
 起点课堂会员权益
起点课堂会员权益科普 | 细节决定A/B测试的成败:有底线的样本量

本文作者将结合自身经验以及相关案例,与你分享在A/B测试中的关键因素——样本量大小。enjoy~
在Testin A/B 测试的运作中,我们曾经遇到过这种情况(这是一道案例分析题):
某位不愿透露姓名的客户A先生为他的产品迭代准备了为期半个月的A/B测试。他希望新的版本能比原版多带来5个百分点的转化率。经过半个月的等待,有1000名用户进入测试,并使得新版转化率成功达到了目标。但是令他疑惑的是,对于这个实验结果的p-value和power检验均不达标。也就是说,这个结果并不可信。
两大检测指标
A先生深感困惑。他不知道该怎么办:是因为效果看似达到了于是停止实验?还是因为检验不达标而做其他的补救措施?
针对A先生的问题,我们进行了一系列分析,最后确定了症结所在:样本量不足。A先生的实验实际上需要至少1500人,但是目前只有1000人进入实验,也就是说样本量的缺口达到了500。若想解决这个问题,只要继续让流量进入实验,达到最低需要的样本量,即可。
看了这个案例,你可能会产生这些疑惑:
- 会出现这些情况居然是因为样本量给的不足?这与实验有什么联系?
- 如果是的话,做一个测试,要给出多少样本量才是足够的?
- 而且,为什么不能让所用用户参与到测试中来,那样一定能保证有足够的数据可以收集不是吗?
——出现这种困惑的客户并不少见,我也是在进一步接触A/B测试以后才明白这其中的关键所在:样本量大小。
有底线的样本量
在上一篇《细节决定A/B测试的成败:不可忽视的抽样》中,我们搞明白了A/B测试和抽样之间的关系,引用一下上一篇中对于抽样的叙述:
“在A/B测试中,我们无法知道所有用户的行为(如点击率)的真正均值……必须通过抽样,抽取一部分具有代表性的用户来测试不同版本的效果(例如均值),从而基于抽样数据进行统计分析……”
那么,这“一部分具有代表性的用户”具体数量应该是多少呢?是不是随便划拉一下数据条,拉个多少多少人来测试就行了呢?
并不。因为,如果样本的容量太小,会导致参数估计值的大小和符号违反经济理论和实际经验,使结果不可信。
举个栗子,陆仁甲的头儿要确定全国十几亿人喜欢吃啥主食,然后陆仁甲划拉了几百号人来一问,哦这些人大部分喜欢吃米饭,然后陆仁甲就说全国人民偏好吃大米——???一想就知道不对是吧。
所以说确定你的实验对于样本量大小的需求是很重要的。然鹅,我在网上那些A/B测试入门教程里少有看到对于样本量估算的介绍,大量的A/B测试科普文章仍旧停留在介绍A/B测试怎么怎么厉害怎么怎么牛逼,要怎么怎么做怎么怎么注意(是的没错之前我们也是这样的~233)。
但就是不告诉你到底应该划拉多少人来做。
别慌。这就告诉你怎么搞这个样本量。
给样本量“秀下限”
为了搞清楚这个样本量的估算是怎么弄起来的,我跑去找我们Testin技术部的大佬寻求了一下技术支援:
大佬:“哦就这事儿,其实吧!要确定样本量这事儿老简单了!”
喏,给你我们搞A/B测试的时候用的方法:
我们用UV来计算实验需要样本量和剩余时间。由于t分布需要一个自由度的参数,而自由度的计算需要样本量n。这里样本量需要计算,所以不能用t分布,而用z分布。如果将自由度设置成无穷大,那么累计概率与z分布一样,此处用正态分布进行实验。
在原假设为真的条件下,假设原始版本和版本一的流量之比为1:k,则样本量之比为n:m=1:k
设x是指最小提升率,比如你原来的转化率是50%,你定一个最小提升是10%,那么你最后的得到的转化率就是55%;另外这个原始版本转化率也要设置好
然后整体实验样本量为n+m=(1+k)*n,这时候我们再带入这条公式
(说着大佬拿出了一条长长的写满根号xyzγδαβ的公式……)

——不不打住打住啊我不是来上高等数学的啊别一言不合就建模啊饶了我吧
技术部的大佬太牛逼了高数学渣表示实在不懂啊……
不过这并没有关系。你想啊,假设有一个黑箱,我们只要知道怎么搞进去一些数字,然后黑箱给我们搞出来一些答案就行了对吧!只要会用就行了对吧!(才不是因为学渣看不懂在找借口呢哼)
所以技术部的大佬们早就准备好了一款样本量计算器,专门为我们Testin的客户估计每次实验的样本量:
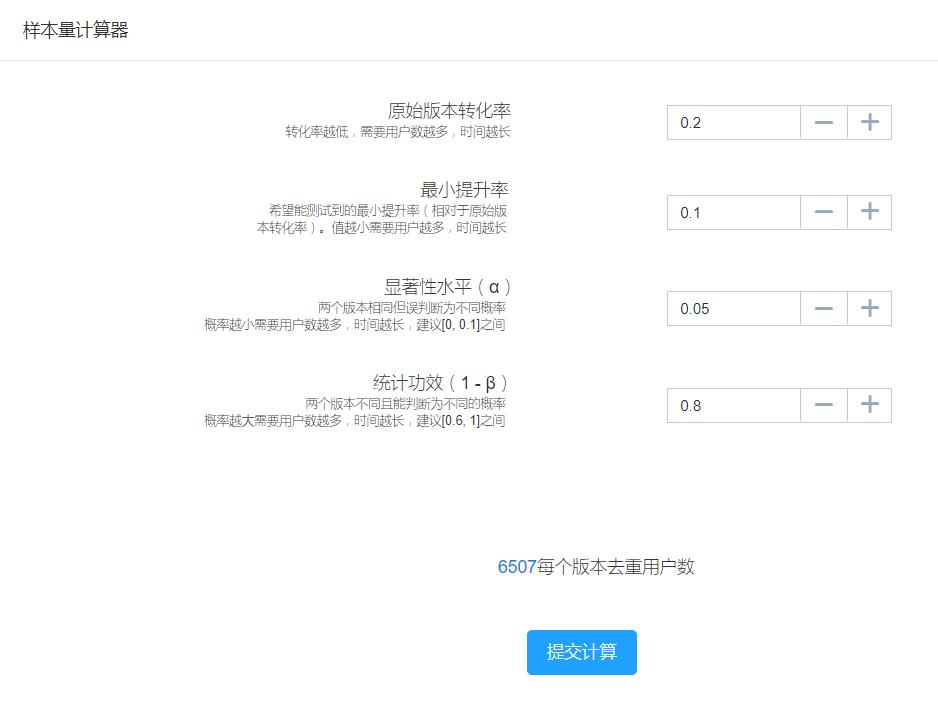
(其实这种计算器并不少见,你也可以直接在网上搜索并使用样本量计算器来估算,只是由于学术界对于样本量估计的争论也是各有各的说法,所以其他计算器使用的公式与我们的可能存在些许差别)
重点是,当你进行A/B测试的时候,要先估算好这个样本量的数值,然后再拉取不少于这个数量的用户来进行测试就行了。
没上限的样本量……?
经过上面两大块的叙述,想必你也意识到了:样本量越大,实验结果的可靠性就越有把握。
但是这就意味着样本量越大越好吗?
(就像现在的手机,屏幕真是越来越大了,但是大就好吗?那你咋不端着个平板电脑打电话呢……)
诚然,样本容量太小,会使抽样误差太大,使调查结果与实际情况相差很大,影响调查的效果,因此做实验的时候,都建议加大流量投入,也因此不建议月活用户数量太少的客户做A/B测试。但样本容量太大,势必会造成人力、物力和财力的很大浪费。这点大家都懂,成本嘛。
但是可能你又有疑问了,我做A/B测试的时候只是在线上收集数据罢了,又不用承担太大的成本,那我加大测试流量有什么好担心的呢?
我们再举个夸张的栗子:陆仁乙有款产品,月活用户几百万。他要进行产品迭代,搞了个A/B测试,A版是原版,B版是新版1,C是新版2(是的没错谁告诉你A/B测试只能有AB两版的啦,同时测试几个版本是可以的哦)为了追求更精确的结果,他给每个版本都分配了25万用户。经过了一周的测试,陆仁乙开心地发现C版拥有超过原版数个百分点的转化能力,同时喜闻乐见地发现B版的25万用户因为B版本体验非常不好,有数万用户删除了应用……
——看到这里你或许明白我要说什么了:不要忘了我们搞测试的初衷是什么:找到最好的版本,规避可能带来的损失。让如此多的用户参与,本就可能带来不可估量的损失了。
毕竟,改革,是有失败的风险的,当你为了追求结果的准确性而盲目提高样本量的时候,你所要承担的风险成本(指由于风险的存在和风险事故发生后人们所必须支出的费用和减少的预期经济利益)已经在不知不觉间上升了。
现实社会不是象牙塔中的理论世界,很多东西是要考虑实际的。因此,如何选择合适的样本容量,才能既满足模型估计的需要,又减轻收集数据的成本,是一个重要的实际问题。
作者:一颗糯米C,公众号:云测数据(testindata),数据驱动增长的坚定实行者
本文由 @一颗糯米C 原创发布于人人都是产品经理。未经许可,禁止转载。






- 目前还没评论,等你发挥!


