
 起点课堂会员权益
起点课堂会员权益可用性测试:任务评估模型与计量方式

在可用性测试中,如何去评估测试的场景或流程呢?应该包含哪些维度?每个维度要如何测量?怎样在不同的任务间做横向对比?本文就此一一讲述。
公司的产品最近发布了一个版本,上线了比较多的新功能。所以需要针对这些新功能做一轮可用性测试。
可用性测试算是用研的一个入门级技能,即使是从业年限不多的我也已经做过多次,基本的方法和流程都比较熟悉了。但是之前做过的可用性测试有个缺陷:没有建立一个严谨、科学的任务评估模型。在可用性测试中如何去评估测试的场景或流程呢?应该包含哪些维度?每个维度要如何测量?怎样在不同的任务间做横向对比?
评估模型
ISO9241中对“可用性”的定义是:特定用户在特定的使用场景中,为了达到特定目标而使用某产品时,所感受到的有效性、效率和满意度。
也就是说,在定义好了用户、场景和目标的前提下,可用性包含了下面三个维度:
- 有效性(Effectiveness):用户完成特定目标的正确和完整程度。
- 效率(Efficiency):用户完成特定目标的效率,与消耗的资源(如时间)成反比。
- 满意度(Satisfaction):用户使用产品时感受到的主观满意程度。
良好的可用性必须能够同时满足有效性、效率和满意度三个条件;但是这三个维度也有层次之分,一般来说,有效性问题>效率问题>满意度问题。
在可用性测试中,仅仅了解每个功能的可用性水平还不够。即使两个功能的可用性水平一样,若一个是产品的基本功能、一个是价值不大的边缘功能,我们还是需要优先去优化价值更高的功能。也就是说,在评估一个任务时,除了可用性之外我们还需要考虑功能本身的价值。尤其是在上线了新功能,或者我们对待测功能的价值还不太确信的时候。
功能的价值可以简单分为两部分:用户价值和商业价值。尽管有时候需要在商业价值和用户价值之间权衡,但是作为一个体验导向的产品,还是应该将用户价值放在第一位。在用户价值之上,若能够满足商业价值,则是更令人满意的结果。
所以,在可用性测试中可以用下面这个模型来对测试的任务进行评估:
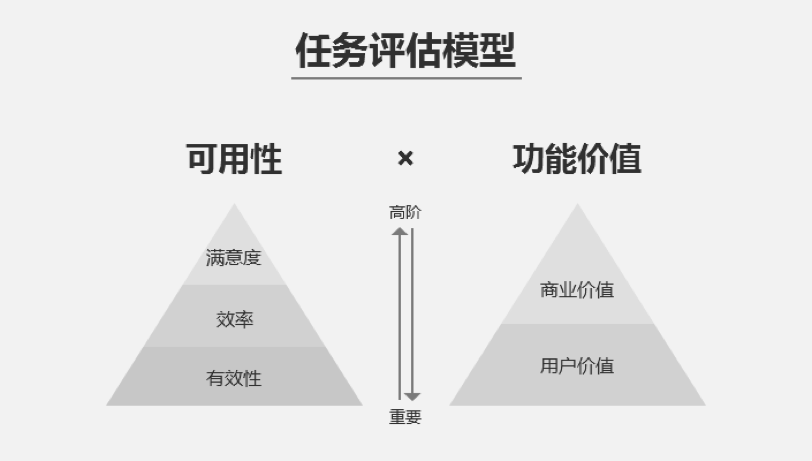
测量方法
在上述模型中,有效性、效率、满意度都是常见的评估维度,有一些经验方法可以参考;用户价值也可以通过用户评价获得。而商业价值则需要根据产品的实际情况进行评估,并且这一般是既有的知识,不需要在可用性测试过程中收集这个数据。因此在可用性测试中我们需要收集的数据就只包含四个维度:有效性、效率、满意度和用户价值。
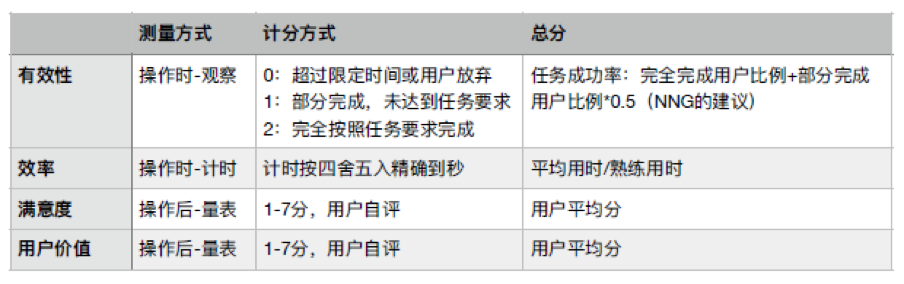
有效性
可以用任务的完成情况来评估有效性,这个数据通过观察用户的操作过程即可获得。
任务完成情况的测量主要参考NNG的建议,将每个用户的操作结果标记为失败、部分完成或全部完成。
失败:如果用户认为自己完成不了而放弃了任务,或者超过了限定时间仍然无法完成任务,则标记为失败。
需要对每个任务都设置一个限定时间。要求对功能非常熟悉的人(相关的产品、设计师都可以)按照任务提示进行操作,记录完成操作所需的时间,称为熟练用时。如果想要提高熟练用时的测量准确度,可以多找几个熟手操作然后取其用时平均值。任务的限定时间根据熟练用时确定,一般是熟练用时的3-10倍,但是最高也不要超过10分钟(没有用户会有耐心花10分钟完成一个任务,如果真的需要这么久,说明任务设计得太复杂了)。
可以根据任务的难度确定倍数,如果任务对于小白用户来说确实很有难度,那么可以适当延长任务限时;如果任务很简单,或者其中包含一些输入的操作,那么可以适当减少任务限时(因为打字往往比较费时,而且对功能熟悉的人打字未必比用户快)。
部分完成:用户只完成了一部分的任务,没有完成任务卡上的所有要求。比如,你希望用户创建一个日程并邀请小王加入,用户成功创建了日程但是却不知道如何(或者忘了)邀请小王,这就是部分完成。之所以要区分“部分完成”这个类别,是因为它跟100%完成有差距,但是又不能与失败混为一谈。
完成:这个很容易理解,就是在限定时间内完成了任务卡上的所有要求。
最后,我们需要根据这些数据计算每个任务的成功率。NNG的建议算法是:任务成功率=(完全完成的用户数+部分完成的用户数*0.5)/用户总数,即完全完成率+部分完成率的一半。
除了用完成、部分完成和失败来评价任务完成情况外,还可以考虑另一种方式:顺利完成、遇到障碍后完成、失败。这是我之前使用的计分方式。这种方式下,以上所述的部分完成会被归于失败的类别(但如果用户犯的是无伤大雅的错误,比如输入错误,可以视为完成)。而成功完成的用户会被细分为顺利完成的和遇到障碍后完成的。之所以这样区分是因为这两种情况揭示了不同的可用水平——能让用户轻松地完成的功能可以说是相当易用的。
效率
效率可以用时间测量,对用户的操作过程计时。
可以从用户拿到任务卡开始计时,在用户宣布自己已经完成、或者限定时间到了的时候即结束计时。不要等到用户读完任务卡、开始操作时才计时,因为有的用户习惯读完再操作,有的却喜欢一边读一边做。也不要在看到用户完成了就结束计时,而要等用户自己认为他已经完成了,因为用户有时候会在做完操作之后去检查自己的操作是否成功了,这也应该算作任务用时的一部分。
计时不需要太精确。手动计时存在几秒钟的误差都算是正常的,而且用户在操作过程中多说了句话、或者应用响应速度慢了些,这些都会影响任务的完成时间(并且很多影响因素跟可用性并没有关系)。所以计时只要精确到秒就好了,提高记录的精确度也没有意义。
在计算每个任务的效率水平的时候,可以用用户的平均用时除以熟练用时所得的倍数表示(数值越大表示效率越低)。
这是为了便于任务间的横向比较,因为不同任务的复杂度不同,A任务平均用时1分钟、B任务平均用时4分钟,也不能说明A的操作效率比B高。通过平均用时/熟练用时的比值,可以知道新手与熟手之间的差距,从而了解因为系统的可用性及学习成本给用户带来的操作时间损耗。
满意度
满意度涉及到用户的主观评价,因此需要通过用户自评量表来收集。
这里参考的是Jakob Nielsen使用的一个单题项七点量表,并根据需要对题目进行了修正:
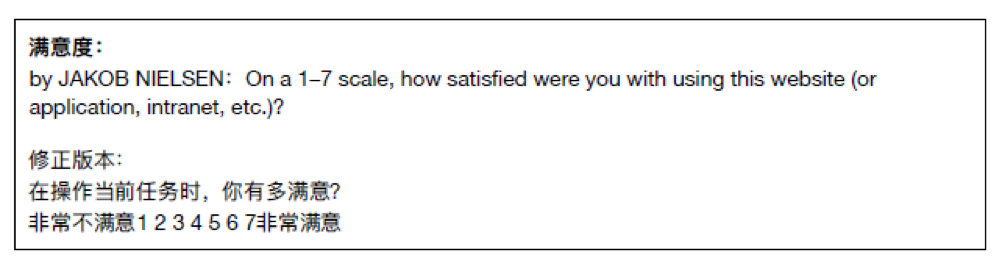
用户价值
用户价值是指用户感知到的功能价值,也需要通过用户的评价获得。
因为我们做的是一款办公软件,所以通过询问功能对工作的帮助来了解用户价值:

满意度和用户价值都需要用户评分,因此用户在完成每个任务之后都会拿到同样的两个题目,要求对该任务做出评价。我会把不同任务的题目打印在同一张纸上,这样用户在评价时可以参考自己对前面的任务的评价来调整分数。
任务横向对比
用有效性、效率、满意度、用户价值四个维度对任务进行评价后,我们可以根据这些数据对不同的任务做横向对比,可以通过类似下方这样的折线图对比不同任务的情况。
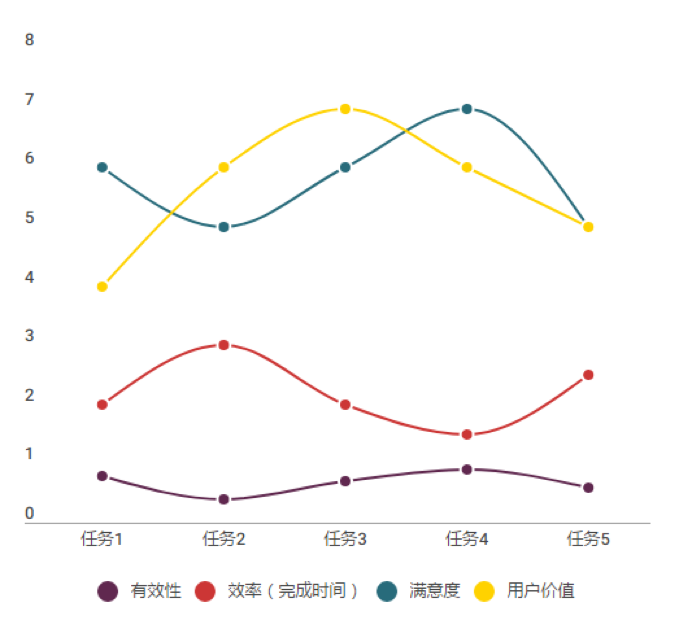
比如从上面这个示例图中,我们可以看到任务2的可用性水平是比较低的(有效性水平低、完成时间长、用户满意度低),但是它的用户价值处于相对较高的水平;而任务3的用户价值最高,可用性水平居中。
有效性、效率和满意度都是用来评估可用性水平的。如果根据这三个数值计算出可用性水平,直接用可用性去做横向对比,是否更方便呢?前文提到在可用性中,有效性问题>效率问题>满意度问题,所以在计算可用性水平时它们应该有不同的权重;并且由于度量方式的不同,它们的量纲有较大差异(从上图可以看出),需要做标准化处理。
因此,我们需要对有效性、效率、满意度分别做标准化处理,然后按照5:3:2的权重计分(或者其他权重,按需调整):
可用性水平=Z(有效性)*0.5-Z(效率)*0.3+Z(满意度)*0.2
(效率处用减号是因为其用时间测量,数值越大效率越低)
这样我们得以在同个量纲上比较不同任务的可用性水平,结合对功能价值的评估,可以得出类似这样的四象限图:
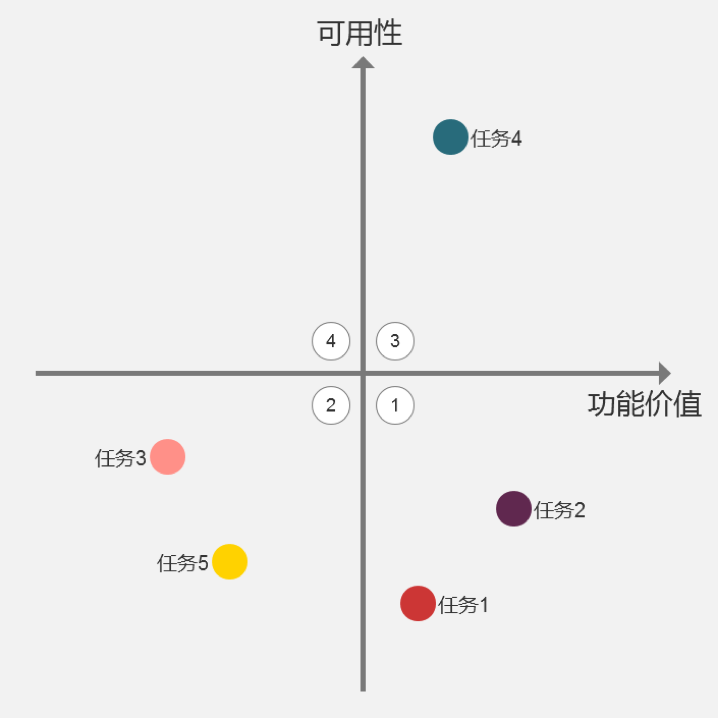
这样的象限图不仅可以帮助我们比较测试的各个功能的情况,还能帮助确定体验优化的优先级。功能价值高、可用性差的功能应该列入最高优先级,其次是功能价值较低、可用性差的功能。
问题优先级
除了上述的评估模型外,在可用性测试中我们还会发现很多可用性问题,这些问题大概是可用性测试产生的最重要的数据了。那么,这些可用性问题是否需要进行优先级评估呢?
可用性问题当然是有优先级之分的,一个问题是影响了功能的有效性、效率还是满意度,就决定了这个问题的优先级如何。我认为可以在每个任务之内按照这个标准对发现的可用性问题进行排序,但是不需要把所有任务发现的所有问题罗列出来去排列优先级。
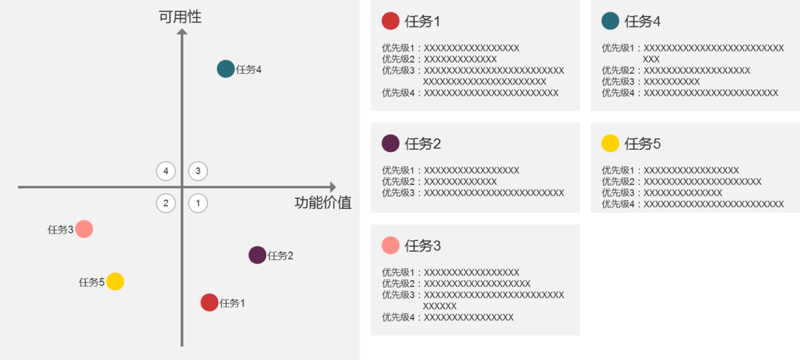
优化可用性问题时应该以功能(即可用性测试中的任务)为单位,而不是以问题为单位——以问题为单位容易只见树木不见森林,可能在修改了很多细节后仍然算不上好用。所以排列问题优先级时,也建议根据上面的四象限图先确定功能的优先级,然后再去查看每个功能具体的可用性问题的优先级。
作者:郑少娜,云之家里一只特立独行的用户研究员。想把生活踩在脚下,说:“叫你搞事情!叫你搞事情!”
本文来源于人人都是产品经理合作媒体@金蝶云之家体验中心(微信ID:UXD-Cloudhub),作者@郑少娜
题图来自 Pexels,基于 CC0 协议









没有任何冒犯的意思,单纯好奇一下哈。您介绍的方法是有基于什么模型或者标准吗。有相关的citation嘛?
请问一下~四象限里提到的功能价值是主观评价么?
文中的理论模型很棒,感谢分享
静下心来看看,学习了,赞!文中NNG是什么意思?
同问
Nielsen Norman Group诺曼尼尔森集团呀!!