
 起点课堂会员权益
起点课堂会员权益Pivot,信息组织的梦想之窗

以图像处理见长的微软Live实验室,最近发布了一款新作:Pivot。装完启动后的第一印象就是一款浏览器,和IE、FF、Chrome又不太一样的是,Pivot精致而华丽。但看安装要求: 256M的显存、Win7或Vista的系统、并且安装.NET Framework3.5和IE8,浏览器哪能需要这豪华的配置啊,去官网细看,果然另有名堂。Live实验室尝试提供一种更有效、更有力和更有趣的,与庞大互联网信息互动的全新方式。通常我们从网络中获取信息的方式是搜索-通过链接逐条浏览-通过浏览再获得相关的链接(相关文章、参考资料等等),直到获取自己需要的信息。而Pivot则提供了一种更为互动更为直观的信息浏览方式。
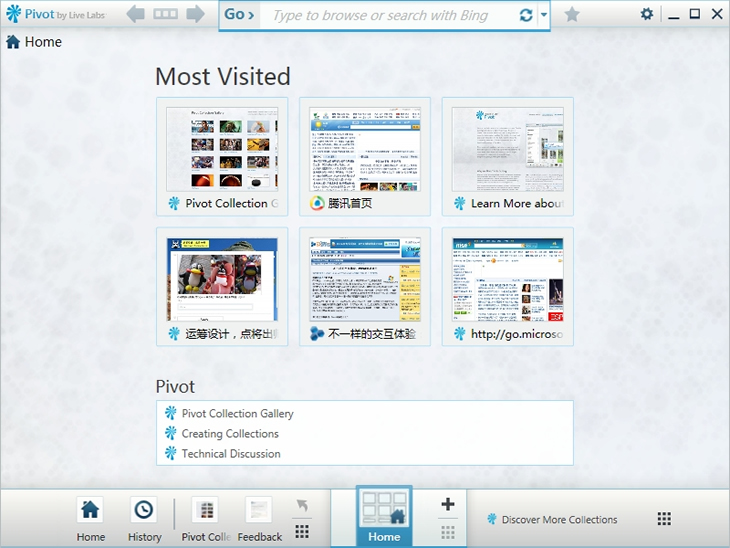
除了安装的时候需要邀请码、用起来有点卡不太爽之处,Pivot的整体体验非常不错,除了采用“深度缩放”技术带来的帅气的动画效果,界面本身的可视化也做的很极致。细看如下:
因为和普通的浏览器布局有些差异,所以在第一次使用时Pivot提供了一些引导,用于对各模块和功能做一说明:
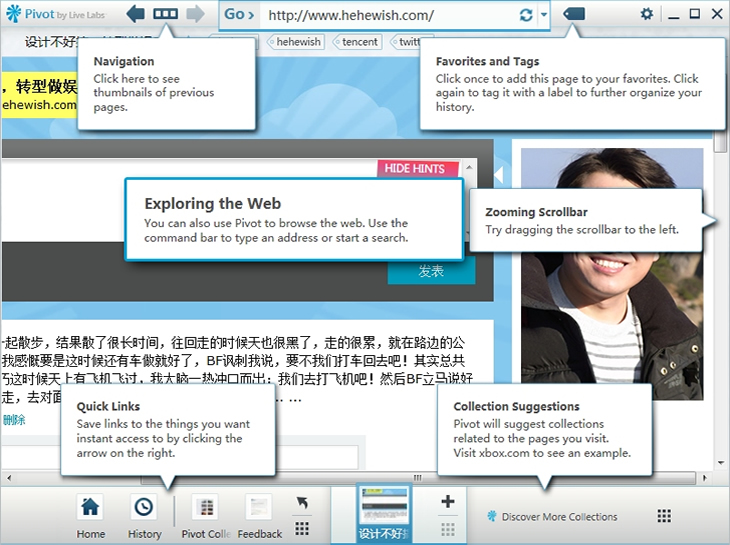
对页面的可视化处理,是Pivot的一大亮点。目前多页签浏览,都是通常页面标题来识别,这种有个弊端就是当打开很多个窗口时,识别性就是个很难处理的问题。在之前一期工作坊的,我们专门讨论了TT5.0浏览器页签工具栏的设计,以解决这个问题。
![]()
Pivot对这个难题的处理挺不错,尽管缩略图很小,但真正用起来发现对不同窗口识别还是很有帮助的,有图有真相:

可视化的设计理念伴随整个产品,随处可见:
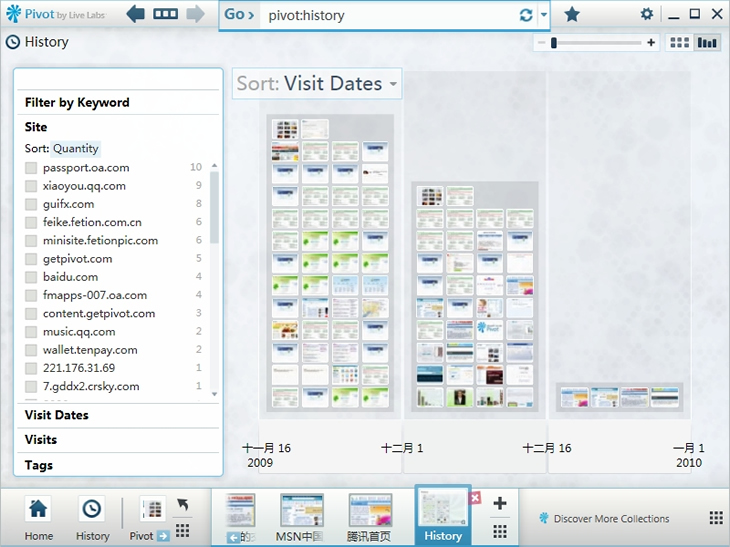
这是Pivot中历史记录的界面:
Pivot自带了一个Collections,里边列了很多和内容商合作提供的Collecitons。看Live实验室的说法,Colleciton是互联网上大量类似信息的集合,这也正是Pivot理念的体现:她将网络还原为“网络”(web)而非众多互相独立的页面:
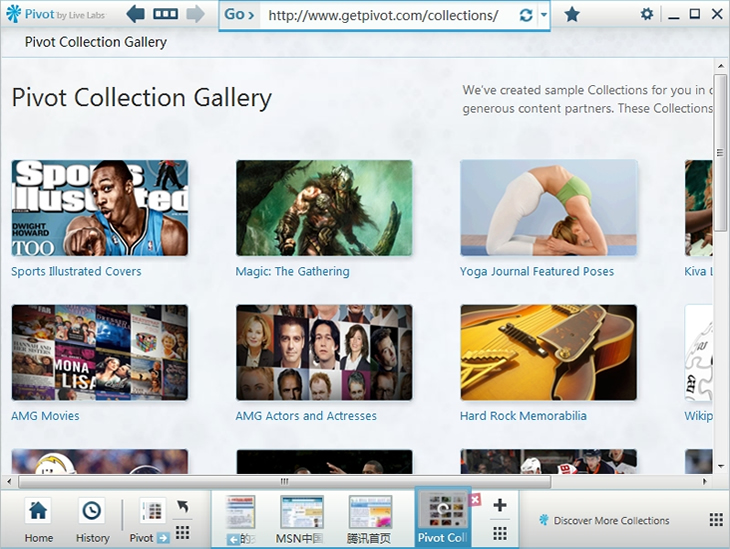
以上这俩个界面展现了Pivot最为核心的能力:先是海量信息,然后提供分类和很多维度(即对象的属性)来一步步过滤,从而快速定位到自己想找的内容。这种信息组织的方式,和Win7中“库”对文件的管理方式非常近似:一是提供快速的搜索,二是提供不同维度(即对象的属性)的筛选和分类:

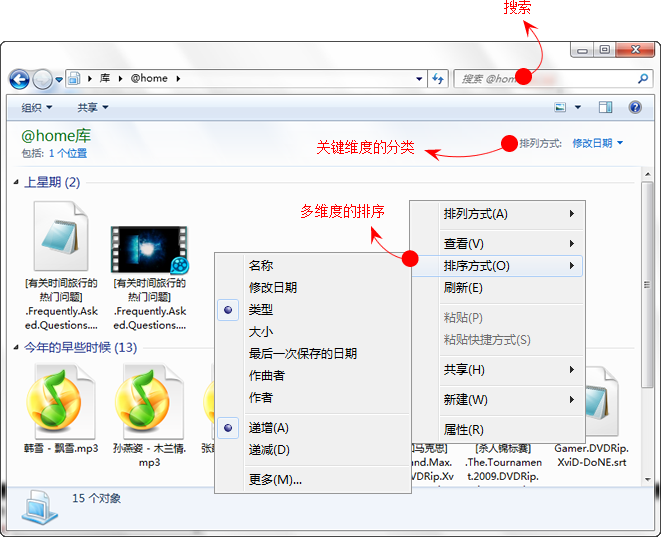
自Vista以来,Windows的搜索体验有了很大的改善,几乎和苹果的SpotLight相媲美。得益于元数据索引表的建立,搜索文件只需要查询索引表就可以给出结果,而不需要像XP一样慢吞吞的访问磁盘。而索引表中,除了我们熟知的属性,比如文件名、大小、日期外,还增加了作者姓名、图像大小、音乐风格、相机光圈等过百项有助于信息搜寻的元数据。
正是因为有众多元数据的支持,才使得“库”对Windows传统的树型文件管理方式带来了一种颠覆性的革新。在树型这样单一的信息组织方式下,管理文件不是件容易的事儿。例如现在需要找一份文件的话,就必须知道该文件的存放路径,否则只能靠搜索(在xp下的搜索体验让人很难容忍),我们需要的只是文件,但不得不记住存放路径这样的冗余信息。又或者我们刚刚看完王军写的一篇Word文档,然后想看看这人写的其它文档,类似这样只知道作者的需求,在传统的文件管理方式下是无法满足的。而在“库”里,我们只需要按作者分类,就能找到王军相关的所有文件。
这样来看“库“的功能要多树型的文件管理方式好用的多,应该会被很普及才对,而事实上到目前为止,”库“还只是Win7中一个仅仅被推荐的功能,和传统的文件管理方式完全不是一个级数。这是为什么呢?原因和06年微软力推的一个概念相关:WinFS。
WinFS是06年的明星,当时微软正在开发外界期望甚高的Vista,在名为“长牛角”的开发计划中,WinFS以一种革新的姿态出现,用于取代传统的文件管理方式。微软投入了巨量的精力,以期望在革新文件系统的过程中遵循以下三个原则:使用户能够“查找”、“关联”和“操作”他们的信息。查找不难理解,强调的是“快”和“准”。“关联”呢,就是指可以通过信息之前的关系找到彼此,就像刚说的找王军写的不同文档一样。而第三点“操作”,有点人工智能的意思。比如我正在开会,只带了手机。这时候收到一封部门经理的邮件,询问最近项目进展。WinFS会自动寻找系统中相应的应用向我发出通知(比如发个短信),收到消息后我想约经理半小时左右汇报此事。WinFS可以协助查看我们日程中空闲时段,自动创建会议。
以下是WinFS的宣传视频,很好的诠释了其核心理念:
在硬盘容量越来越大,电子数据奔涌而来的浪潮中,WinFS的出现无疑给我们带来了福音。可惜微软最终还是没能完成这一全新文件系统的开发,一方面近于Vista的上市期限压力,WinFS对硬件性能的要求始终无法优化到用户可以接受的地步,另一方面是信息类型的复杂度过高,所以微软不得不于06年6月26日宣布停止了WinFS的研发。
尽管只是昙花般在Vista的开发过程中一闪而过,但WinFS的理念却得以保存和继承。其中很多技术整合进到了ADO.net和SQL Server,Win7的“库”也觉得WinFS衣钵。还有微软刚发布的概念产品:Pivot。
相比之一Pivot中的“Collections”要比“库”管理文件更好用,原因在于“库”信息类似众多复杂,有文档、照片、电影、EXE程序等等,相应的关键属性虽然很多,但绝大部分都是空的,这些属性肯定也无法指望用户自己手动输入,所以用起来反就感觉不到关系型索引表带来的优势,相反Pivot的 “Collections”,内容由第三方提供,其中很多元数据可以被完整提供,比如“演员”分类中的出生年月、参演电影数量等等。这样筛选起来就非常高效了。
Pivot的理念,映射到腾讯的产品线,对涉及到资源管理和寻找类的产品有直接的参考意义。比如QQ音乐的乐库,QQLive的视频库,旋风的资源面板,甚至是QQ秀商城。因为这类的资源是官方提供,这样保证每个资源都配备结构化的元数据。
用Pivot的视角来看QQLive的视频库,先是罗列所有资源,然后通过众多维度不断过滤,最终筛选出自己想找的节目:

WinFS搁置, 微软以“库”的形式来继承WinFS的遗志,多少透着无奈。而概念作品Pivot的发布,可以感觉到微软在信息组织方式上的不断尝试和探索,而这种思路正在慢慢成熟,或许终有一天,它会成为我们浏览互联网的梦想之窗。
- (本文出自Tencent CDC Blog,转载时请注明出处)






- 目前还没评论,等你发挥!


