
 起点课堂会员权益
起点课堂会员权益用户画像无头绪?手把手教你RFM模型
在一些营销场景下,对不同客户给予相同的对待或策略有时不太合适,所以我们根据用户数据,分析用户行为和消费倾向,并打上相应的标签应用于不同厂家。用有限的公司资源优先服务于公司最重要的客户,客户与我们的粘性将会更高,并与双方建立忠诚的合作关系。

用户画像:
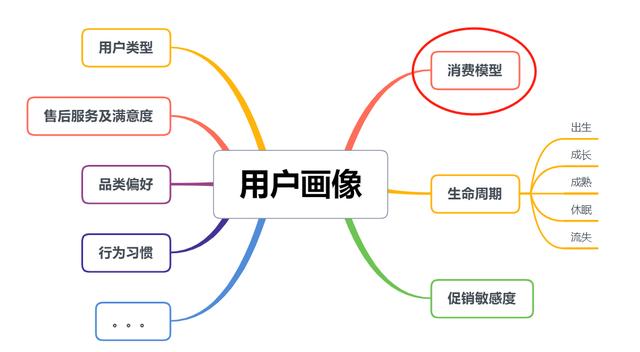
在第一阶段,我们基于RFM模型做用户消费分析,并定义一些指标。
- 最近一次消费(Recency)
- 消费频率(Frequency)
- 消费金额(Monetary)
数据集
- 我们选择2019/03/03 到 2020/03/01一整年53周的数据作为我们的数据分析数据集。
- 数据集包含总共10000个付费用户,总销售额¥1000 M。 (数据已脱敏)
- 我们使用GMV作为销售分析指标,退货部分将在后续另做分析。
数据的选取我们通过HIVE在数据库中选取,其中稍难的地方在于 最近一次购买——需要用到窗口函数 over (partition by xx) 的方法,疑问的同学可以去搜索下,后续我也会出SQL的一些常用方法和心得体会。
最近一次消费(Recency)
我们认为用户的最近一次消费行为离今日越近,他当前的活跃度将会更高,价值也会更高。
因为数据集对应的是TO_B的业务,所以我们此处定义用户如果在周内有消费行为且销售额大于最低阈值,该用户被标记为该周活跃。
我们这边用Tableau进行可视化分析:
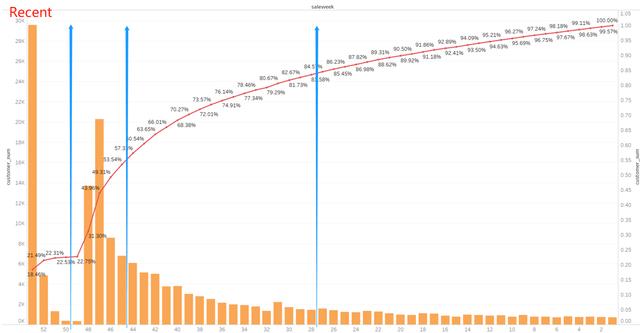
二月份过年且受到新冠状病毒疫情影响,数据下跌显著。
我们根据用户不同Recency在销售额上的数据表现,将用户合理分为四个组。
这边需要提一下,分箱是一个很复杂的点。有的业务人员或者是初学者随手等额/等距分箱,或者无脑“二八法则”,不管是从业务分析的角度还是投入模型的角度,效果可能都极差。
根据我们的分箱,分组表现如下:
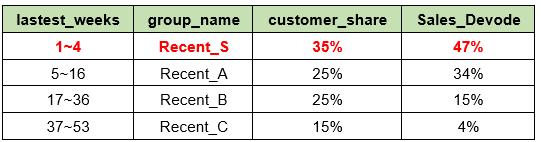
超过85%的用户在最近半年至少消费一次。
用户最近一次消费在距今1~4周的用户数量占比为10%,但提供了将近50%的销售额。
最近一次购买距今超过9个月的用户几乎不产生消费。
这表示Recent_C组的用户已经很有可能将要离开或者已经离开我们了。当然他们有被激活的机会,但是也许不应该花费过多,因为这个群组客户的投资汇报(ROI)相对较低,也就是说 不同的两个组,投入相同的有效资源,高ROI的群组大概率会产生更高的回报。
消费频率(Frequency)
如果用户有任何购买行为,并且订单金额超过一个基础阈值,他们这周就会被标记为活跃用户。我们认为用户的购买行为越频繁,他就会有更高的活跃度和交易价值。
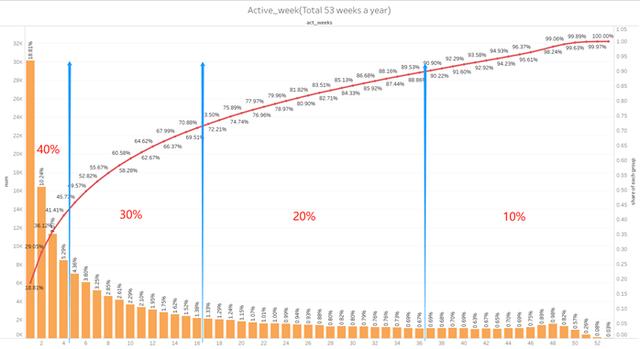
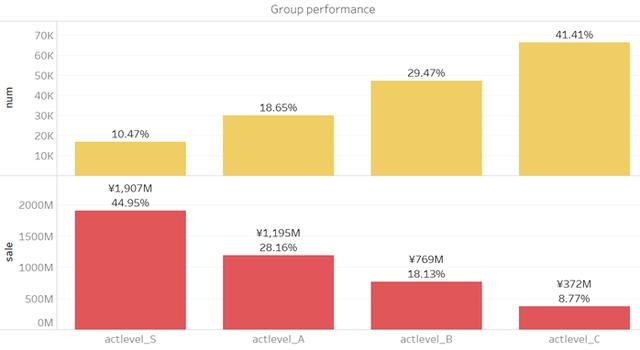
分组表现如下:
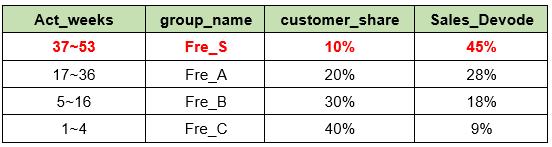
很明显,Fre_S级组别用户最有价值。他们以10%的数量占比贡献了45%的销售额。
消费金额(Monetary)
消费金额一直是商业中的核心指标。这边可以根据需求差异使用销售额,实际毛利等。
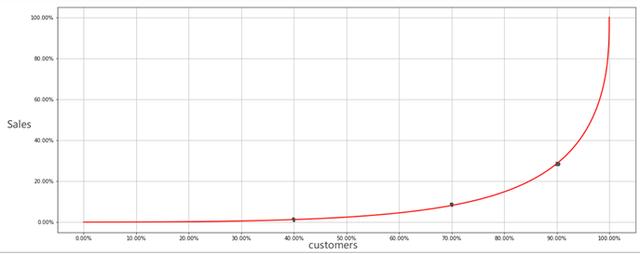
这边单变量分箱我们采用Python模块绘图
分箱边界及表现如下——
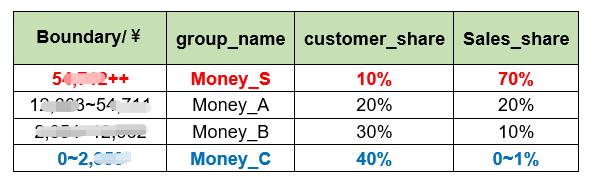
后40%的用户几乎不提供任何消费收益。
而Money_S组客户只占总体的10%,它贡献了总体70%的销售额。但其实进入S组的门槛并不太高,年销售额超过¥xxxxx,已经可以加入消费S组。
这边我们可以提供一个应用场景:会员升级 你的老板让你测算用户升级对整体销售提升的效果。
基于M_part的用户升级测算
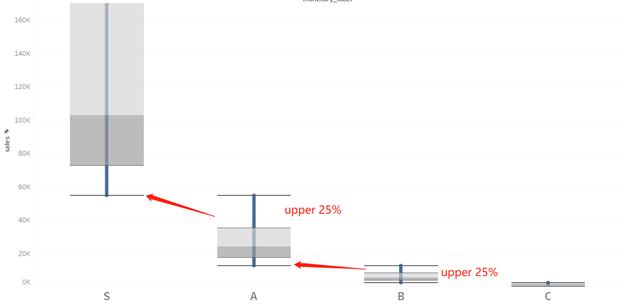
事实上,用户的层级相对来说不是那么容易去改变。另一方面来说,通过有效的策略促进用户升级成功,会对带来巨大的业务增长。
我的测算基于如下思维逻辑——每个群组的头部用户更有机会升级到下一个群组的尾部,举例 C组前25%消费排名用户会有机会加入B组的尾部,B组前25%消费排名用户会有机会加入A组的尾部。

B组头部 → A组尾部 的升级 客户只需要提高消费¥2000每年,所以只需要采取一些策略很容易就可以实现这个目标。所以我赋予这层的转化率是80%,而最后能够得到¥23M的收益。
A组头部 → S组尾部 的升级 客户需要提高消费¥11000,难度提高,所以我赋予这层的转化率是50%,而最后能够得到¥43.5M的收益。
仅仅通过这两个可行度较高的部分就可以增加66.6M的销售提升,而所需的成本很可能就是一些积分,头衔等。但是如果需要提升更高的销售额,那可能需要与客户分享一部分收益。
自然还有A级中部用户升级为头部用户,S级底部用户升级为中部用户…还有活跃部分R和F都可以做很多的提升策略,用户一直是很大的宝藏。
RFM
通过上述分析,我们得到三个简单标签——最近一次消费,消费频次,消费金额。
很多分析者喜欢一上来就把三者赋予对应权重,合并计算出一个得分,确实有可取的场景。但其实每一个标签不是为了单个分析报告或者业务活动服务进行的一次性分析。主要还是作为数据资产,以用户标签库的形式,随取随用,服务于各个业务及分析场景。
这边我们将三者联合:

我们可以看到各个标签下用户的表现然后结合具体业务目的分析。
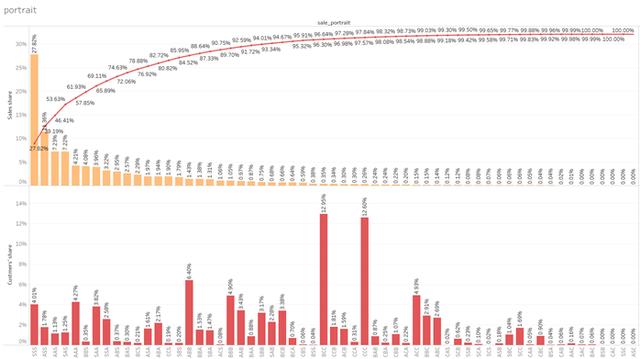
我们选择三个重要标签组来演示:
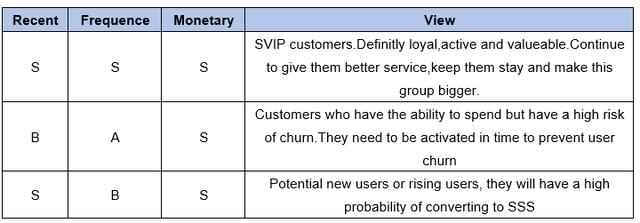
同样,我们可以给每个标签内的组别赋予相应的分值,再对每个标签给定相应地权重,来计算出一个总体得分。
两个应用场景
(1)如果我们举办一个营销活动关于老客户的促销,我们赋予 R 30%的权重 F 30%的权重 M 40%的权重。
用每个用户所在组别对应的分值 X 标签权重 求和 可以得到用户的得分 优先筛选合适分段用户即可。
(2)如果我们要办一个流失用户召回的活动,我们就可以直接选择R标签中的 Recent_C 或更久没有消费的用户,同时他的M得分很高,就可以获得更易召回的目标用户。
最后
这些标签在面对不同的业务环境是会有很多的应用场景,同时他们也可以与更多的标签和数据结合,关联分析来产生更高的业务价值。
不要忽略时间,地区的差异性。不同的地区的用户有着不同的消费水平,我们可以结合具体业务场景分别讨论。
本报告完全基于个人实际工作,尽量详细。不清楚的地方和其他想了解探讨的方向,欢迎留言。如首图,后续会更新更多的用户画像的分析报告与实际应用方法。
作者:范十八,公众号:半仙范十八
本文由 @小春ex 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议










“用户最近一次消费在距今1~4周的用户数量占比为10%,但提供了将近50%的销售额。”这个话是不是有错误,从表里看,1~4周的用户数量占比是35%
感谢指正
前辈说的通过聚类来确定是指的用机器学习的聚类算法?能不能举个稍微具体的例子呢
是的。
有的地方运营部门也会通过业务经验来分群用户。
还有怎么确定分层边界呢
了解了解聚类 各层级表现出明显的差异以及集聚性的特征
前辈能具体讲讲么怎么对不同用户做哪些活动来刺激消费增长
关键是不断弄清楚 他现在是什么人 他此时需要企业提供什么样的价值 再辅助以人性的弱点
能具体讲讲方法么?比如怎么提升到下一层级
“分箱是一个很复杂的点。有的业务人员或者是初学者随手等额/等距分箱,或者无脑“二八法则”,不管是从业务分析的角度还是投入模型的角度,效果可能都极差。”
这句话很赞同,请问您一般是用什么方法做用户分层呢?
同问
主要看你要分箱的变量定义的用户在目标变量(或者说核心指标)上的差异化分组表现。这边可以有聚类的思想在里面,可以品品~