
 起点课堂会员权益
起点课堂会员权益
产品人请自保:每次上线都踩雷?你可能忽略了这几点
 产品经理的核心价值是能够准确发现和满足用户需求,把用户需求转化为产品功能,并协调资源推动落地,创造商业价值
产品经理的核心价值是能够准确发现和满足用户需求,把用户需求转化为产品功能,并协调资源推动落地,创造商业价值产品迭代上线时,总是难免遇到各种意外和问题。这些问题往往不是偶然,而是由于在需求评审、协作沟通、测试覆盖等环节的疏忽所导致的。本文将通过作者团队的亲身经历,分享在产品上线过程中容易被忽视的几个关键点,并提供一份详细的上线前自检清单,帮助产品人和开发者在上线前系统地检查各个维度,避免常见的“连锁反应式灾难”,确保产品迭代的顺利进行。

如果你负责的产品比较复杂或者刚入行,总会碰到一些有的没的影响需求上线,内心五味杂陈:为什么我测完了所有功能点,还会出现一些莫名的bug来影响我的上线?
如果你觉得这只是巧合,那可能是你还没经历够。产品迭代之所以频繁出错,不是因为我们不够努力,而是因为我们太容易相信“这次应该没问题”。
我们团队近期刚经历了一次功能上线后的“连锁反应式灾难”,踩过的坑、犯下的错、总结的方法,全都赤裸裸地写出来,送给每一个在更新前焦虑、更新后抓头发的产品人和开发者。
01 你可能忽略了这些前置风险
第一,需求评审不彻底,遗漏影响范围。
很多小功能背后其实依赖着多个服务和老逻辑,开发只改了一行代码,可能就踩了别人的线。
比如我们这次就是忽略了“跨域限制只在生产环境生效”,结果数据服务直接失效。需求评审时没拉出完整影响范围图,等于是盲开地图。
第二,协作信息不对称,误会频发。

多个团队一起迭代时,组件库、版本号、API 返回格式,任何一处不同步,都可能导致线上事故。而这些问题,在沟通环节常常被“默认没问题”草草带过。结果不是前端样式错乱,就是数据对不上。
第三,测试盲区太多,未覆盖“真实场景”。
常规测试往往只覆盖了主流程,边缘路径、极端设备、缓存策略等都没人管。比如某次移动端 JS 被浏览器拦截,最终原因是脚本顺序在某机型下被打乱——而这个场景压根没人测过。
上线意外,不是突然发生的,而是被“放过”的细节积累而成的。只有在流程设计上就提前考虑边界、同步、测试策略,才能真正降低故障率。
02 上线前,五维度自检清单
每次产品迭代上线,出问题的根本原因,往往不是没做检查,而是检查得不系统、没方法。
我们复盘之后,把上线前需要检查的点归纳成五个维度:功能逻辑、接口依赖、样式适配、灰度回滚、测试兜底。
每次上线前按这五类跑一遍 checklist,可以大大降低“意料之外”的线上事故。
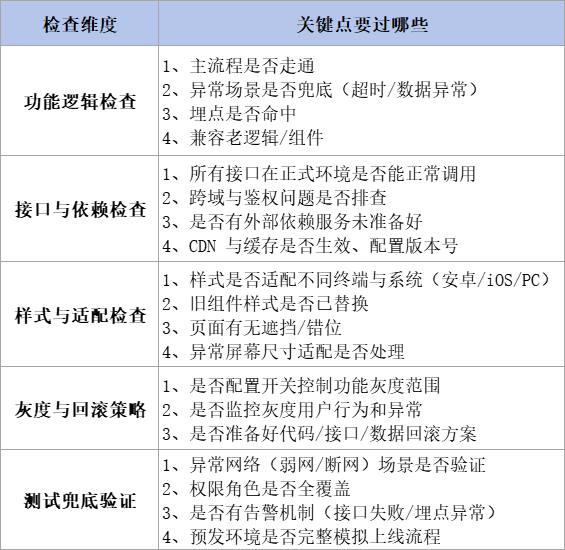
这份清单建议在每次上线前由产品、开发、测试三方一起对表拉通确认,一项一项过,不允许模糊回答“应该没问题”。
最好搭配实际 owner+完成情况标记形成自己的团队版本(比如打 √、写责任人、备注风险项),每次上线时作为必备文档,跑一遍比“祈祷上线不出事”更有用。
最后的话
产品迭代不是一场“赌运气”的游戏,每一次上线都藏着许多看似微小却致命的风险。你如何避免这些意外,决定了你的产品能否健康成长,能否在竞争激烈的市场中立足。
通过上线检查清单,你可以避免常见的跨域问题、样式错乱、数据丢失等坑,让每次发布都更加平稳。更重要的是,这不仅仅是一个“上线流程”问题,而是一个“产品质量控制”问题。
就像乔布斯曾说的:“细节决定成败。”上线前的每一个细节,都关乎产品的未来。别再让“意外”成为常态,掌握好检查清单,守住你的产品质量底线。
希望带给你一些启发,加油!
作者:柳星聊产品,公众号:柳星聊产品
本文由 @柳星聊产品 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。

















我也说一下我的观点:可能是因为在规划、测试和用户反馈环节存在疏漏。确保全面考虑用户体验、严格进行质量控制,并及时响应用户反馈,是避免上线踩雷的关键。
对的,很同意您的观点