
 起点课堂会员权益
起点课堂会员权益定性研究:我们到底应该访谈多少用户?
在用户研究和市场调研领域,定性研究是一种不可或缺的方法,然而,一个常见的困惑是:在定性研究中,究竟需要访谈多少用户才能获得有价值且具有代表性的数据?本文将深入探讨这一问题,从定性研究与定量研究的区别出发,结合实际案例和专家建议,为你提供科学的指导和实用的计算公式,帮助你在成本和收益之间找到最佳平衡点。

你是不是经常遇到这样的问题:当开展一项定性研究时,访谈多少个用户才是最佳的?这个问题背后是成本和收益的最佳平衡点问题。
01 定性研究VS定量研究的样本量
在回答这个问题前,我们首先要知道样本量的本质是用“小数据”推测“大真相”。
无论是调查一个城市的消费者偏好,还是研究全国用户的产品使用习惯,我们几乎不可能调查所有人。因此,需要通过抽样(从总体中选取一部分样本)来推测总体情况。
而这种“推测”,在定性研究和定量研究中的逻辑是不同的。
1.定量研究
定量研究(如问卷):追求“数字的广度”,目标是统计代表性。
定量研究样本量的确定受到很多因素的影响,具体包括:
(1)总体大小当总体规模较小时,样本量会随着总体的增加而相对较多地增加。但是当总体规模达到一定程度后(通常是10000),总体的大小对样本量的影响就变得相对较小了。无限总体假设下的样本量和有限总体校正(Finite Population Correction, FPC)样本量计算公式不同,本文不做详细展开。
(2)期望的置信水平和置信区间常用的置信水平为95%(Z值为1.96)或99%(Z值为2.58)。置信区间(或误差范围)越小,所需样本量越大。
(3)变异性越高的群体变异性(多样性)通常需要更大样本量来捕捉不同群体特征。
(4)研究目的描述性研究一般需要较少样本,而要进行推断或预测的研究可能需要更多样本以确保结果的稳健性。
【常见的经验法则】
- 描述性研究:通常至少30个样本
- 相关性研究:一般至少30-50个样本
- 实验研究:每组至少15-30个样本
- 回归分析:每个预测变量10-15个样本(有些学者建议更高)
- 因子分析:变量数的5-10倍,且不少于100个样本
- 结构方程模型(SEM) :至少200个样本,复杂模型可能需要更多
(5)设计效应
在定量研究中,设计效应(Design Effect, DEFF)反映了复杂抽样方法(如分层、整群或多阶段抽样)相较于简单随机抽样(SRS)对样本量需求的影响。某些抽样方法,比如集群抽样,因为同一个集群内的个体可能很相似,所以结果可能偏向某个方向,导致需要更多样本来纠正这个偏差。
设计效应越大,所需样本量越多,以维持相同的统计精度。
Tips:定量研究样本量问题本文不做展开,感兴趣可到“用户研究成长圈”知识星球学习。
2.定性研究
定性研究(如访谈)追求“信息的深度”,目标是达到饱和(Saturation)。
关于“饱和”的概念,尼尔森诺曼集团(Nielsen Norman Group)的 Maria Rosala(2021 年)提出以下定义:
“在定性研究中达到饱和是指从研究中浮现的主题已经足够详尽,再进行更多的访谈也不会提供能够改变这些主题的新见解。”例如,某App团队想了解用户卸载原因。前10次访谈中,发现了“功能复杂”“广告太多”等6个原因;第11~15次访谈中,新增了“耗电量高”这一原因;第16~20次访谈无新发现。此时可认为达到饱和,样本量定为20人。 2017年,Hennick 等人进一步定义了两种形式的饱和度:
代码饱和(Code saturation)——“当不再发现新问题,且代码本开始趋于稳定时的节点。”
意义饱和(Meaning saturation)——“当我们完全理解问题,且无法再发现任何新的维度、细微差别或问题的见解时的节点。”
根据 Hennick 等人(2017)的说法,代码饱和“可能表明研究人员已经‘听到了所有内容’”,而意义饱和则发生在研究人员“理解了所有内容”时。那么问题来了,访谈的样本量达到多少才能达到代码饱和以及意义饱和?
02 定性研究样本量问题
来自海外的一名专家Katryna Balboni在Victor Yocco等人基础上,提供了一个计算定性研究样本量的公式:
所需样本量 = 被访者未出席率 x ((研究范围 x 人群多样性 x研究方法)/研究人员专业程度)
Participants = No-show rate x ((scope x diversity x method)/expertise)
1.研究范围(Scope)
国外的Rolf Molich基于比较可用性评估研究和个人研究经验,在2010年提出了一个有趣的框架:

Slater Berry在2023年从战术性与战略性研究的角度讨论了不同研究范围所需的样本量问题:
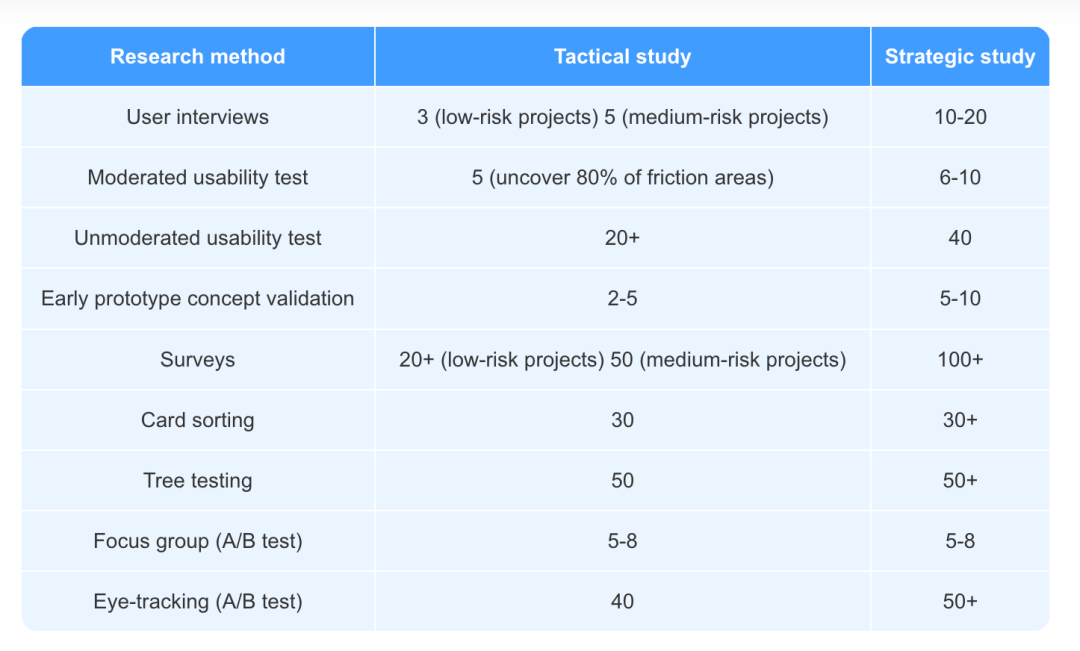
咨询公司 Blink UX 的 Brittany Schiessel同样在2023年提出:
- 基础性研究(10-12 名参与者)——以更深入地了解您的主题或感兴趣领域
- 形成性研究(6-8 名参与者)——在开发开始之前,识别问题和考虑因素以指导设计
- 总结性研究(15+ Ps)—— 用于衡量用户体验
在这些人的基础上,Katryna Balboni做如下收敛:
- 狭窄 —— 针对现有产品或非常具体问题的研究(最少未知数、战术性、形成性)。范围 = 1
- 专注型 —— 创建新产品或探索已定义的问题(存在一些未知因素,战术性或战略性,形成性)。 范围 = 1.25
- 广泛 —— 发现新问题/洞察(许多未知因素,战略性,基础性)。范围 = 1.5
2.样本群体多样性(Diversity)
通常来说,群体越多样化,达到饱和状态所需的参与者就越多(Hennick & Kaiser, 2022)。
在Katryna Balboni的公式中,多样性由一个值表示:
- 非常相似:我使用多个标准来招募具有共同特征和/或习惯的特定人群(例如“拥有 5-10 年经验且使用过 AWS 的英国软件工程师”)多样性 = 1
- 有些类似:我正在招募特定的一群人(例如“具有 5-10 年经验的软件工程师”)多样性 = 1.3
- 有些不同:我正在招募一些不同的参与者或者几组不同的群体。虽然有一些限制,但相当多的人可能符合资格(例如,“在过去 12 个月中在线购物 2 次以上的女性。”)多样性 = 1.5
- 非常不同:我正在招募一组非常多样化的参与者或几个不同的群体。资格标准更宽泛,许多人可能符合条件。(例如,“过去 12 个月内在网络上购物过的人。”)多样性 = 1.7
从“非常相似”到“有些相似”的跳跃,其值增加了 30%。在此之后,每增加一个多样性程度,数值就增加 15%。
这是基于一个假设,即样本群体之间会存在一些相似之处,并且随着样本量的增加,总体重叠量也会增加。
3.研究人员的专业知识(Expertise)
研究人员的专业知识越丰富,对所研究现象越熟悉,他们作为研究工具的表现就越有效。
换句话说,熟练的研究人员可以用更少的参与者揭示见解。
在Katryna Balboni的公式中,专业水平是一个介于 1 至 1.3 之间的值,具体取决于你对以下问题的回答:“参与该项目的研究人员平均有多少年从事这类研究的经验?”
- 0-4 年。 专业水平 = 1
- 5-9 年。 专业度 = 1.1
- 10-14 年。 专业水平 = 1.15
- 15-19 年。 专业度 = 1.2
- 20-24 岁。 专业水平 = 1.25
- 25 年以上。 专业水平 = 1.3
Yocco (2017) 建议这个变量对于初学者研究者应从 1 开始,并且每增加 5 年经验,以 0.10 的速率递增。Katryna BalboniH计算后,发现以这种速率增加专业分母会产生过于显著的影响。
Katryna BalboniH仍然将这个值增加了 0.10,以实现从 0-4 年到 5-9 年经验的首次跳跃,但之后每 5 年区间的增幅减少到 0.05。
4.被访者未出席率(No-show rate)
缺席者是指那些接受了研究邀请但从未出现在访谈中的人。
在对 201 名可用性专业人士的调查中,尼尔森诺曼集团的团队发现人们报告的平均未出席率为 11%(Nielsen, 2003)。同时,Jeff Sauro (2018) 指出典型范围在 10%到 20%之间。
这意味着,每需要 10 名参与者,实际上应该招募 11 或 12 人。
Katryna BalboniH坚持使用 10%的比例——因为这是一个整齐的数字。
5.研究方法
Katryna BalboniH在前人的研究基础上,给出了一张表:
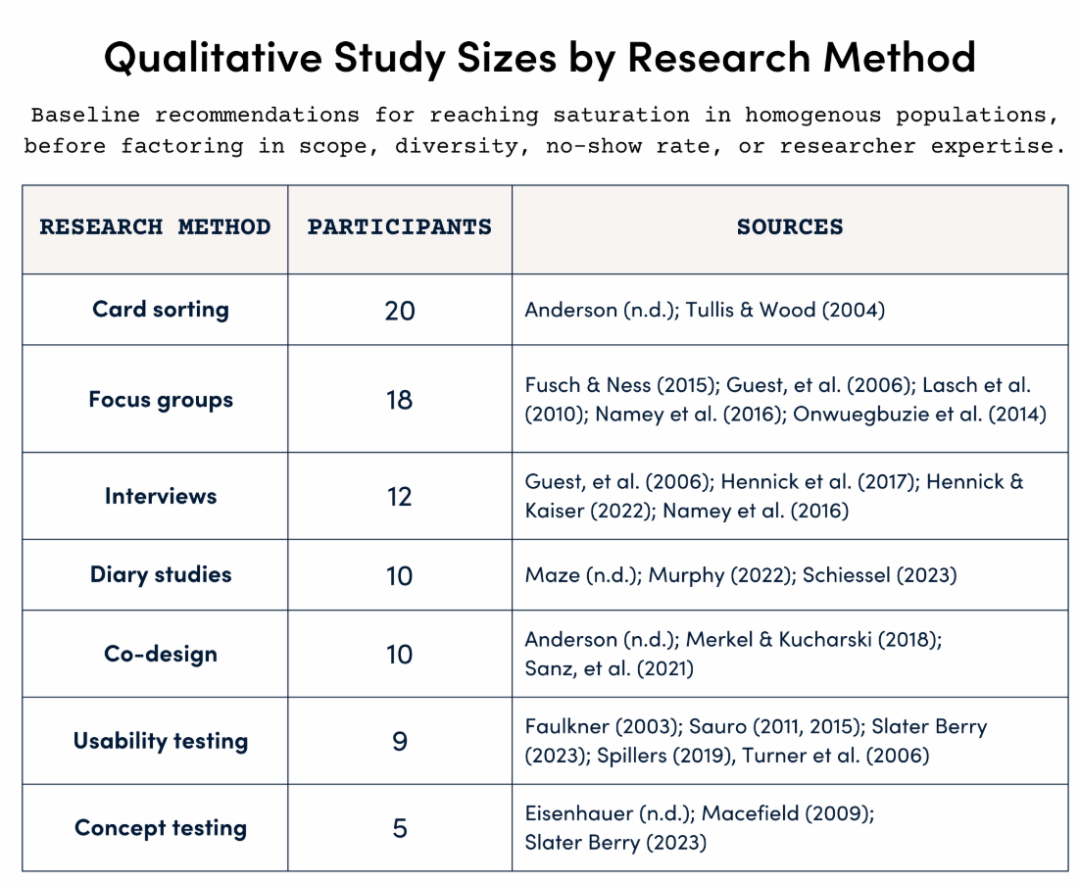
根据这张表:
- 一对一访谈的基准样本量是12个
- 焦点小组的基础样本量是18个(3组,每组6名)
- 日记研究的基准样本量是10个
- 共同设计或参与式设计的基线样本量是10个
- 卡片分类研究的基准样本量是20个
- 可用性测试的基线是9个
- 概念测试(通常在项目的早期阶段进行,以评估用户对想法或简单原型的反应)基础样本量是5个
6.综合起来
现在,我们有了影响饱和的所有变量,根据公式代入计算所需样本量 = 被访者未出席率 x ((研究范围 x 人群多样性 x研究方法)/研究人员专业程度)
场景 1:探索性访谈
你希望在开发新产品时进行一些探索性访谈——假设这个产品是一个面向销售运营的工具。
你的目标用户是销售运营专家,但你也希望与那些在工作中涉及销售运营的其他人员交流。
换句话说,你的被访者可能有某种程度上相似的使用场景和需求。你有10 年的研究经验,并且与一位拥有 4 年客户访谈经验的产品经理共同进行这些访谈——你计划平分这项工作。
- 范围 = 广泛 = 1.5
- 多样性 = 有些相似 = 1.3
- 方法 = 访谈 = 12
- 专业知识 = 5-9 年 [平均] = 1.1
- 未出席率=1.10
因此:样本量 = 1.1 x ((1.5 x 1.3 x 12)/1.1) = 23.4
人不能分成小数,所以我们把样本量四舍五入到 24。
场景 2:概念测试
你是一位用户体验设计师,正在为英国市场开发一款旅行产品。
在对目标受众(假设他们是高收入、对奢华、环保/文化意识强的旅行感兴趣的成年人)进行了一些探索性研究后,你已经有了一个清晰的概念和低保真原型。
现在,你想了解自己是否走在正确的道路上——这些想法能否引起共鸣?你有三年从事这类研究的经验。
- 范围 = 聚焦 = 1.25
- 多样性 = 非常相似 = 1
- 方法 = 概念测试 = 5
- 专长 = 0-4 年 = 1
所需样本量 = 1.1 x (( 1.25 x 1 x 5)/1) = 6.9
所以在这个情况下,你需要招募 7 名参与者。
总之,定性研究的样本量需要根据研究范围、数据收集方法、资源限制以及信息饱和的原则来综合考虑。
研究者需要在数据收集过程中不断评估是否达到了信息饱和,并根据研究进展动态调整样本量。
本文由人人都是产品经理作者【Peron用户研究】,微信公众号:【Peron用户研究】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


