
 起点课堂会员权益
起点课堂会员权益
移动APP可用性测试:数据的量化处理(下)
 产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。
产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。
作为一名用户研究从业者,想找到一本真正可以用来指导实践的资料却是十分难得。本文是继《移动APP可用性测试(上篇):实验室测试与现场测试对比》后的第二篇《量化研究》,主要和大家来聊一聊,拿到可用性测试数据后的量化方式。综合上下两篇文章的主旨来看,解答了如何科学地选择测试场地、如何量化可用性测试结果的两个“冷门问题”。
量化数据
用户研究从业者常常在做可用性测试的时候碰到这样的问题,可用性测试作为一种定性的研究方法,拿到完成率、完成时间以及满意度等结果时是简单做下描述性统计分析(毕竟我们称之为定性),还是可以进一步量化、标准化比较呢?
不是所有的数据都可以拿来量化,这取决于这是哪一种可用性测试。
美国教育家和心理学家Scriven(1967)曾将用来测试学习成果的考试分为两类,一类是Formative test即形成性测试,目的是通过及时的反馈来改进学习(例如随堂听写);另一类是Summative testF即总结性测试,目的是通过测试成绩来评估学习的效果(例如期末考试)。
那么,可用性测试如果也分为形成性测试和总结性测试的话,结果会有什么差异吗?
形成性测试
大部分的可用性测试都是形成性测试,以查找和修复可用性问题为目的,数据也是以问题描述和设计建议的形式来输出。这时候的量化一般仅以问题发生频率和严重等级为代表,任务完成率、完成时间因没有可对比性,所以只做描述性分析。
总结性测试
而总结性测试既然目的是用数据指标去度量一个应用程序的可用性,那么这个指标必然需要一个可以比较的对象,不然又如何去评价这个指标代表的可用性到底是好还是坏。如果以“比较的对象”来划分,总结性测试则又可以分为“基准测试”和“比较测试”。
(1)基准可用性测试
基准可用性测试的目标是描述一个应用程序相对于基准目标的可用性程度(如用你的每门期末考试的成绩去和之前预定的目标成绩进行比较),那么这也就提供了改善产品修复问题的着力点(哪门课没达到预期目标就重点复习),同时为比较改善后的效果提供了基线(重点复习后下次考试是否达到目标)。
(2)比较可用性测试
比较可用性测试,一般设计两个及以上的应用程序进行比较。可以是当前版本与前期旧版本的比较,或者是竞品之间的比较。如果去设计一场比较可用性测试你需要考虑清楚是“被试内测试”(相同的用户完成所有产品的任务)还是“被试间测试”(不同的用户分别完成不同产品的任务)。
- 被试内测试:在用户数较少(或能够给予的酬金有限,无法邀请多人参与)时可以考虑让每个用户分别去完成各款产品的测试,但是必须要切记不能让所有用户在每个产品上的先后顺序保持一致(打破顺序效应)。
- 被试间测试:在用户数充足时可以考虑每款产品分别找不同的用户进行测试,但是这里需要注意的则是必须保证每款产品间的用户个体差异不大(即有相似的年龄、性别、学习经历、竞品使用经历),如果需要在每组内划分为新手用户、中间用户、专家用户,则须保证各组中三类角色的人数占比一致。

数据统计
虽然对如何测量有效性、效率和满意度没有具体的指导方针,但Sauro and Lewis在一项针对近100个总结性可用性测试的调研揭示了从业者收集的典型数据。大多数的测试包含任务完成率(失败率)、任务时间、主观评价、寻求帮助的次数、可用性问题清单(通常包括问题频次和严重等级)。
本文主要就以上几个指标的量化处理进行介绍,更多可用性测试中收集测量指标的实操技巧,请参见《A Practical Guide to Measuring Usability》(Sauro,2010)和《Measuring the User Experience》(Tullis andAlbert,2008)。
任务完成率
(1)定义
也称为成功率,是最基础的可用性测量指标(Nielsen,2001)。
(2)计算
通常以二进制测量形式采集,以任务成功完成以编码1、失败为编码0。
注:二进制完成率即是基础可用性度量指标,也是应用到所有科学领域的度量指标。
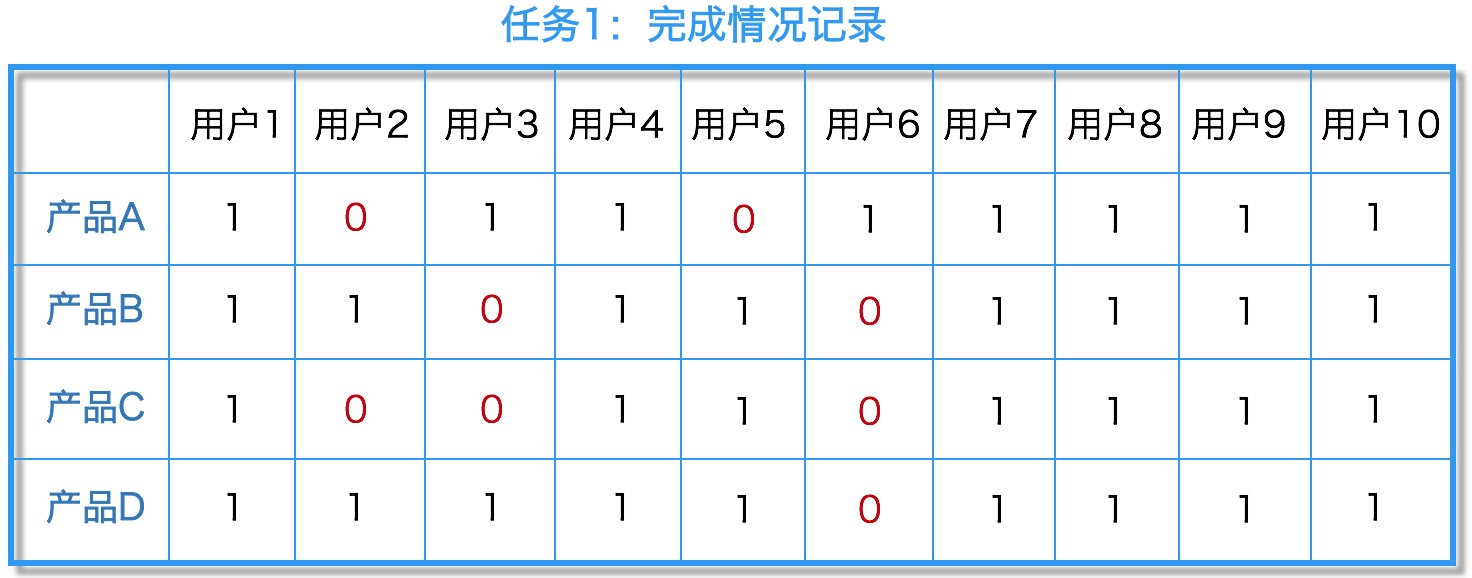

(3)置信区间
虽然我们计算出A产品任务1的完成率为80%(10个人中有8人完成)但是我们却没有办法保证当样本数量为几百人、几千人,甚至当我们有上万用户在使用这个功能时,完成率还会是80%。
如果想要知道在未知的用户总数中能够完成该任务的比例范围,我们需要在这一样本范围上计算出一个二项式的置信区间。Wald校正区间二项式置信区间是最常用的方法,对于任何一种被编为二进制码的测试都适用。并且除完成率外,另一种衡量可用性的常用方法是统计遇到了同一问题的用户数。在使用Wald校正区间公式时,如果3/5的用户遇到了UI设计上的一个问题,那么我们可以95%的肯定,所有实际用户中23%-88%比例的人可能遇到了同样的问题。
任务完成时间
(1)定义
即用户花费在一个任务上的时间,通常为成功完成一个预先设置的任务场景的时间总和。测量和分析任务持续时间的方式一般有三种:
- 任务完成时间:用户成功完成任务的时间;
- 直到用户失败为止所用的时间:从开始直到用户放弃或者未正确完成任务的时间;
- 任务总时间:用户花费在一个任务上的总持续时间。
(2)测量单位
可以是毫秒、秒、分钟、小时、天或年,通常以均值(算术平均数或中位数,两者适用场景不同)。
(3)算术平均数 VS 中位数
到目前为止,我们最常用的是将算术平均数作为衡量集中趋势和等级量表的平均数代表,但是当样本分布呈现为左偏态和右偏态时,中位数明显要比算术平均数更加合适(当为正太分布时中位数与算术平均数相近)。这样说来,是否以后都用中位数来报告平均任务时长就万事大吉了?答案是NO,别忘记了中位数与生俱来的两大缺点:变异性与偏差。关于中位数的变异性与偏差有疑问的同学可查资料或者后台留言哦,篇幅关系这里就不拓展解释了。
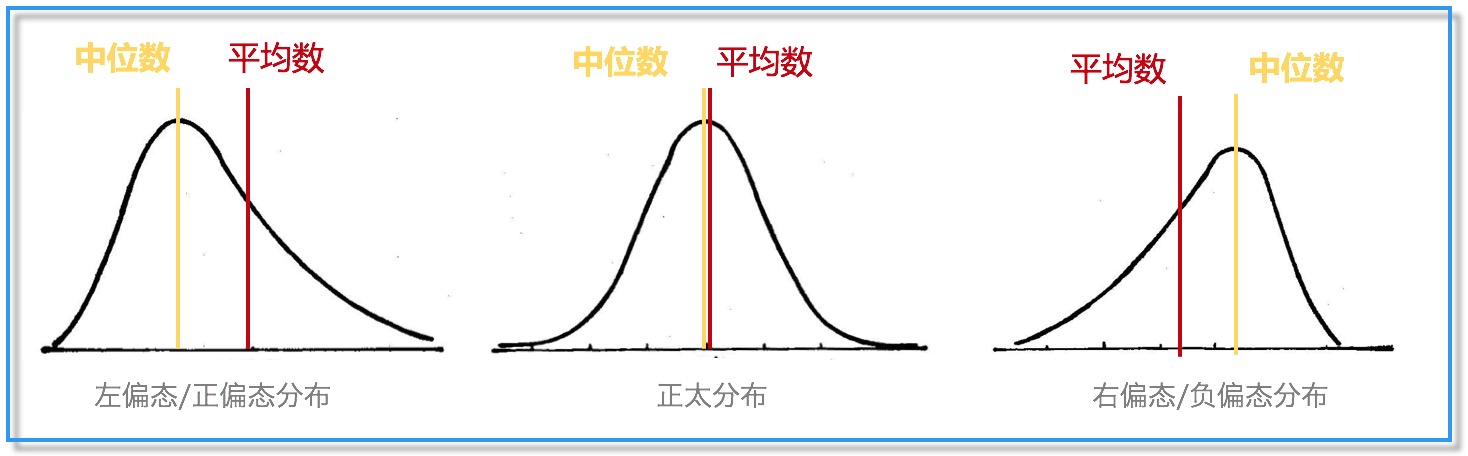
(4)几何均值的计算方法
对于小样本而言(小于25人),几何均值比中位数、算术平均数都更适用(Sauro and Lewis,2010)。对于样本量更大的可用性测试而言,中位数则是最合适的估算方法。计算几何均值,首先要将原始任务时长数据进行对数转换,然后计算所得到转化值的平均数,最后再将其转化回原尺度。工具上可以用Excel函数=LN( )进行对数转换运算,或者使用大多数计算器上都有的“ln”按钮。
满意度评分
(1)定义
即用户使用系统时感知到的主观评价,可在完成一项任务之后立即完成(任务评估问卷),也可以一系列可用性环节结束后完成(整体评估问卷),更可以独立于可用性测试使用。

(2)测量工具
虽然可以自己编写感知易用性的问题,但采用当前可使用的标准化问卷,评估结果会更加可靠。对用研来说标准化问卷是最熟悉的工具与助手,这类可重复使用的问卷,一般由一组特定的问题+使用特定的格式+按照特定的顺序呈现,基于用户的答案产生度量值后也用特地的方法进行统计。基于不同的研究对象和目的,可选用的标准化问卷也不尽相同,所有的标准化问卷都有其优点和缺点,每种问卷都或许在你特定的情况下是最合适的。
常见标准化量表:
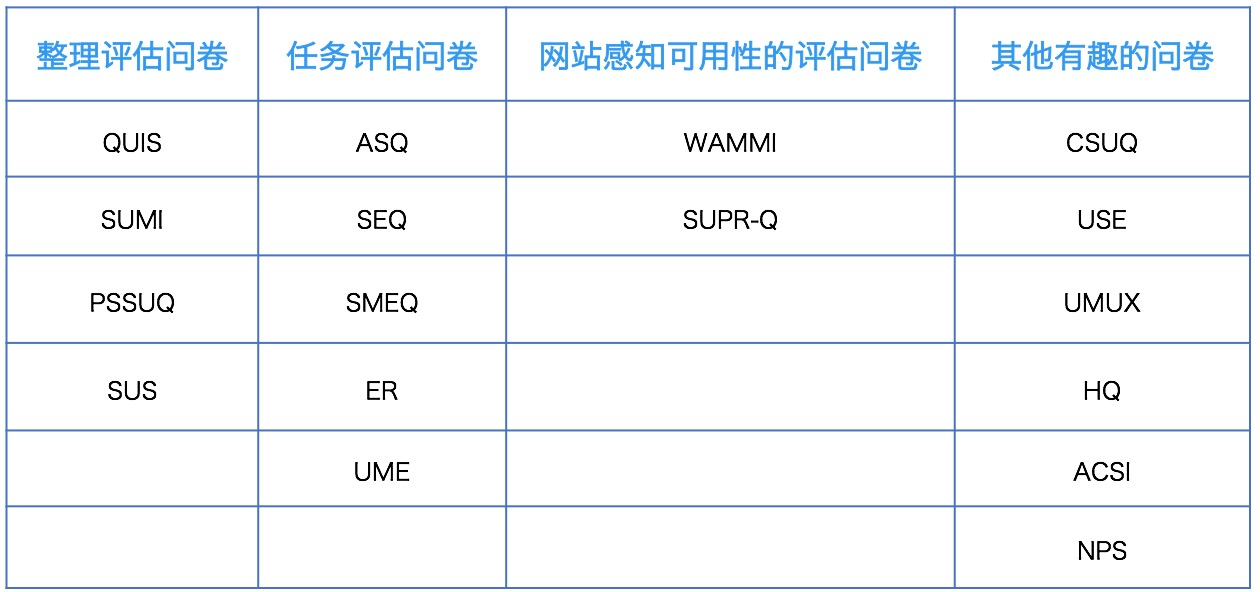
(3)比较方法
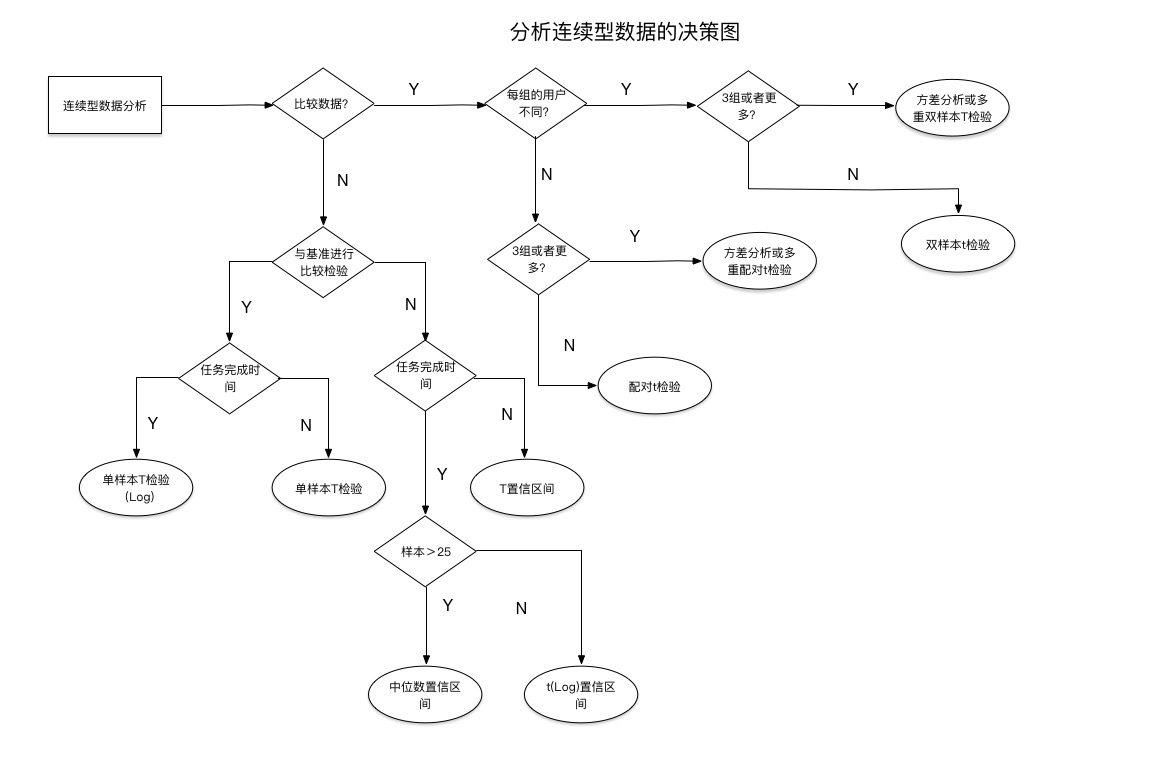
如果要判断例如SUS可用性评分、NPS或者任务时长此类连续变量的均值之间是否存在显著差异,你首先需要明确的是这是场被试间测试还是被试内测试。并且对于不同的数据类型(连续变量or 分类变量)、用户小组数、样本数,均有不同的统计方法。
下图为连续型数据(满意度评分、任务时长)选择统计方法的决策图。离散型二进制数据(任务完成率)的统计决策图,后面有时间会补上。
可用性问题清单
(1)定义
一般包括所属模块、问题编号、问题描述、问题层级(一到四级)、处理优先级以及跟进人。
严重等级判断与可用性准则这里就不重复介绍了,此前的上篇已介绍过。
(2)问题优先级的计算方式:
[(问题频数X4)/总参与人数]+严重等级
如一个UI问题被提到3次,总参与人数为10人,严重等级为三级(一级最高),那么相应的优先级则计算为四级(4.2四舍五入为4),即表示该UI问题的修复优先级为最低四级。
但是在实际工作中,可用性测试中发现的问题,当确定好严重等级后,修复的优先级除了问题频数,还需要综合考虑开发成本、业务成本,最后需要用研人员与产品经理共同确定修复问题的优先级。上方公式仅可作为用研根据问题频次与严重等级去判断修复优先级的算法之一。
总结
关于可用性测试中收集的指标如何量化,本篇中就介绍到这里。其实对于可探索、可深究的问题仍有许多,例如一个复合型的度量指标是否可以全权代表可用性测试中其他指标?小样本数据的量化是否真的可以达到一个可靠的置信区间?
带着问题希望大家可以继续深入探讨,本次抛砖引玉的介绍就到这里,欢迎交流。
作者:媛媛大王(微信公众号:用户研究社 ),资深用户研究员
本文由 @媛媛大王 原创发布于人人都是产品经理。未经许可,禁止转载。

















专家~有个问题想请教下,像「任务完成率」「任务完成时长」「错误次数」「提示次数」这些指标,能否捏合成一个上一层的定量指标?有没有相关的案例,比如在产品发展不同阶段,通过不同指标整合的公式来测量对比提升的效果这样的?求分享~
那个图里,左右偏态说反啦
对【问题优先级的计算方式】有个疑惑,比如一个问题被提到8次,总参与人数为10人,严重等级为三级,那么按您说的计算则为8*4/10+3=6.2,那么应该属于1、2、3、4哪个级别?
学习了
标准化量表确实非常少,这些量表都有相当的理论基础但对于告诉发展的互联网,略显的有些迟钝。我原来发表过一篇关于sus量表的文章,欢迎交流
厉害了word哥
的确,从国外引进的量表很多未经过国内市场的改编,对于互联网产品的适应力较差,所以基本我们在用的时候都会根据公司的产品和用户特性进行调整,欢迎交流~!
我这里还有一篇《SUS 量表在用户体验度量中的应用》显示正在排版,可能是小编要控制每天产量,到时再交流