值得说明的是,尽管12月30日传出雷军挖角罗福莉的新闻,但在1月20日发布的R1论文中,仍有她的署名。
其实现在圈子里很多朋友有一种担心——木秀于林风必摧之:DeepSeek会不会像OpenAI一样,人才纷纷出走,跳槽,挖角,然后创造力逐步下降呢?
但我想,如果一个组织,可以用647天,凭借完全的创造力和热情创造这么伟大的作品。那么更重要的可能不是里面的每个个体,而是这个组织本身。
附上DeepSeek公众号的简介:“致力于探索AGI的本质,不做中庸的事,带着好奇心,用最长期的眼光去回答最大的问题”。
03 我对未来的想法
我自己会有一份完整的未来思考,不会公开,我不希望自己陷入宏观叙事的喋喋不休中。
我只在这里提出两个较为底层和坚固的想法
技术的潜力还很大
这647天里,DeepSeek做了非常多的技术创新,但受限于人力,他们仍然有很多地方没有探索到,或涉猎不深,这意味着技术仍然存在广阔的挖掘潜力和向上空间。甚至哪怕LLM真的有一天停滞了,技术力也会流向图像、视频、音频、多模态、3D等领域相对更弱关注的领域,直到填平所有洼地。
而这只是DeepSeek,还不包括如OpenAI、Claude、Google等同级别的公司,以及其余厂商、学术人员、创业者能涌现出来的智慧。
中国可能发生一些好的变化
如DeepSeek这样的团队很少,但也可能再出现第二个,第三个——尤其在硅谷更是如此,永远相信随机性。但更重要的是,中国市场在感受到这种“硬核创新”所带来的巨额回报后,一定在各个环节都产生一些正向影响。就如同黑神话对单机游戏的改变,哪吒2对电影的改变一样。——对了,请让清华大学104页DeepSeek入门PPT这种内容少一点(非常不客气的指名道姓,我不在乎,Thx)。
总结起来就两句话:看多中国,看多AI,结束。
对了,其实有个有趣的彩蛋,我没放到文章里来,各位如果像我一样从头开始看着13篇论文,不妨看看每篇论文结束部分的“Conclusion, Limitation, and Future Work”,看看DeepSeek对未来的工作规划,是否总是在逐步实现。
另外一些则藏得比较深,他们有时候会偷偷放弃过去的一些方法,不告诉任何人(指写到论文里)。
对我来说,这些内容算是这三天里为数不多的脑皮层舒缓时间。
04 最后,说明一下附属材料
DeepSeek的13 篇论文
在飞书Wiki左侧目录里可以看到,就在这篇文章的下级菜单里
这13篇论文情况如下:
① 中文-英文翻译对照,部分机翻得太离谱的我会亲自校正,但如果不影响我阅读,我就没额外处理,所以翻译质量可能不会太好。
② 另外正文中对公式的推导,由于飞书粘贴过来会变得很扁平,例如2的2次方,可能变成22,但由于大部分公式我是不关注的,所以没有全部处理。
③ 论文末尾有大量的附录,以及引用论文链接。这些内容对我来说信效比较低,所以删掉了,如果要看,可以通过文章开头的论文原始地址去看原文。
④ 比这篇文章更全面,细致的亮点总结,但由于非公开发表,所以基本上没润色过,可能会有些不通顺。
⑤ 包含我阅读时的个人注释,以红底标注,红字说明,但由于我的学识所限,难免有理解错误的地方。并且我是从第一篇开始往后看,所以你越往后看会发现注释越少,因为已出现过的技术我通常不会再注释。

思维导图、人员清单、各个厂商的时间线
这些是我写作中用到的辅助材料
① 思维导图源文件在这篇文章的飞书版本上,拉到文末就可以看见,在这里因为同步不了所以只放了一张图。
② 人员清单我不会公开,这是出于对DeepSeek的尊重。虽然在事实上,竞对公司的人员穿透是一个很普遍的做法,我相信国内乃至国外的诸多竞争对手已经把DeepSeek的全员名单都拉出来了,甚至会比我做得更深入。但能少暴露一点是一点。在这里顺便祝DeepSeek的竞对友商挖角全部失败~
③ 另外我还整理了一份包括OpenAI、DeepSeek、Claude、智谱、minimax等大模型厂商的产品发布时间线,也放在飞书Wiki上。
上述内容除DeepSeek人员清单外,获取方式和论文一样。
本文由@马丁的面包屑 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


