
 起点课堂会员权益
起点课堂会员权益译文|语音助手的替代:语音用户界面(VUI)
“语音助手”这一形式已经十分常见,它通常可以回答用户的某些问题,并为用户成功地答疑解惑。不过,语音助手虽然可以解决某些用户任务,但当任务的繁琐程度升高时,语音助手可发挥的余地便会受限。那么,可以用什么样的方式,来解决语音助手所存在的问题呢?

前言:语音助手是目前最流行的语音用户界面用例。然而,由于语音助理通过与用户交谈来提供反馈,因此语音助手只能解决简单的用户任务,例如设置闹钟或播放音乐。为了让语音用户界面真正取得突破,给用户的反馈必须是可视化的,而不是听觉的。
对大多数人来说,当想到语音用户界面时,首先想到的是语音助手,如Siri、Amazon Alexa或谷歌Assistant。事实上,语音助手是大多数人使用语音与计算机系统交互的唯一环境。
虽然语音助手将语音用户界面带到了主流,但助理范式不是使用、设计和创建语音用户界面的唯一方式,甚至不是最好的方式。
在本文中,笔者将讨论语音助手所面临的问题,并提出一种新的语音用户界面方法,我称之为直接语音交互。
一、语音助手是基于语音的聊天机器人
语音助手是一种使用自然语言代替图标和菜单作为用户界面的软件。语音助手通常回答用户的问题,并积极主动地为用户提供帮助。
语音助手与简单直接的处理事务和指令不同,而是模仿人类对话,并双向使用自然语言作为交互模式,这意味着它既接受用户的输入,又通过使用自然语言向用户回答。
第一批助手是基于对话的问答系统。一个早期的例子是微软的Clippy,它糟糕地试图帮助微软Office的用户,根据它认为用户想要完成的任务给出指令。而如今,助手范式的一个典型用例是聊天机器人,通常用于聊天讨论中担任客服。
另一方面,语音助手是使用语音而不是打字和文本的聊天机器人。用户的输入不是选择或文本,而是语音,系统的响应也是发声朗读出来。这些助手可以是通用助手,如谷歌助手或Alexa,可以合理地回答许多问题,也可以是为特殊目的而构建的定制助理,如快餐订购。
尽管用户的输入通常只有一两个词,并且可以作为选择选项而不是实际文本呈现,但随着技术的发展,人机对话将更加开放和复杂。聊天机器人和语音助手的第一个特性是使用自然语言以及对话风格,而不是典型的移动应用程序或网站用户体验的图标、菜单和交互风格。
自然语言反应的第二个决定性特征是表象人格的错觉。系统使用的语气、质量和语言定义了语音助手的体验、同理心和服务敏感性的错觉,以及它的人格角色。良好的助理体验的想法就像与一个真人打交道。
由于语音是我们最自然的交流方式,这听起来可能很棒,但使用自然语言响应有两个主要问题。其中一个问题与计算机如何模仿人类有关,可能会在未来随着对话式人工智能技术的发展得到解决,但人类大脑如何处理信息的问题是一个人类问题,在可预见的未来是无法解决的。下面让我们来看看这些问题。
二、自然语言响应的两个问题
语音用户界面当然是使用语音作为一种方式的用户界面。但语音模式可用于两个方向:从用户输入信息和从系统向用户输出信息。例如,一些电梯在用户按下按钮后使用语音合成来确认用户选择。我们稍后将讨论仅使用语音输入信息的语音用户界面,并使用传统的图形用户界面将信息显示回馈给用户。
另一方面,语音助手使用语音进行输入和输出。这种方法有两个主要问题:
问题1:模仿人类失败
作为人类,我们有一种天生的倾向,将类似人类的特征归因于非人类的物体。我们在飘过的云朵中看到一个人的容貌,或者看着一块三明治,它似乎在对我们笑。这被称为拟人化。
这种现象也适用于语音助手,它是由他们的自然语言反应触发的。虽然图形用户界面可以构建得有点中性,但人类不可能不开始思考某人的声音是属于年轻人还是老年人,或者他们是男性还是女性。因此,用户几乎开始认为助理确实是人类。
然而,我们人类非常擅长发现假货。奇怪的是,越接近人类的东西,这些微小的偏差就越开始困扰我们。对于那些试图变得像人类但却无法达到人类标准的东西,人们会有一种毛骨悚然的感觉。在机器人和计算机动画中,这被称为“恐怖谷效应”。
我们把语音助手做得越好、越人性化,当出现问题时,用户体验就会越令人毛骨悚然、令人失望。每个尝试过语音助手的人可能都无意中遇到过这样的问题: 回答一些让人感觉愚蠢甚至粗鲁的问题。
语音助手的恐怖谷效应给助手的用户体验带来了一个难以克服的质量问题。事实上,图灵测试(以著名数学家艾伦·图灵的名字命名)通过的条件是,当人类评估者展示两个代理之间的对话时,不能区分哪个是机器,哪个是人。到目前为止,从未有人工智能通过。
这意味着,助手范式为类人服务体验设定了一个永远无法实现的承诺,用户肯定会感到失望。成功的体验只会建立最终的失望,因为用户开始信任他们的类人助手。
问题2:顺序和缓慢的相互作用
语音助理的第二个问题是,自然语言响应的回合制性质导致交互延迟。这得归因于我们的大脑处理信息的方式。
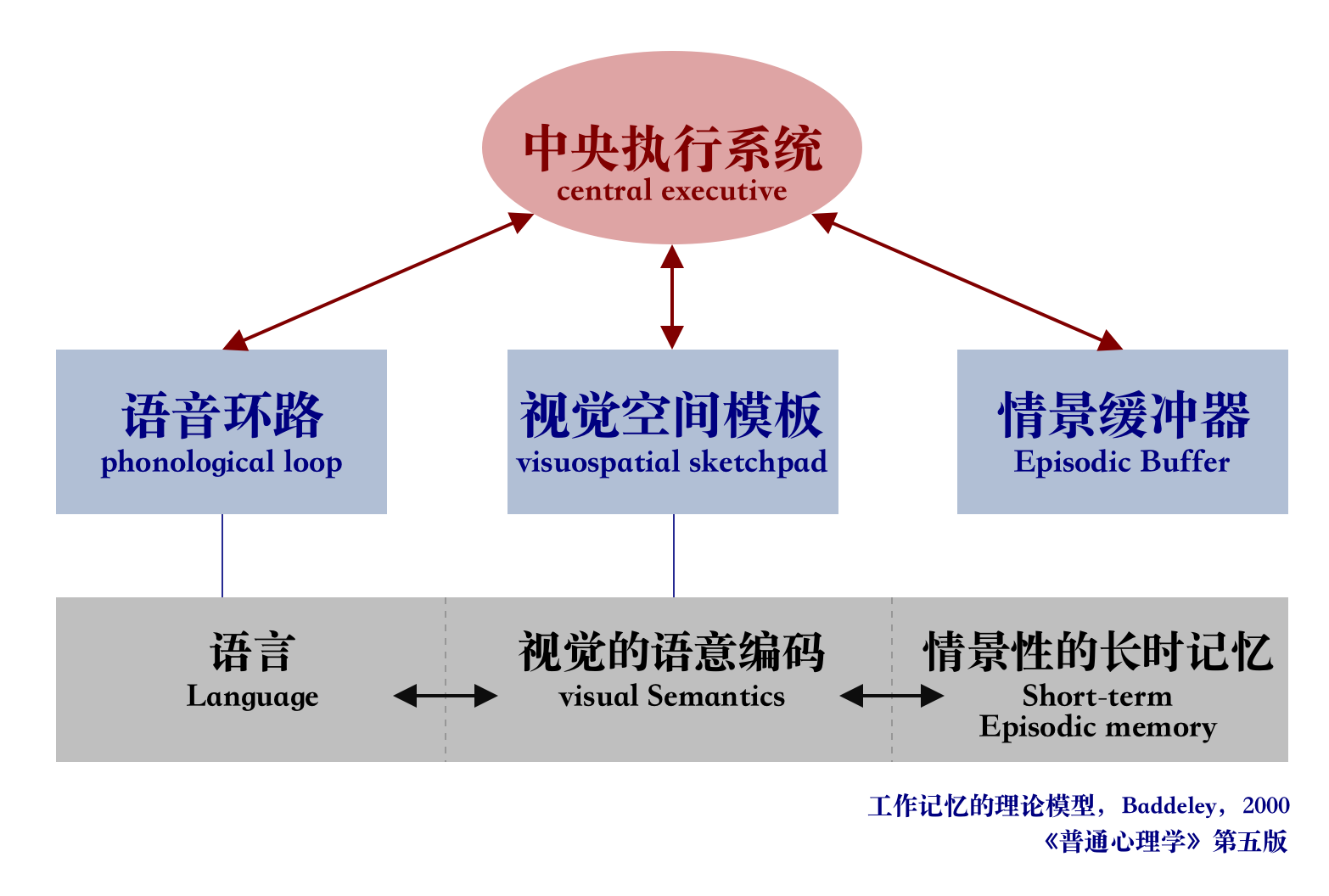
大脑中的信息处理。(资料来源:彭聃龄《普通心理学》)
我们的大脑中有两种类型的数据处理系统:
- 加工处理说话的语言系统;
- 专门加工处理视觉和空间信息的视觉空间系统。
这两个系统可以并行运行,但两个系统一次只处理一件事。这就是为什么你可以一边说话一边开车,但你不能一边发短信一边开车,因为这两种活动都会发生在视觉空间系统中。
同样,当你和语音助手交谈时,语音助手需要保持安静,反之亦然。这创造了一种回合制的对话,其中另一部分总是完全被动的。
然而,假想一个你想和朋友讨论的难题。你们可能会面对面讨论,而不是通过电话讨论,对吗?这是因为在面对面的对话中,我们使用非语言沟通来向对话伙伴提供实时的视觉反馈。这创建了一个双向信息交换循环,并使双方能够同时积极参与对话。
语音助手不会提供实时的视觉反馈。他们依靠一种称为终点测定的技术来决定用户何时停止说话,并在此之后回复。当他们回复时,他们不会同时接受用户的任何输入。体验完全是单向和回合制的。
在双向和实时面对面的对话中,双方可以立即对视觉和语言信号做出反应。这利用了人类大脑的不同信息处理系统,使对话变得更加顺畅和高效。
语音助手卡在单向模式下,因为他们同时使用自然语言作为输入和输出通道。虽然语音输入的速度是打字输入的四倍,但处理消化速度明显慢于阅读。由于信息需要按顺序处理,所以这种方法只适用于简单的命令,如“关灯”,这些命令不需要助手的太多输出。
在前文,我承诺讨论仅使用语音输入用户数据的语音用户界面。这种语音用户界面受益于语音用户界面的最佳部分——自然、快速和易于使用——但不受恐怖谷和顺序交互的影响。
让我们考虑一下这个替代方案。
三、语音助手的更好选择
克服语音助手中这些问题的解决方案是放弃自然语言响应,代之以实时视觉反馈。将反馈切换到视觉,将使用户能够同时提供和获得反馈。这将使应用程序能够在不中断用户的情况下做出反应,并启用双向信息流。由于信息流是双向的,其吞吐量更大。
目前,语音助手最常用的用例是设置闹钟、播放音乐、查看天气和询问简单的问题。所有这些都是低风险的任务,在失败时不会让用户太沮丧。
正如《华尔街日报》的大卫·皮尔斯曾经写道:
我无法想象通过语音助手预订航班或管理我的预算,或者通过对我的扬声器大喊食材配料来跟踪我的饮食。
——《华尔街日报》的大卫·皮尔斯
这些是信息密集型任务,需要正确处理。
然而,语音用户界面终会走向失败。关键是尽快解决这个问题。在键盘上打字时,甚至在面对面的对话中,都会出现很多错误。然而,这一点也不令人沮丧,因为用户只需单击退格并再次尝试或请求澄清即可恢复。
这种从错误中快速恢复的方式使用户能够提高效率,并且不会迫使他们与助手进行奇怪的对话。
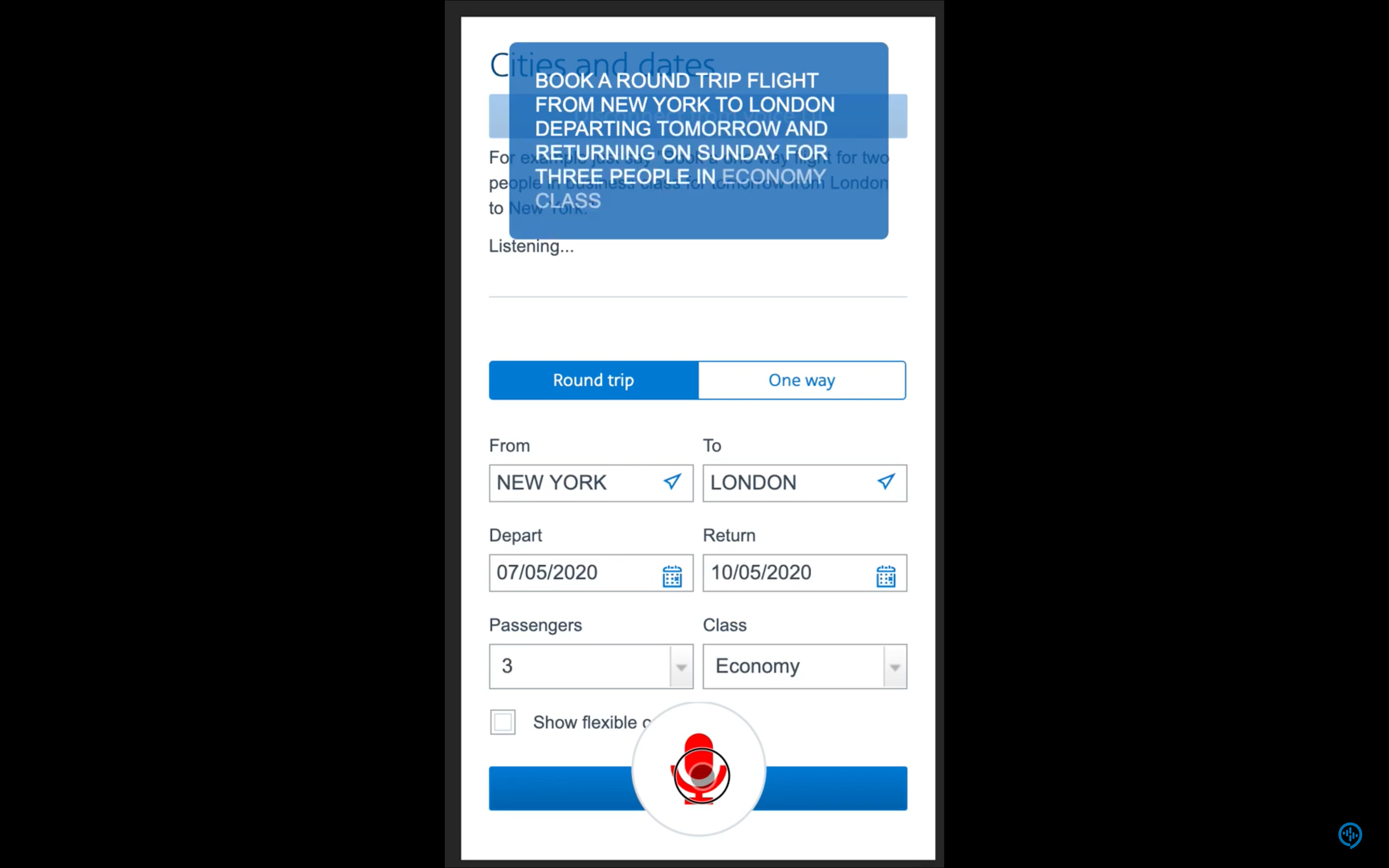
使用语音预订机票。
直接语音互动
在大多数应用程序中,操作是通过操作屏幕上的图形元素、戳或滑动(在触摸屏上)、单击鼠标和/键,或按下键盘上的按钮来执行的。语音输入可以作为操作这些图形元素的额外选项或模式添加。这种类型的互动可以称为直接语音交互。
直接语音交互和语音助手之间的区别在于,用户不是要求语音助理化身去执行任务,而是直接用语音操作图形用户界面。
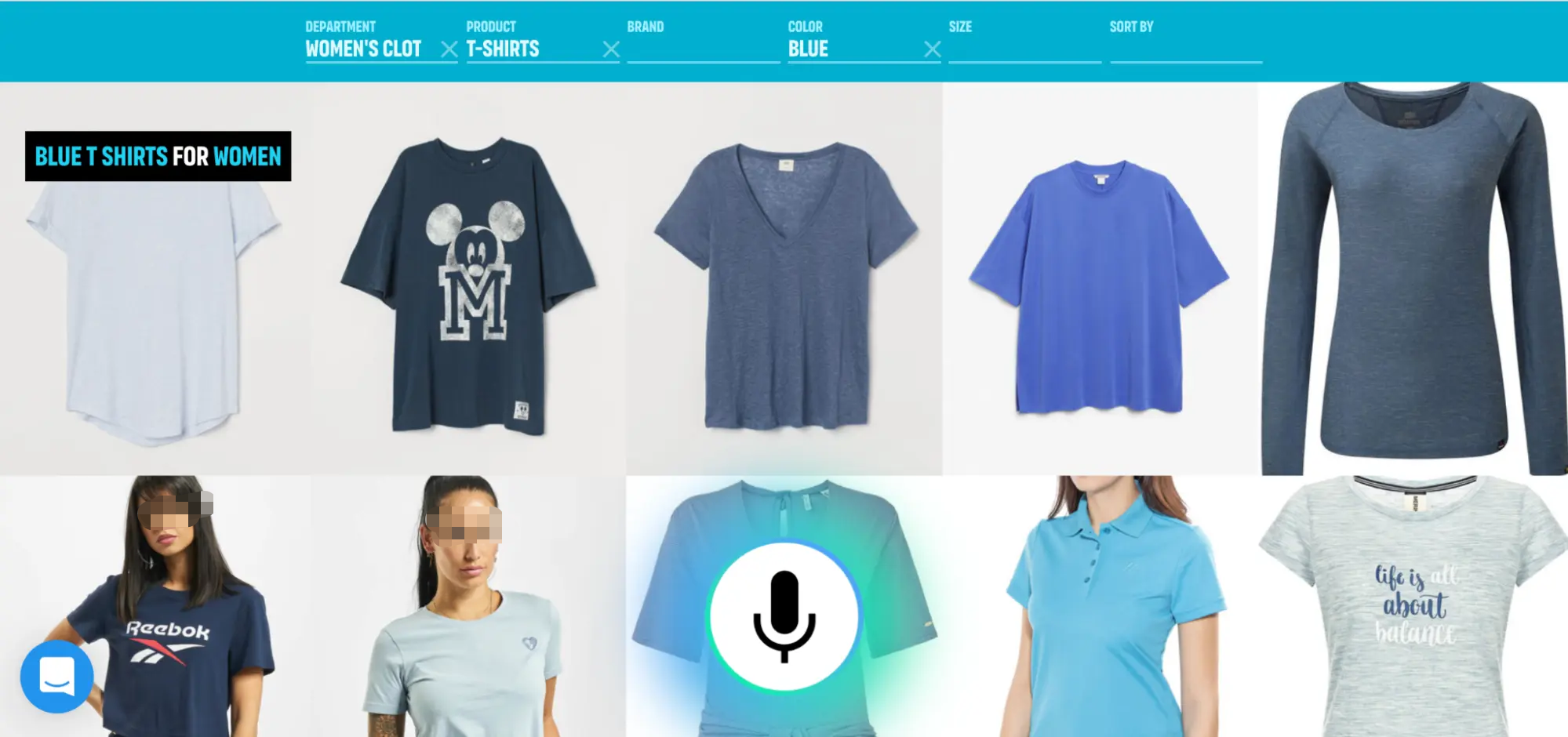
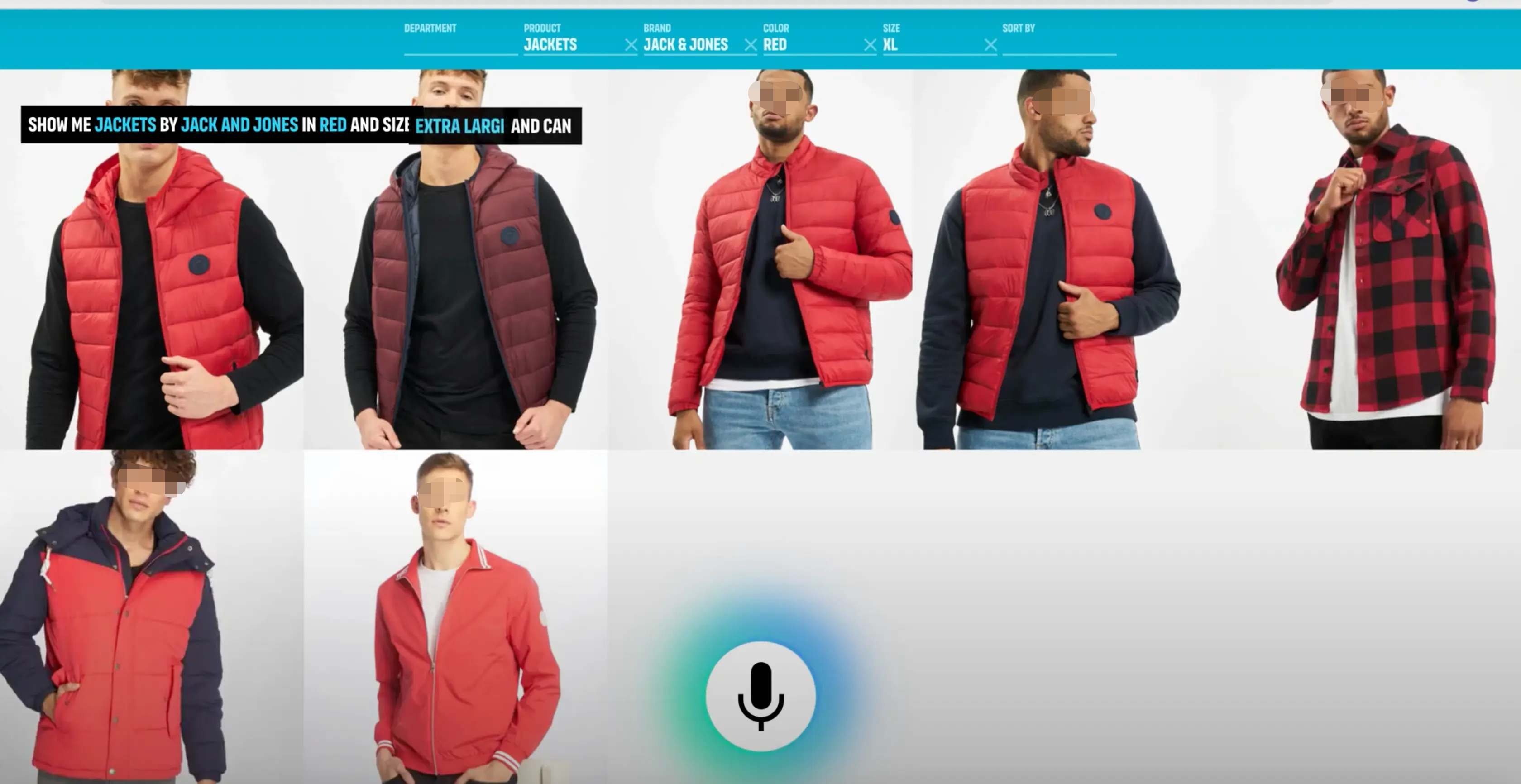
语音搜索在用户说话时提供实时视觉反馈。(图片来源:截图)
“这不是语义吗?”你可能会问。如果你要和电脑对话,你是直接和电脑对话还是通过虚拟角色对话真的重要吗?在这两种情况下,你只是在和电脑说话!
是的,差别很细微,但很关键。当单击GUI(图形用户界面)中的按钮或菜单项时,很明显,我们正在操作一台机器。人对此没有幻想。通过用语音指令代替点击,我们对人机交互做出了改进。而另一种,使用语音助手模式,我们正在创建一个人与人之间的互动的恶化版,所以,获得了恐怖谷效应。
而将语音功能与图形用户界面相结合,可能利用不同模式的力量。虽然用户可以使用语音操作应用程序,但他们也能够使用传统的图形界面。这使用户能够在触摸和语音之间无缝切换,并根据他们的上下文和任务选择最佳选项。
例如,语音是输入丰富信息的一种非常有效的方法。在几个有效的选项中选择,则触摸或单击可能更好。然后,用户可以通过说“向我展示明天从伦敦飞往纽约的航班”来代替打字输入和浏览,然后通过触摸从列表中选择最佳选项。
现在你可能会问:“好吧,这看起来很棒,那为什么我们以前没有见过这样的语音用户界面呢?为什么科技公司大厂不为这类事情开发工具呢?”
嗯,这可能有很多原因。一个原因是,当前的语音助手模式可能是他们从终端用户那里获得的数据的最佳方式。另一个原因与他们的语音技术构建方式有关。
良好的语音用户界面需要两个不同的部分:
- 将语音转换为文本的语音识别;
- 从文本中提取意义的自然语言理解组件。
第二部分是将“关掉客厅的灯”和“请把客厅的灯关掉”这两句话变成同样操作的魔法。
如果您曾经使用过带有显示器的语音助手(如Siri或谷歌 Assistant),你可能会注意到,你几乎是实时地获得文本记录,但在您停止说话后,系统需要几秒钟才能真正执行你所要求的操作。这是由于语音识别和自然语言理解是依次发生的。
让我们看看如何改变这一点。
四、实时口语理解:提高语音命令效率的秘诀
应用程序对用户输入的响应速度是影响应用程序总体用户体验的一个主要因素。第一代iPhone最重要的创新是它反应灵敏的触摸屏。语音用户界面对语音输入及时反应的能力同样重要。
为了在用户和用户界面之间建立快速的双向信息交换循环,每当用户说一些可操作的事情时,启用语音的GUI应该能够立即做出反应——即使是在句子中间。这需要一种称为流式口语理解的技术。
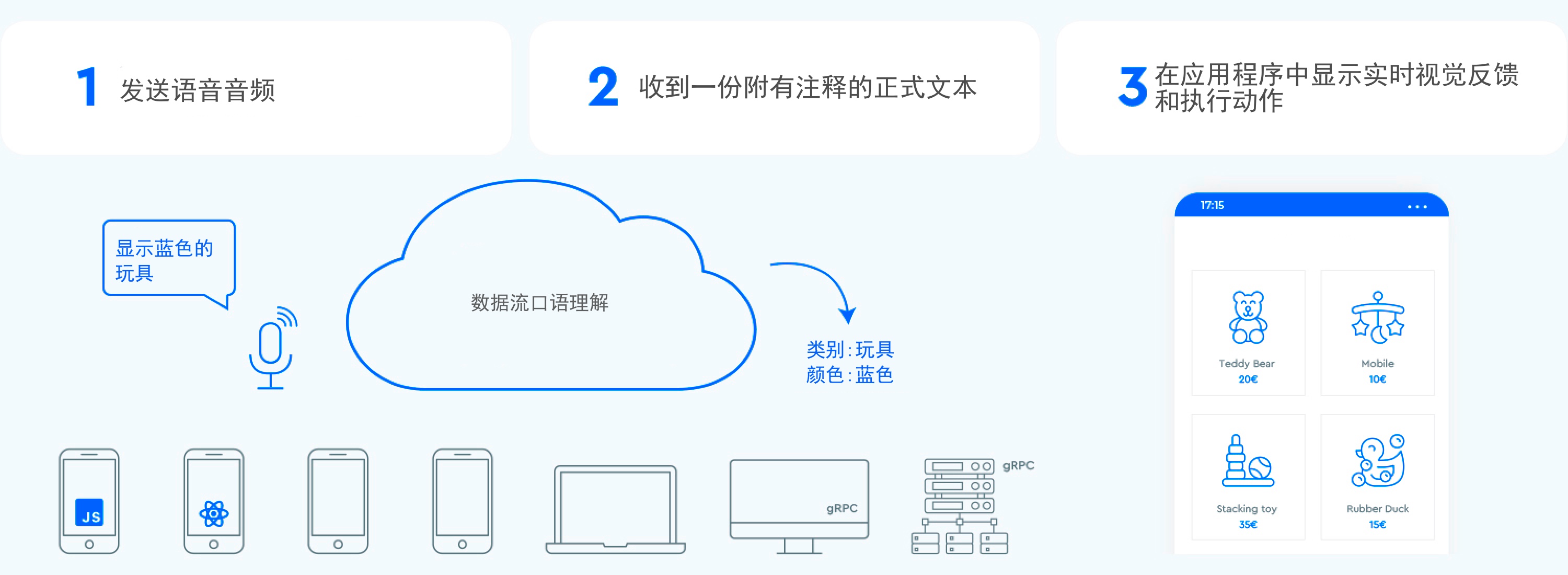
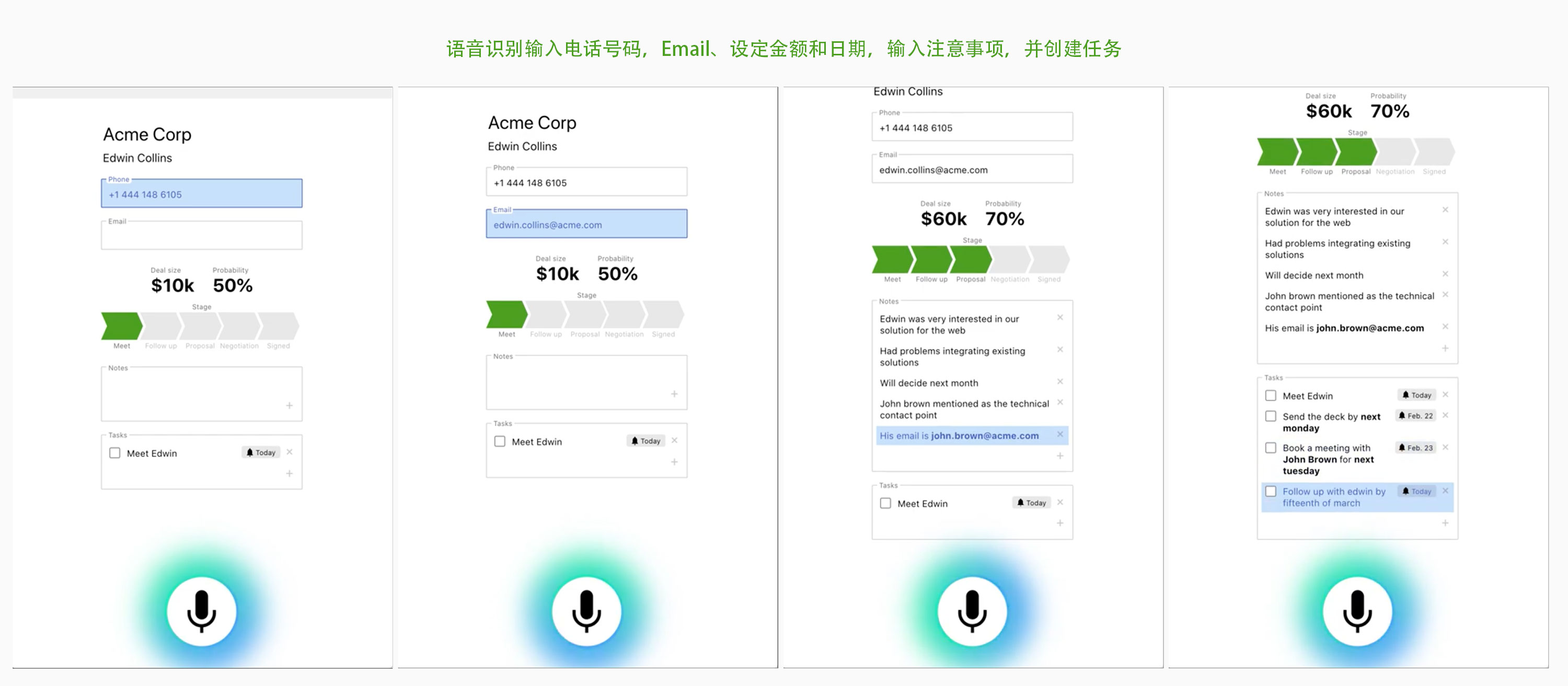
实时视觉反馈需要一个完全流式语音API,不仅可以实时返回对话记录,还可以实时返回用户意图和实体。(图片来源:作者)
传统的基于回合的语音助手系统在处理用户请求之前会等待用户停止说话,与之相反,使用流式语音理解的系统从用户开始说话的那一刻起就积极尝试理解用户意图。一旦用户说了一些可操作的事情,用户界面就会立即做出反应。
即时响应立即验证系统正在理解用户,并鼓励用户继续。这类似于人与人之间沟通中的点头或简短的“嗯”。这就能支持进行更长、更复杂的话语。另外,如果系统不理解用户或用户出现错误,即时反馈可以实现快速恢复。用户可以立即纠正并继续,甚至口头纠正自己:“我想要这个,不,我的意思是,我想要那个。”
实时视觉反馈使用户能够自然地纠正自己,并鼓励他们继续语音体验。由于他们不会被虚拟角色弄糊涂,它们可以以类似于错别字的方式与可能的错误联系起来,而不是个人侮辱。这种体验更快、更自然,因为提供给用户的信息不受每分钟约150字的典型语音速率的限制。
五、结论
虽然到目前为止,语音助手一直是语音用户界面最常用的用途,但使用自然语言响应使其效率低下且不自然。语音是输入信息的一种很好的方式,但听机器说话并不是直达人心。这是语音助手的大问题。
因此,语音的未来不应该在于与计算机的对话,而应该是用最自然的交流方式——语音,来取代繁琐的用户任务。直接语音交互可用于改善Web或移动应用程序中的表单填写体验,创建更好的搜索体验,以及实现更高效的应用程序控制或导航方式。
设计师和应用程序开发人员一直在寻找减少应用程序或网站摩擦的方法。使用语音模式增强当前的图形用户界面将使用户交互速度提高数倍,特别是在某些情况下,例如当终端用户在移动设备上和旅途中以及打字困难时。事实上,即使使用台式计算机,语音搜索也比传统的搜索过滤用户界面快五倍。
下次,当您考虑如何使应用程序中的特定用户任务更易于使用、更愉快或有兴趣增加转换时,请考虑是否可以用自然语言准确描述该用户任务。如果是,请使用语音模式补充您的用户界面,但不要强迫用户与计算机对话。
作者:Ottomatias Peura
原文:https://www.smashingmagazine.com/2021/06/alternative-voice-ui-voice-assistants/
本文由 @怡伶设计宝藏 翻译发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









很认真的看完了,受益