
 起点课堂会员权益
起点课堂会员权益驾驶场景下的语音交互
驾驶场景下,采用的具体的交互方式是什么呢?使用手,亦或是语音?您觉的哪一种更方便呢?
Why is voice user interface?
先抛出一个问题,试着回忆一下,你在开车时是如何操作导航的?
答案大类上无非两种:
- 与手机交互;
- 与车载导航交互。
那么,具体的交互方式呢?使用手,亦或是语音?您觉的哪一种更方便呢?
孰优孰劣暂不下定论,我们试着分析一下语音交互出现的原因。
笔者曾听一位百度云的副总裁说:
『人机交互方式由传统的鼠标,键盘转移到了今天的 Touch 交互。而下一个交互方式的重大变革便是语音交互』。
Assume『人终究是懒的吧』,暂把这条设为定理一。
基于该法则可以推出定理二:能让人懒的方法可以获得喜欢。
那么,怎么能让人懒?
- 降低人的学习成本;
- 提高人的操作效率。
此时再看 VUI (Voice user interface),语音交互具有学习成本极低的特点,只要能清楚的用语言表达目的即可。但是 VUI 并不能完全保证提高人的操作效率。
因此,笔者认为:VUI 最高效的应用场景是『用户明确知道任务目标,且语音交互的速度要快于接触式交互』。
以上,我们再回到驾驶场景中。
人有五感——形、声、闻、味、触。从安全驾驶的角度考虑,视线需要长时间观察路况,不宜频繁打野。信息输入层面上,耳『听』更具有优势。
大脑处理信息后,需要进行信息输出。由于双手『触』受限于方向盘,再从安全的角度考虑,口『说』的优势又体现出来了。
综上,笔者理解的驾驶场景下的语音交互的适用功能为:司机对任务目标很明确,如:播放某某歌曲,且该任务通过语音操作的效率高于接触式操作。
How to do VUI design?
General Interaction Flow:语音获取 -> 语音处理 -> 信息呈现。
类似于 GUI 设计,设计师需要考虑信息的收集、处理、呈现,只是多了语音这个信息载体。
设计流程如下:
- Requirements:明确商业上的需求和用户的需求,进而确定产品的需求;
- Flow:从需求出发,梳理出交互流程;
- Prompts:针对每一个流程,设计语音提示;
- Grammar:针对语音提示,设计语法收集语音反馈;
- User testing:完成设计后,通过用户测试手机反馈;
- Tuning:针对反馈,进一步完善产品。
Requirements
产品需求定义是决定一个好产品的核心,只有把有限的资源集中在『刚需』功能上,用户最后才会买单。后续一切的设计,开发才有意义。
Requirements design:It is always a balance between business interest and user interest.
笔者认为:盈利导向性产品中,需求设计总是在商业利益和用户利益之间发现一个平衡点。如果涉及到公司政治因素,商业利益也包括领导的利益和团队的利益。
你需要知道公司每个部门的想法是什么,领导的想法是什么?
这是保证项目顺利实施的核心。其次,产品必须要用户获利,否则这个项目本身不具有任何意义,除非你想做官僚式产品。
设计师需要考虑商业、公司、人事、用户等各个方面的问题,理性平衡各方面因素,从而达到一个暂时的最优解。
由于软能力层面不可一概而论,本文后续只从用户体验的角度设计功能。
Flow
当功能确定之后,需要详细梳理功能的流程。流程应该反应功能的优先级,同时,确保用户的每一步操作都有相应的反馈。
笔者觉的在这一步,团队成员之间可以多多交流,多讨论流程有哪些可以优化的地方。尽可能的完善流程,以避免后续改动造成的额外成本。
其次,VUI designer 和 GUI designer 应该在这个阶段就开始多合作。鉴于车载的中控屏幕、Kombi 显示屏和 HUD(Head-up display),一个良好的 GUI 界面对于提升 VUI 的用户体验是至关重要的。
在提示信息,显示信息以及错误提示时,图形界面都可以很好的辅助用户进行语音操作。二者相辅相成,缺一不可。
Prompts
在对话设计中,需要设计师对于该门语言有着深刻的理解,包括但不仅限于:停顿、语调、用词、强调等。
每一门语言都有着其独特的 Prosody,这需要课外进行大量的积累。笔者自觉知识有限,这里仅从信息呈现的角度谈谈如何设计对话。
以下内容参考 Amazon Alexa Voice Design Guide
- 清晰的告知用户该做什么?
- 保持简洁;
- 避免过多选项;
- 提供帮助选项;
- 只询问必要问题;
- 有选择的让用户确认;
- 一次只处理一条信息;
- 让用户知道所处上下文;
- 一次不要呈现过多的信息;
- 信息可听度;
- 避免使用专业术语;
- 错误时再次提示给用户指导;
- 错误时提供帮助入口;
- 错误时不要责怪用户;
- 提前预测错误。
具体案例大家可以查看 Amazon 原文。
笔者这里主要强调 10.信息可听度 和 12.错误时再次提示给用户引导。
(1)信息可听度
VUI designer 写的文字最后会通过 TTS (text to speech) 的技术读出来,因此,看上去没有问题的书面用语有时在读出来时会变得不那么自然。所以,建议设计师把对话大声多朗读几遍,这会非常有助于你感知真实的用户场景。
And of course, your ears will tell you how it works.
(2)错误时再次提示给用户引导
在 Voice:user interface design一书中,作者提到了两种错误提示的方式:一种是完整提示,另一种是快速提示。
区别如下:
完整提示
- System:请输入密码?
- User:假如用户输错了或不知道密码,此步骤失败。
- System:密码错误,请再次输入?如果您忘记密码,请登陆 APP 个人界面重新设置密码。
快速提示
- System:请输入密码;
- User:假如用户输错了或不知道密码,此步骤失败;
- System:密码错误,请再次输入;
- User:加入用户操作再次失败;
- System:密码错误,请再次输入。如果您忘记密码,请登陆 APP 个人界面重新设置密码,结束操作请说『结束』。
笔者认为:完整提示更倾向于 Memory load 比较大的操作,用户很容易忘记的内容。很大概率上,用户需要完整的提示在指导其进行操作。
反之,快速提示则更适用于 Memory load 比较小的操作,用户误操的可能比较大,因此首次错误提示应该更加简洁,以高效为首要目的。可针对具体应用场景进行选择。
Grammar
语法层面设计到一些复杂的技术,笔者根据技术识别流程简单介绍下。
![]()
Recognition flow
- 判断结束点;
- 提取有效信息;
- 识别;
- 自然语言理解;
- 对话管理。
(1)判断结束点
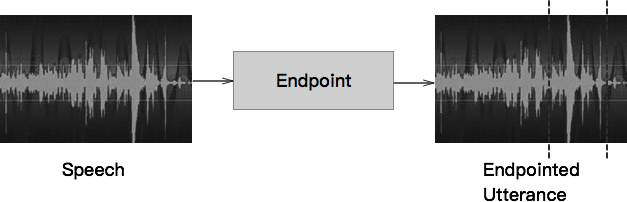
End point
从发出声音到结束声音,截取声音片段。
(2)提取有效信息

Feature extraction
通过处理技术,将声波识别成为一个个发音单元。
(3)识别

Recognition
根据 Dictionary 中的发音单元和单词的匹配,将发音单元识别成特定的文字。
(4)自然语言理解

Natural language
通过算法对文字就行处理,理解其想表达的含义。
(5)对话管理

Dialog management
针对此轮对话的含义,从而进一步设计下一轮对话,其中最核心的部分是在识别模型这一块。
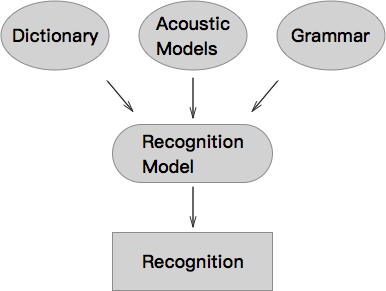
Recognition model
目前主要有两大识别模型:Rule based grammar 和 Statistical language model (SLM)。
两种语法的目的都是为了充分理解用户说的内容,从而指导用户进行下一轮对话,区别在于其实现的技术手段。
Rule based grammar 即为人工定义,利用 voiceXML language 手动定义语法的 slots 和 filler。slots 即需要识别的内容,filler 用于帮助定位 slots。
//Example 1
.GETDESTINATION (?PREFILLER CITY ?POSTFILLER)
PREFILLER [ (I want to go to) (I am going to) (I need a flight to) (?I’m going to) ]
CITY [ (new york) (the big apple) (san francisco) ]
POSTFILLER//Example 2
.GETCITIES (?PREFILLER
[(from CITY: orig to CITY: dest)
(to CITY: dest from CITY: orig)
] {<origin-city $orig> <destination-city $dest>}
?POSTFILLER
)
SLM 则是通过机器学习的算法,基于数据训练出来的自动识别语法。在大数据的背景下,可以实现自然语言理解的功能。其优点是可以允许用户按照自己的想法说出内容,不受限于 Rule based grammar 的有限识别范围。
可以理解为基于人工智能(AI)的语音识别技术。国内比较领先的两大技术提供商 科大讯飞 和 DuerOS. 其手机端的识别能力,笔者在第一次体验时深深感受到了人工智能震撼。
理解技术背景有助于设计师更好的与工程师进行合作,辅助工程师设计出更人性化的语音识别技术。
User testing
测试这一环节和 GUI 基本一致,可以内部先按功能流程测试,记录下不完善的地方。然后根据用例,小规模组织实际用户进行测试,记录下反馈。并在测试完成后进行 Group research 收集用户更多主观上的感受。
等产品上线后,有了大规模的产品数据后,采用 hotspot analysis,针对使用率高和退出率高的区域进行监听,然后分析其原因。
不同的地方是我们可以在 VUI 的早期测试环节使用 Wizard Demo——即通过环境设置让用户觉的语音是机器识别并进行反馈的。实际上是通过测试员在幕后模拟机器发出的。
Wizard Demo 开发时间短、成本低,同时又能很好的扮演实际产品的测试功能。可以运用在 Prototype 技术成本较高的项目中。
Tuning
润色。
好的产品都是不断迭代而来的,一口气不可能吃成个胖子。针对 User testing 中发现的问题:repeatedly iterate until the end。
Let’s check a sample application
Albert Einstein made the comment, “Example isn’t another way to teach, it is the only way to teach.”
So, 笔者本章用一个案例来说明上个章节的设计方法。
Requirements
车载系统的三大核心功能层面为导航,娱乐和通信。导航本身作为车辆出行的辅助性工具,其重要性犹胜。针对导航功能,其三大核心功能为:搜索、路线、和 LBS(Location based services)。
考虑到车辆的通勤属性,即上下班的使用场景会更为频繁。在此我选择『路线』功能作为 VUI 设计的范例。
功能定义:用户可以通过语音设置通勤地址(家和公司),支持语音唤起,导航至指定目的地。
Flow
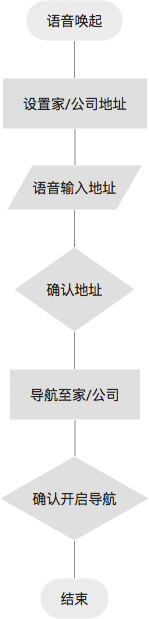
Main flow v1
- Step 1 语音唤起:可以使用方向盘 TTS Button 或语音唤起词技术,对语音识别系统进行唤起。比如:『奥迪奥迪』。
- Step 2 设置家/公司地址:唤起成功后,此时应该有固定声音提示 earcon,如『叮』。告知系统已触发,请说出内容,可以结合 GUI 共同提示。用户发出设置地址指令,设置环境可能出现错误。
- Step 3 语音输入地址:指令发出后,系统识别,然后告知用户语音输入目的地地址。此时需要考虑 prompt 设计,是让用户一次性说出全部地址,还是逐级引导用户输入地址。
- Step 4 确认地址:可能存在识别错误,需要用户确认是否是该地址。
- Step 5 导航至家/公司:成功设置后,语音提示用户是否要导航至该目的地,若超出 timeout,则用户需要再次唤起并发出导航指定。
- Step 6 确认开启导航:系统告知用户大体路况信息,询问用户是否需要开启导航。
- Step 7 结束:开始导航,流程结束。
根据以上分析,完善一下流程图:
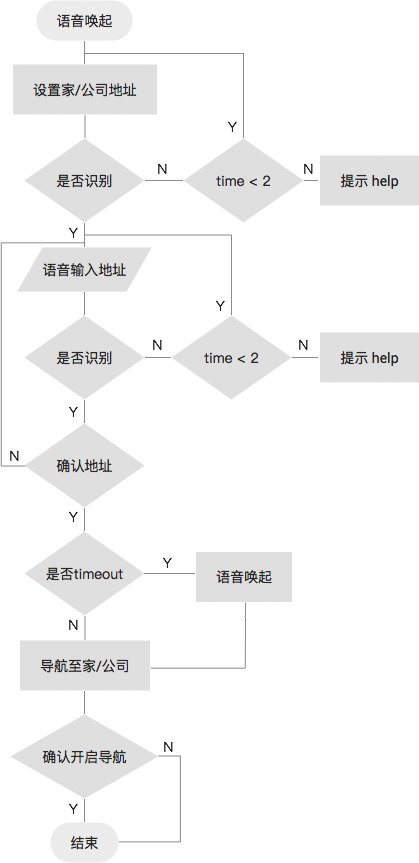
main flow v2
Promp

Grammar
笔者认为:在技术条件允许的情况下,优先使用SLM进行语音识别,最大可能提升用户操作上的自由度。因此在地址识别上,用户即可以说目的地名称,如:奥迪中国楼;也可以说目的地地址,如:酒仙桥路4号。
但这并不意味着设计师就可以不构思语法部分了,尝试用 rule based grammar 来预判用户操作,对于理解整个交互流程和优化 prmpts 的用户体验都是大有裨益的,即使是用作日后测试 SLM 的样本也是极好的。
笔者写两个基本的案列:
//设置地址POI
.ADDPOI (?PREFILLER 名称 ?POSTFILLER)
PREFILLER [ (设置) (我要设置) (我想设置) (添加) (我要添加) (我想添加)]
名称 [ (家) (公司) ]
POSTFILLER [ (位置) (地址) ]//输入地址
.GETDESTINATION (?PREFILLER 地址)
PREFILLER [ (地址是) (我想去) (目的地是) (位置是)]
地址 [ (地址名称) (地址详情) ]
User
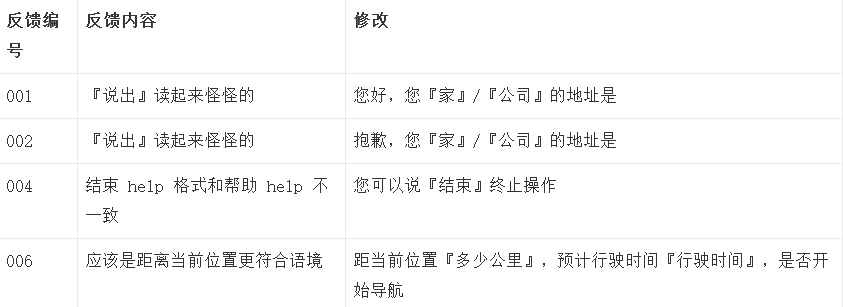
Tuning
结合 user testing 的结果,结合 GUI 的辅助,第一版完整的流程如下。
(1)路线场景下唤起系统:Eercon “叮”

GUI prompt
- 用户语音指令输入:设置公司的地址;
- 系统反馈:您好,您『公司』的地址是。

GUI prompt
- 用户语音指令输入:奥迪中国楼;
- 系统识别错误:抱歉,您的公司地址是。

GUI prompt
- 用户再次语音指令输入:奥迪中国楼;
- 系统识别正确:您公司的地址是奥迪中国楼,位于798酒仙桥路2号,是否确认。

GUI prompt
- 用户确认公司地址:是。
- 用户语音指令输入:导航去公司。
- 系统识别,开启导航:公司距当前位置3公里,预计行驶时间20分钟,是否开启导航。

GUI prompt
识别错误2次以上,是显示帮助信息:您可以说『帮助』查阅使用手册,『结束』终止操作。

GUI prompt
To be continued
想要设计一个优秀的语音交互功能,以上笔者所述只是最基本的入门知识,每一个模块都还有大量的知识需要学习。
尤其考虑品牌建设,类似于 GUI,你的 VUI 的设计理念和设计特色是什么?如何让用户『一耳就听出』这是你设计的?
地图导航中名人语音包就是一个好的尝试。因此,针对目标用户群体,产品声音的 persona definition 是必不可少的。
若最终想提供用户一种和真人对话场景感,这个说话的人是谁就需要好好琢磨了。年龄、性别、职业、口音、语速、用词…
当用户有一天分不清真人语音和机器语音的那天,除了人工智能带来的细思极恐外,陪聊产业的红红火火,恍恍惚惚似乎也是冥冥注定的吧。
Reference
作者:天晨Joey
原文链接:https://www.jianshu.com/p/204441b82709
本文由 @天晨Joey 授权发布于人人都是产品经理,未经作者许可,禁止转载
题图来自 Pexels,基于 CC0 协议









流程图里time<2是什么意思
一些vui文章观点的集合。