
 起点课堂会员权益
起点课堂会员权益干货推荐|数据可视化的五个步骤

数据被称作是最新的商业原材料「21世纪的石油」。商业领域、研究领域、技术发展领域使用的数据总量非常巨大,并持续增长。就Elsevier而言,每年从ScienceDirect下载的文章有7亿篇,Scopus上的机构档案有8万个、研究人员档案有 1 千 3 百万,Mendeley上的研究人员档案有 3 百万。对于用户来说,从这个数据海洋中抓到关键信息越来越难。
许多先进的可视化方式(如:网络图、3D 建模、堆叠地图)被用于特定用途,例如 3D 医疗影像、模拟城市交通、救灾监督。但无论一个可视化项目有多复杂,可视化的目的是帮助读者识别所分析的数据中的一种模式或趋势,而不是仅仅给他们提供冗长的描述,诸如:“ 2000 年 A 的利润比 B 高出 2.9 % ,尽管 2001 年 A 的利润增长了 25 % ,但 2001 年利润比 B 低 3.5 % ”。出色的可视化项目应该总结信息,并把信息组织起来,让读者的注意力集中于关键点。
对于 Elsevier’s Analytical Services 的项目而言,我们一直在寻找提升数据分析和可视化的方式。例如,在我们对于研究表现的分析中有大量关于研究合作的数据;我们为 Science Europe 提供的报告(Comparative Benchmarking of European and US Research Collaboration and Researcher Mobility) 包含跨州合作以及国际合作的数据,这些数据不适合直接用二维表和X-Y图展示。
为了探索数据背后的故事,我们使用了网络关系图来识别国家间的合作,并了解每个合作关系的影响。
本文提供一份包含五个步骤的数据可视化指南,为想用表格、图形来传播观察结果、解读分析结果的人士提供帮助。要记住,建立好的可视化项目是一个反复迭代的过程。
第1步-明确问题
开始创建一个可视化项目时,第一步是明确要回答的问题,又或者试着回答下面的问题“这个可视化项目会怎样帮助读者?”
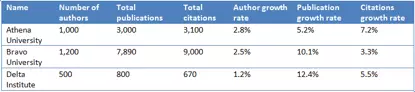
表 1–数据集中的三条记录
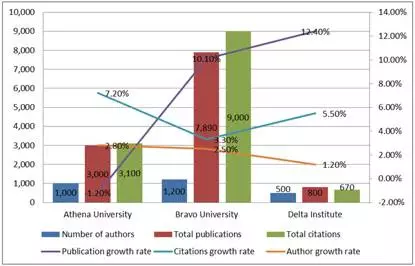
图1-槽糕的可视化项目并不澄清事实,而是引人困惑。此图中包含太多变量
清晰的问题可以有助于避免数据可视化的一个常见毛病:把不相干的事物放在一起比较。假设我们有这样一个数据集(见表 1 ),其中包含一个机构的作者总数、出版物总数、引用总数和它们特定一年的增长率。
图1是一个糟糕的可视化案例,所有的变量都被包含在一张表格中。在同一张图中绘制出不同类型的多个变量,通常不是个好主意。
注意力分散的读者会被诱导着去比较不相干的变量。
比如,观察出所有机构的作者总数都少于出版物总数,这没有任何意义,又或者发现 Athena University、Bravo University、Delta Institution 三个研究机构的出版物总数依次增长,也没有意义。拥挤的图表难以阅读、难以处理。在有多个 Y 轴时就是如此,哪个变量对应哪个轴通常不清晰。简而言之,槽糕的可视化项目并不澄清事实而是引人困惑。
第2步-从基本的可视化着手
确定可视化项目的目标后,下一步是建立一个基本的图形。它可能是饼图、线图、流程图、散点图、表面图、地图、网络图等等,取决于手头的数据是什么样子。在明确图表该传达的核心信息时,需要明确以下几件事:
- 我们试图绘制什么变量?
- X 轴和轴代表什么?
- 数据点的大小有什么含义吗?
- 颜色有什么含义吗?
- 我们试图确定与时间有关趋势,还是变量之间的关系?
有些人使用不同类型的图表实现相同目标,但并不推荐这样做。不同类型的数据各自有其最适合的图表类型。
比如,线形图最适合表现与时间有关的趋势,亦或是两个变量的潜在关系。当数据集中的数据点过多时,使用散点图进行可视化会比较容易。
此外,直方图展示数据的分布。直方图的形状可能会根据不同组距改变,见图 2 。(在绘制直方图时,本质是在绘制柱状图来展示特定范围内有多少数据点。这个范围叫做组距。)
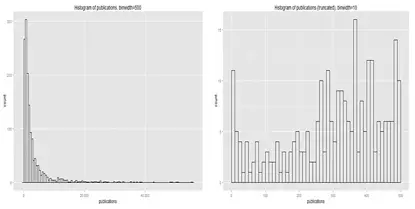
图2-当组距变化,直方图的形状也发生变化。
组距太窄会导致起伏过多,让读者只盯着树木却看不到整个森林。此外,你会发现,在完成下一个步骤以后,你可能会想要修改或更换图表类型。
第3步-确定最能提供信息指标
假设我们有另一个关于某研究机构出版物数量的数据库(见表 2 )。可视化过程中最关键的步骤是充分了解数据库以及每个变量的含义。从表格中可以看出,在 A 领域(Subject A),此机构出版了 633 篇文章,占此机构全部文章的 39% ;相同时间内全球此领域共出版了 27738 篇文章,占全球总量的 44% 。 注意,B 列中的百分比累计超过 100% ,因为有些文章被标记为属于多个领域。
在这个例子中,我们想了解此机构在各个领域发表了多少文章。出版数量是一个有用的指标,不仅如此,与下面这些指标对照会呈现出更多信息:
- 此领域的研究成果总量( B 列)
- 此领域的全球活跃程度
由此,我们可以确定一个相对活跃指标,1.0 代表全球平均活跃程度。高于 1.0 代表高于全球水平,低于 1.0 代表低于全球水平。用 B 列的数据除以 D 列,得到这个新的指标,见表 2 。
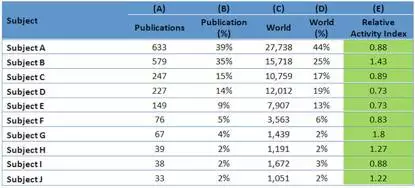
表2-用B列的数据除以D列,得到新的指标:相对活跃程度(E栏)。
第4步-选择正确的图表类型
现在我们可以用雷达图来比较相对活跃指数,并着重观察指数最高/最低的研究领域。例如,此机构在 G 领域的相对活跃指数最高( 1.8 ),但是,此领域的全球总量远远小于其他领域(见图 3 )。雷达图的另一个局限是,它暗示各轴之间存在关系,而在本案例中这关系并不存在(各领域并不相互关联)。
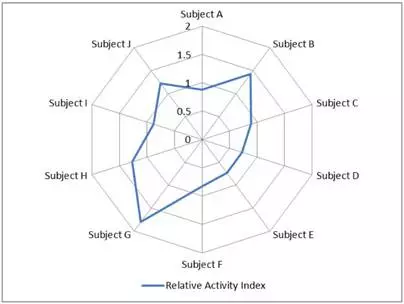
图3-相对活跃指数雷达图
数据的规范化(如本例中的相对活跃指数)是一个很常见也很有效的数据转换方法,但需要基于帮助读者得出正确结论的目的使用。如在此例中,仅仅发现目标机构对某个小领域非常重视没太大意义。
我们可以把出版量和活跃程度在同一个图表中展示,以理解各领域的活跃程度。使用图 4 的玫瑰图,各块的面积表示文章数量,半径长短表示相对活跃指数。注意在此例中,半径轴是二次的(而图 3 中是典型线性的)。图中可以看出,B 领域十分突出,拥有最大的数量(由面积表示)和最高的相对活跃程度(由半径长度表示)。
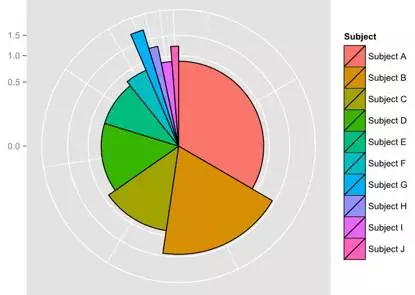
图4-玫瑰图。此图中各块面积表示文章数量,半径长短表示相对活跃指数(E列)。
第5步-将注意力引向关键信息
用肉眼衡量半径长度可能并不容易。由于在本例中,相对活跃指数的 1.0 代表此领域的全球活跃程度,我们可以通过给出 1.0 的参照值来引导读者,见图 5 。这样很容易看出哪些领域的半径超出参考线。
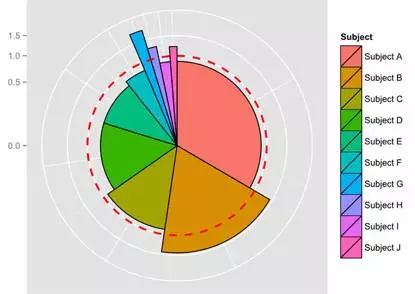
图5-带有相对活跃指数参考线的玫瑰图
我们还可以使用颜色帮助读者识别出版物最多的领域。如图例所示,一块的颜色深浅由出版物数量决定。为了便于识别,我们还可以把各领域名称作为标签(见图 6 )。
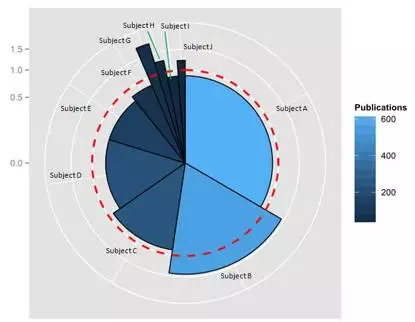
图6-玫瑰图中的颜色深浅代表出版物数量(颜色越亮,出版物越多)
结论
数据可视化的方法有很多。新的工具和图表类型不断出现,每种都试图创造出比之前更有吸引力、更有利于传播信息的图表。我们的建议是记住以下原则:可视化项目应该去总结关键信息并使之更清晰直白,而不应该令人困惑,或用大量的信息让读者的大脑超载。
原作者:Georgin Lau and Lei Pan
翻译:王鹏宇
via:Datartisan数据工匠
原文地址:http://www.36dsj.com/archives/39986






- 目前还没评论,等你发挥!








