
 起点课堂会员权益
起点课堂会员权益用户体验评估方法汇:可用性测试

文章主要围绕可用性测试展开分享。可用性测试在产品评估体系里一直被称为无往而不利的神器。
基本概念
今天我们来分享可用性测试,它在产品评估体系里一直被称为无往而不利的神器!而概念的分歧和模糊,我们在讨论它的时候经常混乱,所以我不得不用许多字数将概念澄清:
1.可用性
根据ISO 9241-11的定义,可用性是指在特定环境下,产品为特定用户用于特定目的时所具有的有效性、效率和主观满意度。
- 有效性是用户完成特定任务和达成特定目标时所具有的正确和完整程度。
- 效率是用户完成任务的正确和完成程度与所用资源(如时间)之间的比率。
- 主观满意度是用户在使用产品过程中所感受到的主观满意和接受程度。
Nielsen认为可用性有五个指标,分别是易学性、易记性、容错性、交互效率和用户满意度。产品只有在每个指标上都达到很好的水品,才具有高的可用性。
- 易学性:产品是否易于学习
- 交互效率:即客户使用产品完成具体任务的效率
- 易记性:客户搁置某产品一段时间后是否仍然记得如何操作
- 容错性:操作错误出现的频率和严重程度如何
总的来说,可用性直接关系着产品是否能满足用户的功能性需要,是用户体验中的一种工具性的成分。可用性是交互式产品的重要质量指标,如果人们无法使用或不愿意某个功能,那么该功能的存在也就没什么意义了。
1.2可用性测试
可用性测试是在产品或产品原型阶段实施的通过观察或访谈或二者相结合的方法,发现产品或产品原型存在的可用性问题,为设计改进提供依据。可用性测试不是用来评估产品整体的用户体验,主要是发现潜在的误解或功能在使用时存在的错误。
可用性测试的具体操作概念包括观察和访谈:
- 观察:让一群具有代表性的用户对产品进行典型操作,同时观察员和开发人员在一旁观察,聆听,做记录。动作的起始位置、习惯顺序、操作的流畅程度、是否有迟疑、循环、肢体和面部表情的变化等等。
- 访谈:让用户陈述使用产品的体验感受,遇到的问题,以及由自身出发提出建议。
您这么操作是为了? 这里遇到什么问题了?总体使用感受怎么样?您觉得怎么设计会更好用?…
该产品可能是一个网站,软件,或者其他任何产品,它可能尚未成型。测试可以是早期的纸上原型测试,也可以是后期成品的测试。
适合用阶段
一般在产品概念初始原型(如图纸/稿纸)提出之后,即可进行简单的可用性测;后期做出高保真原型之后,可以进行更深入的测试;直至产品上线以后,也可对比竞品进行比较测试。
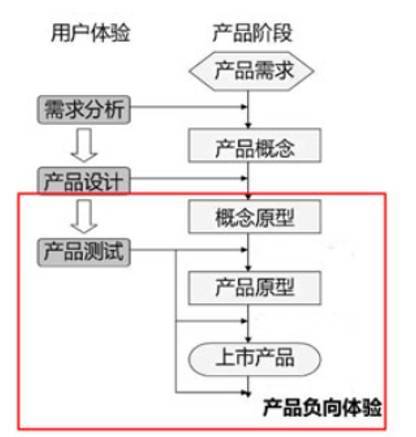
分类
目前的可用性评估方法超过20种,按照参与可用性评估的人员划分,可以分为专家评估和用户评估;按照评估所处于的软件开发阶段,可以将可用性评估划分为形成性评估和总结性评估。形成性评估是指在软件开发或改进过程中,请用户对产品或原型进行测试,通过测试后收集的数据来改进产品或设计直至达到所要求的可用性目标。形成性评估的目标是发现尽可能多的可用性问题,通过修复可用性问题实现软件可用性的提高,总结性评估的目的是横向评估多个版本或者多个产品,输出评估数据进行对比。网站可用性测试包含的步骤有:定义明确的目标和目的,安装测试环境,选择合适的受众,进行测试和报告结果。
1.认知预演
认知预演(Cognitive Walkthroughs)是由Wharton等(1990)提出的,该方法首先要定义目标用户、代表性的测试任务、每个任务正确的行动顺序、用户界面,然后进行行动预演并不断地提出问题,包括用户能否建立达到任务目的,用户能否获得有效的行动计划,用户能否采用适当的操作步骤,用户能否根据系统的反馈信息评价是否完成任务,最后进行评论,诸如要达到什么效果,某个行动是否有效,某个行动是否恰当,某个状况是否良好。
- 该方法优点在于能够使用任何低保真原型,包括纸原型。
- 该方法缺点在于:评价人不是真实的用户,不能很好地代表用户。
例如:对于安卓横屏原型的认知预演,由团队成员完成,主要是产品经理。

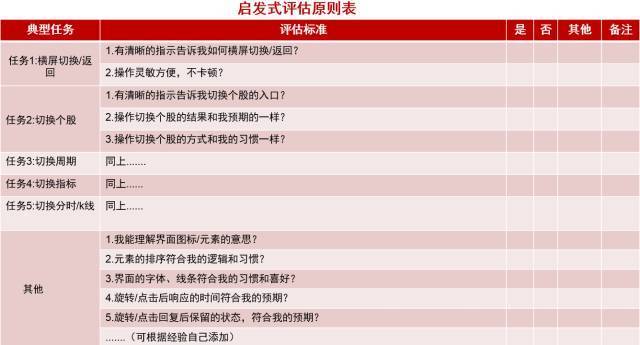
2.启发式评估
启发式评估 (Heuristic Evaluation)由Nielsen和Molich(1990)提出,由多位评价人(通常4至6人)根据可用性原则反复浏览系统各个界面,独立评估系统,允许各位评价人在独立完成评估之后讨论各自的发现,共同找出可用性问题。
该方法的优点:专家决断比较快、使用资源少,能够提供综合评价,评价机动性好;
不足之处:
- 是会受到专家的主观影响;
- 是没有规定任务,会造成专家评估的不一致;
- 是评价后期阶段由于评价人的原因造成信度降低;
- 是专家评估与用户的期待存在差距,所发现的问题仅能代表专家的意思。
例如:对于安卓横屏原型的启发式评估,由产品经理、用户研究员、技术开发共5名成员完成。

操作使用完原型之后,按照事先拟定的评估原则表进行评分和备注,随后根据所有评估原则表结果总结并讨论;评估原则表如下:
3.用户测试法
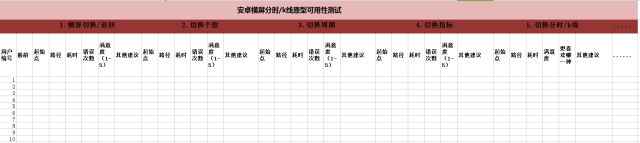
用户测试法(User Test)就是让用户真正地使用软件系统,由实验人员对实验过程进行观察、记录和测量。这种方法可以准确地反馈用户的使用表现、反映用户的需求,是一种非常有效的方法。用户测试可分为实验室测试和现场测试。实验室测试是在可用性测试实验室里进行的,而现场测试是由可用性测试人员到用户的实际使用现场进行观察和测试。
用户测试之后评估人员需要汇编和总结测试中获得的数据,例如完成时间的平均值、中间值、范围和标准偏差,用户成功完成任务的百分比,对于单个交互,用户做出各种不同倾向性悬着的直方图表示等。然后对数据进行分析,并根据问题的严重程度和紧急程度排序撰写最终测试报告。
例如:对于安卓横屏原型的用户测试,由公司内部员工(已排除相关产品和技术开发人员)6名用户完成。

测试脚本于事先根据测试需求拟定,用于引导用户触及典型操作,也用于测试后评估问题优先级用。如下:
注意事项
- 你测试的是产品,而不是使用者。当用户不能按预期完成任务时,需要改变的是产品而非用户。
- 更多地依靠用户的表现(操作,使用时间,错误率等),而不是他们的偏好(主观态度,满意度评价等)。
- 基于用户体验,找出问题的最佳解决方法
测试流程
1.定义并招募被试
选择具有代表性的用户可以减少样本数量,提高研究效率。一般来说,参与可用性测试的产品的用户或近期使用过竞品的用户。在定义目标用户时,可以从三个角度入手:
- 人口学特征,性别、年龄、学历、职业、地域等
- 使用动机,如买家/卖家、企业/个人等
- 使用经验,如产品使用时长、竞品使用情况、互联网使用年限等
应该招募多少用户呢?据统计5名用户大约可以发现85%的问题。一般在迭代测试中,用户数量一般控制在5-10个。如果用户类型较多事,可安排每个类型3-5名用户。
2.典型任务创建
首先要通过内部沟通确定一份功能点清单。一般选择产品或页面5-8个功能点进行测试,这些功能点可以是用户常用功能、新增功能、关注度高的功能及先前版本中存在问题的功能等。在可用性测试中,以用户任务的方式展示出来。任务要能够代表典型用户的行为,并且聚焦在我们关心的功能点上。任务设置要具体、可执行,尽量接近用户使用的实际情况。联系产品或页面的使用场景,给用户提供执行任务的情境信息,如告诉用户为什么要查找信息、为什么要购买物品等。避免专业术语或内部用语。
3.测试结果整理——可用性问题分级
经过可用性测试,可能会发现产品或页面的很多可用性问题。为了方便内部人员决策,需要对这些可用性问题进行分类或等级界定。常见的分级方法有:
五级划分
- 5级:无关紧要的错误
- 4级:问题虽小但却让用户焦躁
- 3级:中等程度,耗费时间但不会丢失数据
- 2级:导致数据丢失的严重问题
- 1级:灾难性错误,导致数据的丢失或者软硬件的损坏
三级划分
- 低:会让参加者心烦或沮丧,但不会导致任务失败。
- 中:与任务的失败有一定关系但不直接导致任务的失败。
- 高:直接导致任务失败的问题。
二维划分,根据出现频率和影响严重性
- 频率低 、频率高
- 影响大、中等、严重
- 影响小、不严重 、中等
决策树,根据以下三个因素综合决定的:
- 频率(Frequency):偶然的or经常性的
- 影响(Impact):容易克服or很难克服
- 持续性(Persistence):一次性的or持续的
多维划分,根据问题所属范围和问题出现频率
- 问题所属范围:交互、视觉、文案、功能、bug
- 问题出现频率:N个人出现同样的错误
最后,根据分级后的可用性问题,安排优先级去解决和调整。可用性测试在产品迭代中,可以迅速敏捷地使用,通常出现了各种各样的变式,我们在实际使用中应该结合本项目的实际情况和已有的人力、物力来灵活使用。
作者:大狗狗,互联网金融产品用户研究员,心理学二年级学渣,公众号:同花顺UED(公众号:Mob-HitThink-UED)
本文由 @大狗狗 原创发布于人人都是产品经理。未经许可,禁止转载









学习了
截图的红配黑,两个色系都这么深,怎么看得见呢?这种截图建议多和你们美工沟通下