
 起点课堂会员权益
起点课堂会员权益百度策略产品经理面试:如何评估小红书的Feed流效果?
基于这道百度策略产品经理面试题,笔者向我们介绍了答题思路以及相关的面试经验。

大家好,我是今天去面了百度的Isabel,职位是策略产品经理,部门是推荐技术平台部,主要是做手机百度App的Feed流推荐。
在面试过程中,除了常规的深挖简历项目之外,还会被问到了业务方面的开放性问题,需要现场回答。
在回答过程中,面试官也一直认真地用电脑记录下我回答的答案,个人感觉百度似乎更看重面试者的临场思维表现,根据现场的回答来判断综合素质。
由于我顺利通过了一面,面试官也评价我的回答答得不错,于是便想给大家分享当时遇到的开放性问题,以及我的回答。
我被问到的是那个经典的问题“你最喜欢的App是什么?”,我的回答是小红书。而众所周知的,在产品面试中这个问题基本都是面试官用来挖坑的,果然接下来就是死亡三连:如何去评估小红书的Feed流效果?小红书Feed流存在什么问题?如何解决?
可能很多小伙伴都和我一样没有过相关经验,看到Feed流这个看起来很高大上的术语,一脸懵逼:这是啥?
因此,在分享我的答案之前,我首先会简单介绍一下Feed流是什么。然后再以小红书为例,聊聊Feed流是如何评估效果、从而持续优化的。
一、什么是feed流
Feed流的准确定义一直存在争议。简单来说,Feed流是持续更新并呈现给用户内容的信息流,它存在于各种各样的APP,字节跳动的抖音便是以Feed流起家的。
小红书的Feed流如下图:
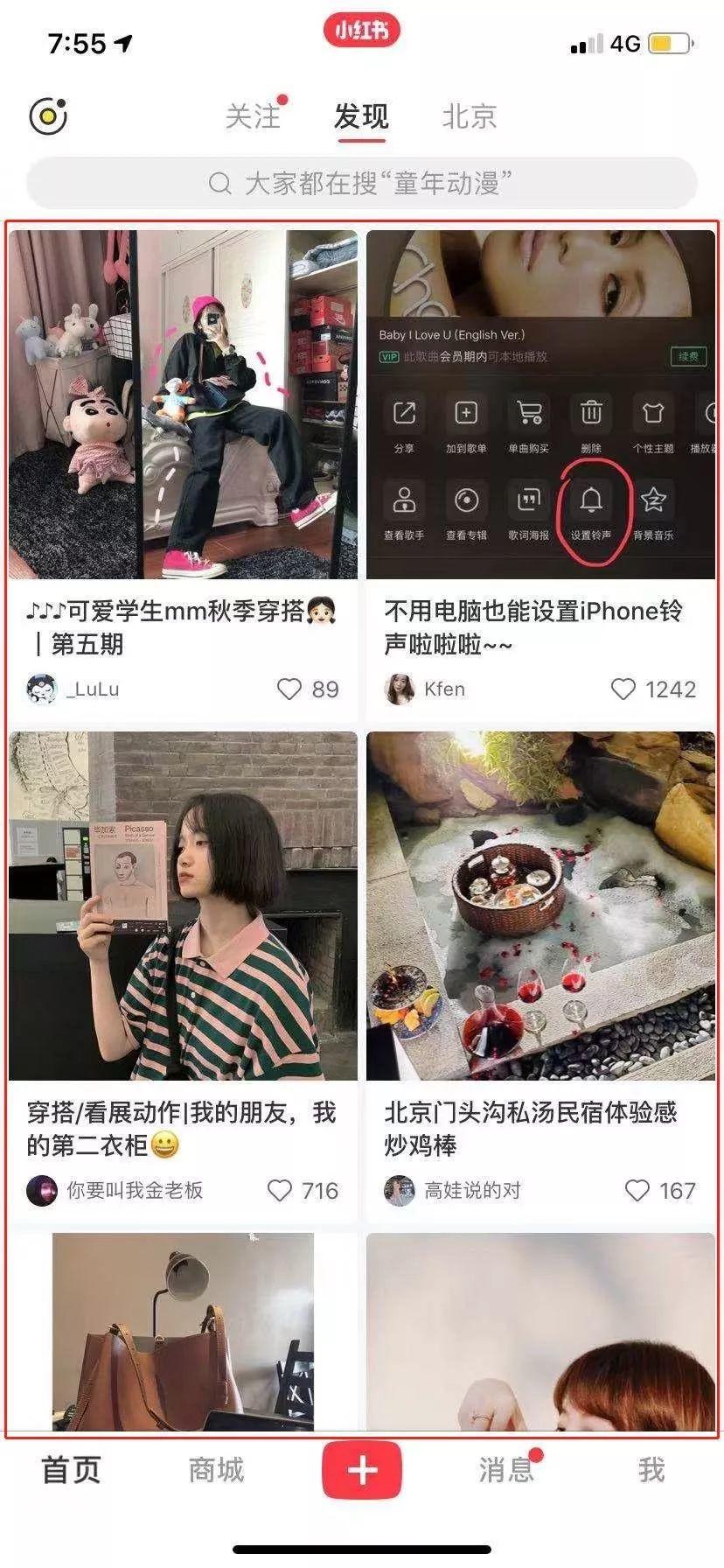
通过图片大家应该对Feed流是什么有了大致的认知,接下来说说我理解的Feed流:Feed流的核心是“个性化推荐”,它的两个主体是内容和用户,是用户与内容的匹配,“信息找人”的展现方式。
总的来说,给Feed流产品下一个定义,则是:通过一定的策略,从大量内容中筛选出部分内容,经过排序后展现给用户。
二、Feed流的生命周期:从产生到效果评估
Feed流是用户与内容的匹配,目的是从大量内容中找到用户最喜欢的内容。那么,这是通过什么样的策略来产生的,又该如何优化呢?接下来聊聊Feed流从产生到优化的全过程。
Feed流的产生,遵循着策略制定的四步骤:问题(目的)、输入、计算、输出。具体来说,是一个这样的过程:
为了达到“给用户展现感兴趣内容”的目的,输入一系列指标,进行逻辑计算,最终输出一个用户满意的Feed流结果。
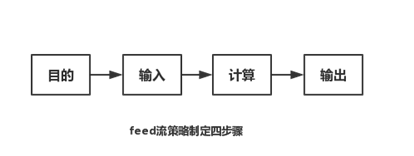
除了“逻辑计算”这部分通常由RD(开发同学)来实现之外,其它的步骤都是策略产品经理需要去考虑并完成的。
接下来,我也会按照策略制定的四步骤,逐步聊聊Feed流是如何产生的。
目的
很显然,Feed流的目的是,要大量内容中找到用户最喜欢的内容。
输入
如何寻找到需要输入的指标呢?
对于这个问题,我们可以从匹配的双方,也就是用户和内容,这两个维度来拆解问题来思考。
- 从用户的角度来说,我们需要通过获取尽可能多的数据,构建用户画像,从而了解用户是个什么样的人。
- 从内容的角度来说,我们需要获取大量、多样、优质的内容,有足够的内容推给他。通过这一系列的动作,我们就可以知道,要把什么样的内容推给他。
细化到具体指标,可以从以下维度来考虑:
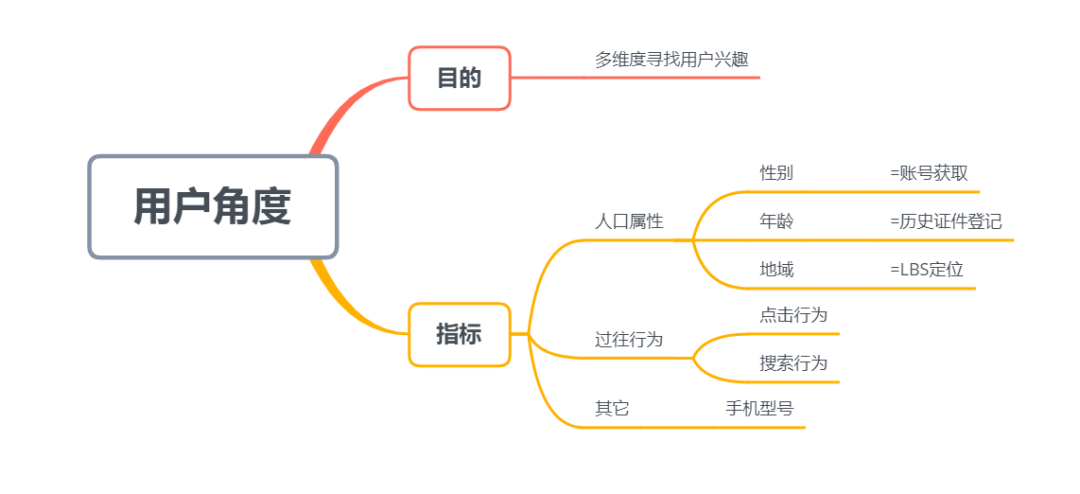
(1)从用户角度,我们的目的是多维度寻找用户兴趣,从以下指标考虑:
1)人口属性
从性别、年龄等维度考虑:基于性别与年龄的应用较为简单,思想有点像数学中的“聚类算法”:检测到用户是女性,会更多地推送女性喜欢的内容,而“女生喜欢的内容”又是基于其它女性用户的数据得到的。
基于LBS定位:可以从两个维度考虑:
- 一是简单地基于地理位置的内容推送,用户在北京海淀区,则会向他推送北京海淀区相关的内容;
- 二是结合地理位置进行城市层级划分,例如北上广、一线城市、二线城市等,检测到用户处于二线城市,则向他推送二线城市用户喜欢的内容。
2)过往行为
- 过往搜索行为:用户之前有搜索过“美食”,则接下来会推送美食相关的内容。
- 过往点击行为:用户在Feed流中点击“科技”相关内容,侧面说明用户对科技更感兴趣,因此更多地向用户推送科技的内容。
3)其它可获取信息
- 例如手机型号信息,若用户使用的是iPhone,可判断用户对iPhone相关内容可能会感兴趣,从而向用户推送iPhone相关的内容。
- 以及结合具体业务情况,其它可以拿到的信息。
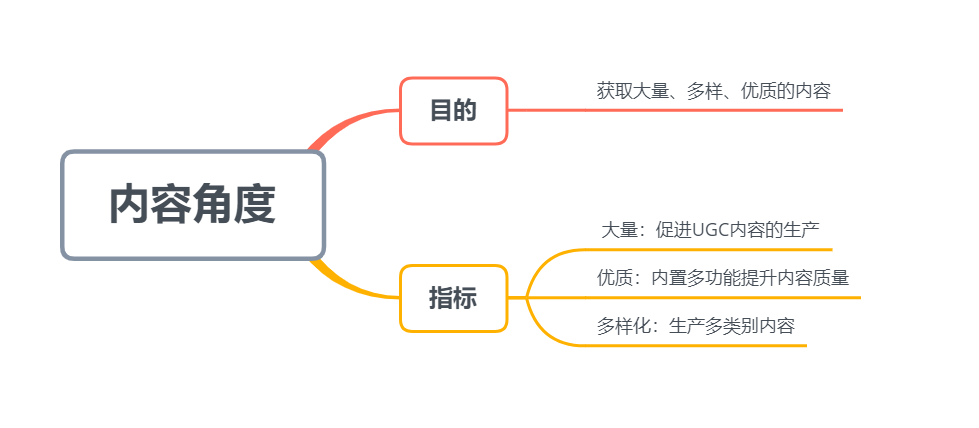
(2)从内容的角度,我们的目的是获取大量、多样、优质的内容,从这三个维度也可以采取多方面的措施:
1)大量
搭建社区生态,利用鼓励措施增大用户生产内容的量级。
2)多样
- 通过内容运营,鼓励用户生产多类别UGC内容。
- 为用户展现的内容不局限于兴趣匹配,还可以向用户推送:平台热门信息、猜测喜欢信息等,推送内容多样化。
3)优质
- 吸引网红、明星等KOL入驻,增加内容的质量。
- 小红书主要以图片内容为基础形式,可内置配乐、滤镜、贴纸等美化功能,提高UGC内容质量。
输出
省略“逻辑计算”这部分不谈,来聊聊策略的最后一步,即输出一个用户满意的Feed流结果。
如何判断用户是否满意呢?
这就涉及到Feed流效果评估的问题。
一个基本原则是,要想评估Feed流展现效果好不好,就是要通过各方面进行打分,从而得出该Feed流在用户心中的“喜爱度”。
打分规则可以粗略从两个角度来考虑:一是排序,用户喜爱的内容排在越靠前,则说明该Feed流效果越好。二是从内容本身来看,用户喜爱的内容出现的越多,则说明Feed流分数越高、效果越好。
细化到具体的评估指标,可以从以下维度考虑:
- 前n个点击量:例如考虑前10个内容中,用户点击了几个内容。通过计算占比的值,来评估效果
- 点击量:这是最直观的数据。用户点击该Feed流的内容越多,说明用户喜爱度越高
- 停留时长:用户在Feed流的内容中停留时间越长,说明用户对该Feed流越感兴趣
- 活跃度:用户点赞、评论、转发等行为
三、feed流的优化策略
通过以上步骤,我们初步产生了一个Feed流。然而就像一句古话,“上线不是结束,而是新的开始”,产生Feed流之后的过程,就是不断优化迭代的血泪史了。
接下来,以小红书为实例,咱们聊聊小红书Feed流存在的问题是什么?以及基于这个问题,如何对Feed流进行优化。
作为小红书的忠实用户,我使用小红书时遇到最大的问题,便是内容的同质化。
一方面是正常内容的同质化:
- 从内容生产的维度来说,正常用户由于跟风、模仿等原因,发布的内容越来越趋于相似
- 从内容接受的维度来说,每天推送的内容没什么新鲜感,仅是推送最近、过去感兴趣的内容
另一方面是不正常的同质化:例如某些软广,发布了大量相似的内容。
小红书是内容平台,内容的同质化很显然会极大降低内容质量,轻则流失部分用户,重则降低产品的核心竞争力。因此,对小红书来说,同质化问题,需要被排在较高的优先级去考虑。
为了解决内容同质化问题,我们可以从内容本身出发,从“内容重复度”的维度为将内容粗略归类,进而思考不同类型的解决方案:
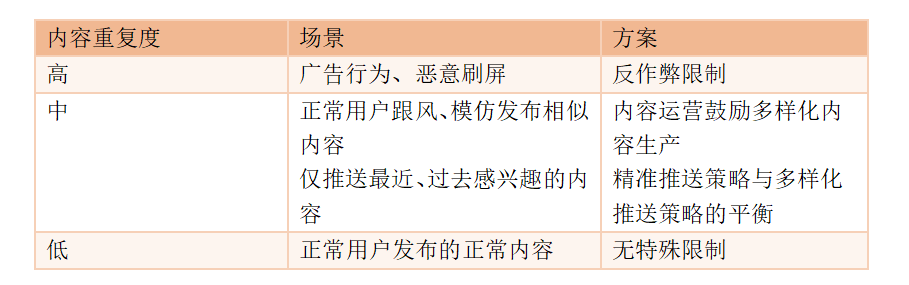
方案一:反作弊限制高重复度内容
简单来说,对于疑似广告的行为,需要对内容进行识别和处理。
从识别的角度,可以从以下指标来判断内容是否是广告行为,对单个内容的“广告疑似度”进行打分:
- 内容重复度极高
- 重复篇数较多
- 发布重复内容的IP段相似
- 其它数据指标异常(点赞量、留言量短期快速增加)
从处理的角度,由于小红书是一个内容社区,简单粗暴的删除内容有可能引起误伤,或是损害内容生态。
我认为处理方式可以从“降低优先级”的角度考虑:根据单个内容的“广告内容疑似度”,来适当降低广告内容在首页Feed流及搜索中的排序。
若该内容被判断为大概率属于广告,则优先级则会降低,甚至完全不展现给用户。通过这样的方法,对高重复度内容进行限制。
方案二:内容运营鼓励多样化内容生产
对于跟风、模仿发布相似内容的用户,他们可能是出于两种心态:一是不知道要发布什么内容,二是想通过跟风模仿来获得归属感、认同感。
基于这个背景,我们可以通过在内容发布页增加文字提示的运营方式,来鼓励用户发布多样化的内容。例如以下提示,适当引导用户发布的内容:
- 美食类:晚上好,晒晒你的丰富大餐吧
- 健身类:说说你最近的瘦身成果吧,听说80%在小红书晒健身计划的人都瘦了哦
- ……
一方面,从用户角度来说,结合场景的提示语拉近了用户与内容社区的距离,适当的引导可以解决用户发布内容时“不知道选取什么主题”的问题。
另一方面,从公司角度来说,也可以通过实时监控与调整,来完善社区内容的多种类。具体来说,当遇到“美食类内容生产较少”的问题,可以通过增加美食类引导语比例,来促进社区内容的种类完整性。
方案三:精准推送策略与多样化推送策略的平衡
Feed流的最终目的是“寻找到用户喜欢的内容”,为了达到这个目的,一个有效的途径是进行用户与内容的“精准匹配”,通过过往信息来判断用户的兴趣,即精准推送策略。
但实际上,用户对“自己喜欢的内容”的界定是比较模糊的。有时候,就连用户自己也无法准确描述自己喜欢的是什么,仅局限于对过去信息来判断用户兴趣,会忽略掉用户未来、有可能兴趣。因此,就会出现推荐内容同质化的问题。
因此,除了推荐精准预测的内容外,也应当进行多样化内容的推送。在进行内容匹配时,为用户展现的内容不局限于兴趣匹配,还可以向用户推送:平台热门信息、猜测喜欢信息等,推送内容多样化
面试是我们向面试官输出和表现自己的过程,不断面试被问到新的问题,就可以通过在复盘的阶段主动查询资料和深度思考来进一步了解。
如果大家对这篇文章有什么建议与意见,欢迎在评论区留言与我沟通~
本文由 @Isabel 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议









非常优秀
感谢作者,非常优秀
优秀
内容同质化严重的问题在各大内容平台都存在,作者提出的思路很不错,学习啦~
写的很好
连用户自己也无法准确描述自己喜欢的是什么,仅局限于对过去信息来判断用户兴趣,会忽略掉用户未来、有可能兴趣——确实如此。在做类似的推荐产品中,可以考虑abtest,结合深度学习,多推荐算法并行,通过文中的几个指标为导向不断升级推荐准确性。
个人觉得写的很好,如果可能,可以加我微信聊:aini520ko1007