
 起点课堂会员权益
起点课堂会员权益如何避免定量用户流失研究的误区?

在产品发展的成熟期,获取一个用户的成本往往比留住一个用户成本多得多,因此如何规避用户流失就显得尤为重要。
有一个比喻非常恰当:产品如同蓄水池,用户好比池中之水。池子中每时每刻都有新用户源源不断地加入,也有一部分用户选择离开。如果用户流失超过新用户的补给,且速度越来越快、规模越来越大时,产品如若不警惕,蓄水池迟早会干涸。
这是用户流失研究的背景。产品阶段不同,重心也会从拉新转移到留存,对于一个成熟的产品和饱和的市场而言,获取一个新用户的成本可能是留住一个老用户的数倍,流失率的降低也意味着营收的增加,在这种条件下,流失研究的价值是显而易见的。
而研究流失用户所面临的主要问题,是如何衡量用户流失的规模,重中之重是梳理清楚“流失用户”和“流失率”的定义。或许你脑海中早已经罗列好了几点困惑:
- 研究对象是谁:是登录用户、注册用户,还是全部用户的流失率?
- 流失周期为何:是次日流失率、7日流失率还是月流失率?
- 如何定义流失:1个月没有访问的用户?2个月没有下单/消费的用户?还是3个月没有登录的用户?
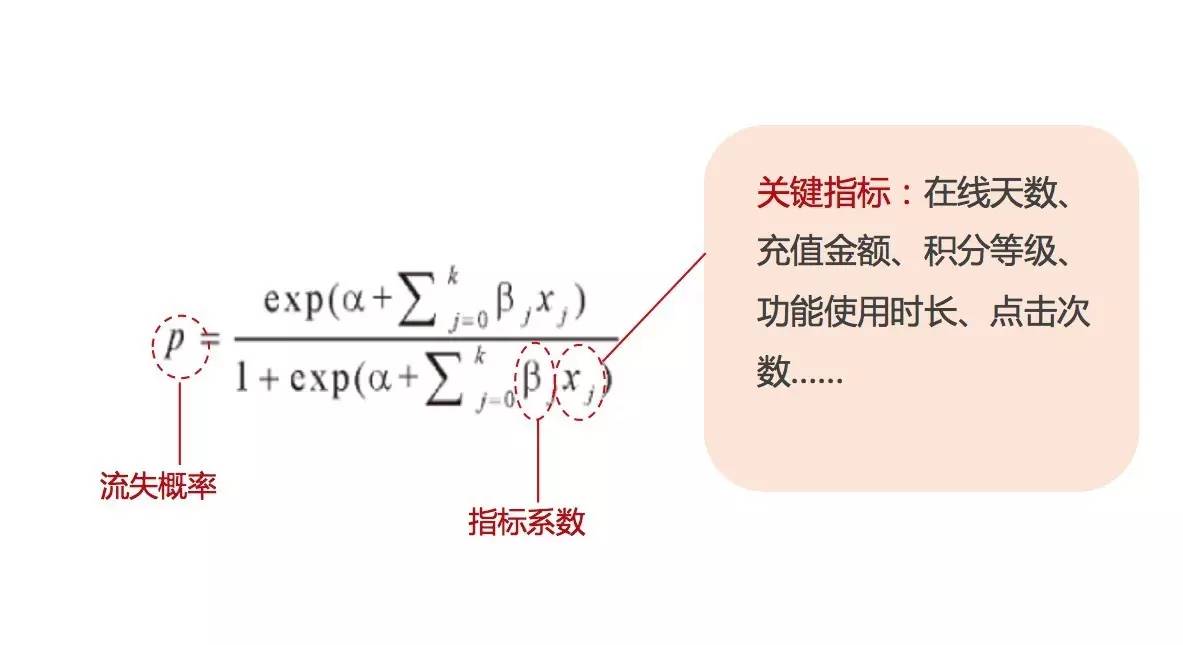
为了给流失一个明确、又能符合产品特征的定义,并且相对准确地识别出可能流失的用户,我们引入二元逻辑回归作为定量流失研究的模型。在模型中,我们将一段时间内用户的一系列行为特征数据(如在线天数、充值金额、积分等级、点击次数……),代入二元逻辑回归方程中,就可以计算出相应的流失概率。
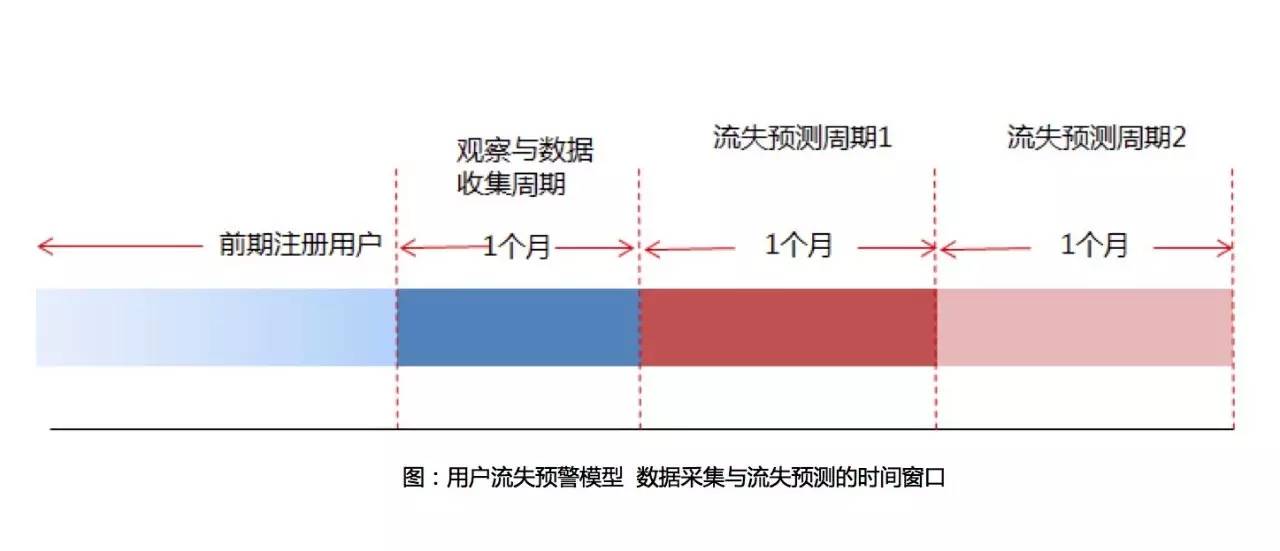
也可以用下图数据采集与流失预测的时间窗口来理解这一过程。选择产品中一部分老用户,观察和收集他们在一个月内的行为数据(深蓝色部分)。通过这些数据,我们可以预测其在未来一段时间内(红色部分)的流失与留存情况。在预测周期1内出现但周期2未出现的,说明在周期2内流失了,如果两个周期内都没有出现,那么可能在观察期内就流失了,上述两种都属于流失;而周期1和周期2都有出现的用户,则是留存用户。
但是,在通过定量模型来研究流失的过程中,往往存在着几个常见的误区:
- 概念误区:自己研究的对象真的是流失用户吗?有多大比例是“伪流失用户”(回流用户&使用间隔大的用户)?
- 方法误区:定量模型的优化只能依赖增减指标吗?是否数据一扔就能一劳永逸?还有哪些方法可以提升模型预测准确性?
- 应用误区:流失预警模型只能用于区分流失与非流失用户?定量数据和流失模型还可以怎样支撑用户细化与运营方案?
一、数据仅为工具,产品理解贯穿始终
如何界定流失用户,避免概念误区
在构建流失模型时,通常以月作为分析和数据提取的周期,比如在上图时间窗口中,以连续一个月没有使用算作流失。但这种简单粗暴的划分方法往往会带来三方面的问题。
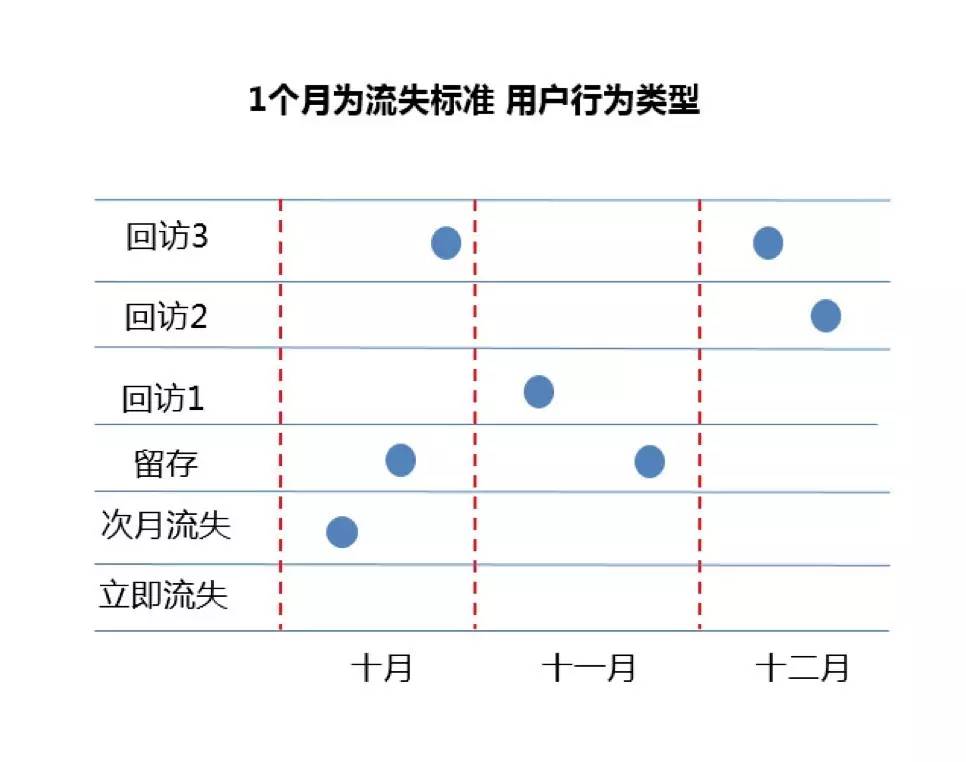
一是,流失周期受用户使用间隔决定,不同周期划分影响用户结构比例。如果以1个月作为流失周期,那么十月出现但十一月没有出现(蓝色圆点代表出现)的用户在十一月流失了,而实际上,他在十二月又出现了,是一个回访用户(见回访3),并没有真实流失。如果我们以2个月为周期,则“回访3”的用户在10~11月,12月以后两个周期内都出现过,应该是一个留存用户。周期划分对用户流失界定有着直接影响。
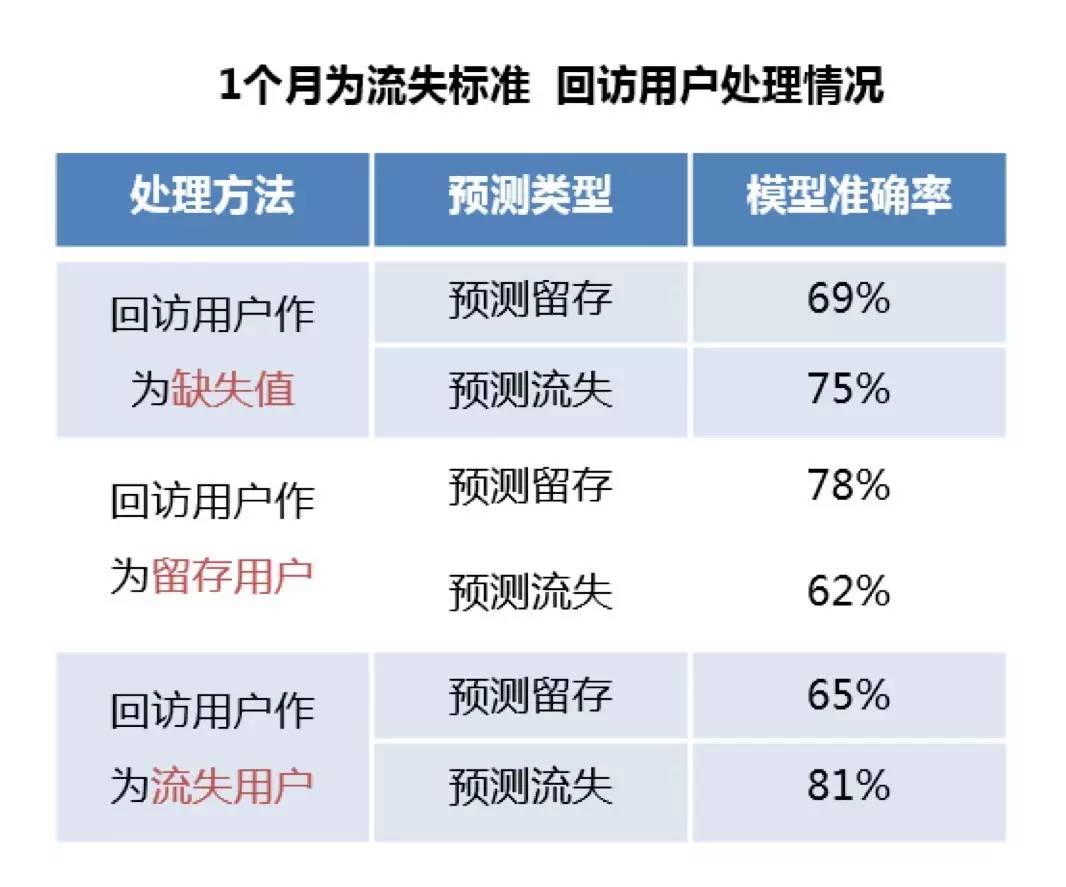
二是,如果简单以一个月为周期进行用户分类,回访用户过多(比如占总体15%),无法忽视且难以处理。无论以何种周期划分,必然存在一定比例的回访用户,将回访用户作为缺失值、算作留存用户或者作为流失用户,均对模型准确率有较大影响。
三是,流失周期划分会影响模型的准确率与平衡性。如下表,以总样本100w为例,分别以4周、5周、6周作为流失标准,划分出的流失和留存用户是不同的,对应的流失留存预测准确率也不同。流失周期过短,流失预测的准确率低,因为定义为流失的用户中有大量实际留存的用户,只是其使用间隔长而已(比如以1周没登录就算流失,但实际上很多留存用户2~3周才登录一次,也被划分成流失用户);同时周期过短,定义为留存的用户实际上后来也会流失。
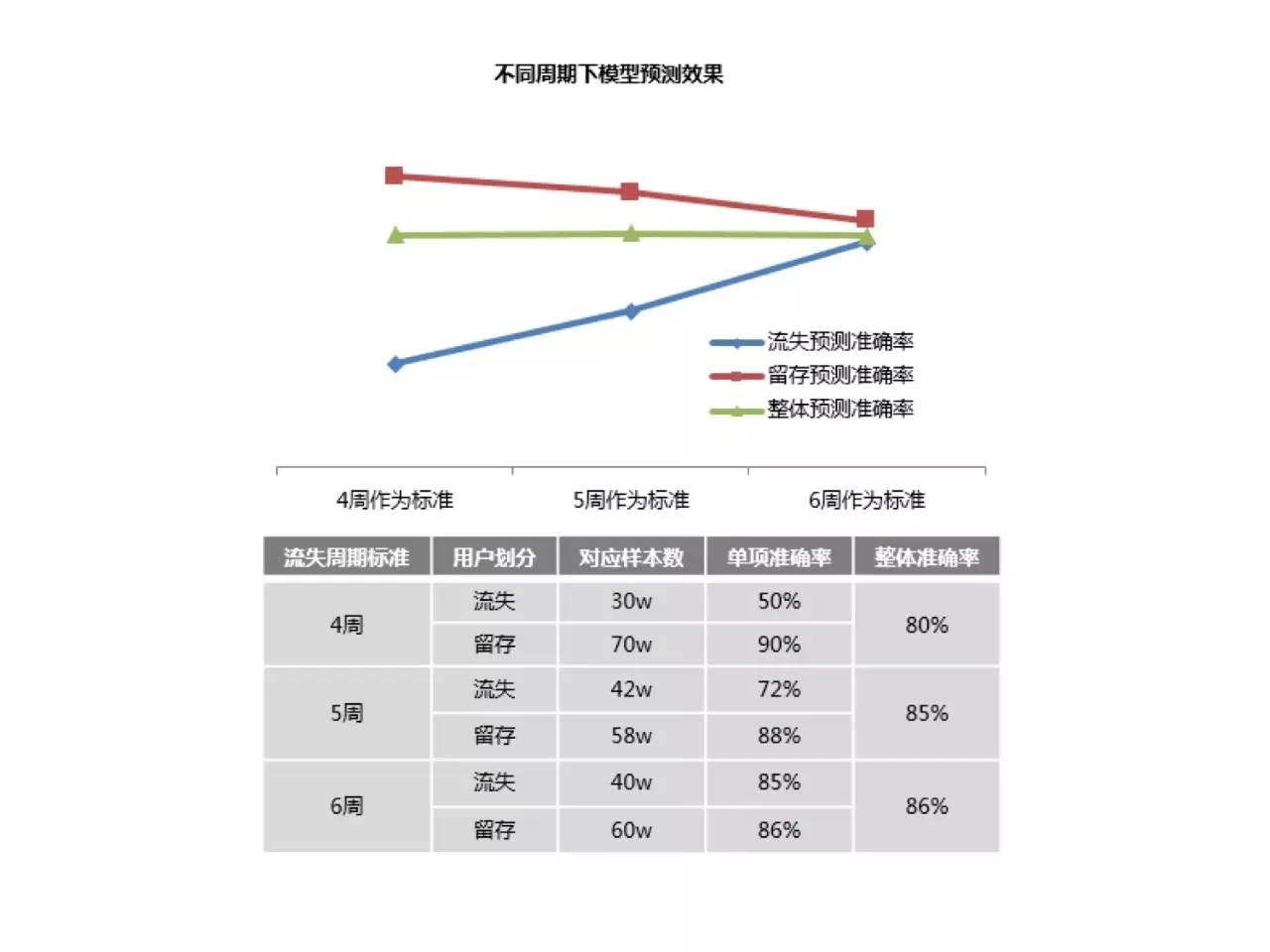
因此,不合理的周期造成预测准确率低且不平衡,我们需要不断尝试周期划分,在保证整体准确率的情况下寻求流失与留存准确率最佳的平衡点,才能更为准确地同时预测流失及留存情况。如果流失准确率有90%但留存只有50%,那么虽然我们预测流失的用户几乎都是真正会流失的,但可能只识别出了总体用户中一小部分流失用户,还有大量流失用户被划分在了留存用户中,导致留存准确率过低。
在这种情况下,选择恰当的定义方法显得至关重要。通过查阅资料,我们发现对流失比较经典的定义是“一段时间内未进行关键行为的用户”,关键点在于如何界定时间周期(流失周期)和关键行为(流失行为)。
我们选择经典的拐点理论来作为周期界定的参考:用户回访率拐点(用户回访率 = 回访用户数 ÷ 流失用户数 × 100%),同时结合对产品的理解,选择“主动登录”这一行为作为是否流失的关键行为。
但经典的理论也会遇到尴尬:没有出现拐点怎么办?
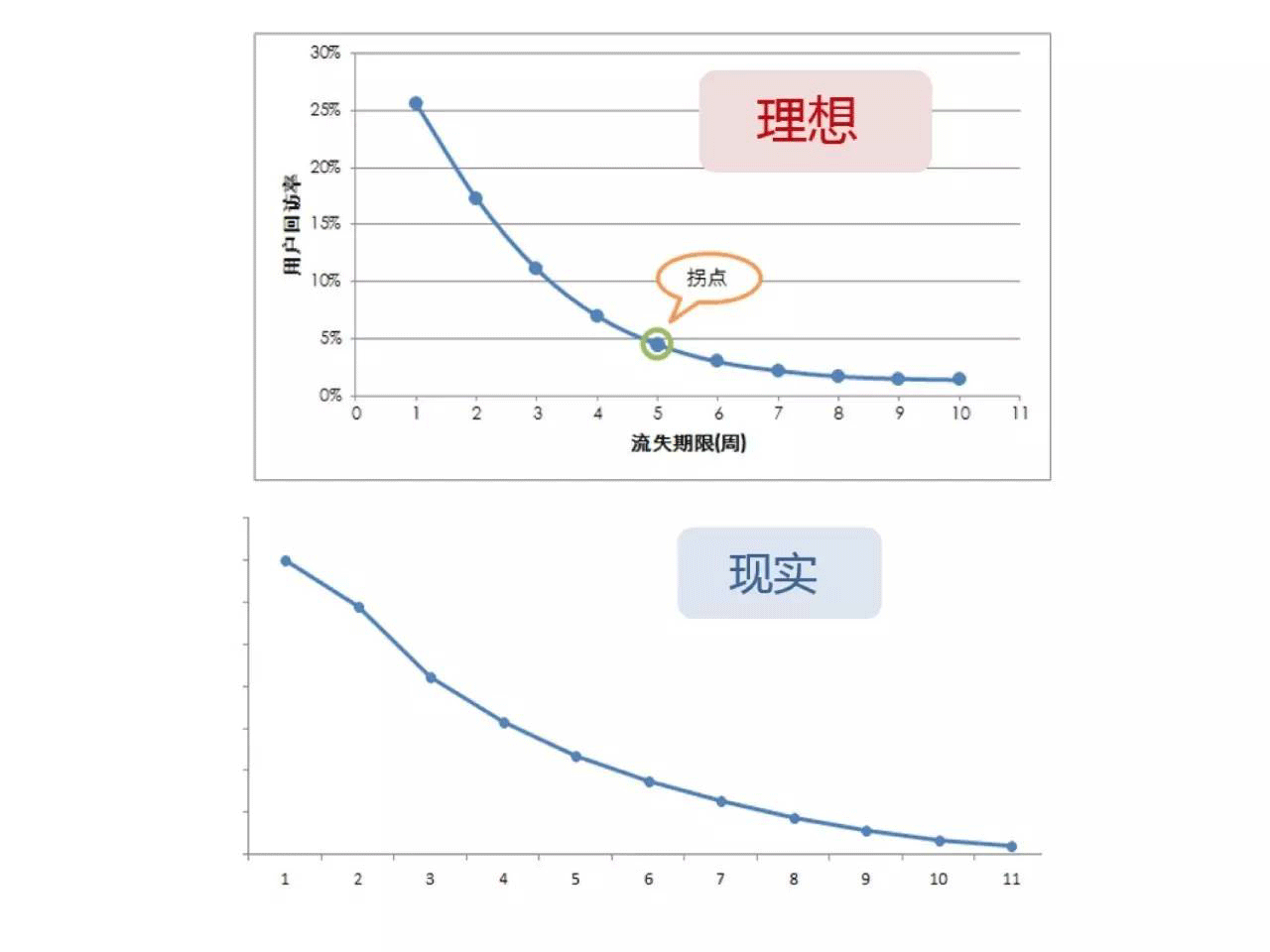
回访率拐点可能与产品存在一个平台期(瓶颈)有关:用户/玩家处在哪些等级可能流失加剧,或者是在线时长达到多少会产生疲倦加剧流失,哪些角色的用户更容易流失等等——比如游戏,游戏的特点是:回合、关卡、任务、日常与升级,但这与一些产品长周期、长间隔的用户使用行为模式并不相同。
在没有拐点的情况下,可以依据产品经验或结合模型预测准确率判断,一般产品的回访率5%-10%,不管划分多长的时间周期都会存在回访,误差不可避免。
二、指标没选好,模型调到老
如何优化数据模型,避免方法误区
搭建数据模型的关键在于行为数据的选择,这也是最耗时耗力的地方。在建立模型之前,有必要和数据&开发的同事来一次促膝谈心,对数据库和埋点的情况进行摸底,再次明确一些数据概念的操作化定义,避免发生误解。
比如,误解通常来自于以下几点:
- 对活跃用户的定义:是登录用户、打开app的用户还是在线用户?
- 数据映射和匹配:是按用户维度(账号)提取还是按照设备维度(设备ID)提取数据?如何处理一个账户多台设备和一个设备多个账户的关系?
- 数据埋点:登录用户和匿名用户(非登录)埋点是否一致?某些关键操作(比如主动打开App)的有无准确埋点?能否区分前台打开还是后台打开?
- 数据状态与记录方式:能否获取历史数据,历史数据是累加记录还是覆盖?
可问题往往没有那么简单,即使定义得再精确细致,模型的准确性也可能不高。如果明白“管中窥豹”这个成语的意思,你很可能找到了答案。
通常我们以一个月为周期,提取用户一个月内的行为数据。但是产品不同,用户操作习惯是大相径庭的,有的产品1个月的时间周期太短,就难以形成足够的行为数据,好比是盲人摸象,摸到一条尾巴要预测出是一头大象,的确很有难度;另一方面,时间过短部分用户尚在好奇和探索阶段,没有完全沉淀下来成为真正的用户。反之,如果一味增加提取数据的时间周期,项目执行的时间成本也会水涨船高;同时,等提取周期结束,一些用户早已流失,即使预测成功也难以挽回。
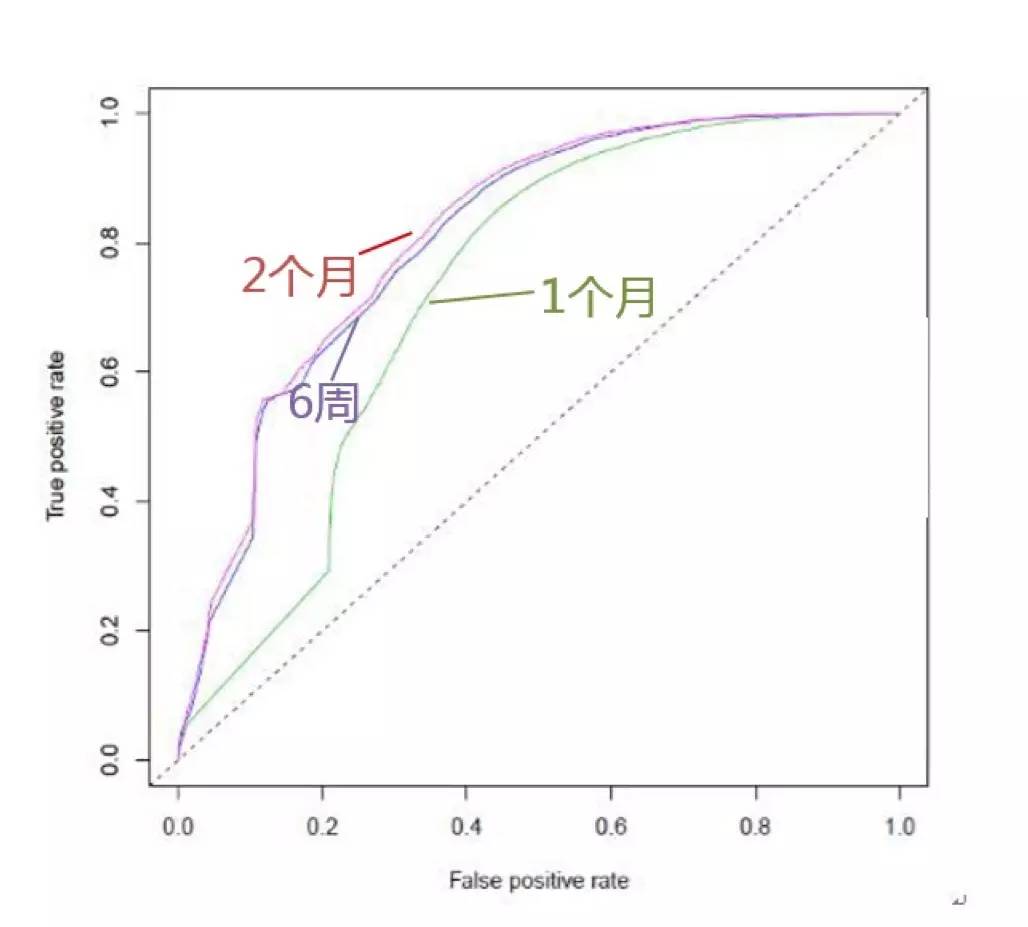
模型的准确性依赖于数据提取周期问题的解决,我们需要一个用户多长时间的数据才能准确预测该用户下一阶段的行为?通过二元逻辑回归的ROC曲线可以进行评估,如下图,6周的数据明显优于1个月(曲线右下方面积越大预测准确性越高),而2个月的数据只略优于6周,幅度有限,且时间成本较大,因此选择6周作为数据提取的周期。
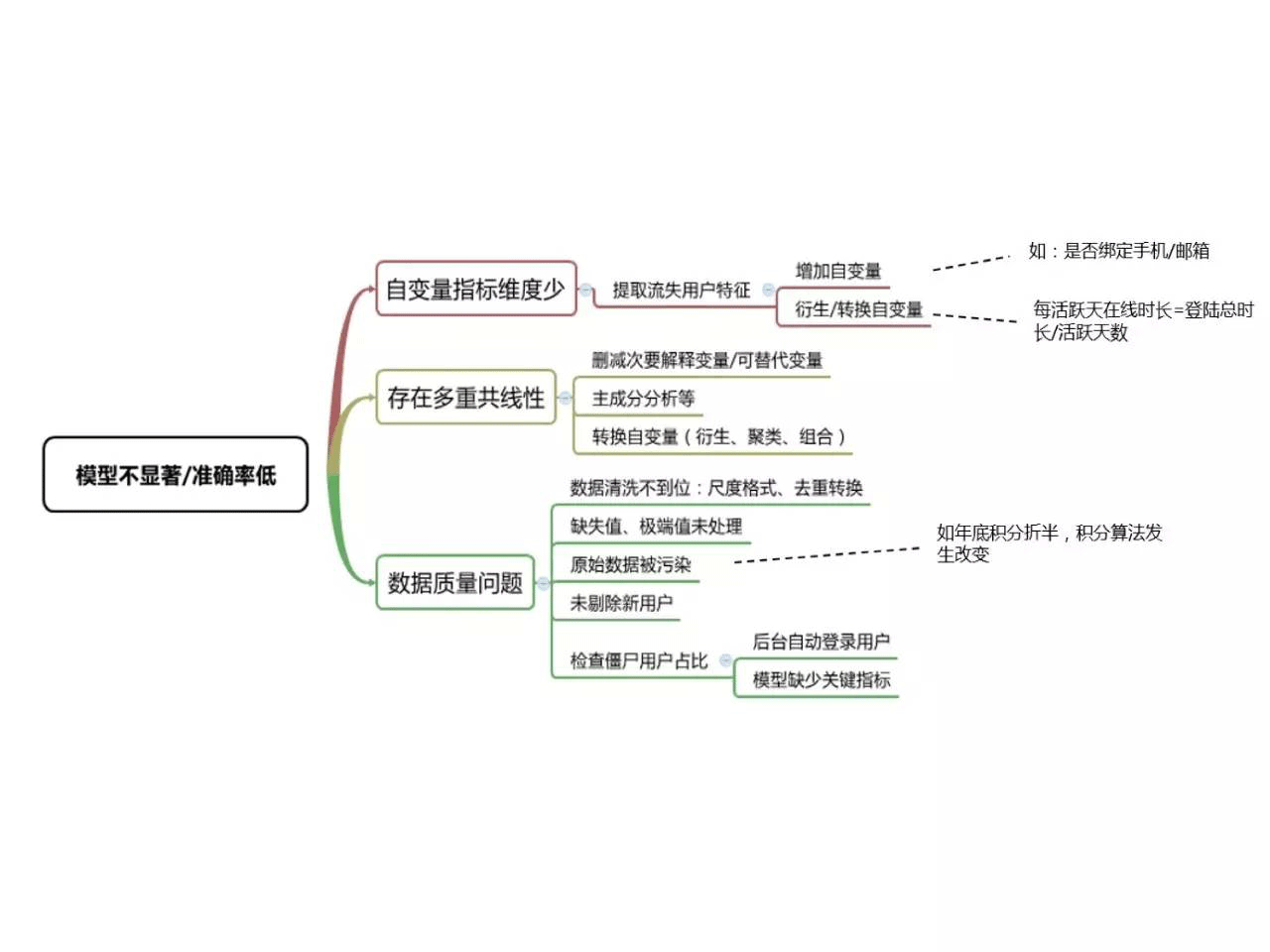
第二个难点在于流失原因的分析,也即流失影响因素的选择。选择一些具有流失用户典型特征的指标维度作为自变量,一步步尝试修改指标,迭代模型。如果前期流失模型准确性低,并且流失用户的特征与模型的特征不符,则需要寻找新的流失因素,并纳入流失预警模型的提取数据点。指标的选择,一方面需要不断试错,最主要还是基于对业务的理解。
建模过程中的主要问题是模型预测准确性低,我们可以通过检查是否没有纳入典型的指标维度、是否存在多重共线性来有的放矢地加以解决,有时不显著的原因可能出乎意料——比如产品功能更新了,或者年底积分折半了,拿到的是被污染过的数据而不自知。
三、不止预测:模型只是方法而非终点
如何支持用户运营,避免应用误区
通过流失预警模型,我们可以获得产品一系列功能模块或指标对流失留存的影响因子,并计算出每个用户的流失概率。通过影响因子,我们可以对流失原因有所了解,在此基础上进行深入研究和确认,结合用户反馈的频率、专家意见等确定改版的优先级。
计算流失概率只是一种方法,而不是研究的最终目的,流失研究也不能到此就浅尝辄止。区分出可能流失的用户是为了提高挽留策略的针对性,提高效率与减少成本,实现精细化运营——这也是流失模型的核心价值所在。
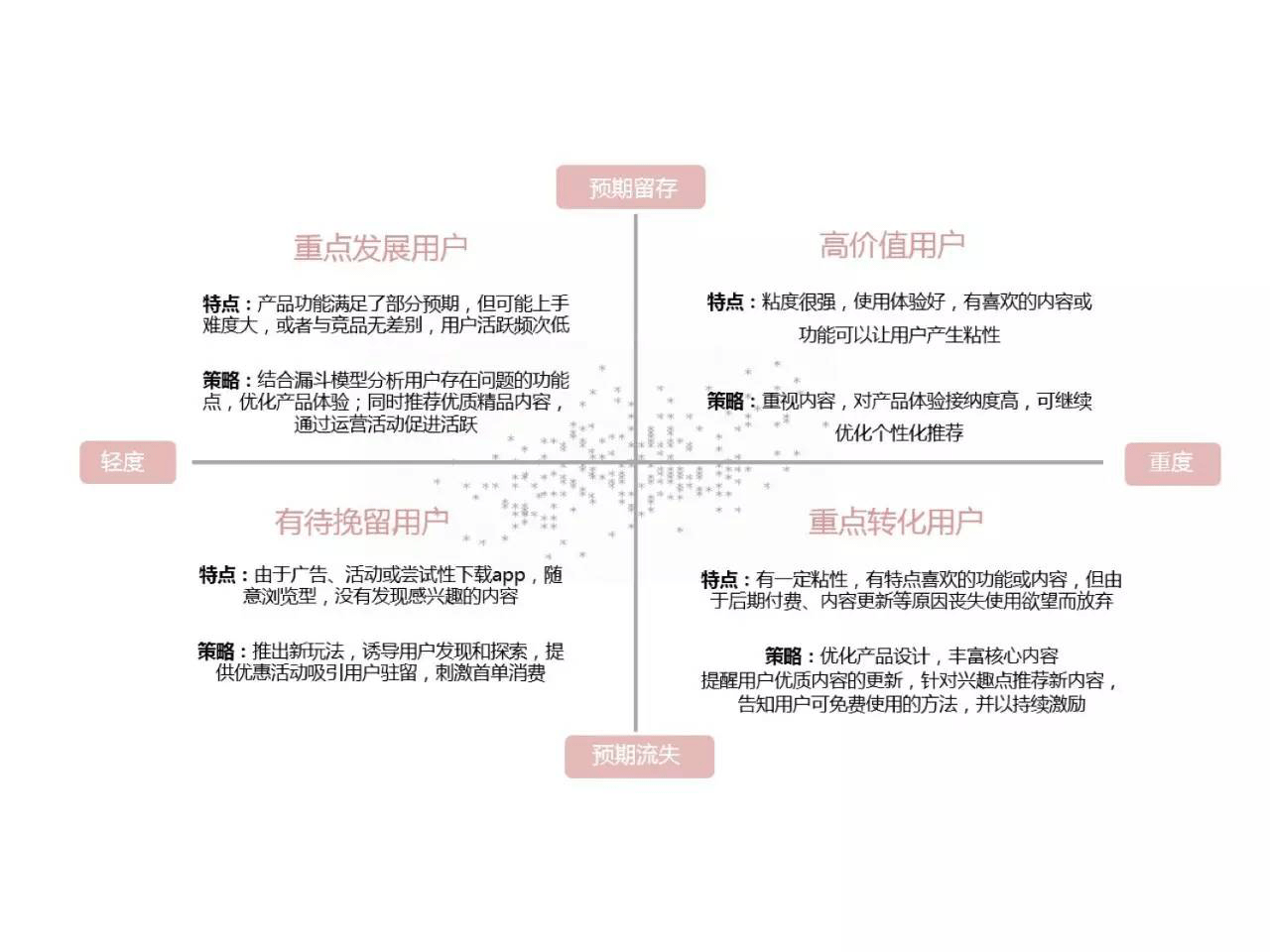
比如,从用户使用的轻重程度出发(如上图),在通过模型计算出用户未来的流失概率后,将使用App的频率和时长作为用户轻重度的划分标准,结合用户流失留存预期,将用户划分为高价值、重点发展、重点转化、有待挽留等几种类型,分析每个类型用户不同的行为特点和使用痛点,采取针对性的运营策略。
当然,流失模型也可结合付费维度进行研究。先筛选出极有可能将会流失的用户,再根据购买频次和付费金额来进行细分:从未付费的用户可通过优惠券、促销活动或超低价商品吸引回访、促成首单购买;少量付费且客单价低的用户可以精准推送符合个性化偏好的商品,或者推荐符合该用户消费层次的超值商品;多次付费的老用户,可以增加会员专属优惠,通过回馈激励增强用户粘性,延长使用周期。
以上只是流失模型的两个层面的应用,在不同项目中还可以结合多种方式对用户进行精细化运营。模型准确性高的话,可以用更少的成本、对用户更少的干扰来留住更有价值的用户。
当然,提及用户细分、精细化运营和产品功能体验的优化,又离不开对用户的理解和对产品业务的积淀。和这种不断的积淀一样,流失预警模型也需要不断地修正和迭代,以适应产品发展的需求。以模型作为一种研究技术,以对用户和业务的理解积淀作为基础,来一起推动产品迭代和运营活动的落地,这两者都是用户研究的价值所在。
作者:项宇,网易产品发展部用户研究员,对接阅读类产品的用研工作,不断学习与探究用户群体背后的微观动机与宏观行为。
本文作者@项宇,由@用盐有点咸(微信公众号:用盐有点咸) 授权发布,未经许可,禁止转载。









不实用
请教下为什么用二元逻辑回归方程计算出流失概率呢?