
 起点课堂会员权益
起点课堂会员权益B端产品 | 用户体验量化的三个案例
笔者在学习Tom Tullis、Bill Albert的《用户体验度量》后,开始思考:针对B端产品,如何在线上环境中,通过对用户数据的采集、分析,完成对产品的用户体验量化?
本文给出三个案例进行尝试,从简单到复杂阐述三种量化的维度。

为什么要量化用户体验
针对企业内部使用的B端产品,在日常做设计的过程中,体验设计师常常是凭借经验来完成对产品的体验优化。“经验”一般有两种来源:
- 参考竞品的设计
- 参考自己已做过的类似产品
很明显,这两种设计经验有一个很大的缺陷,就是很容易“拍脑袋”定方案——产品经理拍、设计师拍,更多的时候是领导拍。
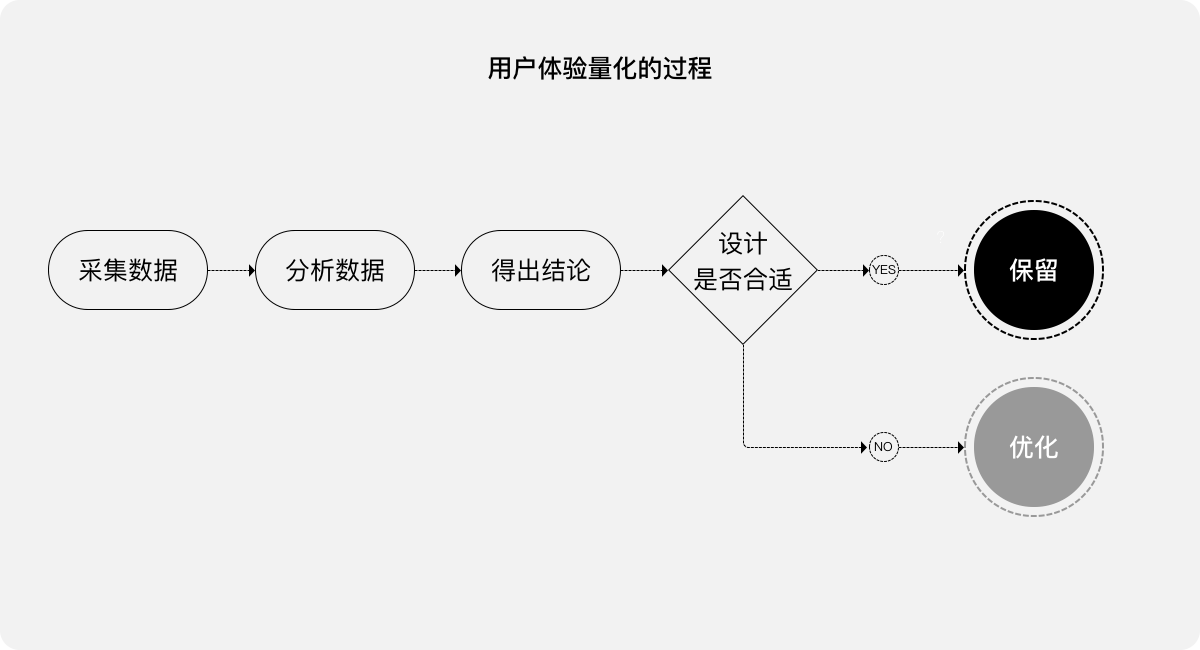
“拍脑袋”,有时真的是天才般的灵感火花,但大概率是盲目瞎拍。因此,如何避免出现这种“瞎拍”,是体验设计师应该考虑一下的问题。“用户体验量化”就是一个很好的手段:
“通过对用户体验相关的数据进行采集、分析,使用量化的数据证明设计的‘合适’与‘不合适’,合适的保留、不合适的继续优化,为产品的迭代建设保驾护航”
一维量化:单个指标直接比较
案例一:“任务”
针对B端效率类的工具型产品,其不以用户留存时间为目标,反而如果能降低用户完成任务的耗时,则说明该任务链路的用户体验优化是成功的。
因此,线上可以采集一个指标的数据:任务时长,即用户从启动任务到任务完成所用的时长。或者,直接采集用户从进入该B端效率类的工具型产品到最终离开的时长。通过比较优化前后的时长,以达到用户体验量化的目的。
但是该类型产品所采集的数据存在一种缺陷——样本量少。
原因在于这种产品在公司内部的用户群体很小,例如一些基础类的云产品,用户量可能在两位数。因此,采集的数据其分布状态离散、无法直接通过分布状态判定。
那么如何在有限的样本量情况下,区分其优化前后的用户体验数据呢?
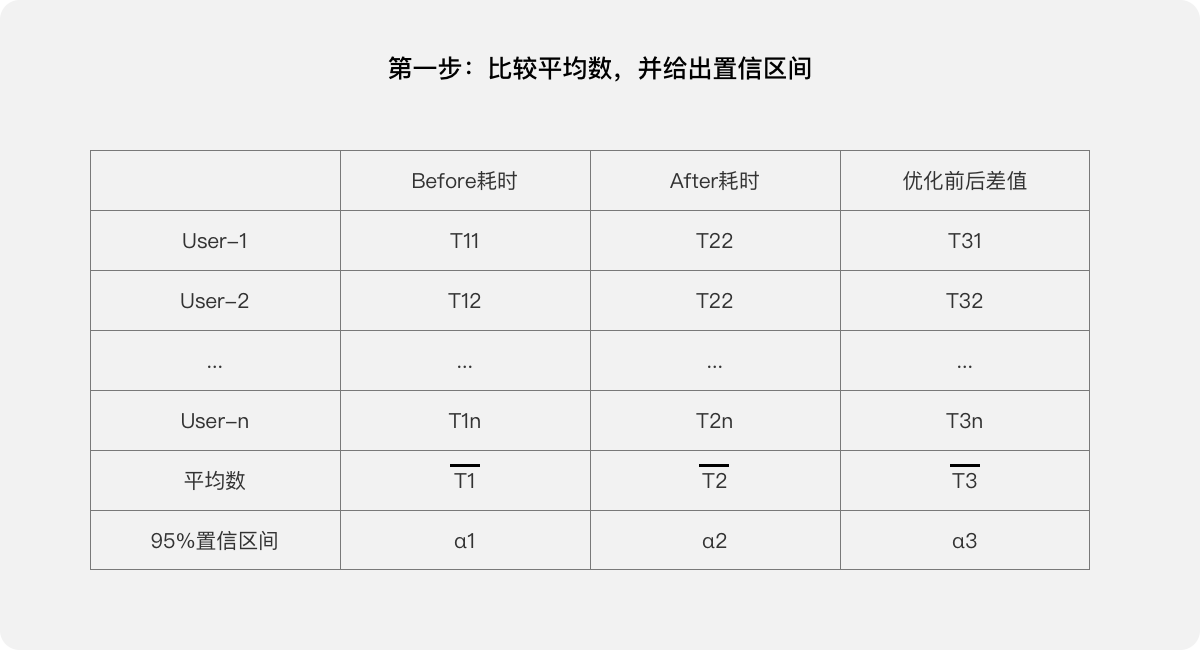
我们可以进行数据分析:平均数,置信区间,t检验。

第一步,比较平均数,并给出置信区间。
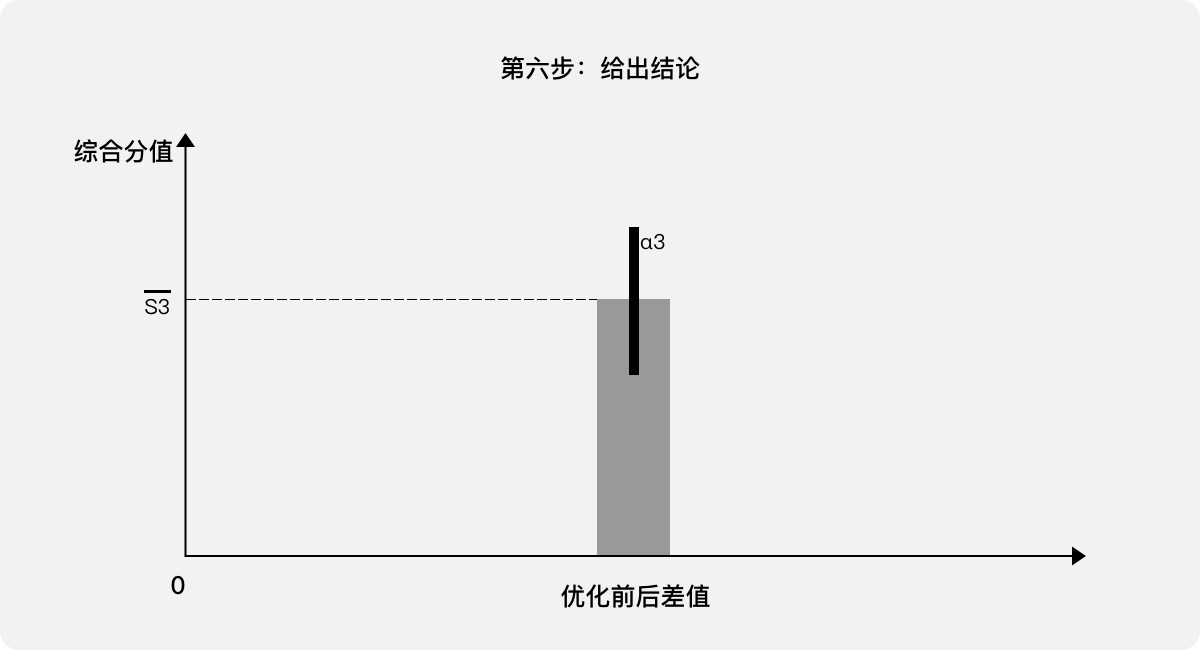
第二步,判断置信区间是否存在重叠,如果“无重叠”或“重叠较小”,则基本认定差异显著,也就可以直接通过优化前后差值及其置信区间来量化用户体验,参考第五步。
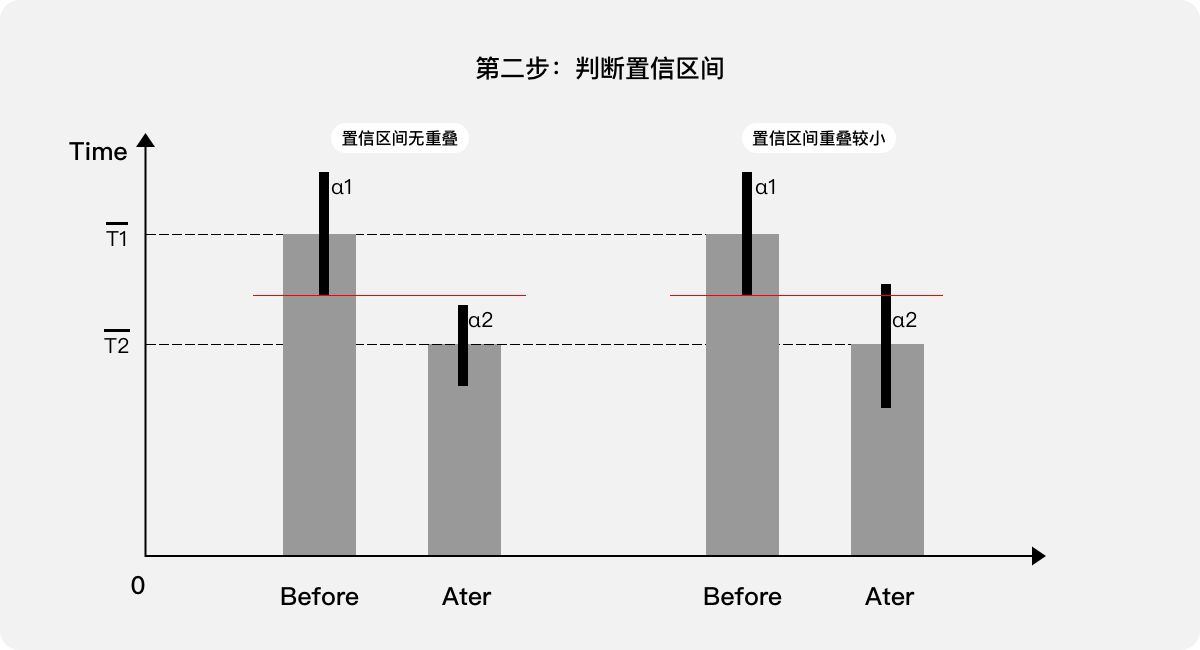
第三步,如果置信区间“重叠较大”,则无法确认存在差异,需进行t检验,如果t检验的概率值较大(>0.05)则说明差异性不显著,表示优化前后的用户体验变化不明显:优化方案“不合适”。
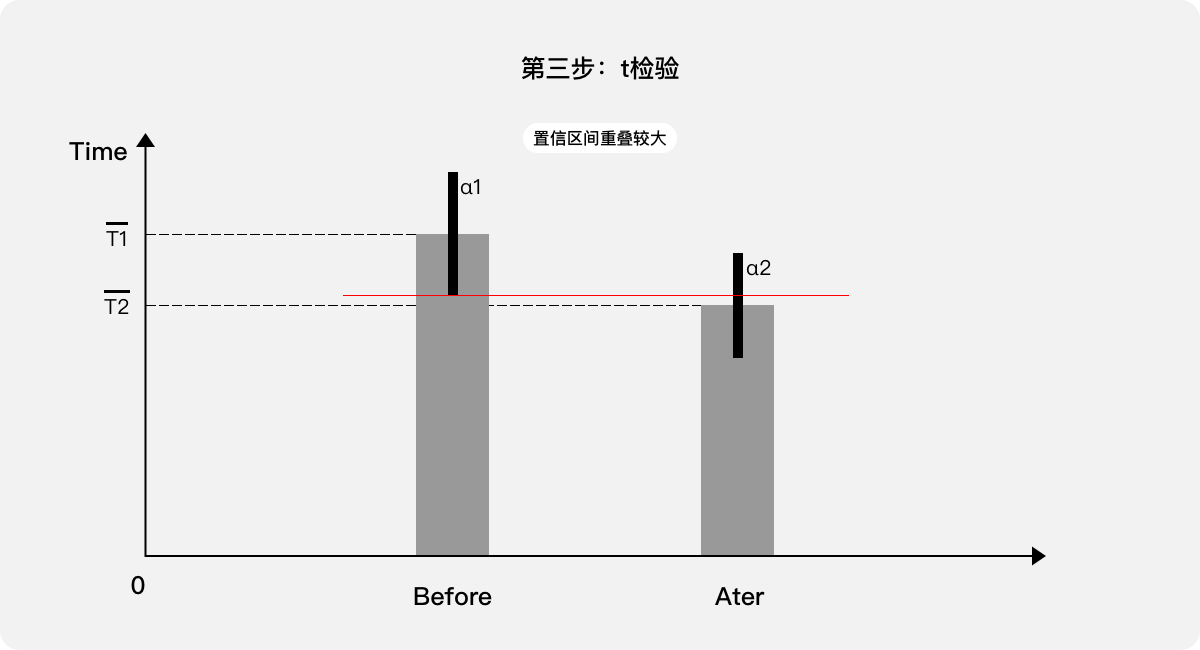
第四步,如果t检验的概率值很小(<<0.05)说明差异性显著,表示优化前后的用户体验变化明显,也就可以直接通过优化前后的差值及其置信区间来量化用户体验。
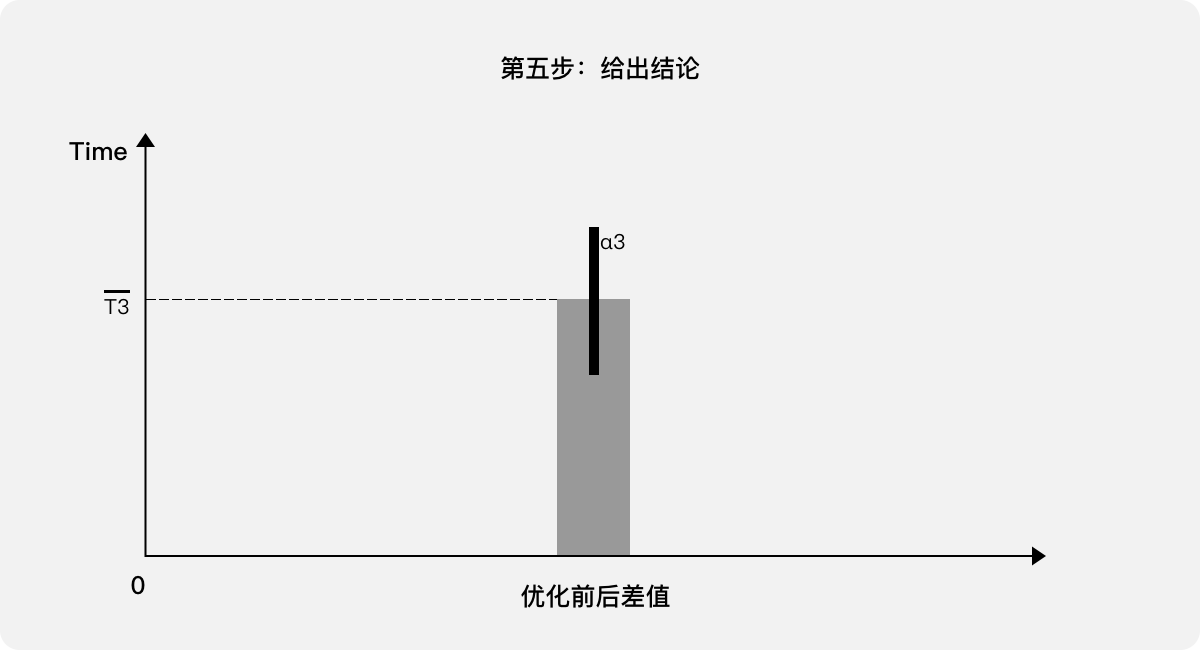
第五步,给出结论:该“任务”经过用户体验优化,成功降低了单次“任务”耗时。在95%的置信区间内平均降低了T3,其中置信区间为(T3-α3,T3+α3)。
二维量化:多个指标进行比较
案例二:“表单”
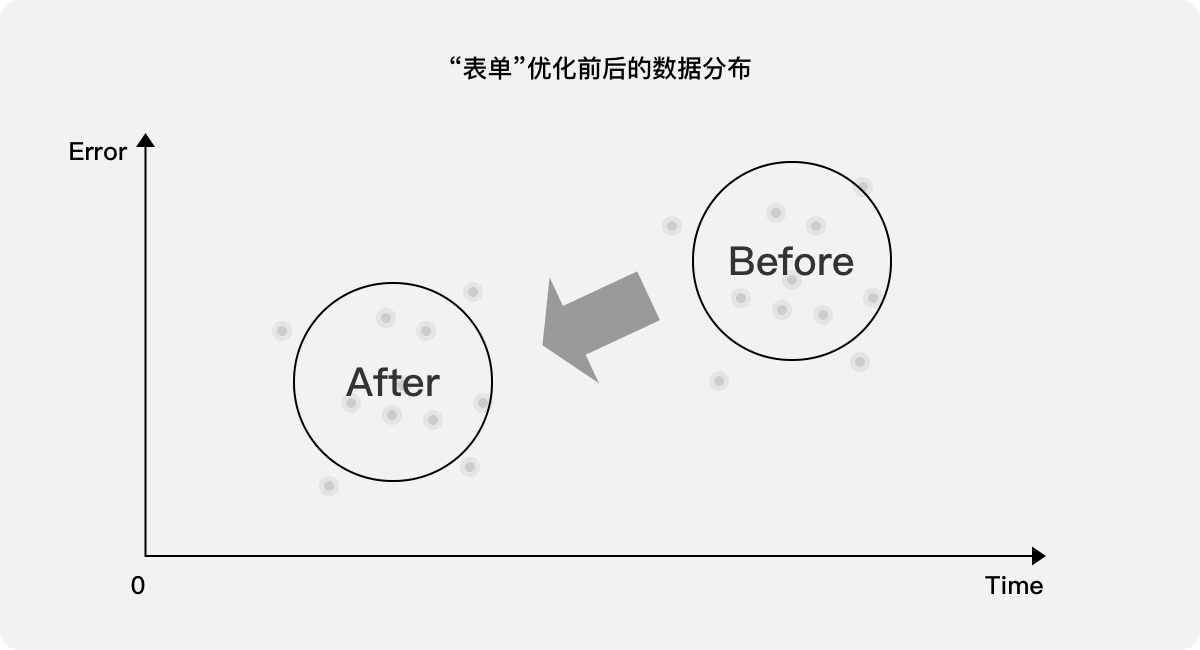
针对B端产品的某个“表单”页面,在用户填写过程中采集两个指标的数据:
- 耗时:用户从打开表单填写页面到成功提交所用的时长
- 报错次数:用户在填写过程中触发报错提示的总次数
当体验设计师优化该表单填写页面并发布上线后,比较前后版本的耗时和报错次数,并将其映射至二维图,理想态应该是整体数据向左下移动,优化前耗时长、报错次数多,优化后耗时短、报错次数少。
发散点1:如果表单有多个页面,可分别从整体和单个页面去进行量化分析,以发现链路的哪个环节仍然存在问题。

发散点2:针对报错的内容,将其进行等级区分,可更细致量化分析,甚至可用低等级异常置换高等级异常,以提升整体体验。
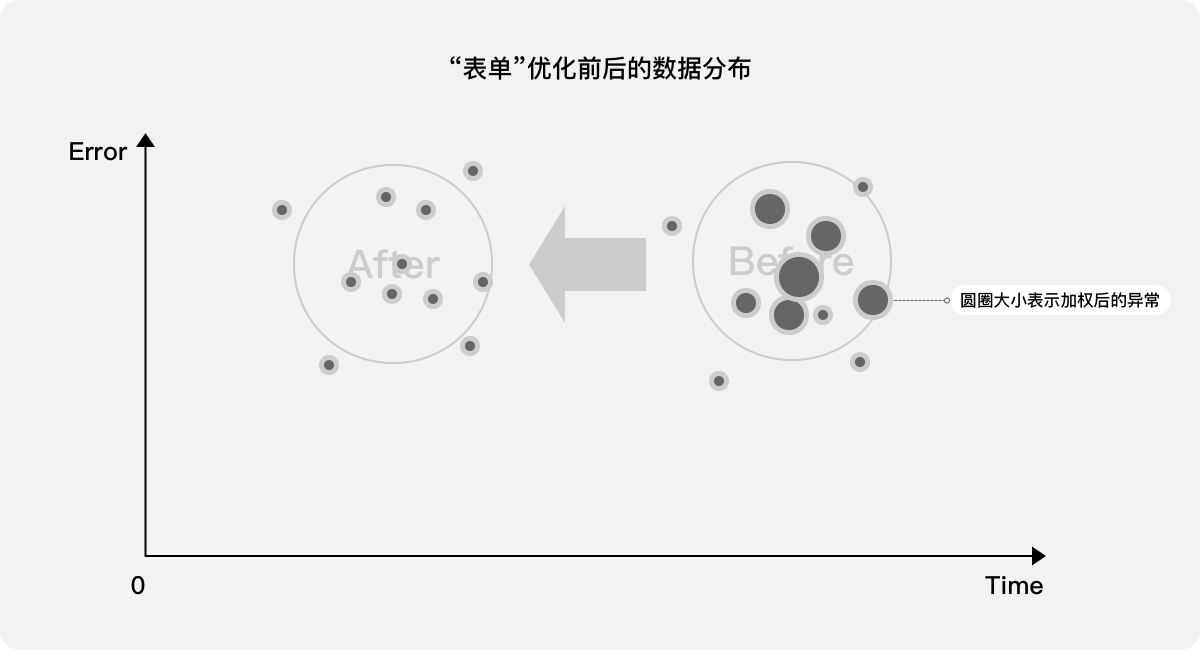
如上,当只需分析两项指标的时候,可以直接将数据映射在二维图上进行比较。但如果有3个及以上的指标,如何进行量化?
可以通过给指标进行“加权”,计算出一个综合分值,通过比较综合分值就可以间接量化其用户体验。
假设有三项指标:p、q、r
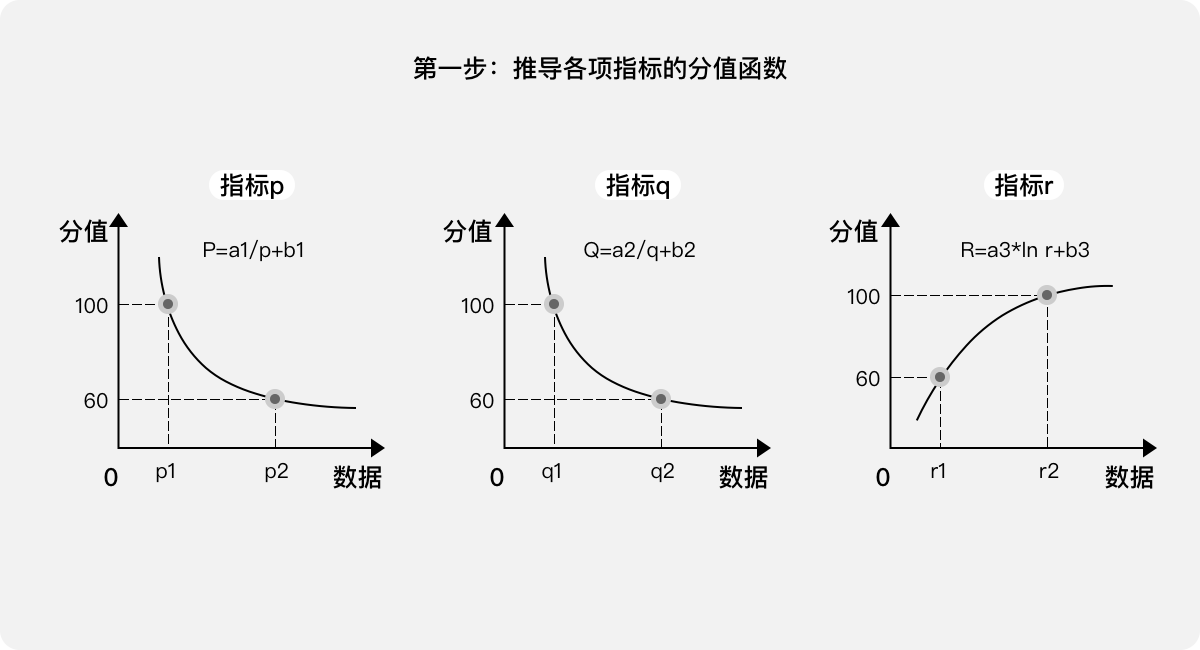
第一步:推导各项指标的分值函数(分数越高表示体验越好)。
建议:如果指标的数据和得分是正相关,可以使用对数函数(y=ln x);如果是负相关,则可以使用幂函数(y=1/x)。通过定义“满分、及格”两个坐标(如果需要更细腻,甚至可以定义多个坐标,例如优良中差等等),即可推导出各项指标的函数式(a、b均为系数)。
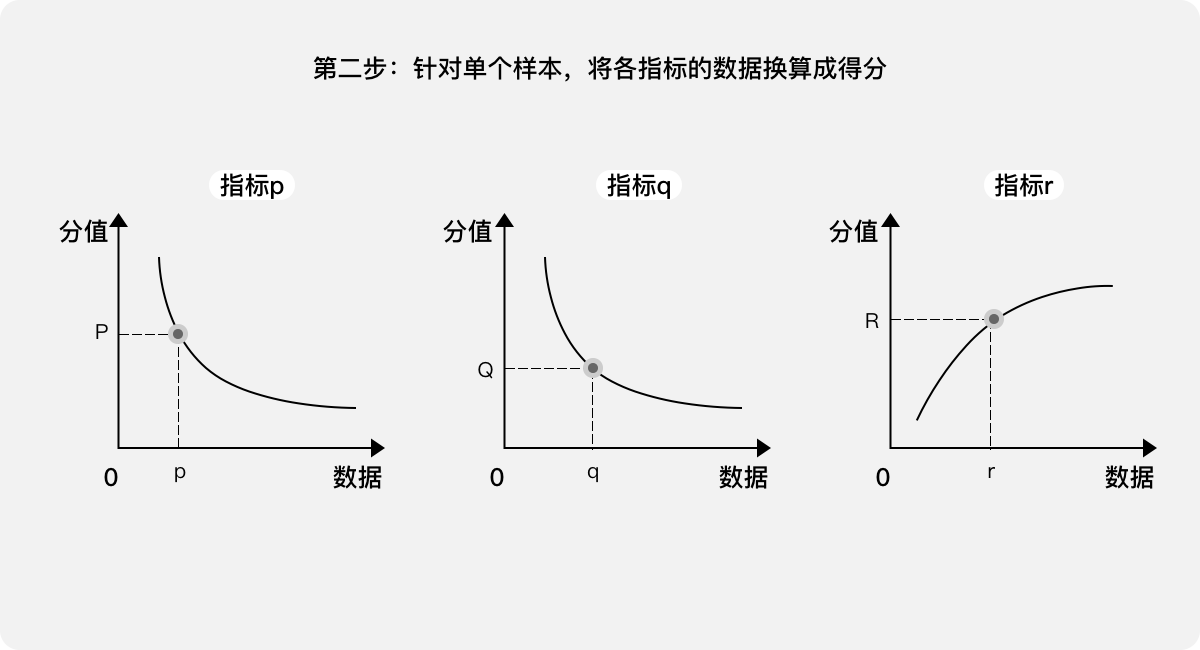
第二步:针对单个样本,将各指标的数据换算成分值。把各项指标的采集数据当作自变量,可计算得出对应的因变量,即得分:P、Q、R。
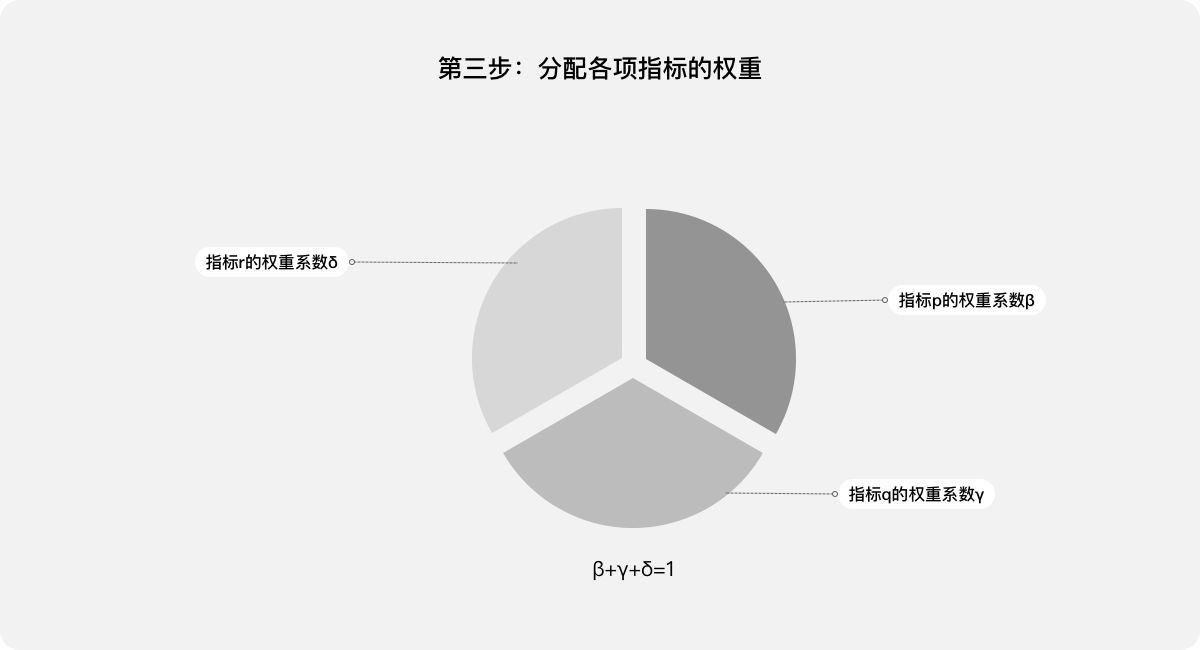
第三步:分配各项指标的权重:β、γ、δ,其中β+γ+δ=1。
第四步:计算每个样本的综合分值。其综合分值等于每项指标的得分与权重的乘积之和,为:
S=P*β+Q*γ+R*δ
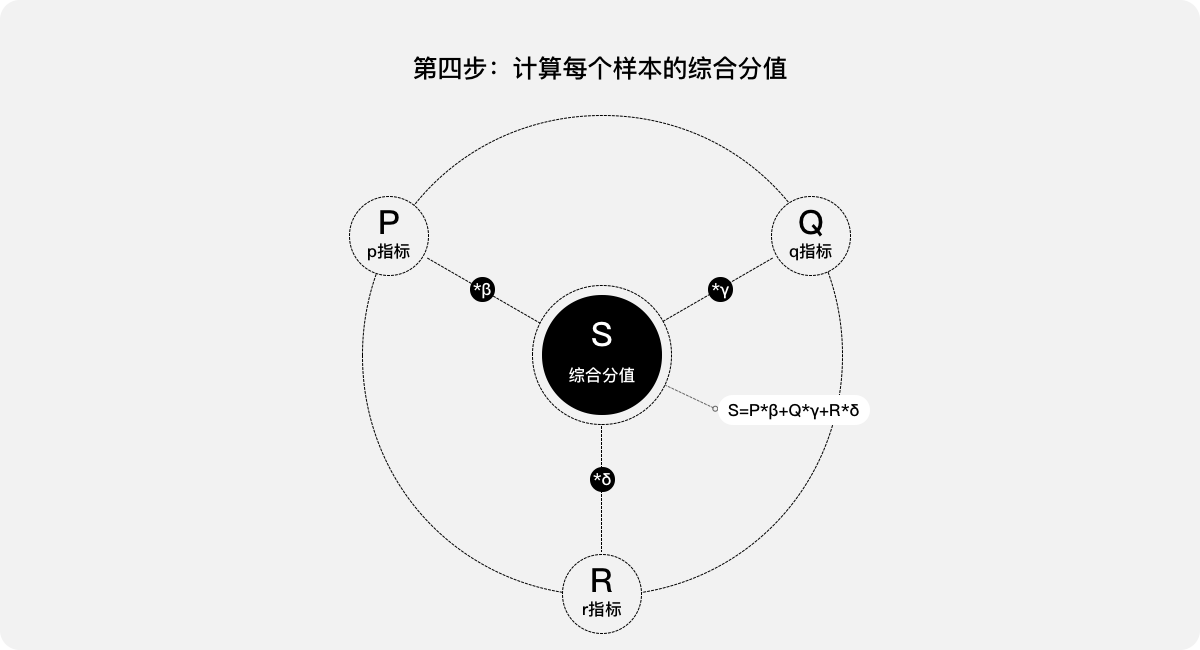
第五步:数据分析。针对所有用户的综合分值S,参考使用案例一中的“平均数、置信区间、t检验”进行分析,比较优化前后的数据。
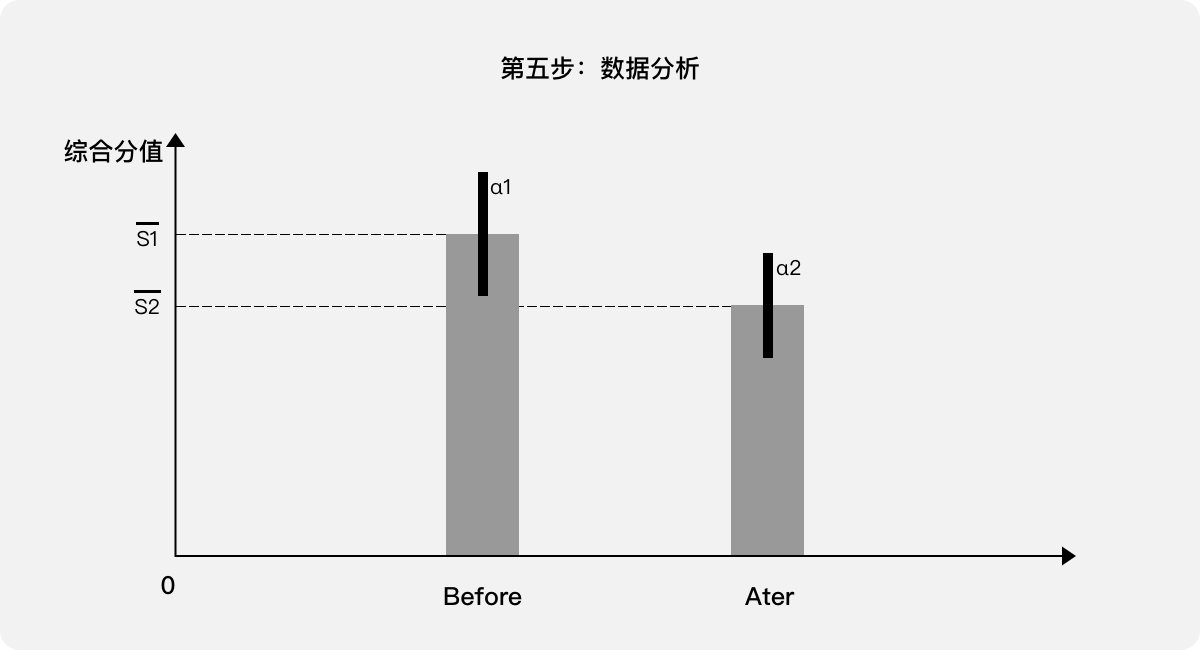
第六步:给出结论。该“表单”经过用户体验优化,成功提高了用户体验分值。在95%的置信区间内平均提高了S3,其中置信区间为(S3-α3,S3+α3)。
多维量化:多类指标进行比较
案例三:“产品”
针对B端产品,在量化其整体的用户体验时,会采集多种类型的指标,包括不限于:绩效、可用性、满意度、生理数据等等。如何使用多类型指标进行用户体验量化?
假设采集了以下3类共9种指标的数据:
- 绩效,p1、p2、p3
- 可用性,u1、u2、u3
- 满意度,h1、h2、h3
有两种方法可以对其进行处理:
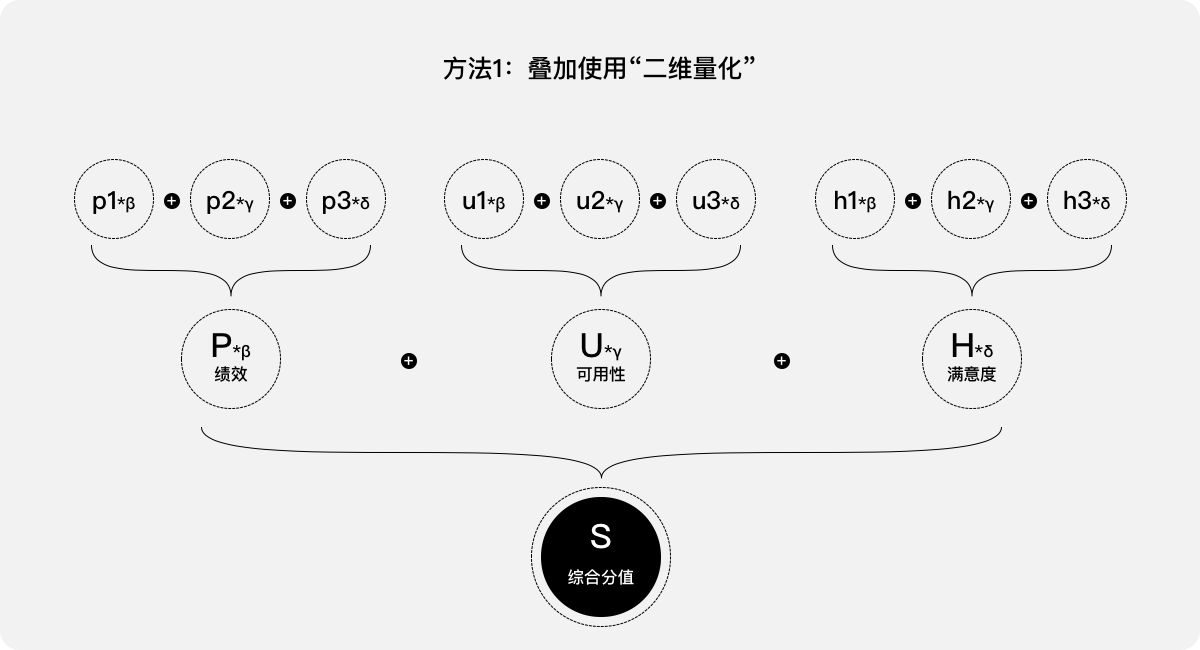
方法1:叠加使用“二维量化”。针对“绩效”的指标p1、p2、p3,参考案例二中的处理方法予以加权,就可以得出一个“绩效”的分值P,同理可分别得出“可用性”的分值U和“满意度”的分值H;针对这三项分值P、U、H,继续参考案例二中的处理方法,可以得出一个综合分值S,即该产品的用户体验分值;
方法2:先“降维”,然后使用“二维量化”。将9种指标视为产品的9个维度,首先通过使用降维方法,得到9个互相独立、具有正交特征的新指标(综合指标)。然后选出靠前的n个(n<=9)综合指标,参考案例二中的处理方法予以加权,就可以得出一个综合分值S,即该产品的用户体验分值。
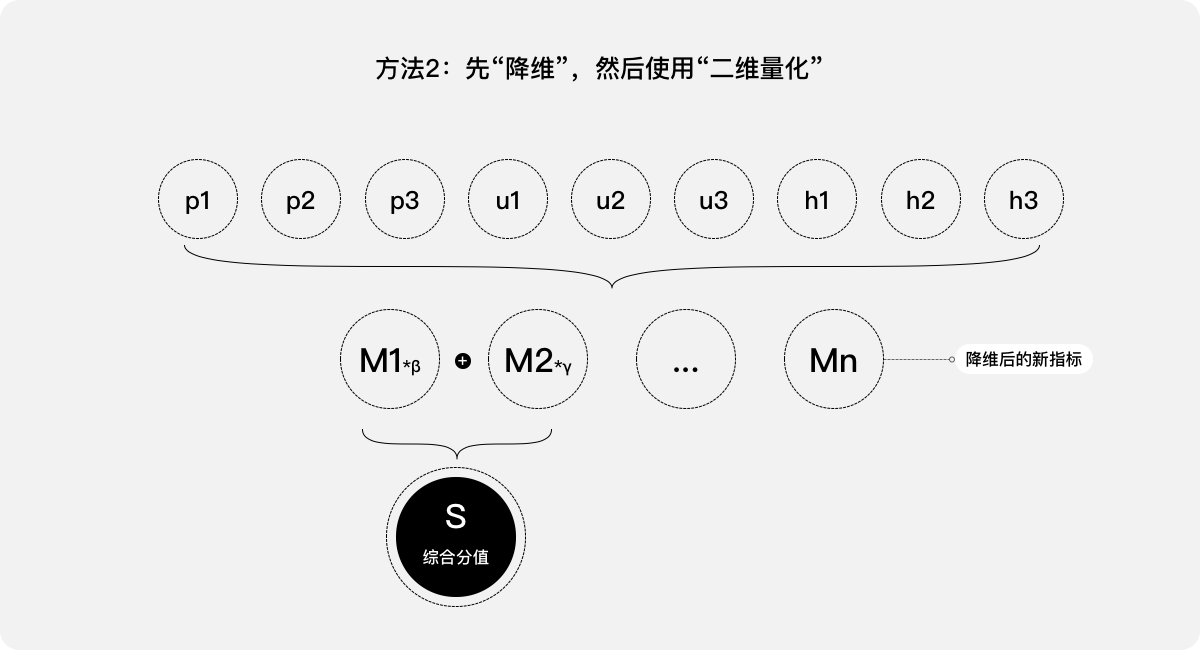
以上两种方法均可,但第2种可能会更精准、更直观。
原因在于,虽然指标都是独立采集、甚至分属于不同的类型,但部分指标之间可能存在一定的正相关或负相关。例如,绩效指标“成功率”和可用性指标“帮助的实时性”可能会存在正相关:帮助的实时性越高,成功率可能会越高。
如果使用方法1进行处理,由于给各指标加权需要人为识别、决定,具有相关性的指标之间其权重难以保持一致。多次人为加权,不仅计算的复杂程度高、稳定性也很低。
如果使用方法2中的降维:
- 对具有相关性的指标进行合并、减少冗余信息造成的误差
- 去除噪声和不重要的特征,降维得到的综合指标之间独立性强、识别度高。
需要注意的是,降维肯定会损失一些信息,这可能会让最终结果不能100%体现原数据,但是通过把多维数据降至2、3维,就可以对其进行数据可视化,便于直观地发现分布形态。针对合并后的综合指标,人为识别、加权更精准。
降维方法有很多种,此处使用主成分分析法(PrincipalComponents Analysis,PCA)进行降维,其主要是通过对协方差矩阵进行特征分解,以得出数据的主成分(即特征向量)与它们的权值(即特征值),步骤如下:
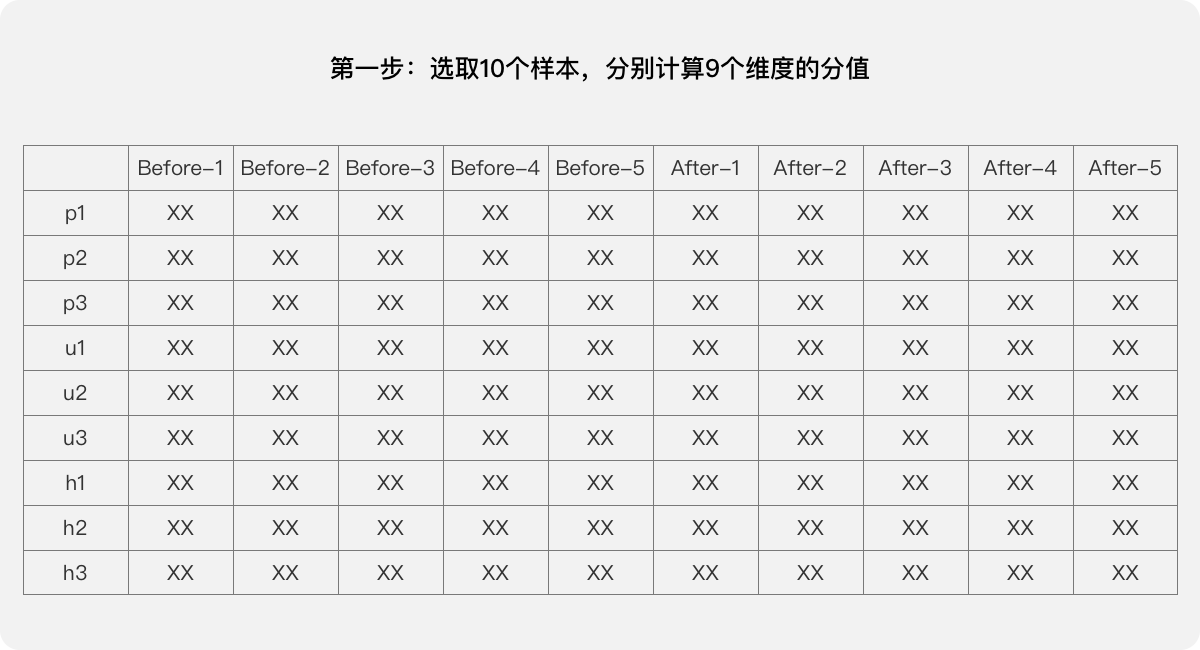
第一步:选取10个样本(优化前后各5个),参考案例二种的分值函数分别计算9个维度的分值:p1、p2、p3、u1、u2、u3、h1、h2、h3。
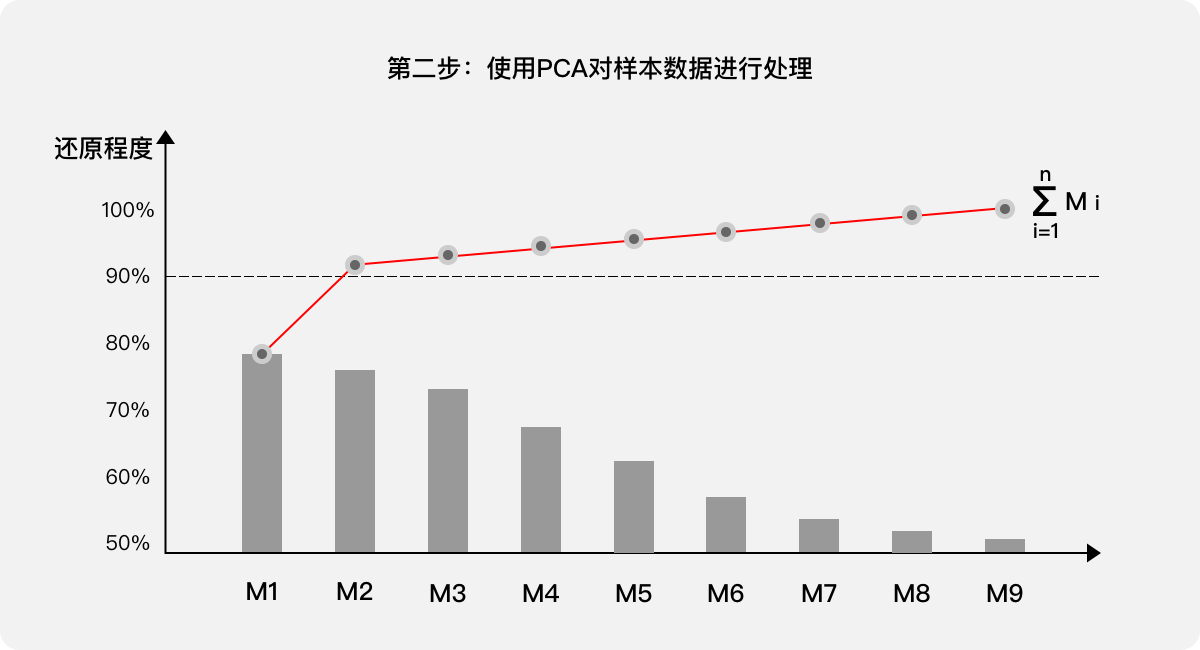
第二步:使用PCA对样本的数据进行处理,针对处理结果按照还原程度由高到低列出主成分(新的综合指标M1、M2、M3…M9),根据需求确定合适的还原程度,如果需要90%,则新的综合指标为M1、M2。
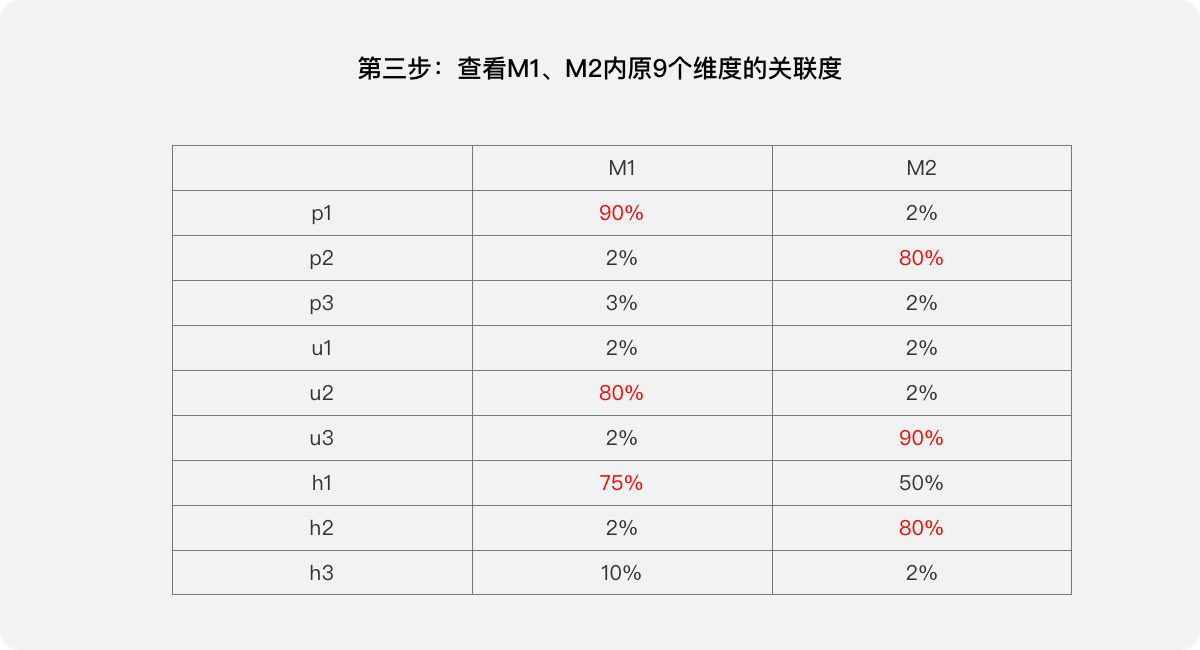
第三步:查看M1、M2内原9个维度的关联度,据此可理解M1、M2两个综合指标的含义,M1主要代表p1、u2、h1,M2主要代表p2、u3、h2。
第四步:数据可视化。针对10个样本,利用各样本在M1、M2两个新的综合指标内的分值(坐标),映射至二维图。
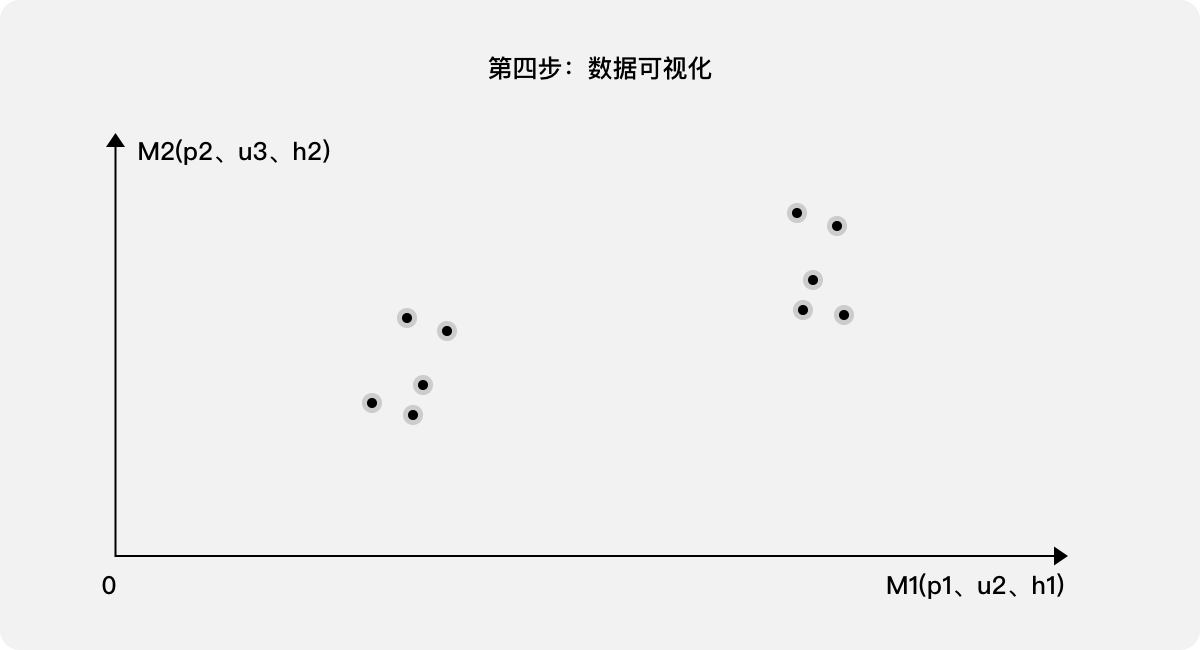
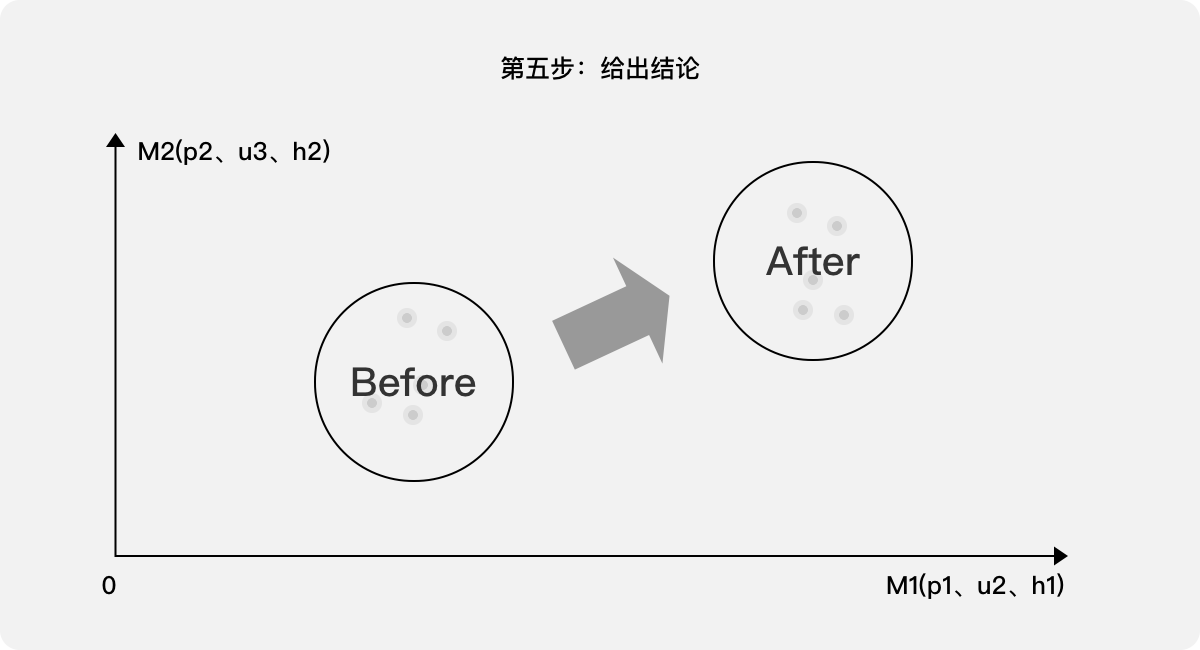
第五步:给出结论。通过观察10个样本的分布状态,可以清晰看出经过优化,产品的用户体验分值是否明显提高。另,如果需要得出一个综合分值S,则可以根据M1、M2的含义分别予以加权,参考案例二中的处理方法即可得出。
总结
由于B端产品的用户群体较小、强功能、弱设计等等原因,一般在产品的整个生命周期里面都很少使用量化的数据来指导产品建设和体验设计。在本文中,通过三个案例介绍了三种量化方案:
- 第一个“任务”案例中,是量化单个指标,定义为“一维量化”
- 第二个“表单”案例中,是量化多个指标,定义为“二维量化”
- 第三个“产品”案例中,是量化多类指标(降维),定义为“多维量化”
不同类型、不同建设阶段的B端产品,可以选择合适的用户体验量化方案。寻求量化点并采集有效数据,是用户体验设计师可以多多思考的。
作者:胡欣欣,公众号:吹拉弹唱大师(ID:cltcds)
本文由@吹拉弹唱大师 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash, 基于CC0协议









第二三种方法没办法用的,整体就是薛定谔理论。。。😂
在数据已经确定的情况下,选择不同的时间段,或者延长时间段,得出的数据很可能会不一样。。。
所以根本没办法拿出来做比较
有体验度量方面的交流群吗
感谢作者分享!统计部分讲得很清晰!有个问题想跟大家交流:对于任务和表单两种情况,如何排除任务和表单本身的任务难度影响?
比如after之后用户填写的表单变复杂了,那么就很难直接跟before进行比较了。如果数据量足够大的话,可以通过随机的方式平衡差异,但文中也提到用户量可能很小,甚至只有20个,这种情况要如何处理呢?
可以回到用户要完成的任务本身来看,表单优化前后,用户要完成的任务是不是一致?如果是一致,就可以对比看数据,如果任务不一致,那么就不能对比看数据。我感觉哈,“难度”不是评价是否可以前后对比的标准
写的文章好棒,最近研究b端,找时间把你文章都看一遍,哈哈哈
哈哈,谢谢~
第二、三种量化有没有例子能够带入进去?
案例二“表单”,案例三“产品”
产品体验步骤
非常欣赏作者的思考,通过用户行为数据量化评估用户体验是用户研究必须要去突破的一个方向,我也正在做这方面的尝试,过程虽然很难,但是相信前途是光明的,一起加油吧~
棒~
很佩服作者的一般讲解。但如果这个原假设一开始就不适用呢,那之后一系列的数学演练是不是就只是看起来很酷炫,比如为什么我们不直接获得听取用户对于该产品在使用过程中的槽点,来进行针对性改正呢,毕竟纯基于数据的得出的结论也说服力不大,况且,这个演练如果需要学过统计学才能做的话,或许是不是也有相关的软件在输入相关数据后,能更好的得出结论呢。我是觉得,在优化用户体验这方面,有时候如果我们可以直接接触客户的话,就没必要在苦苦研究这些纯数据,这样就有种舍近求远的感觉。共勉!
不是一般,是一番 😥
嗯嗯,你说的很对,本文只是我看书后的一点读后感,也算是一个系统的复盘和总结。研究和落地,中间差了十万八千里,脚踏实地固然重要,偶尔仰望星空也未尝不可~用户体验度量是一个很庞大的命题,从不同的角度去解释、印证,没有对和错。
说句真心话哈~我看完后确实有点懵,但如果总结是偏结果性结论并不是理论性结尾就完美点了!类似这种数据化分析出体验好坏的办法确实存在1.相对客户调研成本更高时间更长;2.团队协同合作存在沟通门槛高;3.学习跟复用难度较大;等问题导致并不实用。但本人非常认可作者学以致用的方式,虽然现在还相当复杂,可我相信只要坚持在懂得数据分析的原理再去使用分析工具会得到质变性的好处,最后感谢作者的分享~ 😉
嗯嗯,谢谢。如果是负责一两个产品的用户体验,大家都会觉得直接用户调研就可以了,简单、高效;如果是10个产品、100个产品、1000个产品呢?例如我在的苏宁易购,整个集团有几千个业务系统,那么作为用户体验设计师,可以尝试设计一套用户体验相关的数据分析产品去量化数以千计业务系统的用户体验。。。当然,目前还在进行中
优秀的帅小伙
网易的可用性测试这么复杂的吗。。
咳咳,俺是苏宁易购的~只是一点读后感而已
无语了,搞这么复杂,为了什么?不说一般公司, 就是头部大厂,也不会用这么复杂的一套体系就做什么用户体验量化,成本收益比太低。
哈哈,别慌,写着玩的