
 起点课堂会员权益
起点课堂会员权益定量研究:需要测试多少用户?

在收集可用性指标问题时,20 个用户的测试通常会提供相当可靠的置信区间。
我们可以根据质量指标定义可用性,例如学习时间、使用效率、可记忆性,用户错误和主观满意度等。可悲的是,因为这么做费用很高,很少有项目收集以上这些指标:收集这些指标需要测试的用户数是简单测试的 4 倍。
由于用户性能存在巨大的个体差异,因此需要测试许多用户。当你衡量人时,你总会得到一些非常快速的人和一些非常缓慢的人。鉴于此,你需要在相当多的观测值上对这些度量取均值,以平滑度量的可变性。
一、Web 可用性数据的标准偏差
从以前的分析中我们了解到,网站等产品上的用户表现遵循正态分布。这是值得高兴的,因为正态分布在统计上很容易处理。通过这两个数字——平均值和标准偏差——你就可以绘制表示数据的钟形曲线(正态分布曲线)。
我分析了 1520 个用户任务时间度量,它们来自 70 个官网和内联网相关的任务测试。在这些研究中,标准差为平均值的 52%。例如,如果某个人物的完成平均时间是 10 分钟,那么该指标的标准偏差为 5.2 分钟。
二、去除异常值
为了计算标准偏差,我首先删除了过慢用户的异常值。这是合理的吗?在某些方面,不是的:慢用户是真实存在,并且在评估设计质量时应该加以考虑的。因此,即使我建议从统计分析中删除异常值,你也不应该忽略它们。对异常值的测试会话进行定性分析,并找出降低性能的“坏运气”(例如:糟糕的设计)。
然而,对于大多数统计分析,都应该消除异常值。因为它们是随机发生的,所以在一项研究中可能会有更多的异常值,这些极端值会严重影响平均值和其他结论。
计算统计数据的唯一理由是将它们与其他统计数据进行比较。假设任务时间均值为 10 分钟,但 10 分钟好还是坏?你无法判断,因为这个数据是孤零零存在的,没有和其他数据进行比较。
如果要求用户订阅电子邮件,10 分钟的平均任务时间将会非常糟糕。从许多新闻订阅流程相关的研究中得知,其他网站的平均任务时间为 1 分钟,用户只需要不到 2 分钟就能满意。另一方面,10 分钟就表示用于更复杂任务的可用性非常高,例如申请抵押贷款。
关键在于收集可用性度量标准,将它们与其他可用性度量标准比较,例如将你的网站与竞争对手的网站进行比较,或将你新的设计与旧网站进行比较。
当从两个统计数据中消除异常值后,仍然会有有效的比较。如果留有异常值,两种情况下的平均任务时间都会显得高一些。但如果没有异常值,你更可能得出正确的结论,因为你不太可能高估平均值,而这个平均值恰好有更多的异常值。
三、估算误差的余量
当将来自正态分布的多个观测数据进行平均时,平均值的标准偏差(SD)是各个数值的 SD 除以观测数量的平方根。例如,如果有 10 个观察值,则平均值的 SD 为原始标准差的 1 / sqrt(10)= 0.316 倍。
![]()
我们知道,对于企业官网和内部网的用户测试,SD 是平均值的 52%。换句话说,如果测试了 10 个用户,那么平均值的 SD 将是平均值的 16%,因为 0.316 x 0.52 = 0.16。
假设我们正在测试需要 5 分钟才能完成的任务。那么,平均值的 SD 是 300 秒的 16% = 48 秒。对于正态分布,2/3 的例子与平均值相差 +/- 1 SD。因此,我们的平均水平将在 48 秒之内。
下图显示了测试不同用户数量时的误差幅度,假设需要 90% 的置信区间(蓝色曲线)。这意味着 90% 的可能性在此区间,5% 过低,5% 过高。对于实际的项目,确实不需要做得比这个更精准。
红色曲线显示了如果放宽要求到一半的时候会发生什么。(这意味着我们会在 1/4 时间内过低,而在 1/4 时间内过高。)
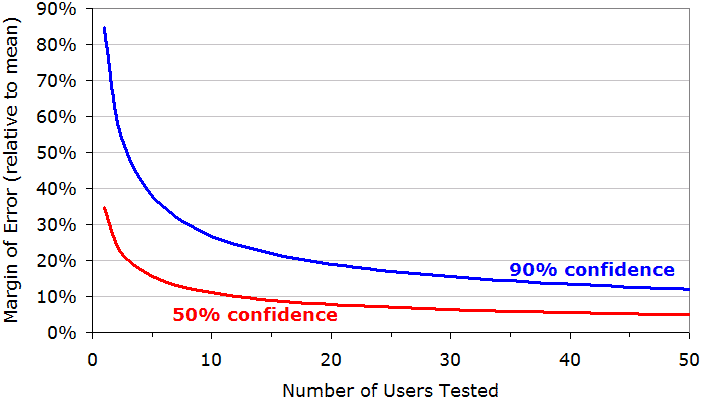
不同数量用户与误差范围大小
四、确定用户数量
在图表中,误差范围表示为可用性度量标准平均值的百分比。例如,如果测试 10 个用户,则误差范围则是平均值的 +/27%。这就是说如果平均任务时间是 300 秒(5 分钟),那么误差范围是 +/-81 秒。因此,置信区间就从 219 秒变为 381 秒:90%的可能性在此区间内; 5% 的低于 219,5% 的高于 381。
这是一个相当宽松的置信区间,同时,这也是为什么我建议在收集量化可用性指标时用 20 个用户进行测试的原因。对于 20 个用户,可能会有1个异常值(因为 6% 的用户是异常值),将平均覆盖 19 个用户数据。这使得置信区间从 243 变为 357 秒,因为测试 19 位用户的误差范围是 +/-19%。
你可能觉得这仍然是一个很宽松的置信区间,但事实上,要进一步收紧这个置信区间需要付出高昂的代价。要获得 +/-10% 的误差范围,需要 71 个用户数据,也就是说你必须测试 76 人来考虑 5 个可能的异常值。
从实际项目来看,测试 76 个用户是完全没必要的。每个设计测试 20 个用户,就可以获得 4 种不同设计的足够好的数据,而不仅是为了更好的指标,将预算用户单个设计测试。
实际上,对于大多数情况来说,+/-19% 的置信区间就足够了。主要是,要比较两种设计,看哪一种更好。毕竟,网站之间的平均差异是 68% ——这远高于误差范围。
另外,请记住 +/-19% 几乎是最坏的情况;90% 的机会你会做得更好。红色曲线显示,如果使用 20 个用户进行测试并分析 19 个数据,则其中一半可能性在平均值的 +/-8% 范围内。换句话说,一半的可能性获得了较好的精准度,另一半获得十分高的精准度。这就是非学术项目所需要的。
五、定量与定性
基于以上分析,我建议在做 20 个用户的定量研究测试。这非常贵,因为很难找到符合目标用户群的测试用户。
幸运的是,你不必衡量可用性从而改进它。通常,只需少量用户就可以进行测试,并根据对其行为的定性分析所发现的问题来修改设计。当你看到有几个人被同样的问题所困扰时,你并不需要了解用户被影响到了什么程度。如果它正在(或者已经)伤害了用户,那就有必要调整或者改进的必要。
通常可以对 5 个用户进行定性研究,不过定量研究的费用大致为定性的 4 倍。此外,定量研究很容易出错并产生误导性数据。当你收集数据而不是见解时,一切都必须十分精确,否则就做不好定量研究。
由于价格昂贵且难以正确运用,通常会特别谨慎的使用定量研究。我十分建议,你做的前几个可用性研究最好是定性的。只有经常做可用性研究,并且将研究结果与实际结合运用并取得实质性的进展后,才能开始在研究中使用一些定量研究。
#专栏作家#
郑几块,人人都是产品经理专栏作家,前新浪微博产品经理。
本文系作者@郑几块 独家翻译授权,未经本站许可,不得转载
题图来自 Pexels,基于 CC0 协议









挺复杂的 ➡