注意图中的“考点”和“标签”,机器是不认识“题目”的,机器学习的数据就是这些人工打上的“标签”。现在的题库动辄号称千万题量,其实哪怕是百万,生产一个上图这样标准化的题库的唯一办法就是雇佣大量的廉价劳动力,比如大学生兼职团队。在这种情况下,你打出来的标只能是“粗粒度”的。“粗粒度”怎么理解?大家都学过中学数学的,我们尝试估计一下这种标签的种类数量。整个高中数学约30个单元,如数列、立体几何、函数、不等式等。按照“等差数列、等比数列”、“定义法”、“空间几何体”、“图解法”这样的用词,每个单元平均十几个标签吧,总数我猜在300个左右。好,我们来感受一下这样一个场景,智能题库给你推送了5道题,都带有“直线方程”这个标签,结果你全做错了。这时不管背后的机器怎么学习,它一定要再给你推一道带“直线方程”标签的题吧。这有用吗?你刚才犯的错误是“用点斜式设直线方程时忘记考虑斜率K不存在的情况”,或者是忘记了“与直线Ax+By+C=0垂直的直线是Bx-Ay+C1=0 (C1≠C)”,再或者是在“用方法四求直线关于某定点对称的直线”时用错了“中点坐标公式”,blablabla……然后这次给你推的题是“求两条直线的交点坐标”。嗯,它们都是“直线方程”。
感谢数学不好的小伙伴坚持看完上面这一段,我想表达的观点是——粗粒度的个性化是伪个性化。用俄罗斯方块做个比喻,如图,下面那些坑就是学生的薄弱点或者叫做用户的需求,五花八门。现在你要消掉它,如果落下来的全是4×4甚至6×6的方块,那你永远也别想成功。
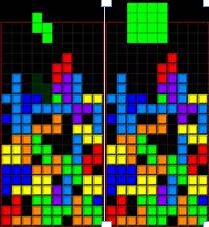
回到上面题库的第二个问题就是,任何数据所训练出来的模型的颗粒度不可能超过数据本身的颗粒度。所以,在数据质量(颗粒度)达到某个阈值之前,再多的数据可能都是“废的”,数据的质量决定了个性化的有效性。
实际上,数据颗粒度这件事还间接影响了前一篇中我们提到的“学习主动性”问题。这里先卖个关子,回头一并在学习主动性一节阐述。
市面上估计有十几款题库,有兴趣的朋友可以都装来看看,show出来的知识点基本都是上面截图那种粒度的。然后就有个朋友跟我说“真像你说的那么多问题,人还拿了那么多钱呢”。对这个问题,我想起前几个月有篇文章,讲的是对比IDG和红杉的投资,标题是“赌选手还是赌赛道”之类的。这两年在这个领域创业有两个感觉,一是好像全行业都觉得所谓风来了,他妈的再有个三五年,在线教育绝对是和电商之于传统零售一样,对传统教育必须是颠覆啊;二是至今都没有一个能够得到较广泛认可的模式或产品,尤其是K12。所以,第一点决定了资本必须布局,得投啊,晚了没坑了啊。第二点是都不靠谱那投谁呢?其中一个答案就是“赌赛道”,越有钱越这么干。起码最好的赛道要有我的份,然后每个赛道里面尽量挑最好的选手呗。猿题库当年也是做平台(粉笔网)的呢。2013年,多少平台拿钱了呀,到2013年下半年就开始死了,粉笔网团队很棒啊,能够快速转型到第二波最靠谱的模式——题库。然后各种题库纷纷冒出来了,到现在题库也开始泛滥了,那第三波最靠谱的在哪里?不知道,希望是我们哈。
其实组题类题库还有一种,就是面向老师的,猿题库是面向学生的。我个人其实比较喜欢面向老师的组题类产品。可能是因为自己做了段时间老师,觉得自动组卷这玩意真是有用啊。去年我们经常用梯子网查题,可惜它倒了。现在也有一些面向老师的组题产品,不过比较少。想来想去,面向老师的组题产品不能成为主流的原因可能是两个,一是盘子小,二是商业模式不成立。面向学生的组题产品的商业模式,我理解核心是导流玩转化率,通过对接其他环节完成整个闭环。用一个朋友的话讲是,“给人特别互联网的感觉”。对比起来,面向老师的就差的比较多了。这一块因为想的不多,就先不展开扯淡了。
今天拍了很多猿题库,猿题库的朋友不要打我哈。猿题库是题库里做的最棒的,我们也偷着学了点东西。比如公式的处理,latex串用的很棒,在存储、传输和显示等方面都有极大优势,还有很强的扩展性,比起现在很多用图片的那是高大上太多了。
FROM Techxue

 起点课堂会员权益
起点课堂会员权益








说到底 其实就是推荐题库的问题; 技术上好难解决啊…